
MATLAB-Based Layerwise Self-Adaptive Physics-Informed Neural Network in Applications to Multidimensional Coupled Burgers' Equations with High Reynolds Numbers
Source: arXiv:2606.12348 · Published 2026-06-10 · By Harish P. Bhatt, Xi Chen, Jingsai Liang
TL;DR
This paper addresses the challenge of accurately simulating multidimensional coupled Burgers' equations (MCBEs) at high Reynolds numbers, where sharp shock fronts and steep gradients develop over time. Traditional mesh-based numerical methods such as finite differences and finite elements struggle due to stability issues and extensive mesh dependency near shocks. The authors present an enhanced physics-informed neural network (PINN) framework implemented in MATLAB, incorporating a novel layerwise self-adaptive weighting strategy that dynamically adjusts penalty weights for the PDE residual, initial conditions, and boundary conditions during training. The framework also adopts a dual-phase optimization combining Adam and L-BFGS optimizers for more stable and accurate convergence.
Through extensive numerical experiments on 1D, 2D, and 3D variants of the coupled Burgers’ equations with high Reynolds numbers, the proposed LSAAL-PINN consistently outperforms standard PINNs trained with Adam only and those with Adam plus L-BFGS but without adaptive weighting. Results demonstrate significantly lower relative L2 error norms and better capture of shock formation, highlighting the benefit of the self-adaptive weighting and hybrid optimization. This study advances PINN methodologies for solving stiff, nonlinear PDEs with sharp dynamics, providing a continuous, mesh-free solution approach implemented and validated within MATLAB.
Key findings
- LSAAL-PINN achieves a relative L2-error of 1.79e-4 in the 1D Burgers' equation after 7000 iterations, compared to 3.10e-4 for AL-PINN and 8.65e-3 for A-PINN (Fig. 3).
- For 2D coupled Burgers' equations at Reynolds number 10,000 (ν=0.0001), LSAAL-PINN is about 8x more accurate than AL-PINN and roughly 1385x more accurate than A-PINN after 7000 runs (Fig. 6).
- In 3D CBEs with Re=3, LSAAL-PINN obtains the lowest L2 errors across time and variables u,v,w compared to baseline PINNs (Fig. 9).
- Hybrid dual-phase optimization (Adam followed by L-BFGS) combined with layerwise self-adaptive weighting yields more consistent and steadier loss decay than Adam-only or Adam+L-BFGS without adaptive weights (Figs. 5, 8, 10).
- The self-adaptive weighting dynamically balances loss components for PDE residual, initial and boundary conditions, preventing dominance of any single term during training.
- LSAAL-PINN captures sharp shock fronts and steep solution gradients in Burgers' equations better than standard PINNs, which produce oscillations or fail to converge accurately.
- The method uses well-distributed collocation points via Latin Hypercube Sampling to enhance training in transition regions with steep gradients.
- The MATLAB implementation shows feasibility of PINNs with automatic differentiation on an Apple M3 Pro chip with reasonable training configurations and iteration counts.
Threat model
The adversary is a computational scientist or engineer attempting to solve PDEs with high Reynolds number effects where sharp shock fronts and stiff nonlinear convection-diffusion terms make classical numerical methods and vanilla PINNs ineffective due to instability, oscillations, or poor convergence. The adversary's capabilities include access to the PDE formulation, specifying initial and boundary conditions, and computational resources to train deep neural networks. They cannot directly manipulate the physics or introduce mesh-based discretization refinements without substantial computational cost. The challenge is to create a framework that can robustly learn accurate solutions without excessive tuning or mesh dependency.
Methodology — deep read
The threat model is an adversary in numerical simulation seeking an efficient, accurate PDE solver that can handle stiff nonlinearity and shocks without mesh refinement or oscillations. The adversary does not have access to additional data but relies on solution smoothness and computational efficiency.
Data provenance consists of synthetically generated collocation points for the PDE residual, initial condition points, and boundary condition points across 1D, 2D, and 3D domains matching Burgers' equations with high Reynolds numbers. Points are sampled via Latin Hypercube Sampling to ensure uniform coverage including critical transition regions with steep gradients. Typically, datasets include thousands of collocation points (e.g., 5000 to 8500 PDE points) and hundreds to thousands of IC and BC points.
The core architecture is a feedforward fully-connected deep neural network with six hidden layers and 32 neurons per layer, using tanh activation to maintain smooth differentiability for PDE derivatives. Input is spatial coordinates plus time (d+1 dimension), output is the predicted velocity component(s). Weights and biases are initialized with Xavier initialization.
