
Measuring Semantic Progress in Multi-turn Dialogue via Information Gain
Source: arXiv:2606.12332 · Published 2026-06-10 · By Paul He, Shiva Kasiviswanathan, Dominik Janzing
TL;DR
This paper addresses the challenging problem of evaluating multi-turn information-seeking dialogues, focusing on the dimension of semantic progress: the accumulation of new, relevant, and non-redundant information across a conversation. The authors formalize semantic progress as question-conditioned uncertainty reduction about a latent task-relevant semantic state. They propose a novel, efficient, training-free metric based on Gaussian information gain computed in embedding space that approximates this uncertainty reduction. This approach yields a deterministic, reference-free dialogue-level score with desirable theoretical properties including monotonicity, additive decomposition, and diminishing returns for redundant evidence. Unlike costly LLM-as-a-judge methods, this metric avoids autoregressive inference, is reproducible, and can run on CPU with lightweight embedding models.
Experiments on three human preference benchmarks—MT-Bench, Chatbot Arena, and UltraFeedback—show that the Gaussian information gain metric achieves high agreement with human judgments (84.03% on MT-Bench, 71.64% on UltraFeedback), competitive with or surpassing several LLM-based judges, while being 3-10x faster. Ablations demonstrate robustness to embedding model size and reveal that the covariance-based uncertainty reduction component is critical for performance beyond simple embedding similarity. Overall, the method offers a scalable complementary signal to holistic evaluators for semantic progress in information-seeking dialogue.
Key findings
- GAUSSIANIG achieves 84.03% agreement on MT-Bench, 65.80% on Chatbot Arena, and 71.64% on UltraFeedback with human preference labels.
- Relative to LLM-as-a-judge baselines, GAUSSIANIG reduces evaluation runtime by 3-10 times (e.g., 86s vs 132-633s on MT-Bench for 100 dialogue pairs).
- The metric preserves structural properties such as monotonicity (no decreases in score when adding evidence) and diminishing returns (submodularity) for redundant information (Theorems 2, 3).
- Embedding backend ablation shows stable performance across models from 2 million to 4 billion parameters, indicating saturation of semantic directions in embedding space (e.g., Potion-2M model achieves 80.25% on MT-Bench).
- A cosine-similarity-only ablation obtains only 44.5% agreement, far below GAUSSIANIG’s 84.0%, demonstrating that covariance updates and redundancy discounting are essential.
- Score increases substantially with addition of novel relevant evidence but is minimally affected by irrelevant or redundant padding, indicating sensitivity to question-relevant information rather than length.
- Adjusting weighting parameters β and cutoff η for question relevance tunes sensitivity to hallucinated or irrelevant content, with moderate β=1 and η=0.05 already outperforming chance.
- The method requires no retraining or fine-tuning, relying instead on fixed embedding encoders and closed-form Gaussian precision updates.
Threat model
Not a security-focused paper; threat model is implicit, assuming an information-seeking dialogue setting where the agent must provide relevant, non-redundant semantic evidence to reduce user uncertainty. The adversary could be a dialogue system producing irrelevant, redundant, or hallucinated information, but no explicit adversarial capabilities or attacks on the metric are modeled.
Methodology — deep read
Threat Model & Assumptions: The adversary is implicit rather than explicit; the scenario assumes information-seeking dialogues where an agent provides answers to user questions, and the metric evaluates agent-induced semantic progress. The adversary could be a flawed system that provides irrelevant or redundant information, but no explicit adversarial robustness testing is performed.
Data: Evaluation is conducted on three public benchmarks - MT-Bench and Chatbot Arena providing paired dialogue comparisons with human preference votes, and UltraFeedback offering scored responses across multiple quality dimensions. Only examples with non-tied preference labels are used, covering a realistic range of information-seeking dialogues.
Architecture/Algorithm: The core is a Gaussian information gain estimator in embedding space. Each dialogue turn’s answer is segmented into evidence units (e.g., sentences), separately embedded (enc). A latent semantic uncertainty variable S ~ N(0, Σ_0) models unresolved semantic aspects. Each evidence embedding acts as a linear measurement of S, weighted by question relevance computed from cosine similarity to the question embedding q and optionally a quality factor rqual (set to 1 here).
Training Regime: No training; the method is training-free and fully deterministic. Parameters σ_0, σ (noise variance), and relevance weighting parameters β, η are set heuristically. Embeddings are computed with various pretrained encoders, some lightweight (2M params) and others larger (up to 4B).
