
Which Models Are Our Models Built On? Auditing Invisible Dependencies in Modern LLMs
Source: arXiv:2606.12385 · Published 2026-06-10 · By Sanjay Adhikesaven, Haoxiang Sun, Sewon Min
TL;DR
This paper addresses the opaque and fragmented dependency ecosystem underlying modern large language models (LLMs). Current LLM development heavily relies on recursively composing other models for data generation, filtering, evaluation, and supervision, creating complex, multi-hop dependency chains that are difficult even for original developers to fully trace. Existing documentation and auditing approaches are insufficient to capture this recursive, heterogeneous structure. The authors contribute ModSleuth, an agentic system that reconstructs large-scale dependency graphs solely from public release artifacts with source-grounded evidence. ModSleuth uniquely distinguishes direct dependencies (that affect model weights or training data) from indirect dependencies (that influence development without direct training impact), represents dependencies as operation-centered relationships across heterogeneous artifacts, and resolves identity ambiguities via an identity lattice. Applied to four public LLM releases with rich artifacts, ModSleuth recovers 1,060 verified dependency edges (more than three times prior baselines) and constructs extensive multi-hop graphs revealing license implications, evaluation bias loops, and significant documentation gaps. This work provides a rigorous, reproducible approach enabling transparency and governance for the increasingly recursive and compositional nature of modern LLM development.
Key findings
- ModSleuth recovers 1,060 verified dependency edges under an unbounded recursive scope across four LLM releases, over 3× the highest baseline (314 dependencies by GPT-5.5 Pro).
- Even the most conservative depth-1 scope recovers 484 verified dependencies, exceeding the strongest baseline by 54%.
- Direct dependencies dominate, accounting for 1,191 verified edges (72% of total), with indirect dependencies contributing 463 edges (28%).
- Most direct dependencies influence downstream systems through data operations (generation, filtering, transformation) rather than weight inheritance—350 edges vs 28 for checkpoint lineage.
- Recursive dependency chains can extend up to 8 hops deep involving heterogeneous artifact types (models, datasets, transformations).
- External dependencies comprise 75–82% of verified edges, showing that LLMs heavily rely on artifacts developed outside their own organizations.
- Complex audit findings include license-relevant multi-hop paths, training-evaluation coupling risks, recursive preference loops, and code-level provenance not documented in papers.
- ModSleuth aggregates evidence from multiple public sources (papers, model/dataset cards, code repositories) to uncover dependencies that are undisclosed or unknown even to original developers.
Threat model
The adversary is an LLM developer or organization seeking to obscure, omit, or misrepresent upstream dependencies in their public disclosures to avoid license obligations, mitigate scrutiny of data contamination, or hide recursive bias propagation. The attacker controls what artifacts and documentation are released publicly. The system assumes no access to proprietary internal metadata or private communication. The adversary cannot modify or forge historical public artifacts once released. The goal is to audit and reconstruct dependency graphs under these constraints from official public sources only.
Methodology — deep read
Threat Model & Assumptions: The primary adversarial concern is lack of transparency and undetected risks arising from recursive model dependencies. The system assumes only publicly available official release documentation, code, datasets, and cards. Undeclared or hidden dependencies remain out of scope and untraced, so the resulting graph is a lower-bound.
