
ArogyaSutra: A Multi-Agent Framework for Multimodal Medical Reasoning in Indic Languages
Source: arXiv:2606.13572 · Published 2026-06-11 · By Tanmoy Kanti Halder, Akash Ghosh, Subhadip Baidya, Arijit Roy, Sriparna Saha
TL;DR
This work addresses the critical challenge of enabling robust multimodal medical reasoning in low-resource Indic languages, a setting where most existing multimodal large language models (MLLMs) underperform due to language and domain gaps. The authors introduce ArogyaBodha, a large-scale multilingual multimodal medical QA dataset covering 31 body systems, 21 clinical domains, six imaging modalities, and eight diverse sources, spanning English and seven major Indian languages. To leverage this dataset, they propose ArogyaSutra, an actor-critic multi-agent framework integrating tool-based visual grounding with dual memory (short- and long-term) and language-aware reflective feedback to iteratively refine reasoning steps rather than directly predicting final answers. Extensive experiments demonstrate that ArogyaSutra consistently outperforms strong generalist and medical baselines—including GPT-4 variants and domain-specific models—across all Indic languages, improving average accuracy by up to 9.2 points over its base model and achieving 50.4% accuracy on an out-of-distribution benchmark. Ablations validate the key roles of the critic agent, tool grounding, memory components, and language code-switching in driving these gains.
Key findings
- ArogyaSutra(Qwen2.5-VL-7B) achieves an average accuracy of 43.40% across seven Indic languages, outperforming GPT-4.0 by +4.1 points (39.30%) and its own base model Qwen2.5-VL-7B-Instruct by +9.2 points (34.21%) (Table 3).
- On an out-of-distribution benchmark derived from Spanish clinical exam questions translated into Indic languages, ArogyaSutra attains 50.4% accuracy vs 35.0% for the base Qwen2.5-VL-7B-Instruct (Table 5).
- Removing the Critic agent reduces accuracy from 43.4% to ~33.4%, indicating the critic's critical role in guiding reasoning (Table 4).
- Disabling both tool grounding and memory further drops accuracy to 26.86% (Table 6), showing these modules' complementary contributions.
- Code-switching corrective feedback is essential, with its removal causing a >16 point accuracy drop (Table 4).
- Memory modules (short and long-term) improve performance from 26.86% to 30.57%, and combined with grounding, reach best results of 43.40% (Table 6).
- Translation quality is robust across languages, with reverse-translation cosine similarities around 0.93–0.94 and BLEU4 scores averaging 0.49–0.57 (Table 2), preserving clinical semantics.
- Multilingual consistent reasoning and language fidelity are demonstrated qualitatively, with ArogyaSutra producing more medically and linguistically coherent responses than MedGemma-4B-it and Qwen2.5-VL-7B baselines (Figure 2).
Threat model
Not explicitly defined as a security adversary model. Implicitly assumes input clinical queries and medical images are authentic but potentially noisy or ambiguous; the system is not designed to handle maliciously crafted adversarial inputs or attempts to corrupt medical reasoning outputs.
Methodology — deep read
Threat Model & Assumptions: The adversary model is not explicitly defined as this is primarily a medical reasoning and language understanding task rather than a security attack scenario. However, implicit assumptions include noisy or ambiguous clinical query inputs in low-resource Indic languages combined with complex medical images requiring step-wise reasoning. The system assumes access only to the input images and queries in the low-resource languages, with no privileged adversarial control.
Data: The ArogyaBodha dataset was curated by combining eight heterogeneous sources including publicly available medical reasoning benchmarks, medical imaging repositories, and postgraduate medical entrance exam questions from India. Total dataset size is 40,857 instances spanning English and seven Indic languages (Bengali, Hindi, Assamese, Tamil, Telugu, Punjabi, Marathi). The data covers 31 body systems, 21 clinical domains, and six imaging modalities such as CT, MRI, and X-ray. Data filtering included relevance checks for image–question alignment using GPT-4o-mini and Gemini-2.5-Flash models with manual medical verification. Translations into Indic languages were performed with Gemini-2.5-Pro, validated through reverse-translation and cosine similarity measures, and scored by medical experts for clinical and linguistic fidelity.