Evaluation Protocol: Dialogue-level semantic progress score is computed as the sum over turns of per-turn Gaussian information gains (log-det change of posterior covariance). Metrics are agreement rate with majority human preference label and Kendall’s τ rank correlation. Compared against multiple LLM-as-a-judge baselines executed with zero temperature via hosted APIs. Ablations test embedding models, relevance weighting parameters, length padding effects, and a cosine-only baseline. Runtime is measured on fixed subsets to assess operational cost.
Reproducibility: The evaluation code, embedding models, and benchmarks are public or standard. The method is fully deterministic given fixed embeddings and hyperparameters, and requires no retraining or autoregressive inference. Raw data and detailed algorithmic pseudocode provided in appendices. Some computations rely on standard Gaussian linear algebra updates.
Example end-to-end: For a 5-turn dialogue, each answer is broken into sentences, each sentence embedded to a vector z_t,i. The question at that turn is embedded as q_t. Each z_t,i is assigned a relevance weight from cosine similarity max(0, <q_t, z_t,i>)^β thresholded by η. These weighted vectors update the precision matrix J_t = J_{t-1} + sum_i (weight / σ^2) z_t,i z_t,i^T. The per-turn info gain is 0.5 * log det(J_t) - log det(J_{t-1}), summed across turns. The resulting score ranks dialogue-level semantic progress by uncertainty reduction over latent S.
Technical innovations
- Formalization of semantic progress in dialogue as question-conditioned uncertainty reduction modeled by information gain on a latent Gaussian embedding space representation.
- Derivation of a closed-form, training-free Gaussian estimator for semantic progress using weighted precision matrix updates from embedding-space evidence.
- Theoretical guarantees of monotonicity, additive telescoping across dialogue turns, and submodularity (diminishing returns) for evidence accumulation.
- Demonstration that second-order embedding statistics with Gaussian maximum entropy approximation provide an interpretable, efficient dialogue-level semantic progress metric distinct from autoregressive LLM evaluators.
Datasets