Data: Target LLM releases are four models with extensive public artifacts: Olmo 3, Nemotron 3 Super, DR Tulu, and SmolLM3. The evidence corpus includes technical reports, model/dataset cards, code repositories, blogs, and linked upstream artifacts. Identity ambiguity necessitates an identity lattice to precisely capture artifact versions, subsets, and related metadata.
Architecture/Algorithm: ModSleuth is an agentic pipeline built on Claude Code for information extraction. It combines recursive artifact discovery, mention extraction, identity resolution, and structured dependency edge construction. A novelty is formalizing dependencies as operations with roles (generation, filtering, evaluation, rewriting), distinguishing direct vs indirect dependencies and grounding every edge in source evidence. Dependencies attach at the most specific resolved identity node in the lattice.
Training Regime: Not a ML model training task, but the multi-agent workflow involves recursive calls issuing navigation, extraction, and normalization tasks. Human audits review flagged inconsistency or ambiguity cases.
Evaluation Protocol: Evaluated on number of verified dependency edges recovered per target release. Verification is performed post-hoc by an independent agent (Claude Sonnet 4.6) that reads evidence URLs and issues JSON verdicts (verified, refuted, unclear). Baselines use single-prompt LLMs (GPT-5.5 Pro, GPT-5.4 Pro, ChatGPT) or non-staged Claude Code. Three nested scopes (depth-1, unbounded, BFS reachability) quantify graph completeness.
Reproducibility: ModSleuth code, models, and recovered graphs are publicly released. The dataset is restricted to publicly accessible artifacts with clear provenance. However, some source ambiguity and missing dependencies mean the graphs are a conservative lower bound.
A concrete example: Given Olmo 3, ModSleuth gathers its papers, cards, and repos; extracts mentions like “Olmo 3 32B-Think” and upstream generators; resolves identities via the lattice; constructs evidence-backed edges for direct dependencies (e.g., synthetic data generation) and indirect dependencies (e.g., evaluation models); then recursively applies the same tracing to upstream models referenced, producing a multi-hop graph of 481 verified forward-reachable edges with detailed source anchors.
Technical innovations
- Formalization distinguishing between direct dependencies (affecting weights or training data) and indirect dependencies (influencing development decisions without training entry).
- Operation-centered dependency representation capturing the diverse and specialized roles upstream artifacts play in LLM pipelines (generation, filtering, rewriting, evaluation).
- An identity lattice framework that reconciles artifact mentions across versions, subsets, datasets, and repositories, preserving uncertainty instead of forcing premature merging.
- A staged, agentic pipeline leveraging modern LLMs (Claude Code) for recursive, source-grounded disclosure extraction combined with an explicit validation phase to produce auditable dependency graphs.
Datasets
- Olmo 3 artifacts — public release datasets and model checkpoints spanning multiple upstream models, filters, and datasets — source: official releases and repositories
- Nemotron 3 Super datasets and models — public artifacts with thorough documentation — official sources
- DR Tulu dataset and model artifacts — publicly released code and papers
- SmolLM3 releases — compact open models and datasets on public repos
Baselines vs proposed
- GPT-5.5 Pro: verified dependencies = 314 vs ModSleuth (unbounded) = 1,060
- GPT-5.4 Pro: verified dependencies = 283 vs ModSleuth (unbounded) = 1,060
- Claude Code single-prompt (CC-single): verified dependencies = 275 vs ModSleuth (unbounded) = 1,060
- ChatGPT Deep Research: verified dependencies = 171 vs ModSleuth (unbounded) = 1,060
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.12385.