Architecture/Algorithm: ArogyaSutra builds on Qwen-VL multimodal backbone models with 3B or 7B parameters. It employs an actor-critic multi-agent framework where the Actor proposes incremental semantic reasoning steps based on input observations, goals, visual cues, and memory states. The Critic evaluates each step's correctness with scalar confidence scores. If incorrect, the Critic diagnoses error types (linguistic vs logical) and issues language-aware reflective feedback—code-switching to English for language errors or using the original Indic language to correct reasoning faults. This feedback updates dual short-term and long-term memory modules storing past mistakes to avoid repeating them. The framework incorporates tool grounding with four key vision operators (open-vocabulary object detection, zoom/crop, edge detection, depth analysis) to improve visual evidence extraction. At inference, the Actor uses policy distillation from Critic-guided rollouts to predict actions without explicit evaluation.
Training Regime: Fine-tuning was done on NVIDIA A100 80GB GPUs for 3 epochs with a learning rate of 5e-4, batch size 2 with gradient accumulation steps of 4, and weight decay 0.01. Parameter-efficient fine-tuning via LoRA was applied to language, attention, and MLP projection layers with rank 16 and dropout. Multilingual balanced training was performed on a dataset subset of approximately 18K samples with equal language representation. The model was optimized using supervised learning over the Critic-refined action dataset constructed from simulated actor-critic trajectories.
Evaluation Protocol: Evaluation was performed in a zero-shot setting using choice accuracy as the primary metric. The test set included 130 samples per language (910 total) balanced across sources for controlled cross-lingual comparison. An additional 60-question out-of-distribution set derived from Spanish residency exam questions translated into the Indic languages was used to assess generalization. Baselines comprised general-purpose and medical multimodal models, including GPT-4 variants, Qwen family models, Mistral, LLaVA, BioMistral, MedGemma, and MedVLM-R1. Ablations tested the effect of removing the critic, tool grounding, memory modules, and code-switching mechanisms.
Reproducibility: The authors provide source code and dataset publicly. However, some datasets are filtered versions of publicly available medical datasets and postgraduate exam questions with anonymization. The exact seed values for training are not mentioned. Model weights from Qwen-VL were used as backbones. Overall, the paper appears to enable reproducibility with the released resources but some medical dataset licensing or filtration dependencies exist.
Concrete example end-to-end: Given a multimodal input consisting of a medical image (e.g., brain MRI slice) and a complex clinical query in Hindi referencing symptoms and image findings, the Actor initiates reasoning by applying visual grounding tools (e.g., zoom and edge detection) to extract salient image regions. It predicts the first intermediate semantic step, such as identifying lesion location. The Critic evaluates the step and detects a language generation error—repetitive tokens—then code-switches the feedback into English for clarity. The Actor uses this feedback stored in short-term memory to refine the next reasoning step, e.g., hypothesizing diagnosis. If logical errors are found next, feedback is issued in Hindi to leverage contextual grounding. This iterative actor-critic loop continues until a stable, medically coherent final answer is produced or the retry limit is reached, after which training leverages stored trajectories for policy distillation.
Technical innovations
- ArogyaSutra introduces a novel actor-critic multi-agent framework combining tool-based visual grounding with dual-memory error-aware reflection for step-wise multimodal medical reasoning.
- Integration of language-aware reflective feedback with adaptive code-switching to English or Indic languages depending on error type to enhance linguistic stability in low-resource language settings.
- Curated ArogyaBodha, a large-scale multilingual multimodal medical question-answer benchmark spanning eight data sources, seven Indic languages, and six imaging modalities.
- Distillation of the critic's iterative evaluation and correction process into a single actor model enabling efficient inference without explicit critic usage.