- MT-Bench — Hundreds of info-seeking dialogue pairs with human preference labels — Public benchmark
- Chatbot Arena — Paired dialogue comparisons with crowd human votes — Public benchmark
- UltraFeedback — Diverse scored responses across multiple dialogue quality dimensions — Public benchmark
Baselines vs proposed
- Mistral Large 3: MT-Bench agreement 76.50% vs GAUSSIANIG 84.03%
- DeepSeek R1: UltraFeedback agreement 71.43% vs GAUSSIANIG 71.64%
- GPT OSS 120b: Chatbot Arena agreement 65.27% vs GAUSSIANIG 65.80%
- Claude Sonnet 4: MT-Bench agreement 81.93% vs GAUSSIANIG 84.03%
- Cosine-only baseline: MT-Bench agreement 44.5% vs GAUSSIANIG 84.0%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.12332.
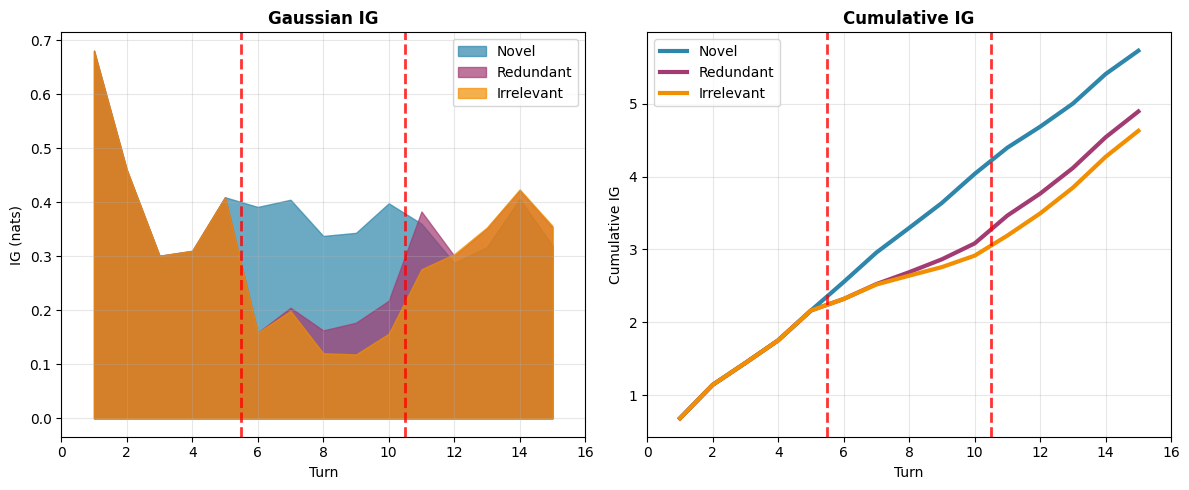
Fig 3: Information gain distinguishes dialogue quality in a 15-turn synthetic setting. We compare
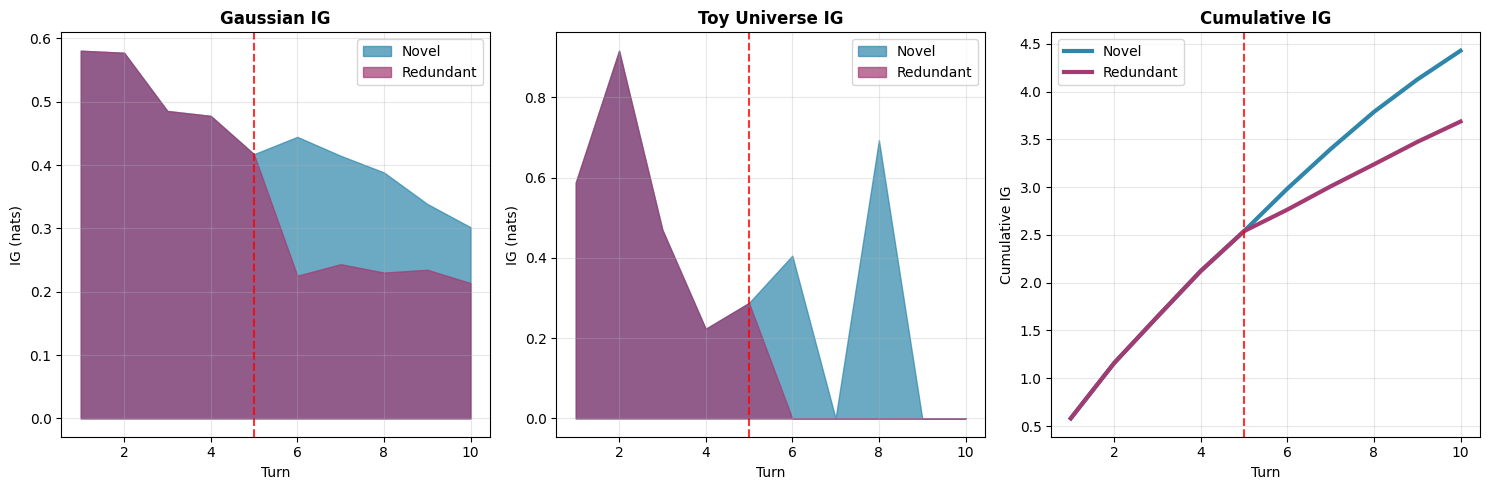
Fig 4: Toy example with the city guessing universe. The LLM tries to guess a city by asking
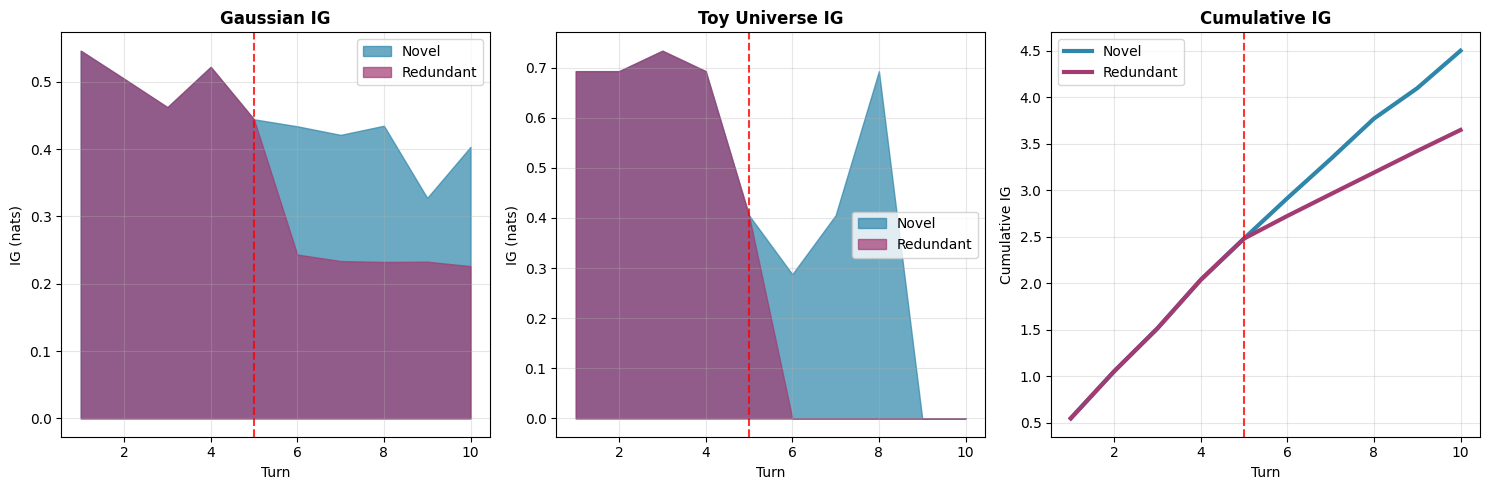
Fig 5: Toy example with the movie guessing universe. The LLM tries to guess a movie by asking
