
"That's AI Slop, You Bot!" Studying Accusations, Evidence, and Credibility in Online Discourse Towards LLM-Generated Comments
Source: arXiv:2606.12073 · Published 2026-06-10 · By Jason Miklian, John E. Katsos
TL;DR
This paper investigates the sociolinguistic dynamics and social functions of accusations that online comments are AI-generated, focusing on the rise of the pejorative label "AI slop" across millions of comments on Hacker News and Reddit from 2023 to 2026. Contrary to expectations from signaling theory, the authors find that accusations increasingly serve social gatekeeping and in-group boundary maintenance rather than accurate detection of AI-generated content. The evidence includes a 10x rise in pejorative accusation share alongside a stable or declining presence of older inauthenticity terms, sentiment shifts toward gatekeeping speech acts, and a matched-control linguistic analysis showing that prose features distinguishing actual AI text do not predict which human-written texts get accused. The findings extend signaling theory by showing that a substitute social signal for authenticity can stabilize and grow even when it fails to accurately screen for AI content. Detection technology alone cannot resolve this social policing dynamic.
Key findings
- Pejorative accusation share (Tier 2) rose from ~2% in January 2023 to ~25% by early 2026 on both Hacker News and Reddit, a more than 10x increase.
- Older inauthenticity terms (shill, astroturf, etc.) showed a flat or declining share over the same period, evidencing lexical displacement by 'AI slop'.
- LLM-validated REAL accusation rates differ by tier: Tier 2 pejorative labels achieve 72.6-78.0% REAL accuracy, far higher than direct accusations (T1) at ~33-35%.
- Sentiment analysis shows mean VADER compound score of accusations softened slightly over time (+0.21 in 2023 to +0.07 in 2026), with a rise in negative accusations below -0.3 from 16% to 28%.
- Matched-control logistic regression shows prose features distinguishing AI-generated text (contraction rate, formal adverbs, preposition density, sentence variance) do not predict which human comments are accused of being AI.
- Formal moderator enforcement of AI accusations grew from near zero in 2023 to 16.5% of accusations by 2026 on certain subreddits, indicating institutionalization.
- Across subreddits, pejorative accusation rates vary but the hierarchical order of tier label reliability is consistent, with T2 > T1 ≈ T3 > T5 > T4.
- Approximately 120,000 annualized confirmed AI accusations on Reddit and 10,000+ on Hacker News by 2026, indicating substantial scale.
Threat model
Adversaries are online community members or readers who may accuse comment authors of AI use to enforce social norms or gatekeep authenticity. They do not possess perfect detection capabilities or verifiable ground truth. The accusation mechanism operates under uncertainty, with accusers relying on heuristic, impressionistic, or social cues rather than computational AI-detection technology. The model assumes accusers cannot reliably distinguish true AI-generated prose from human-written text at scale, and the accusation does not require actual screening accuracy to function socially.
Methodology — deep read
The study collected approximately 25 million public comments (12 million Hacker News, 13 million Reddit) spanning January 2023 to May 2026. Reddit data were from Arctic Shift archive via JSON API; Hacker News from Algolia search archive. Eighteen subreddits were sampled covering AI-focused, creative, general discourse, and tech-academic communities. Comments were scanned with a regex lexicon of 137 patterns organized into five tiers capturing direct accusations (T1), pejorative labels (T2), stylistic tell calls (T3), mocking/parody phrases (T4), and indirect sense-based IDs (T5). The lexicon included context filters to reduce false positives.
A stratified sampling of 7,500 comments (5,000 Reddit, 2,500 Hacker News) balanced across tiers, time, and subreddits were annotated via LLM judgment (Claude Opus 4.7) into five categories: REAL (genuine AI accusation), DISCLOSURE (AI generated or self-identified), NEUTRAL-REF (non-accusatory AI mention), FP (false positive), and AMBIGUOUS. This enabled precision estimation per tier and platform.
