
HybridCodeAuthorship: A Benchmark Dataset for Line-Level Code Authorship Detection
Source: arXiv:2606.12620 · Published 2026-06-10 · By Luke Patterson, Li Wang, Adam Faulkner
TL;DR
This paper addresses the growing need to identify AI-generated code within modern software codebases, which increasingly contain a mix of human- and AI-authored code at fine granularity rather than whole-file level. Existing benchmarks for AI code detection typically rely on academic, LeetCode-style problems and label entire code snippets as either human- or AI-generated, limiting realism and utility for industry use. To fill this gap, the authors introduce HybridCodeAuthorship, a novel benchmark dataset of Python code files with line-level interleaving of human and AI-generated code reflecting authentic usage scenarios of AI code assistants in practice. The dataset is constructed by leveraging CodeSearchNet, validating correctness through unit tests, and using three large language models (LLMs) to generate AI replacements for selected code lines based on masked human code. Ground-truth line-level AI/human labels are provided. Benchmarking two state-of-the-art AI-generated code detectors—DroidDetect and AIGCode Detector—demonstrates the challenge posed by fine-grained detection, with the best F1 scores being modest: 0.56 at line-level and 0.48 at chunk-level detection. This highlights the difficulty of reliably distinguishing AI from human code at this granularity, motivating future research.
Key findings
- HybridCodeAuthorship dataset contains 4,196 Python code files (10,488 total samples with multiple LLM rewrites) and 2,827,938 lines of code with 17% (488,896) AI-generated lines.
- 39% (4,103) of human-authored files pass unit tests versus 29% (3,000) of AI-interleaved files.
- The line-level F1 scores for AI-generated code detection peak at 0.56 using the AIGCode Detector, with chunk-level F1 scores reaching 0.48, indicating line-level detection is somewhat easier than chunk-level in this benchmark.
- AIGCode Detector outperforms DroidDetect consistently across all LLMs (GPT-OSS-120b, Llama 3.3-70B, and Llama-4-Scout), dataset splits (trivial vs nontrivial lines), and granularity levels.
- Detection performance on trivial code lines is substantially worse than on nontrivial lines, except for some anomalies with the GPT-OSS-120b LLM variant.
- The dataset construction pipeline includes validation with unit tests and filters out AI-generated or human code files failing those tests, though some legacy code limitations remain.
- Code interleaving uses a three-step process: line identification for masking (with target AI code density p sampled uniformly), marking lines with intent summaries, and AI code generation guided by these summaries.
- The final labeling for AI/human authorship is established by Python diff between original and AI-modified files on the line granularity.
Threat model
The threat model considers an adversary or detection algorithm that must identify AI-generated lines within codebases containing a mixture of human- and AI-authored code, typical of modern hybrid software development. The adversary has access only to the code text and standard features, without privileged information about authorship or AI prompts. Detection models cannot rely on file-level coarse signals and must operate at line or chunk granularity. They cannot directly inspect developer interactions or logs, only the final code text.
Methodology — deep read
The paper develops HybridCodeAuthorship, a benchmark dataset for line-level AI code detection, in two main phases:
Threat Model & Assumptions: The adversary in this context is a detection model tasked with identifying if individual lines of code are AI- or human-authored within software projects that realistically mix the two. The detection models have no direct insider knowledge of authorship beyond code text features and perturbation signals; the dataset simulates real developer interactions including partial AI code insertion.
Data: Provenance, Size, Labels, Splits, Preprocessing Source human-authored code files are from CodeSearchNet, a 2019 dataset of around 2M open-source code files annotated as human-authored. For Python, 4,814 files currently available on GitHub were selected, with 4,196 successfully processed for at least one LLM. Each file underwent a unit testing phase that used project-specific tests identified by scanning repository folders and parsing test code for imports to confirm their relevance.
Files passing these tests were candidates for interleaving.
