
Nonslop: A Gamified Experiment in Human-AI Collaborative Writing
Source: arXiv:2606.12350 · Published 2026-06-10 · By Maria Edwards, Julian Togelius
TL;DR
This paper explores human-AI collaborative writing through a gamified experiment called Nonslop, which inverts the common AI-writing assistant paradigm by explicitly discouraging users from accepting AI-generated word suggestions. The goal is to reveal authentic user preferences and the tradeoff between creative autonomy and efficiency when AI suggestions are available but penalized. Using 74 participants and 214 valid text responses to various writing prompts, the study analyzes how often and under what conditions users attempt to incorporate AI suggestions despite disincentives. It also clusters user behavior and examines prompt characteristics influencing AI adoption.
The key novelty is the game framing where AI suggestions are forbidden or discouraged, making acceptance of them an explicit transgression and revealing nuanced human decision-making around co-creation with language models. The results show that most submissions (73.8%) had no attempts to use AI suggestions, indicating users preferred creative autonomy when given an incentive to avoid AI influence. However, prompt category mattered: explanatory prompts elicited the most AI adoption, while creative and observational prompts led to minimal AI use. The study also identifies three behavioral clusters of users, ranging from minimal adopters to active adopters of AI-suggested words. These findings suggest that AI adoption in writing is shaped by social incentives, task type, and individual user strategies.
Key findings
- 73.8% of submissions contained no attempts to use AI-suggested words despite their availability.
- Only 7.5% of submissions contained attempts to use more than one AI-suggested word.
- User clustering revealed three groups: Minimalists (72% users, avg. 2.17 responses, 0.28 AI attempts, 9.11 words), Selective adopters (16%, 3.25 responses, 2.08 attempts, 40.8 words), and Active adopters (11%, 7.25 responses, 6.13 attempts, 14.77 words).
- Explanatory prompts had the highest average AI adoption attempts per submission at 0.791, over six times that of creative prompts at 0.118.
- Prompts with more user submissions tended to have lower AI adoption transgressions (correlation r = -0.261).
- The AI evaluation scoring used GPT-4o-mini with a 0 temperature, scoring 1) relevance, 2) grammar, and 3) coherence on a 5-point scale each, combining for a total score out of 15.
- Technical constraints prevented about 53% of users from participating due to Web-LLM requirements (WebGPU, browser support).
- The game design successfully made AI suggestion adoption an explicit, penalized behavioral choice rather than a default.
Threat model
The adversary is a dystopian AI entity seeking to learn from human individuality through writing, attempting to coax users into adopting AI-generated text. Users know AI suggestions are available but are incentivized or forced not to accept them. The adversary cannot forcibly insert AI-generated words without user transgression—accepting AI suggestions is an explicit rule violation and a deliberate behavioral choice by the user.
Methodology — deep read
The study's threat model involves a user interacting with a local language model suggesting next words in real-time as they write responses to prompts, while an adversarial AI lurks in the narrative as a dystopian overseer trying to learn human individuality. The user is explicitly disincentivized or prevented from accepting AI suggestions, making acceptance a rule violation rather than an encouraged behavior.
The data consists of 214 filtered valid free-text submissions from 74 unique participants collected via a web game. The prompts varied by qualitative difficulty levels and task types (creative, observational, personal, philosophical, explanatory). Users chose between easy mode (penalties displayed but AI suggestions can be used) and hard mode (AI suggestion use blocked). Both modes were combined for analysis as results did not differ significantly.
The architecture used two LLMs: a local Qwen 2.5 0.5B Instruct model running in-browser via Web-LLM generated top-5 next-word suggestions at each whitespace, filtered to exclude stopwords. The most probable next word was displayed as an autocomplete suggestion and in a UI above the input field. The high LLM-capacity GPT-4o-mini-2024-07-18 was used post-submission to score responses on relevance, grammar, and coherence (each 0-5 scale) with temperature 0 for reproducibility.
The training regime was not applicable as models were pre-trained; instead the experiment ran live user inference in browser. A significant portion of attempted users (162 out of 303) failed to run the local LLM due to WebGPU or browser restrictions.
Evaluation metrics included counting attempts by users to violate AI-suggestion restrictions (i.e., whether users tried to type AI predicted words), response length, and AI-assigned scoring. Statistical analysis included descriptive statistics, k-means clustering on user features (number of submissions, AI attempts, average response length), prompt-level correlation analysis, and categorical prompt grouping by task type.