A placebo lexicon of 14 pre-2022 inauthenticity terms (e.g. shill, astroturf) was applied in parallel as a falsification control.
Sentiment was computed using VADER scores aggregated monthly for LLM-validated REAL accusations. A sample of 300 Reddit accusations was speech-act coded qualitatively into five types (sneer, dismiss, mockery, gatekeep, structural protest) tracing register migration.
A matched-control test was performed on human parent comments to accusations: 421 randomly sampled accused comments with matched 2,048 non-accused controls (matched by subreddit, month, and length). Six proxy linguistic features known to distinguish AI from human text (article density, contraction rate, formal-register adverbs, preposition density, sentence-length variance, mean token length) were computed on comment texts. Logistic regression modeled probability of accusation relative to these features controlling for fixed effects.
Trend analyses used Mann-Kendall tests and regression with fixed effects. Figures and tables report time series of tier shares, lexical substitution, sentiment trajectories, tier precision rates, and regression coefficients.
The approach combines large-scale corpus analysis, LLM-assisted annotation, sociolinguistic coding, and statistical inference to examine accusation prevalence, linguistic properties, and social functions. However, the paper does not evaluate detection accuracy against ground-truth AI labels beyond LLM-based validation.
Technical innovations
- Deployment of a multi-tier regex lexicon to classify AI accusations in noisy online discourse, validated via LLM judgment to quantify precision by tier.
- Introduction of a matched-control linguistic analysis showing disconnect between statistical AI-detection features and social accusations of AI authorship.
- Application of signaling theory and enregisterment sociolinguistics to explain the rise and stabilization of 'AI slop' as a substitute authenticity signal despite low screening accuracy.
- Use of a placebo lexicon from pre-AI inauthenticity terms to falsify alternative hypotheses about general skepticism rising over time.
Datasets
- Hacker News public comments — 12 million comments (2023-2026) — Algolia HN archive
- Reddit public comments — 13 million comments (2023-2026) from 18 subreddits — Arctic Shift archive JSON API
Baselines vs proposed
- Pejorative Tier 2 accuracy: 78.0% REAL on Reddit vs Direct Tier 1 accusation: 35.1% REAL
- Tier 2 accusations on Hacker News: 72.6% REAL vs Tier 4 parody patterns: 4.8% REAL
- Mann-Kendall test on Tier 2 share: tau=0.90 (p<1e-15) Reddit, tau=0.87 (<1e-15) HN vs placebo terms declining (tau=-0.25 and tau=-0.64 respectively)
- Logistic regression odds ratio for Tier 2 vs Tier 1: OR=5.4 Reddit, OR=5.94 Hacker News (p<1e-15)
- Matched-control test: none of six linguistic proxy features significantly predict accusation status (p-values > 0.05 except mean token length p<0.001 with negative effect)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.12073.
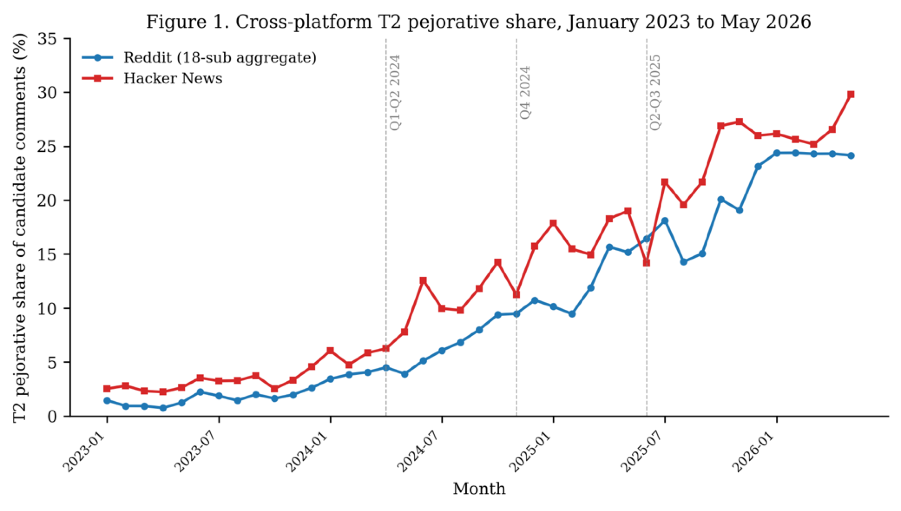
Fig 1: Cross-platform Pejorative (Tier 2) share, January 2023 to May 2026.