The loss function is a weighted sum of three components: PDE residual loss (enforcing Burgers' PDE), initial condition loss, and boundary condition loss. Critically, a layerwise self-adaptive weighting strategy learns the penalty weights λ_PDE, λ_IC, and λ_BC dynamically at each training iteration via gradient ascent on λ to balance these terms and prevent any dominating.
Optimization uses a dual-phase scheme: phase one updates NN parameters θ via Adam optimizer while simultaneously updating weights λ by gradient ascent on loss w.r.t λ. After specified iterations, λ weights are fixed and phase two refines θ using L-BFGS, a second-order quasi-Newton method, for loss convergence. This stabilizes training and avoids local minima.
Evaluation uses relative L2 error norms comparing the predicted solution to analytical or highly accurate reference solutions over multiple time snapshots. Experiments are conducted on 1D, 2D, and 3D coupled Burgers' equations with varying Reynolds numbers (up to 100). Performance is measured against two baselines: a standard PINN with Adam only (A-PINN) and one with Adam plus fixed-weight L-BFGS (AL-PINN).
Reproducibility is aided by MATLAB 2025a implementation using the deep learning toolbox for automatic differentiation, executed on readily available Apple M3 Pro hardware. However, no public code or datasets are linked in the preprint. Parameters such as network depth/width, learning rate, and iteration counts are provided explicitly. The training setup and hyperparameters are systematically described allowing reproduction.
As a concrete example, the 1D Burgers' equation is solved using a 6-layer, 32-neuron network with 5000 PDE points, 400 initial, and 200 boundary points. The dual optimizer scheme runs 5000 Adam iterations updating θ and λ together, followed by 2000 L-BFGS iterations refining θ with frozen λ. The final solution predicts shock formation with relative L2 error 1.79e-4, significantly superior to baselines.
Overall, the methodology combines an adaptive penalty weighting scheme integrated tightly into PINN training, leverages two-phase gradient-based optimizers, and leverages MATLAB's AD for computing derivatives of complex nonlinear PDE residuals in multi-dimensional domains with high Reynolds number effects.
Technical innovations
- Introduction of a layerwise self-adaptive weighting strategy to dynamically balance losses for PDE residuals, initial, and boundary conditions during PINN training.
- Use of a dual-phase optimization scheme combining first-order Adam updates with gradient ascent for weight parameters, followed by second-order L-BFGS refinement on fixed weights.
- Application of the combined adaptive weighting and hybrid optimization strategy to multidimensional coupled Burgers' equations with high Reynolds numbers—challenging PDEs characterized by steep shocks.
- Implementation and demonstration of these innovations within a MATLAB deep learning framework leveraging automatic differentiation for efficient PDE residual computation.
Datasets
- Synthetic collocation points for PDE residuals, initial and boundary conditions—ranging from 400 to 8500 points depending on PDE dimension and example; generated via Latin Hypercube Sampling (not publicly available).
Baselines vs proposed
- A-PINN (Adam only): 1D Burgers relative L2-error = 8.65e-3 vs LSAAL-PINN = 1.79e-4
- AL-PINN (Adam + L-BFGS, fixed loss weights): 1D Burgers relative L2-error = 3.10e-4 vs LSAAL-PINN = 1.79e-4
- A-PINN: 2D CBEs relative L2-error for v component at t=1 is ~1385x higher than LSAAL-PINN
- AL-PINN: 2D CBEs relative L2-error about 8x higher than LSAAL-PINN
- In 3D CBEs with Re=3, LSAAL-PINN achieves noticeably lower L2-errors across variables u,v,w compared to A-PINN and AL-PINN
- LSAAL-PINN's total training loss consistently lower and converges faster than baselines (Figs. 5, 8, 10)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.12348.