The interleaving modifies select atomic code segments (lines or functional units) masked and replaced by AI-generated code from three LLMs: Llama3.3-70B, Llama-4-Scout, and GPT-OSS-120b. The target proportion of AI code p was sampled uniformly over {10%, 20%, ..., 100%} to vary injection density. Code identification relied on LLM prompts to find replaceable segments, which were replaced with a placeholder comment containing a summary of intent, and then re-generated by another LLM pass conditioned on this summary.
Final datasets include labels per line (AI vs Human) based on line diffs between original and AI-augmented files. Line triviality (Trivial/Nontrivial) is also labeled via regex and heuristics.
- Architecture/Algorithm: The study benchmarks two AI-generated code detectors:
- DroidDetect: A fine-tuned ModernBERT model trained on human and AI code pairs.
- AIGCode Detector: An adaptation of DetectGPT using CodeBERT for perturbation instead of T5. Detection compares log probabilities of original lines vs perturbed versions, aggregating perplexity, standard deviation, and burstiness into a composite score used to decide AI vs human authorship at line and chunk levels.
Chunks are defined as contiguous lines with the same ground-truth author.
Training Regime: The detectors are pretrained elsewhere; this paper adapts them for HybridCodeAuthorship evaluation. Details on epochs, batch size, hardware, or hyperparameters for fine-tuning are not explicitly provided, indicating use of existing pretrained models. Perturbation and scoring parameters follow prior work (Xu and Sheng, 2024; Mitchell et al., 2023).
Evaluation Protocol: The dataset is split by LLM variant and code triviality label. Metrics include Precision, Recall, and F1 score for line- and chunk-level detection. The top F1 score reported is 0.56 at the line level for AIGCode Detector on nontrivial lines.
Baseline comparisons with DroidDetect show AIGCode Detector significantly better performance. Statistical significance tests are not reported. Evaluation is held out on the dataset with no indication of cross-validation.
- Reproducibility: The full dataset including line-level labels and code versions is available on GitHub at https://github.com/CapitalOne-Research/c1-hybrid-code-authorship. Model weights and code for detectors are external (e.g., DroidDetect on HuggingFace). The dataset leverages open source repos and publicly available LLMs (or their outputs).
End-to-end Example: A human-authored Python file from CodeSearchNet is processed to identify candidate lines (e.g., 20% targeted for AI replacement). The LLM generates descriptive summaries for those lines. On the marked file, the LLM generates AI code fulfilling the intent summaries. Unit tests from the original repo are run on the AI-augmented file to ensure correctness. Finally, the Python diff library compares line-by-line to label lines as 'Human' if unchanged or 'AI' if replaced. These labels form ground truth to evaluate detection algorithms.
Note: Some pipeline details such as exact prompting heuristics, LLM inference parameters, and error handling are in appendices and partially described.
Technical innovations
- A novel dataset construction pipeline that generates hybrid human/AI code files with interleaved AI-generated lines realistically simulating developer-AI interactions.
- Line-level ground truth authorship attribution produced by diff’ing original and AI-replaced code lines, enabling fine-grained evaluation beyond prior all-or-nothing snippet labels.
- Use of comprehensive unit testing on both human-authored and AI-altered code files to ensure functional correctness and dataset quality.
- Adaptation of perturbation-based AI text detection, specifically AIGCode Detector using CodeBERT perturbations and composite scoring, to line- and chunk-level code authorship attribution.
Datasets
- HybridCodeAuthorship — 4,196 Python code files (10,488 total AI-altered samples) — constructed from CodeSearchNet (public GitHub repos)
- CodeSearchNet — ~2 million code files (2019 dataset) — public GitHub repositories
Baselines vs proposed
- DroidDetect line-level F1 = 0.328 (trivial lines), 0.419 (nontrivial lines) vs AIGCode Detector line-level F1 = 0.560 (trivial), 0.530 (nontrivial) on GPT-OSS-120b dataset split
- DroidDetect chunk-level F1 = 0.181 (trivial), 0.237 (nontrivial) vs AIGCode Detector chunk-level F1 = 0.480 (trivial), 0.440 (nontrivial) on GPT-OSS-120b
- Across LLMs and splits, AIGCode Detector consistently outperforms DroidDetect by margins of roughly +0.2 to +0.3 F1
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.12620.