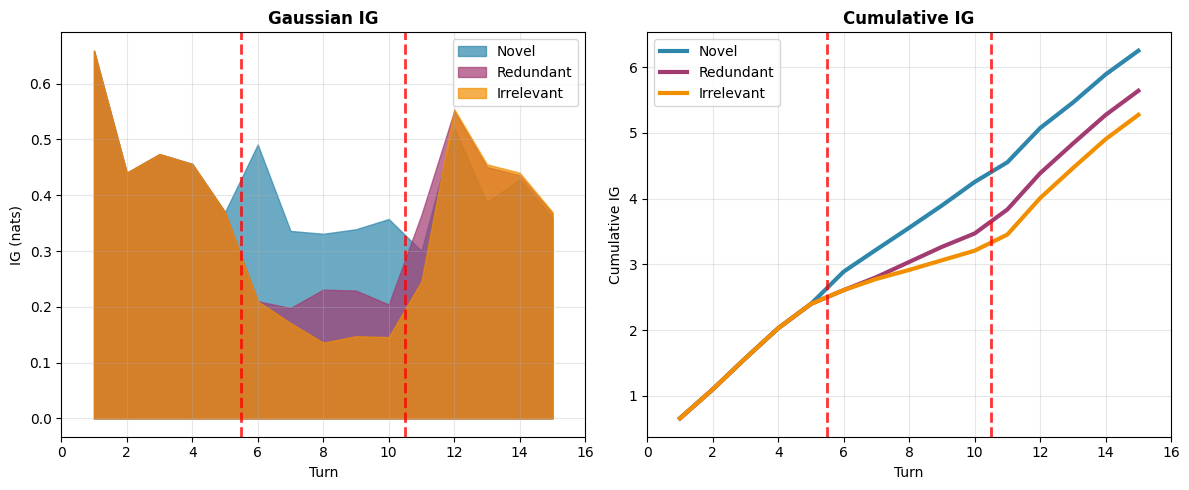
Fig 6: Toy example where the user asks open questions for advice related to gardening. The
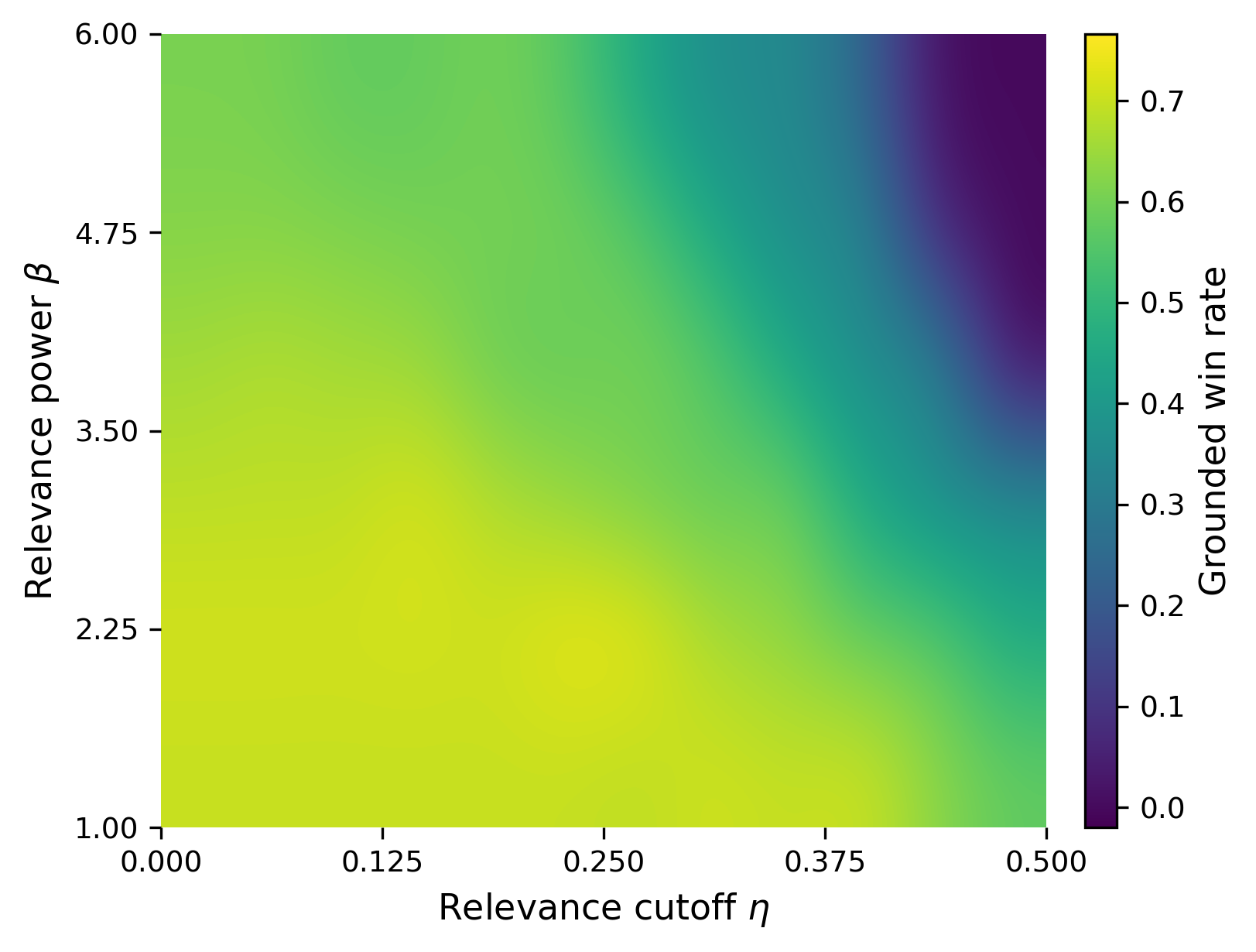
Fig 7: Sensitivity of grounded win rate to the relevance cutoff η and weighting exponent β in the
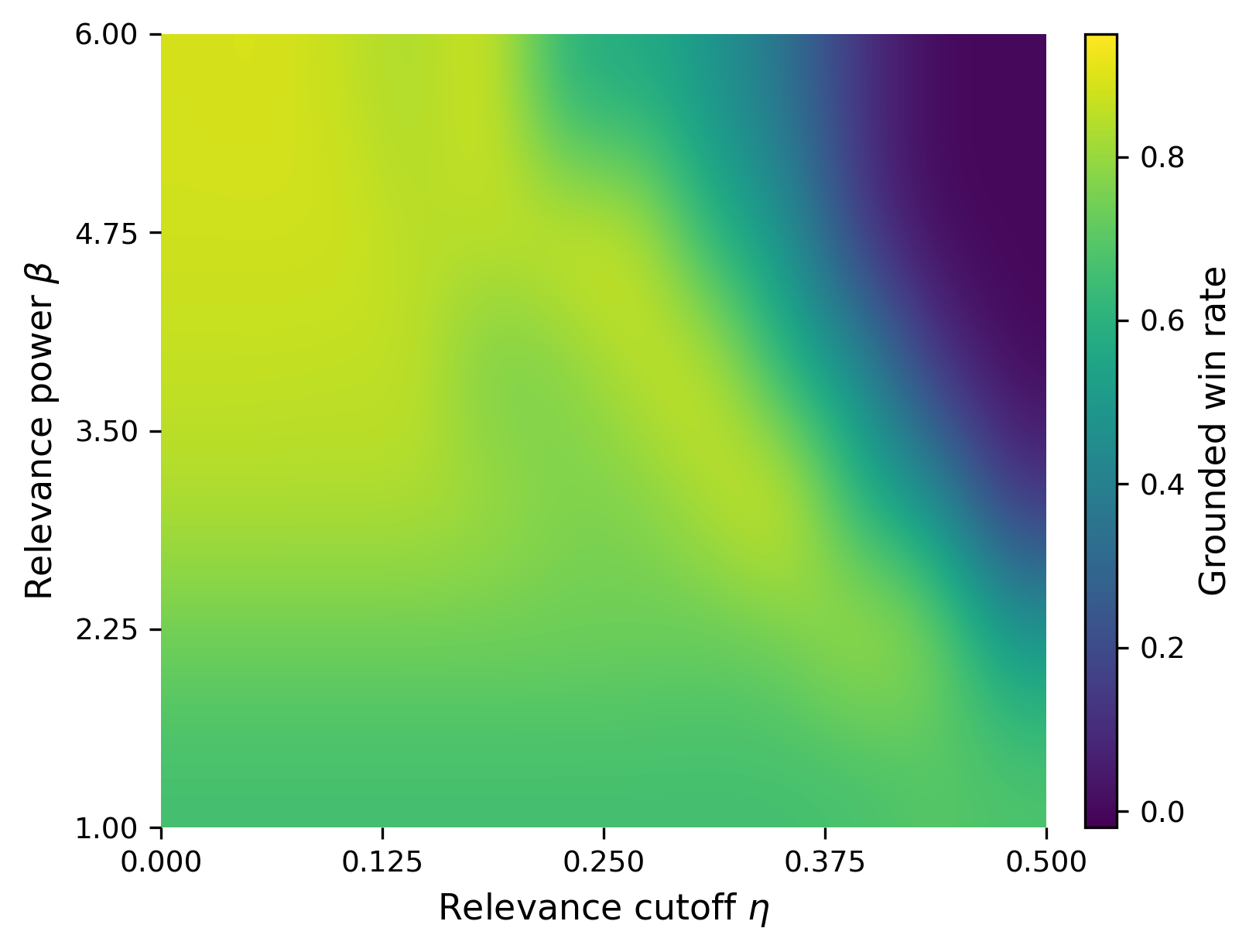
Fig 6 (page 25).
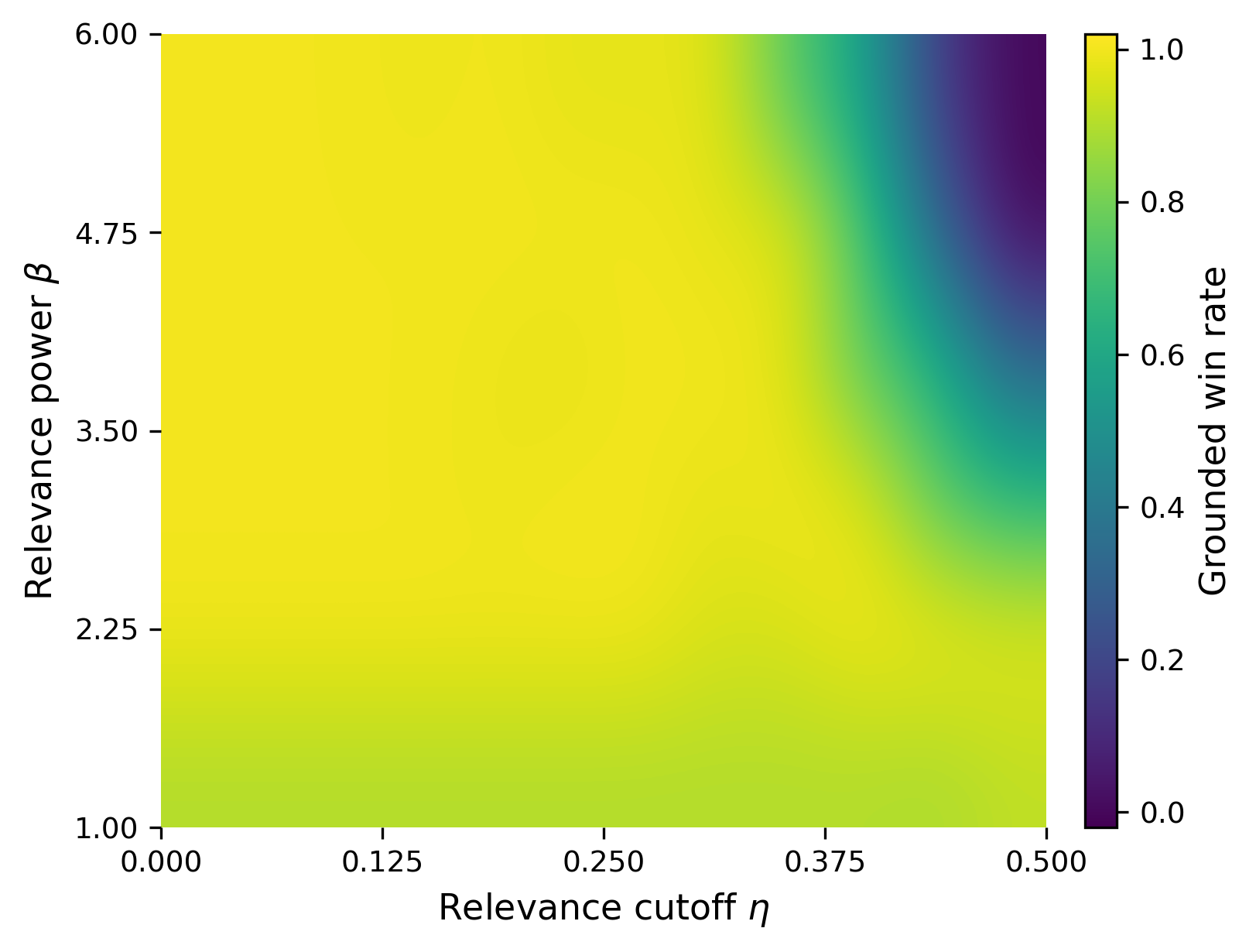
Fig 7 (page 25).
Limitations
- Focuses solely on semantic progress dimension; does not evaluate factuality, coherence, safety, style, or user satisfaction.
- Relies heavily on the quality of the fixed embedding model and evidence extraction; embedding choice affects results.
- Does not include explicit adversarial or out-of-distribution robustness testing against malicious or highly noisy inputs.
- The latent Gaussian assumption and second-order covariance approximation may obscure finer semantic nuances beyond linear embedding structure.
- No user-in-the-loop or in-application feedback validation; only evaluated against static human preference benchmarks.
- Calculations require careful tuning of relevance weighting parameters (β, η) which affect sensitivity and may be dataset-dependent.