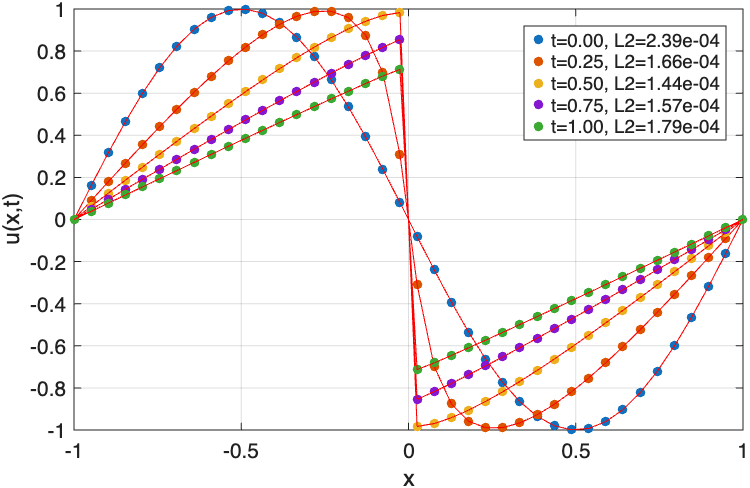
Fig 3: The comparison of exact solution (dots) vs. predicted solution (solid lines) u(x, t) at various time levels for 1D Burgers’
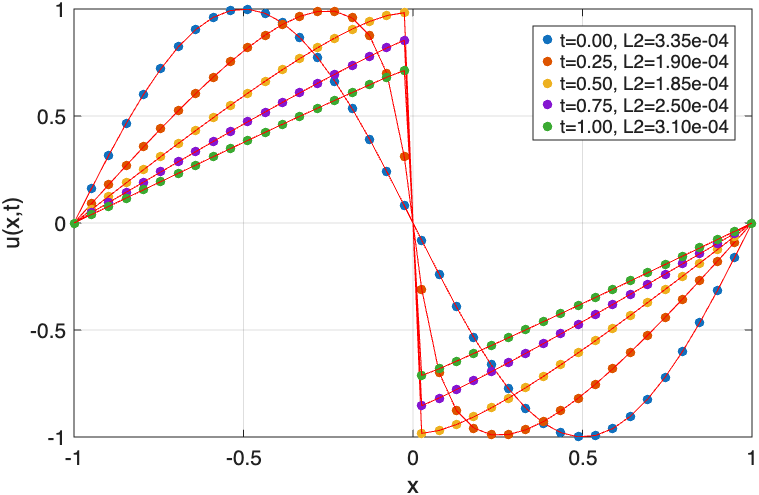
Fig 4: The comparison between exact and predicted solution of 1D Burgers’ equation
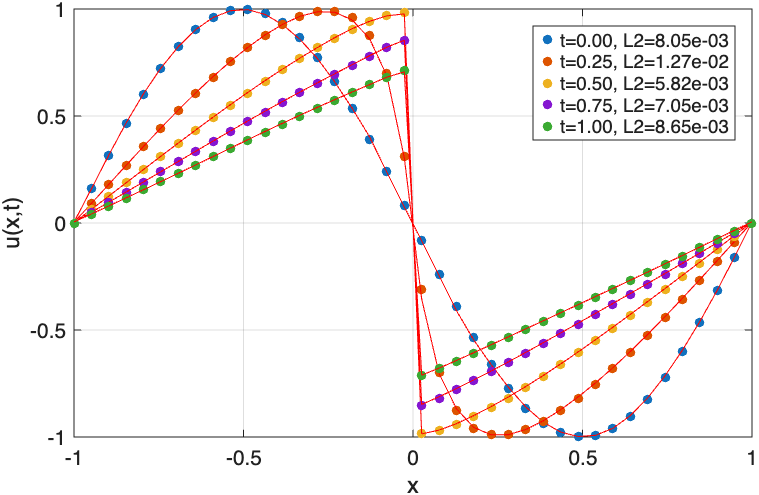
Fig 5: throughout the training process. From Figure 5 (a)-(c), one can see that an initial decay in loss is observed
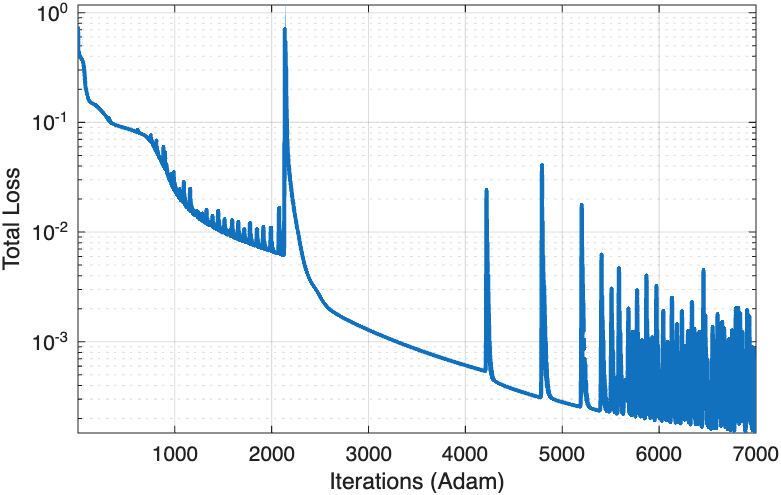
Fig 6: Comparison of the exact solution (dots) and the predicted solution (solid lines) at various time levels for 2D CBEs.