Datasets
- ArogyaBodha — 40,857 samples — curated from eight heterogeneous public medical datasets and Indian postgraduate medical exam questions
- MedXpertQA — 1,982 samples — public
- MedTrinity-25M — 576 samples — public
- MedPix-2.0 — 464 samples — public
- MAMA-MIA — 64 samples — public
- BRATS24 — 393 samples — public
- PMC-VQA — 1,073 samples — public
- GMAI-MMBench — 164 samples — public
- NEET-PG, FMGE — 391 samples — public postgraduate medical exam data
Baselines vs proposed
- GPT 4.0 mini: average accuracy = 36.05% vs ArogyaSutra(Qwen2.5-VL-7B) = 43.40%
- GPT 4.0: average accuracy = 39.30% vs ArogyaSutra(Qwen2.5-VL-7B) = 43.40%
- Qwen2.5-VL-7B-Instruct baseline: average accuracy = 34.21% vs ArogyaSutra(Qwen2.5-VL-7B) = 43.40%
- BioMistral-7B medical model: average accuracy = 26.35% vs ArogyaSutra = 43.40%
- MedGemma-4B-it medical model: average accuracy = 36.11% vs ArogyaSutra = 43.40%
- On OOD benchmark: MedGemma-4B-it = 45.2% vs ArogyaSutra(Qwen2.5-VL-7B) = 50.4%
- Ablation w/o Critic and Image Grounding: 33.43% vs full ArogyaSutra = 43.40%
- Ablation w/o Image Grounding: 26.86% vs full ArogyaSutra = 43.40%
- Ablation w/o code-switch: 26.86% vs full ArogyaSutra = 43.40%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.13572.
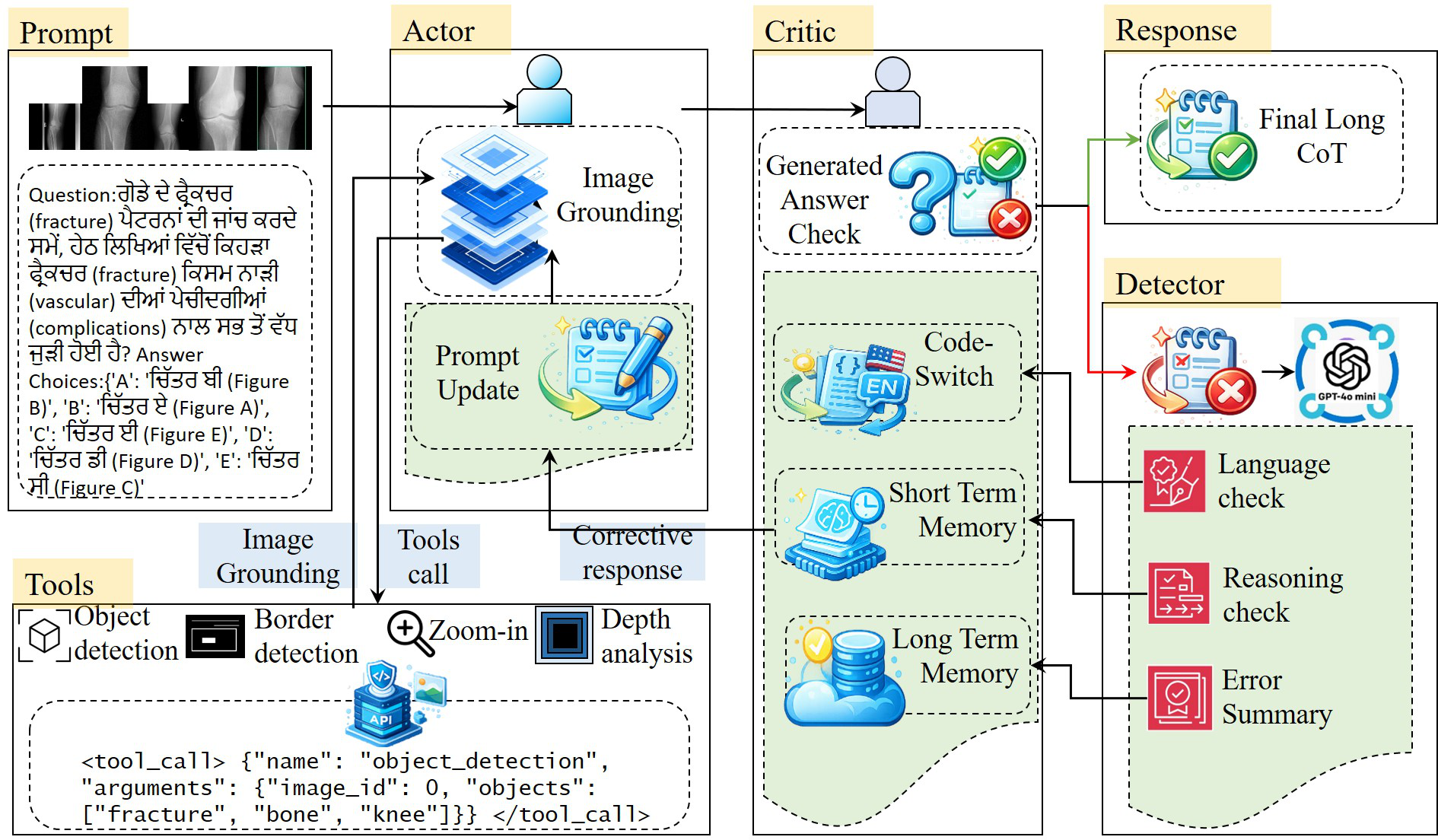
Fig 1: Overview of the ArogyaSutra framework. ArogyaSutra employs an actor–critic architecture enhanced with tool-based image
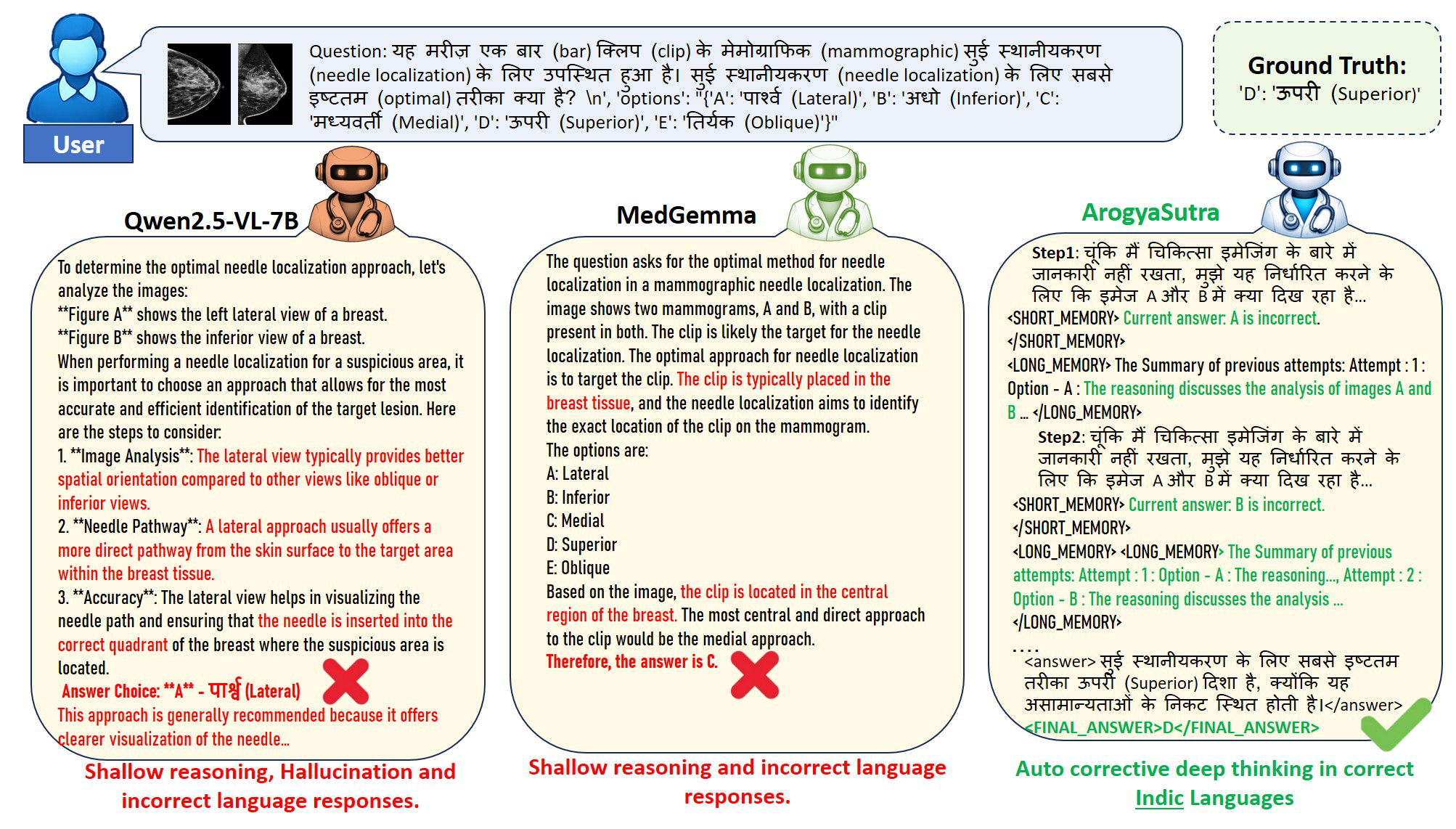