Fig 1: Dependencies ModSleuth surfaced: (1) DR Tulu’s SFT traces to Claude Sonnet 3.7 via

Fig 2 (page 1).

Fig 3 (page 2).
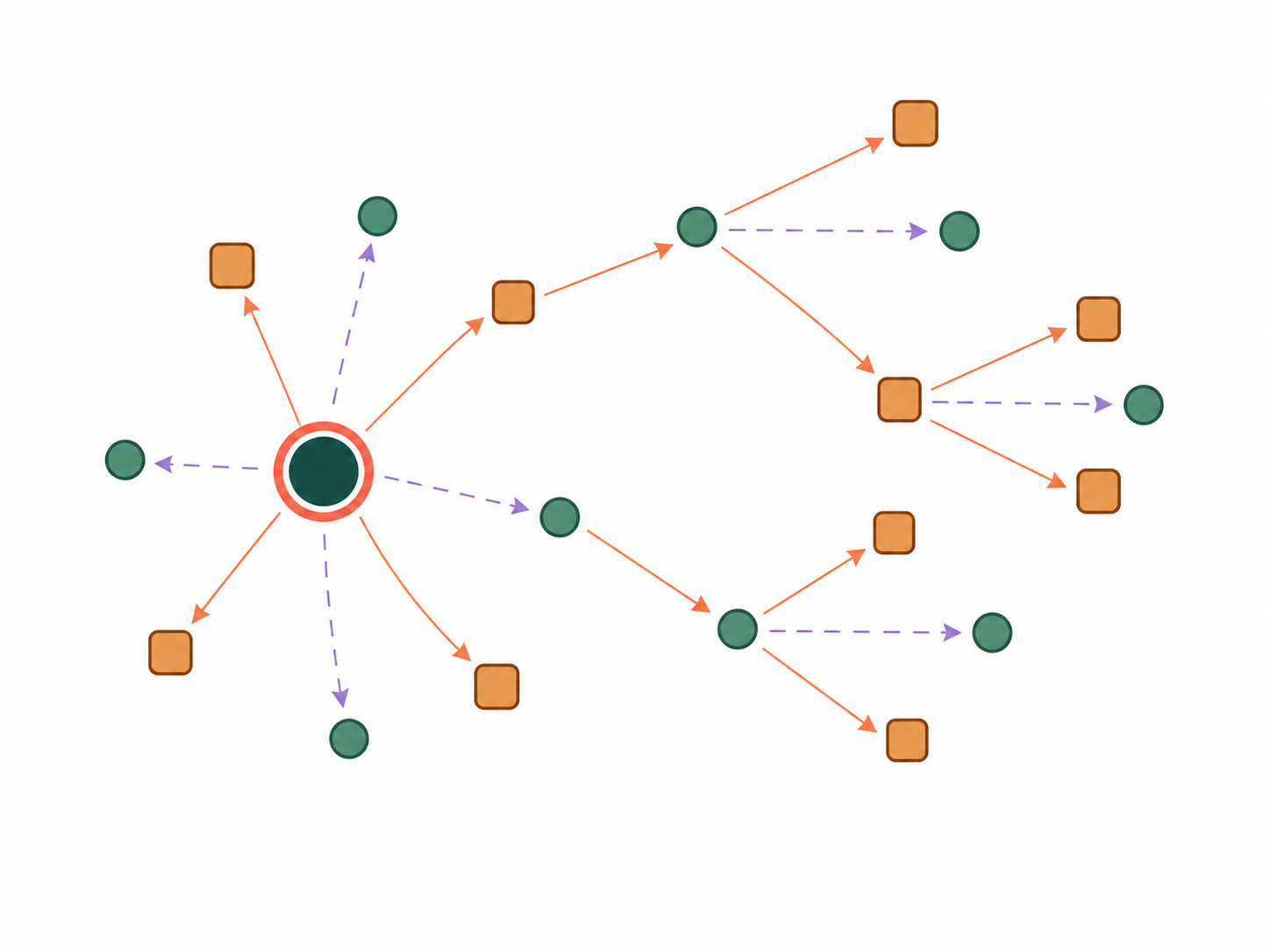
Fig 2: Overview of ModSleuth. ➊Public artifacts for the target release are gathered and organized

Fig 5 (page 5).

Fig 6 (page 5).
Fig 7 (page 5).
Fig 8 (page 5).
Limitations
- ModSleuth recovers only declared dependencies visible in public official artifacts, thus underestimating true dependency graphs.
- Recursive tracing relies on artifact documentation quality which varies: inconsistent names, incomplete versioning, and sparse metadata cause identity resolution challenges.
- Verification uses another LLM agent which may err in evidence interpretation; no independent human audit was comprehensively performed due to scale.
- No adversarial evaluation against attempts to conceal or misreport dependencies; non-declared hidden dependencies remain invisible.
- The approach assumes static artifacts at snapshot time without handling continuous or dynamic model updates.
- Results depend on availability of rich public release artifacts; closed-source models with limited documentation are outside scope.
Open questions / follow-ons
- How to detect and recover undocumented or hidden dependencies that are absent from public disclosures?
- Can behavioral or model-weight analysis methods complement declared dependency tracing to produce more complete graphs?
- How to extend ModSleuth to support continuous or incremental updates to dependency graphs as models evolve?
- What governance frameworks can effectively leverage dependency graphs for license compliance and contamination mitigation?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this work highlights the challenge that modern LLMs—and by extension, advanced adversarial automation systems—are built on complex recursive model-model dependencies that are rarely fully documented. Understanding these hidden dependency chains is critical for risk assessment, especially in areas like synthetic data contamination, evaluation bias, or license compliance. The ModSleuth framework and its formalization of direct vs indirect dependencies provide a practical foundation for systematically auditing the provenance and lineage of models that may be used in adversarial automation or in evaluating human interactions. Furthermore, the large-scale graphs and insights into the multi-hop nature of dependency propagation can inform defense practitioners on potential cascades of bias or contamination introduced upstream, which might affect the reliability of bot-detection or CAPTCHA-solving systems relying on LLM outputs. While this tool focuses on dependency auditing, its concepts may inspire designing system components that incorporate provenance checks or dependency transparency to improve robustness against adversarial misuse of complex model stacks.
Cite
@article{arxiv2606_12385,
title={ Which Models Are Our Models Built On? Auditing Invisible Dependencies in Modern LLMs },
author={ Sanjay Adhikesaven and Haoxiang Sun and Sewon Min },
journal={arXiv preprint arXiv:2606.12385},
year={ 2026 },
url={https://arxiv.org/abs/2606.12385}
}