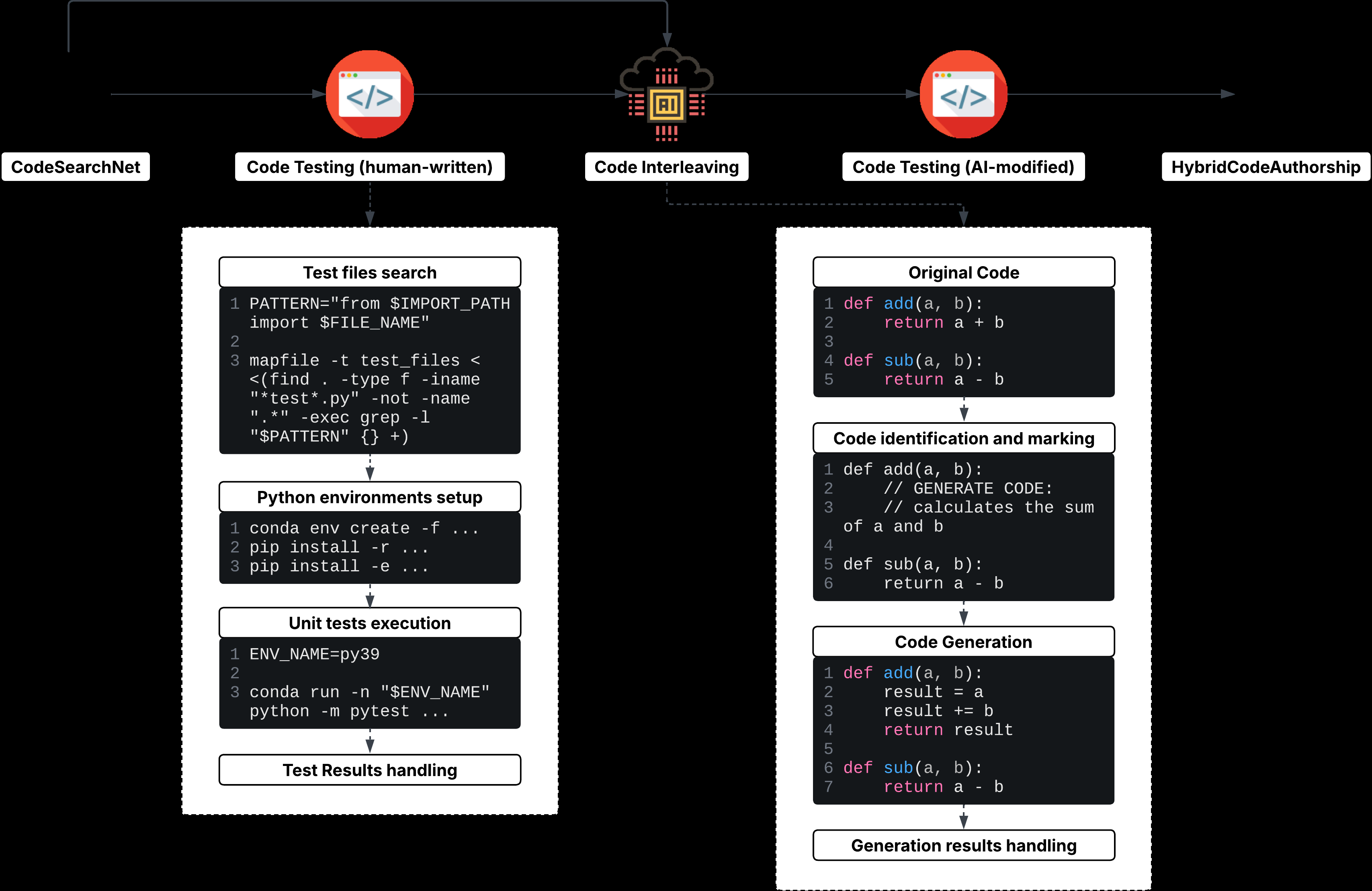
Fig 1: Overview of the data construction pipeline for HybridCodeAuthorship. First, human-authored