This methodology allows granular observation of micro-decisions users make when AI assistance is discouraged rather than encouraged. However, no adversarial users or distribution shifts were explicitly tested. The source code and models are partly dependent on Web-LLM and OpenAI APIs; reproducibility is limited due to closed data and technical constraints of browser-based inferences.
As a concrete example, a user in hard mode responding to an explanatory prompt would see AI next-word predictions while typing but cannot accept them without penalty or rejection. Their attempts to incorporate suggested words count as 'transgressions' signaling a choice for efficiency over game-imposed creative autonomy. Post-submission, their text earns a score from GPT-4 based on grammaticality, relevance, and coherence. Patterns of such transgressions across users, prompts, and response length form the dataset for the behavioral analyses.
Technical innovations
- A gamified human-AI writing experiment design that explicitly discourages AI suggestion acceptance, reversing typical 'helpful assistant' paradigms.
- Use of a local browser-executed LLM (Qwen 2.5B) for real-time next-word prediction combined with a high-capacity LLM (GPT-4o-mini) for post-hoc automated scoring within a game narrative.
- Behavioral clustering of users based on submission frequency, AI-suggestion adoption attempts, and response length to reveal distinct writing strategies under AI disincentive.
- Categorical analysis linking prompt task type with rates of AI suggestion adoption, providing insights into task-dependent human-AI co-creation dynamics.
Datasets
- Nonslop user submissions — 214 valid text responses — collected via web-based gamified experiment with 74 unique users (non-public)
Baselines vs proposed