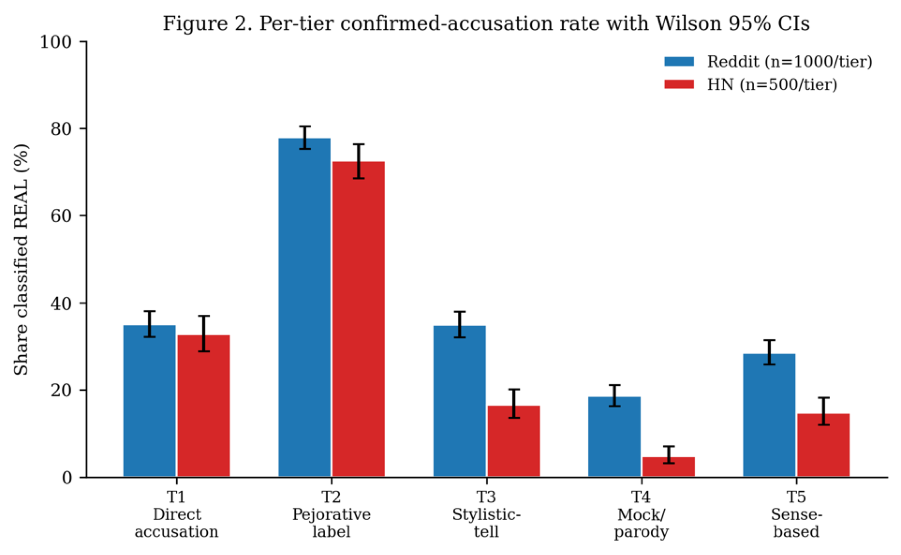
Fig 2: Per-tier REAL share on Reddit (n=1,000 per tier) and Hacker News (n=500 per tier) with
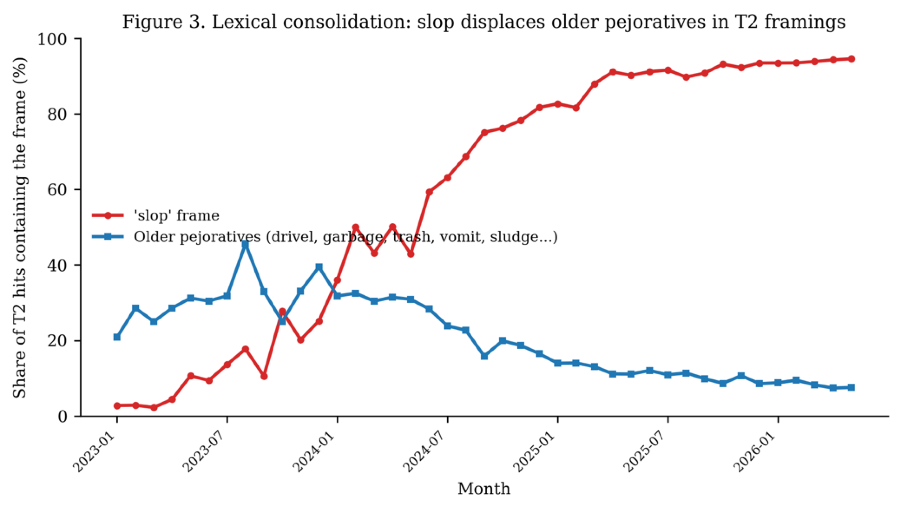
Fig 3: Lexical consolidation: slop displaces older pejoratives in Pejorative (Tier 2) framings.
