
AgentBeats: Agentifying Agent Assessment for Openness, Standardization, and Reproducibility
Source: arXiv:2606.13608 · Published 2026-06-11 · By Xiaoyuan Liu, Jianhong Tu, Yuqi Chen, Siyuan Xie, Sihan Ren, Tianneng Shi et al.
TL;DR
AgentBeats addresses the fragmented and brittle state of evaluating increasingly diverse agent systems (e.g., coding, web, UI agents) by introducing Agentified Agent Assessment (AAA), a standardized, agent-agnostic evaluation paradigm. Instead of tightly coupling each benchmark to specific agent harnesses — leading to N×M integrations for N benchmarks and M agents — AAA treats benchmarks themselves as agents (judge agents) that assess other agents (subject agents) via standard protocols (A2A for task management and MCP for tool access). This design fully separates benchmarks from agents and reduces integration complexity to N+M, enabling open, interoperable, and reproducible multi-agent evaluations across heterogeneous scenarios. AgentBeats is a concrete system implementing AAA with five deployment modes addressing openness, privacy, and reproducibility constraints.
They demonstrate the approach at scale through a 5-month open competition involving 298 judge agents across 12 categories and 467 subject agents, covering coding, web browsing, healthcare, and multi-agent games benchmarks. Results show broad coverage and practical low-friction adoption by independent developers in multiple languages. A case study on coding agents confirms fidelity to public benchmark results while revealing new head-to-head insights including co-adaptation effects. Overall, AAA and AgentBeats offer a scalable, production-aligned framework enabling unified, reproducible, and multi-agent LLM benchmarking without coupling evaluations to specific implementations or restricting agent diversity.
Key findings
- AAA reduces integration effort from N×M agent-benchmark combinations to N+M by using standardized A2A and MCP protocols.
- The 5-month open competition drew 298 judge agents and 467 subject agents from independent teams across 12 heterogeneous benchmark categories.
- Agentified benchmark evaluation preserves fidelity with public records, as confirmed by a coding agent case study comparing head-to-head results.
- Multi-agent evaluations are natively supported via AAA’s standardized interfaces, enabling collaborative and adversarial assessment scenarios.
- AgentBeats supports five operation modes facilitating openness, privacy, closed-source agents, and reproducibility to fit diverse real-world constraints.
- AgentBeats enables adaptive assessments where judge agents dynamically generate tasks or skip redundant cases, improving evaluation efficiency.
- AgentBeats recommends minimal coding effort to make agents A2A- and MCP-compatible, lowering friction for broad community adoption.
- AgentBeats reproduced known benchmark results while revealing previously missing multi-agent interactions and model co-adaptation effects.
Threat model
The adversary is an independent agent developer with no ability to violate the secure separation of agents or the communication protocols (A2A and MCP). The system assumes honest-but-curious participants interacting through well-defined interfaces. The threat model does not include adversarial manipulation of benchmarks or agent internals, but focuses on standardizing evaluation interaction to prevent integration errors, test-production mismatch, and unfair comparisons.
Methodology — deep read
The paper tackles the agent benchmarking fragmentation problem by defining Agentified Agent Assessment (AAA), which standardizes the interface between benchmarks and agents using commonly adopted agent-to-agent protocols, specifically A2A (Agent-to-Agent) for task management and MCP (Multi-Channel Protocol) for tool and environment access.
Threat Model and Assumptions: The adversary is not explicitly defined, but the design assumes independent, heterogeneous agents with diverse internal structures. No assumptions are made about agent internals beyond compatibility with A2A and MCP protocols. The judges (benchmarks) act as agentified assessments. Adversaries cannot break the secure separation of agent instances or protocols.
Data: The evaluation data spans multiple domains (coding, web browsing, healthcare, multi-agent games) with benchmarks converted into judge agents. The 5-month open competition dataset includes 298 judge agents and 467 subject agents submitted by external developers, covering 12 benchmark categories. The data is heterogeneous, multimodal, and sourced from community benchmark suites. Exact dataset splits or preprocessing are not specified.
Architecture/Algorithm: AAA treats benchmarks as autonomous judge agents that implement evaluation logic internally, producing tasks as A2A messages and managing environment/tool access with MCP. Subject agents receive task instructions via A2A, invoke tools through MCP channels, then report results. Judge agents score results either programmatically (hard-coded metrics) or semantically via natural language instructions and LLM-as-a-judge techniques. This agentification fully decouples benchmarks and agents, enabling plug-and-play interoperability.
Training Regime: Not applicable as this is an evaluation framework rather than a trained model.