Open questions / follow-ons
- How to integrate semantic progress metrics with complementary signals assessing factuality, coherence, and safety for more holistic dialogue evaluation?
- Can the underlying embedding space and evidence extraction be optimized or adapted for better capture of semantic uncertainty and progress?
- What is the robustness of the metric under adversarially crafted dialogues containing misleading or contradictory information?
- How does semantic progress scoring perform in more open-ended or creative dialogues beyond strict information-seeking scenarios?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this work offers a principled and efficient approach to measuring meaningful information accumulation across multi-turn interactions without resorting to costly LLM-based evaluations. In the bot-defense context, understanding semantic progress can help distinguish between genuine user queries that seek incremental knowledge versus automated bots that produce redundant or irrelevant responses. The proposed Gaussian information gain metric could be incorporated into evaluation pipelines to monitor dialogue system quality at scale, flagging conversations that lack true semantic advancement indicative of human-like engagement. Furthermore, the lightweight embedding-based formulation enables deployment in resource-constrained environments or real-time monitoring, avoiding latency and cost challenges of large autoregressive models. However, as it focuses narrowly on semantic progress without assessing safety or factual correctness, it should be combined with complementary evaluators when detecting malicious or low-quality interactions. Overall, this metric expands the toolkit for scalable dialogue-level evaluation by offering a rigorous, theoretically grounded signal directly tied to information-seeking efficacy rather than fluency or style.
Cite
@article{arxiv2606_12332,
title={ Measuring Semantic Progress in Multi-turn Dialogue via Information Gain },
author={ Paul He and Shiva Kasiviswanathan and Dominik Janzing },
journal={arXiv preprint arXiv:2606.12332},
year={ 2026 },
url={https://arxiv.org/abs/2606.12332}
}