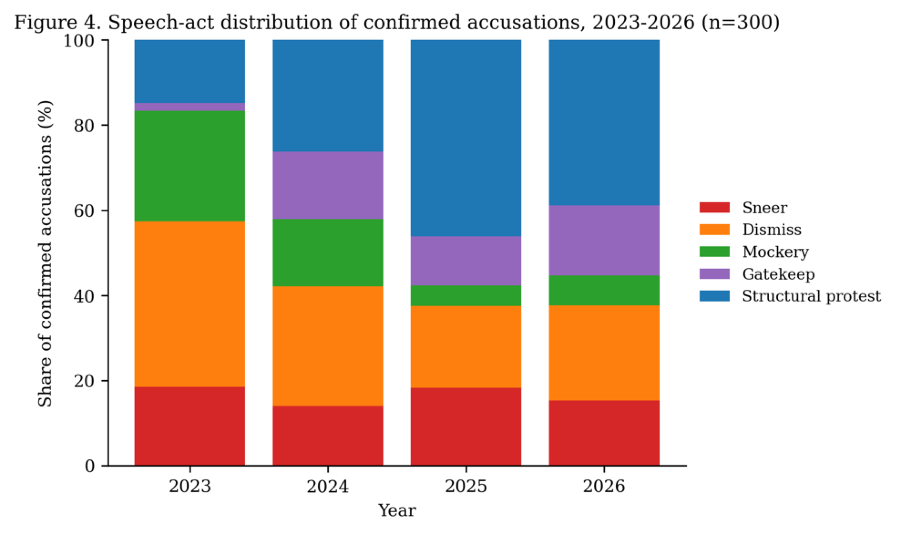
Fig 4: Speech-act distribution of confirmed accusations, 2023-2026, n=300.
Limitations
- Accusation ground truth relies on LLM judgment without human expert verification or gold-standard AI-written labels.
- Matched-control linguistic features limited to surface proxies; deeper semantic or contextual cues unexamined.
- No adversarial or experimental validation to probe causality between accusation patterns and prose features.
- Data limited to English language, specific platforms, and public comments; private forums or other languages not studied.
- Temporal lag—data until May 2026—may miss subsequent evolution of AI discourse or regulatory impacts.
- Lack of individual user-level longitudinal analysis to examine accuser or accused behavior patterns over time.
Open questions / follow-ons
- What deeper linguistic or contextual cues, beyond surface proxies, do accusers use when targeting comments as AI-generated?
- How does the social function of AI accusations interact with formal platform governance and moderation policies over time?
- Can improved explainable AI detectors modify or reduce the social gatekeeping role of accusations in online communities?
- What are the long-term impacts of AI slop discourse on epistemic injustice and trust in different online subcultures or languages?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this study illustrates that accusations of AI-generated content in online forums increasingly serve a social policing and in-group signaling role rather than a reliable screening function. Tools aimed purely at detecting AI-generated text may have limited impact on user-driven enforcement behaviors, which are shaped more by social dynamics than by textual features. Understanding this divergence is critical when designing bot-defense systems or behavioral CAPTCHAs—social signals and community norms can amplify or distort detection efforts. Consequently, defenses must consider the social ecology of accusations, recognizing that misattributed AI labels may proliferate and that false positive flagging can fuel gatekeeping conflicts. Monitoring linguistic markers alone may not be sufficient; incorporating contextual and community governance signals will likely improve synergy with social moderation practices.
Cite
@article{arxiv2606_12073,
title={ "That's AI Slop, You Bot!" Studying Accusations, Evidence, and Credibility in Online Discourse Towards LLM-Generated Comments },
author={ Jason Miklian and John E. Katsos },
journal={arXiv preprint arXiv:2606.12073},
year={ 2026 },
url={https://arxiv.org/abs/2606.12073}
}