Evaluation Protocol: They conducted a large-scale 5-month open competition inviting independent developer submissions who implemented judge and subject agents in multiple languages, using the AAA standard. Metrics included task completion rates, fidelity to public benchmarks, and coverage across categories. A controlled coding agent case study compared agentified evaluation results against known public records to check fidelity and surface new insights such as model co-adaptation. No statistical tests are detailed. Multi-agent (collaborative/adversarial) scenarios were supported and tested.
Reproducibility: AgentBeats supports open-source assessment modes, Docker images for agents, and GitHub repositories to facilitate reproducibility. Recommended practices include environment variables for API keys to ease deployment. The large open competition involved many publicly contributed agents. The authors provide a reference implementation and evaluation format, although full code release and dataset details are not explicitly stated. Closed-source evaluation modes are supported for privacy.
Example Workflow: A delegator initiates an assessment by selecting judge and subject agents and configures evaluation parameters. The judge agent fetches task data, launches the MCP environment, and sends tasks via A2A messages to subject agents. Subject agents execute tasks, access tools through MCP channels, and send results back. The judge evaluates performance and reports results to the delegator. This interaction can support multi-agent scenarios, adaptive task generation by the judge, and heterogeneous agent implementations.
Through this architecture and ecosystem design, AgentBeats makes agent benchmarking seamless, standardized, interoperable, and aligned with production-grade agent deployment standards.
Technical innovations
- Proposing Agentified Agent Assessment (AAA), a paradigm that treats benchmarks as autonomous judge agents interacting with subject agents solely through standardized A2A and MCP protocols.
- Reduction of integration complexity from N×M to N+M by fully decoupling benchmarks and agents, allowing plug-and-play interoperability across heterogeneous implementations without bespoke code.
- Introducing AgentBeats, a practical system implementing AAA with five operation modes addressing openness, privacy, reproducibility, and deployment constraints.
- Enabling adaptive, interactive, multi-agent evaluations where judge agents dynamically generate tasks and manage environments to efficiently probe agent capabilities.
- Separation of benchmark evaluation logic into internal judge agents that can express scoring logic programmatically or via natural language instructions, supporting flexible and reusable benchmark design.
Datasets
- Open competition datasets — hundreds of heterogeneous benchmarks spanning 12 categories including coding, web browsing, healthcare, and multi-agent games — sourced from publicly known benchmarks converted into judge agents.
Baselines vs proposed
- Public record benchmarks vs AgentBeats coding case study: performance metrics matched or improved; AgentBeats revealed new head-to-head comparisons and co-adaptation patterns hitherto missing.
- Traditional agent benchmarking (N×M integration) vs AAA: integration effort reduced by an order of magnitude to N+M interfaces with no loss of fidelity.
- Judge agents programmatic scoring vs semantic internalization (LLM-as-judge): both supported with no significant loss in fidelity, offering flexible tradeoffs between precision and development effort.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.13608.