- Easy mode (AI suggestion use penalized but allowed): no significant difference in AI adoption rates compared to hard mode (AI suggestion use blocked).
- Minimalist users (largest cluster): avg. 2.17 responses, 0.28 AI adoption attempts; Selective adopters: 3.25 responses, 2.08 AI attempts; Active adopters: 7.25 responses, 6.13 AI attempts.
- Explanatory prompts: avg. AI adoption attempts = 0.791 per submission; Creative prompts: 0.118.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.12350.

Fig 1: Initial game introduction and interface.
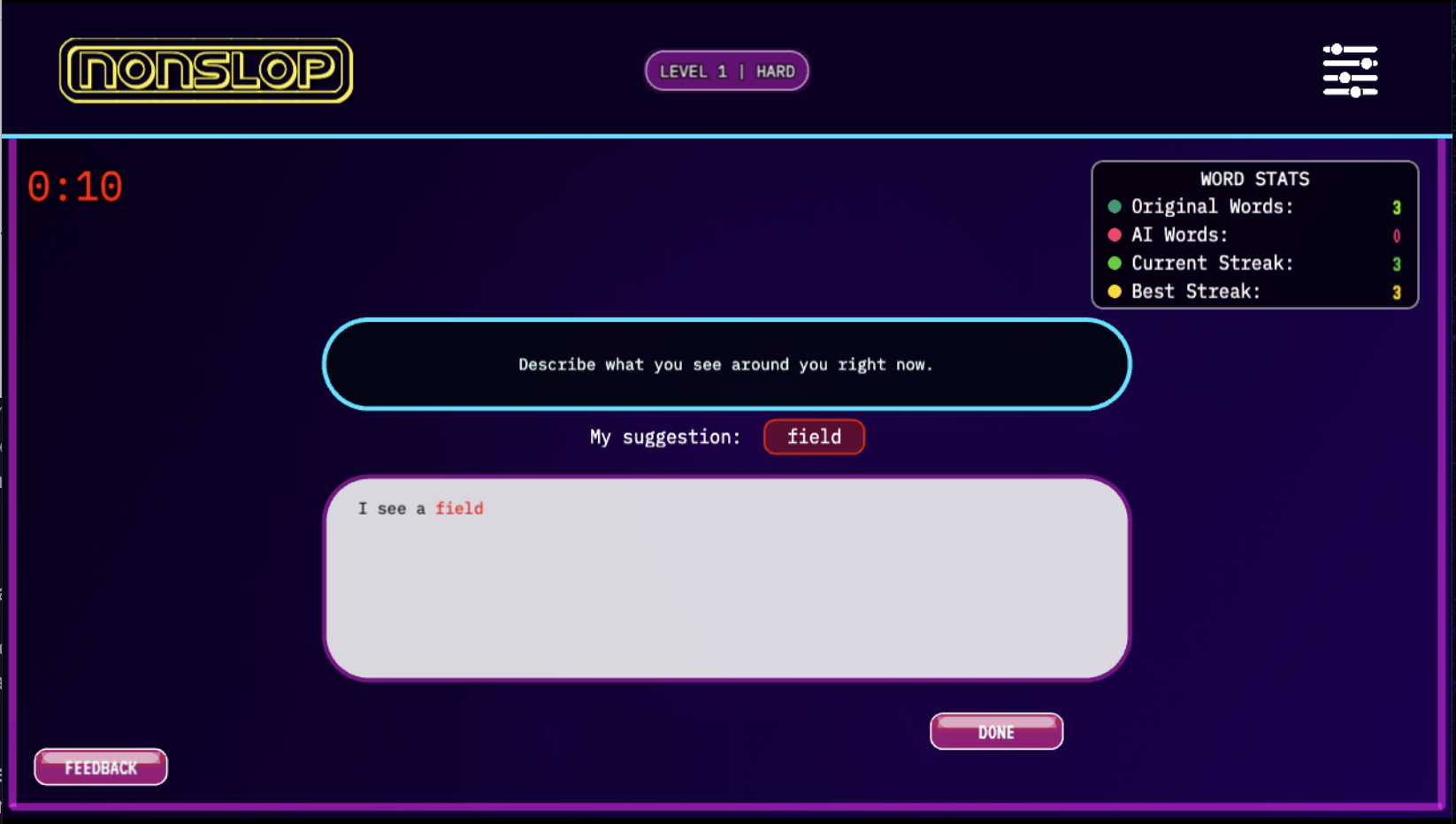
Fig 2: Main game interface for Nonslop. Users respond to a prompt by
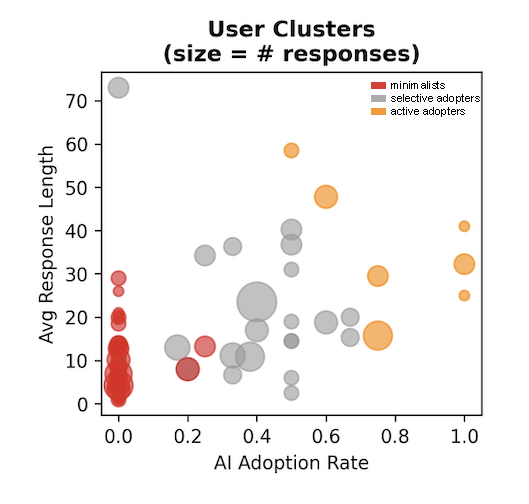
Fig 3: Visualization of the three user clusters derived from k-means
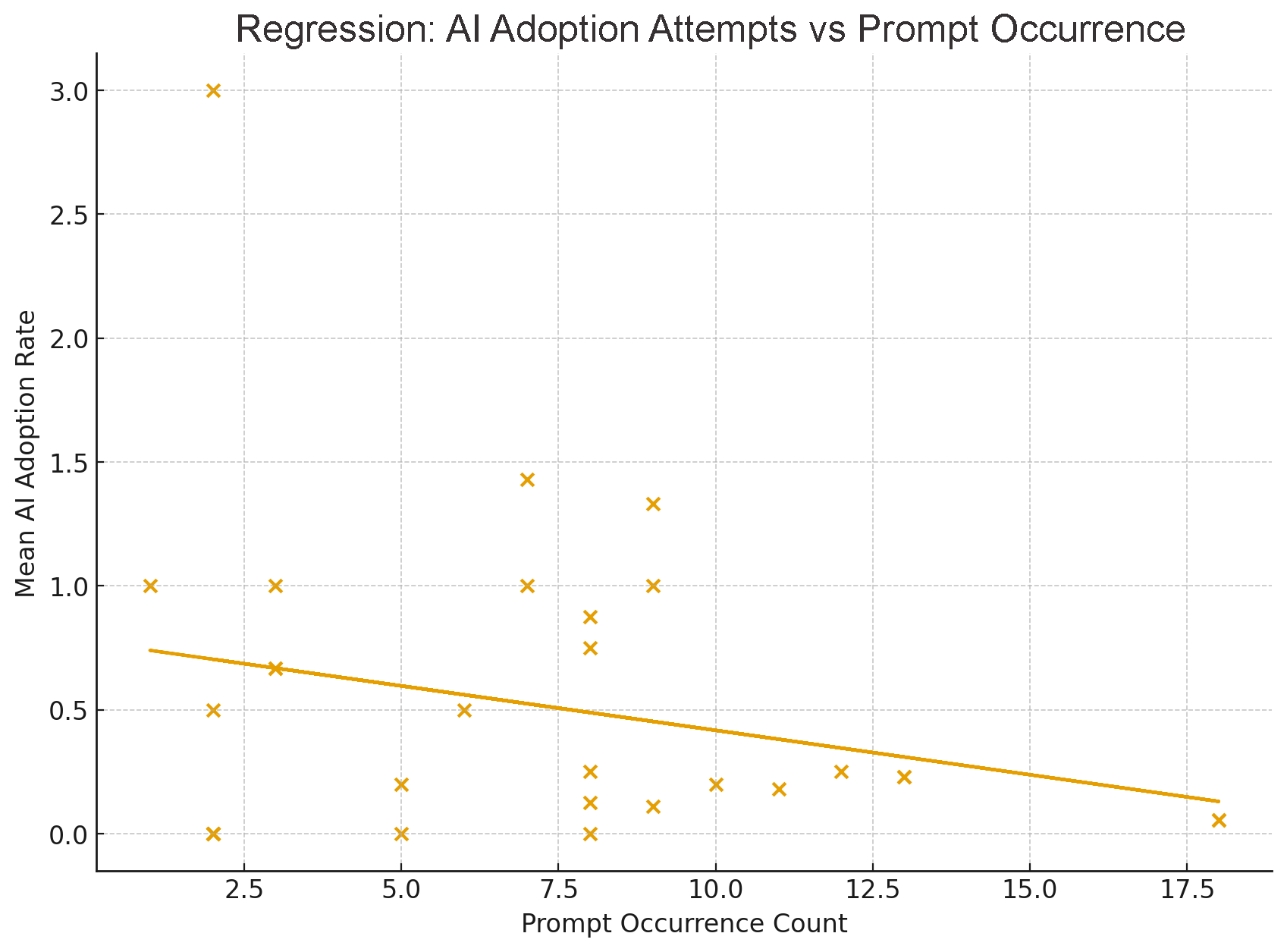
Fig 4: Prompt-level comparison of the number of submissions per prompt
Limitations
- Sample skew due to 53% of attempted users failing to load the game caused by WebGPU/browser restrictions, limiting generalizability.
- Short response lengths and limited session repeat data restricted understanding of longitudinal behavior change.
- In-browser inference delays may have affected user experience and engagement, possibly biasing participation.
- LLM-based scoring is imperfect, sometimes missing grammar errors or overcorrecting, limiting evaluation reliability.
- Small post-playtest survey sample (7 participants) limits insights into user perceptions.
- No explicit adversarial or robustness testing of user strategies under attack scenarios.
Open questions / follow-ons
- How do user strategies and AI adoption patterns evolve over multiple sessions or longer-term engagement?
- Can interface design variations (e.g., different incentive structures, or partial encouragement of AI use) modulate adoption rates and creative autonomy differently?