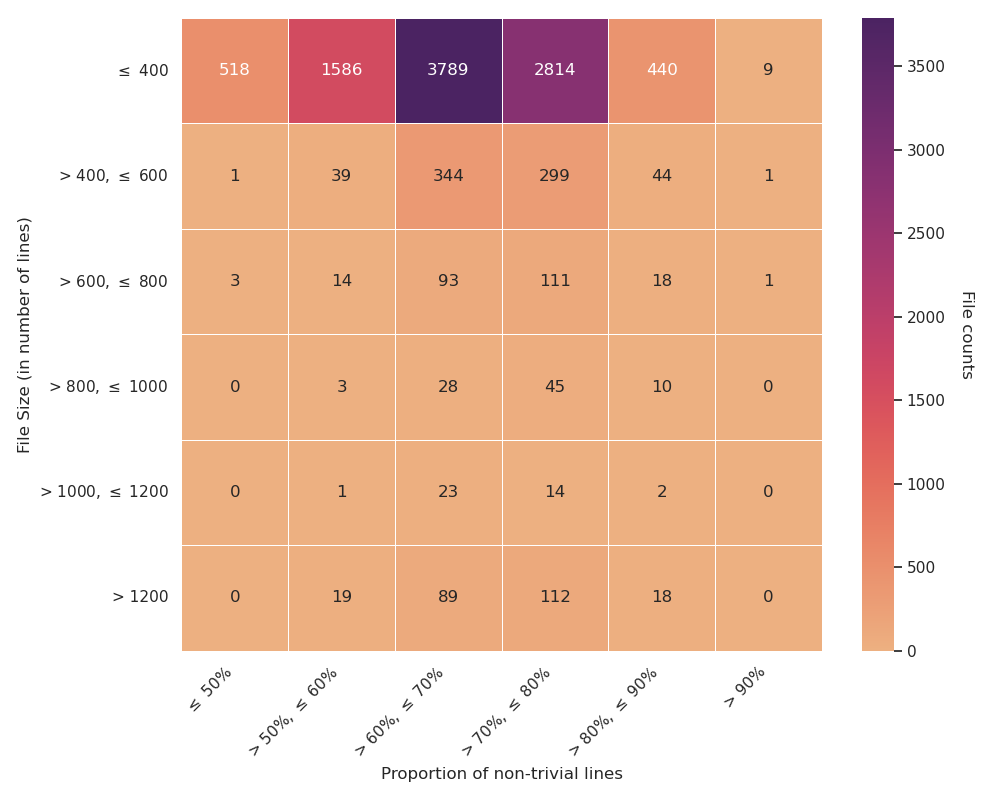
Fig 2: Overview of HybridCodeAuthorship with respect to the distributions of file counts and proportion