Fig 2: Overview of qualitative comparisons between ArogyaSutra and baseline models.

Fig 3 (page 7).

Fig 4 (page 7).
Limitations
- The model can still produce reasoning errors or misinterpret visual evidence particularly in rare or atypical clinical cases, risking potential misuse if outputs are trusted blindly.
- Despite covering seven languages, the dataset excludes low-resource Indic dialects and common code-mixed clinical language, limiting real-world linguistic diversity coverage.
- The actor-critic framework depends heavily on the accuracy of underlying visual grounding tools and the multimodal backbone; failures in these components can cascade through reasoning.
- The dataset and framework focus on curated, clinically verified data, so performance in truly unconstrained, noisy clinical environments remains untested.
- Training and evaluation do not include adversarial examples or robustness tests against deliberate medical misinformation inputs.
- The approach assumes availability of multimodal images with queries; text-only or audio-based medical interactions are not addressed.
Open questions / follow-ons
- How can ArogyaSutra be extended to handle code-mixed and dialectal language common in real-world clinical contexts in India?
- Can the framework incorporate other modalities such as clinical notes, lab results, or patient histories to improve reasoning?
- What robustness guarantees or detection can be introduced to handle adversarial attacks on medical image or text inputs?
- How well does ArogyaSutra generalize to other low-resource languages or to completely unseen clinical domains not covered in ArogyaBodha?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this paper illustrates a sophisticated use of multi-agent reinforcement learning and actor-critic architectures for incremental reasoning in noisy multilingual multimodal environments. The dual-memory approach tracking error patterns and dynamic code-switching feedback mechanisms are notable techniques to improve the stability and trustworthiness of language outputs under resource constraints. While focused on medical QA, the underlying principles could inspire security systems reliant on complex step-wise decision-making across multimodal inputs, especially in low-resource or multilingual contexts. The dataset construction and multilingual evaluation rigor also underscore the importance of robust benchmarking to avoid language or modality biases often exploitable by adversaries. However, direct applicability to CAPTCHA is limited since the system focuses on clinical reasoning rather than adversarial bot detection or challenge generation per se.
Cite
@article{arxiv2606_13572,
title={ ArogyaSutra: A Multi-Agent Framework for Multimodal Medical Reasoning in Indic Languages },
author={ Tanmoy Kanti Halder and Akash Ghosh and Subhadip Baidya and Arijit Roy and Sriparna Saha },
journal={arXiv preprint arXiv:2606.13572},
year={ 2026 },
url={https://arxiv.org/abs/2606.13572}
}