- How do different genres or domains beyond the five prompt categories affect AI suggestion acceptance?
- Can more nuanced automated evaluation metrics better capture the quality and creativity of human-AI co-written text under these disincentives?
Why it matters for bot defense
From a bot-defense or CAPTCHA perspective, this work provides a sophisticated example of how gamification and rule-based constraints can surface subtle human decision patterns in the presence of automated assistance. While focused on creative writing, the behavioral segmentation and prompt-dependent variation in AI suggestion adoption illustrate how user interactions with machine-generated content can reveal underlying intent, autonomy, or resistance. This suggests that introducing explicit costs or penalties to automated assistance in security interaction designs (like CAPTCHAs) may enable clearer differentiation between human agency and automated or scripted responses, helping detect bots relying on AI completions.
Furthermore, the cluster analysis framework and prompt categorization could analogously inform adaptive CAPTCHA difficulty or challenge style selection based on observed user behaviors, improving robustness against AI-augmented bots. The gamified and narrative elements highlight the potential of friction and incentive reshaping to elicit meaningful behavioral signals beyond typical correctness or response timing, which could enrich bot-detection feature sets.
Cite
@article{arxiv2606_12350,
title={ Nonslop: A Gamified Experiment in Human-AI Collaborative Writing },
author={ Maria Edwards and Julian Togelius },
journal={arXiv preprint arXiv:2606.12350},
year={ 2026 },
url={https://arxiv.org/abs/2606.12350}
}