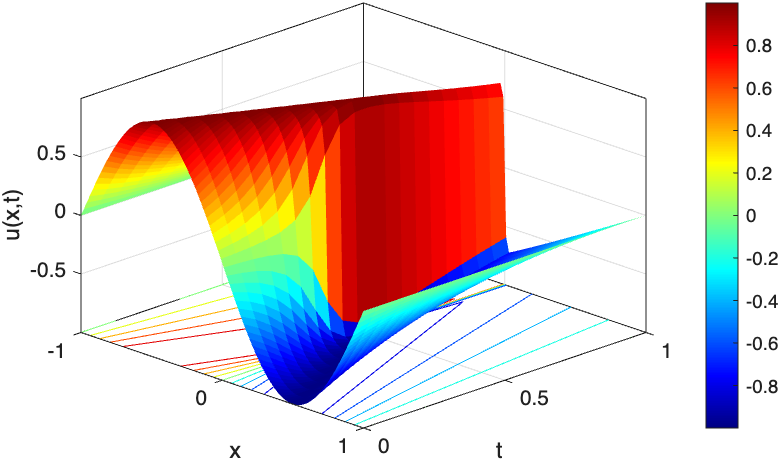
Fig 7: The spatio-temporal solution profile of u with ν = 0.0001 until time t = 1 obtained by three PINN variants.
Fig 8: The comparison of the total training loss values produced by three PINN variants for Example 2.
Fig 7 (page 7).
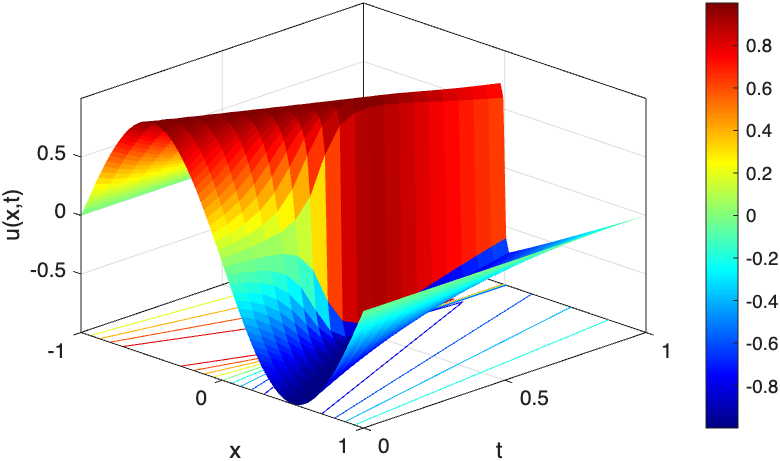
Fig 8 (page 7).
Limitations
- No adversarial robustness or noisy data analysis—performance tested only on exact or smooth synthetic solutions with high precision.
- Datasets are synthetic and limited to Burgers' equations; no real-world PDE data or other nonlinear PDEs explored.
- Method currently validated only on fully supervised forward problems; inverse problems or parameter discovery not addressed.
- Implementation and experiments limited to MATLAB environment, which may limit cross-platform replication or speed compared to Python frameworks.
- No ablation isolating the individual impact of layerwise self-adaptive weighting apart from the dual-phase optimizer.
- Scalability to very high dimensional or more complex PDE systems not assessed.
Open questions / follow-ons
- How does the self-adaptive weighting strategy generalize to other classes of nonlinear PDEs beyond Burgers' equations?
- To what extent can the approach be extended to inverse problems or PDE parameter identification tasks leveraging physics-informed constraints?
- What is the robustness of the method under noisy or sparse data conditions, especially with real measurement data?
- Could incorporating other adaptive techniques like pointwise weighting or uncertainty quantification improve or complement the layerwise adaptive weighting?
Why it matters for bot defense
While the work is focused on physics-informed neural networks for PDE simulation rather than bot detection or CAPTCHA challenges, there are relevant lessons for bot-defense practitioners working with neural networks in adversarial or data-scarce domains. The layerwise self-adaptive weighting strategy represents a effective way to dynamically balance competing loss objectives — a concept that could inspire improved loss balancing in multi-objective security models, for example, weighing adversarial robustness versus user experience. Additionally, the dual-phase optimization approach combining first-order and second-order methods may provide insight on training stability for models sensitive to loss landscape stiffness, which can occur in bot or CAPTCHA detection tasks involving heterogeneous data modalities. Finally, the emphasis on capturing sharp transitions (shock fronts) in data could relate to better neural modeling of abrupt behavioral shifts common to bot activity. However, direct applicability is limited since this work addresses PDE solutions rather than classification or anomaly detection.
Cite
@article{arxiv2606_12348,
title={ MATLAB-Based Layerwise Self-Adaptive Physics-Informed Neural Network in Applications to Multidimensional Coupled Burgers' Equations with High Reynolds Numbers },
author={ Harish P. Bhatt and Xi Chen and Jingsai Liang },
journal={arXiv preprint arXiv:2606.12348},
year={ 2026 },
url={https://arxiv.org/abs/2606.12348}
}