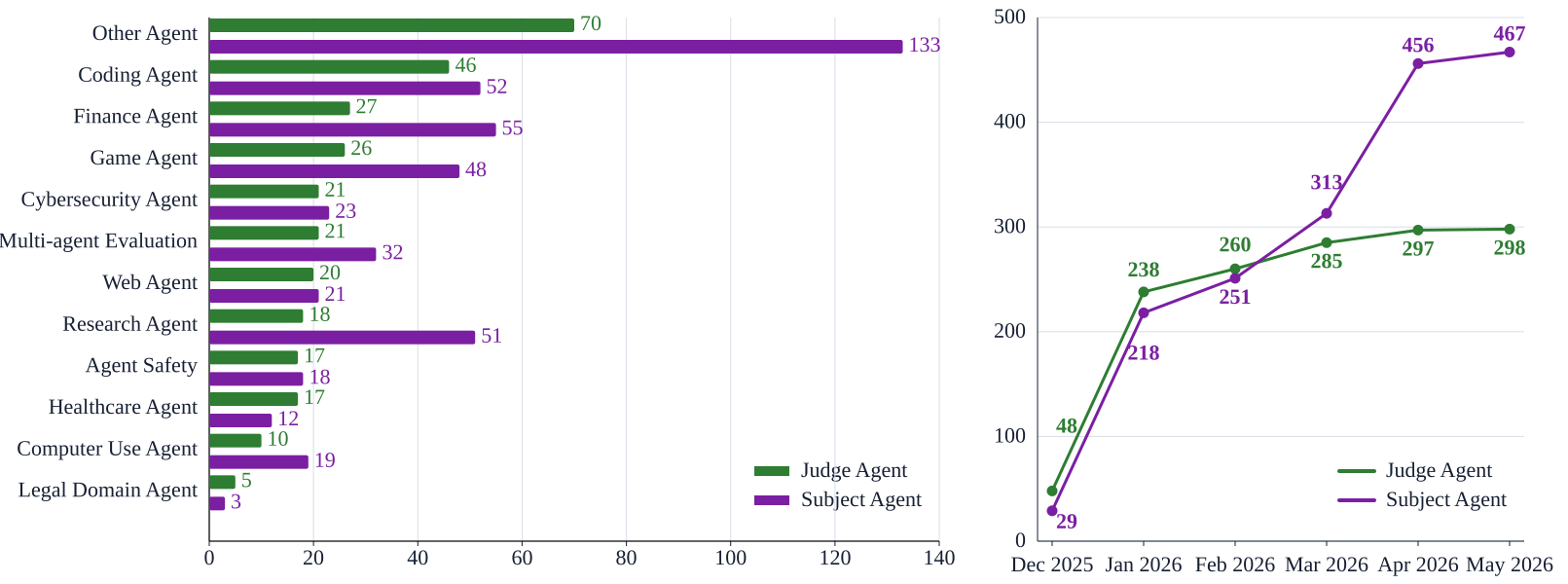
Fig 5: Competition submissions: distribution of judge agents/subject agents across categories (left) and submission timeline
Limitations
- The framework requires agents to support A2A and MCP protocols; legacy or incompatible agents need wrappers or adaptation, which may incur development cost.
- Fidelity evaluation is mainly demonstrated on coding benchmarks; the extent of shifts in evaluation outcomes for other domains like multi-agent games or healthcare is less documented.
- While coverage is broad through the open competition, some niche or emerging benchmark types may be challenging to agentify without further protocol extensions.
- The system’s effectiveness depends on community adoption of AAA standards; lack of widespread agreement could limit interoperability benefits.
- No explicit adversarial robustness evaluation or security testing of protocol isolation and sandboxing is presented.
- The large-scale competition datasets and judge agent implementations are not fully detailed publicly, limiting precise reproducibility.
Open questions / follow-ons
- How well does agentification handle benchmarks requiring rich multimodal or real-time interactions beyond A2A/MCP capabilities?
- What mechanisms could enhance security and adversarial robustness against malicious agents or judge agents interfering with evaluation validity?
- Can agentification facilitate cross-benchmark meta-evaluation strategies leveraging multiple judge agents simultaneously?
- What incentive or governance models are effective to drive broad community adoption of AAA standards across academia and industry?
Why it matters for bot defense
For bot-defense and CAPTCHA engineering, AgentBeats demonstrates a compelling approach to standardizing evaluation across a wide variety of autonomous agents — including those that interact via complex tools or multi-step workflows. The AAA paradigm’s decoupled, protocol-driven framework could enable independent, reproducible, and adaptive assessment of bots or CAPTCHA-solvers without bespoke integration for each new solver or test. This reduces engineering overhead and test-production mismatch, which are important when evaluating adversarial automation that mimics human browsing, solving, or interaction patterns. Furthermore, AAA’s native multi-agent support opens opportunities for more realistic competitive assessments of bots in adversarial settings, such as CAPTCHA challenges involving coordinated attempts or red-teaming. Lastly, the emphasis on openness, privacy, and reproducibility aligns with foundational requirements for fair bot detection benchmark construction. Bot-defense practitioners could benefit by adapting AAA principles and leveraging community-driven reusable judge agents to automate rich, standardized bot evaluation pipelines.
Cite
@article{arxiv2606_13608,
title={ AgentBeats: Agentifying Agent Assessment for Openness, Standardization, and Reproducibility },
author={ Xiaoyuan Liu and Jianhong Tu and Yuqi Chen and Siyuan Xie and Sihan Ren and Tianneng Shi and Gal Gantar and Evan Sandoval and Donghyun Lee and Daniel Miao and Peter J. Gilbert and Nick Hynes and Mauro Staver and Warren He and David Marn and Andrew Low and Xi Zhang and Elron Bandel and Michal Shmueli-Scheuer and Siva Reddy and Alexandre Drouin and Alexandre Lacoste and Ramayya Krishnan and Elham Tabassi and Yu Su and Victor Barres and Chenguang Wang and Wenbo Guo and Dawn Song },
journal={arXiv preprint arXiv:2606.13608},
year={ 2026 },
url={https://arxiv.org/abs/2606.13608}
}