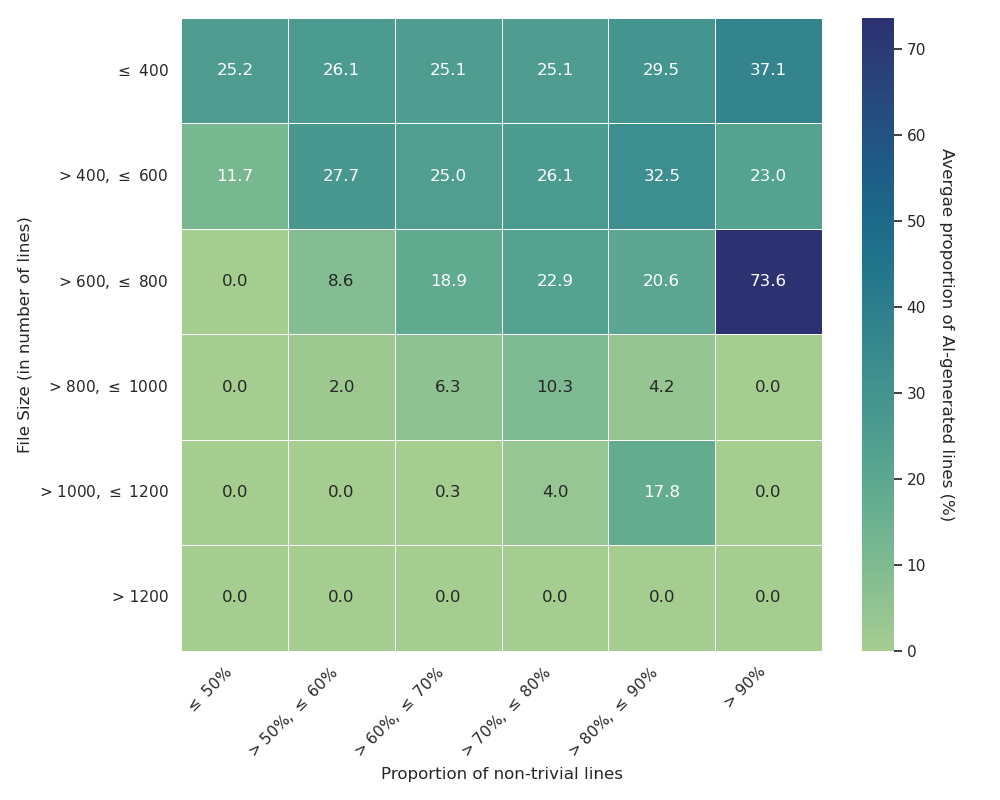
Fig 3 (page 8).
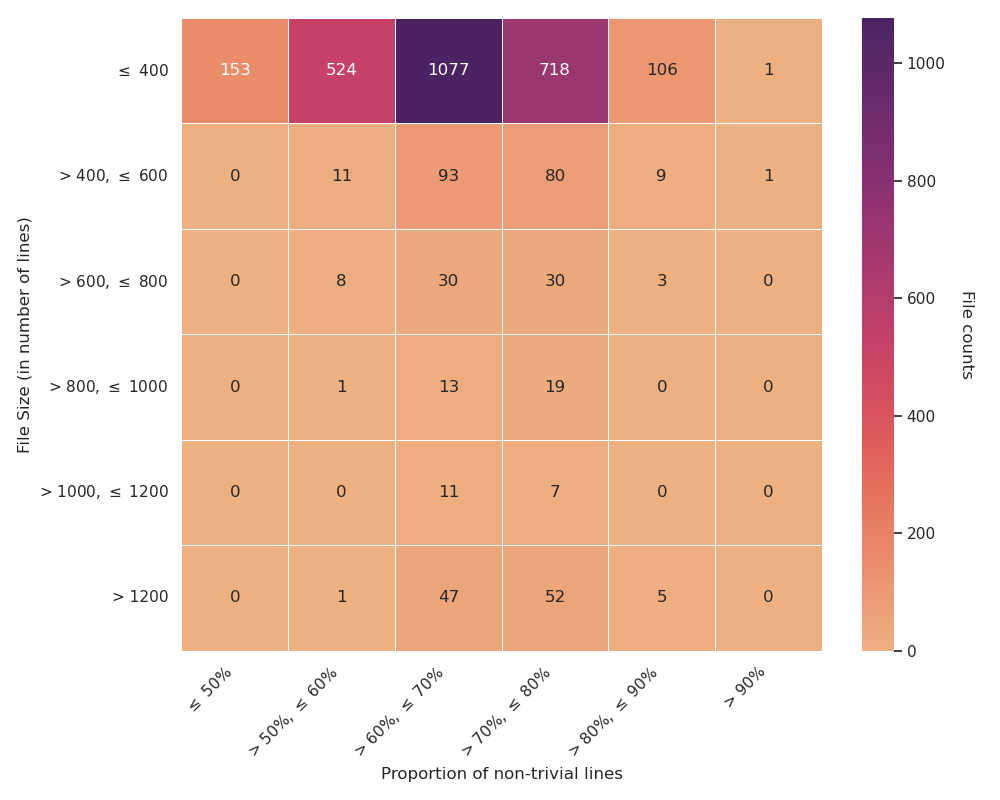
Fig 4 (page 8).
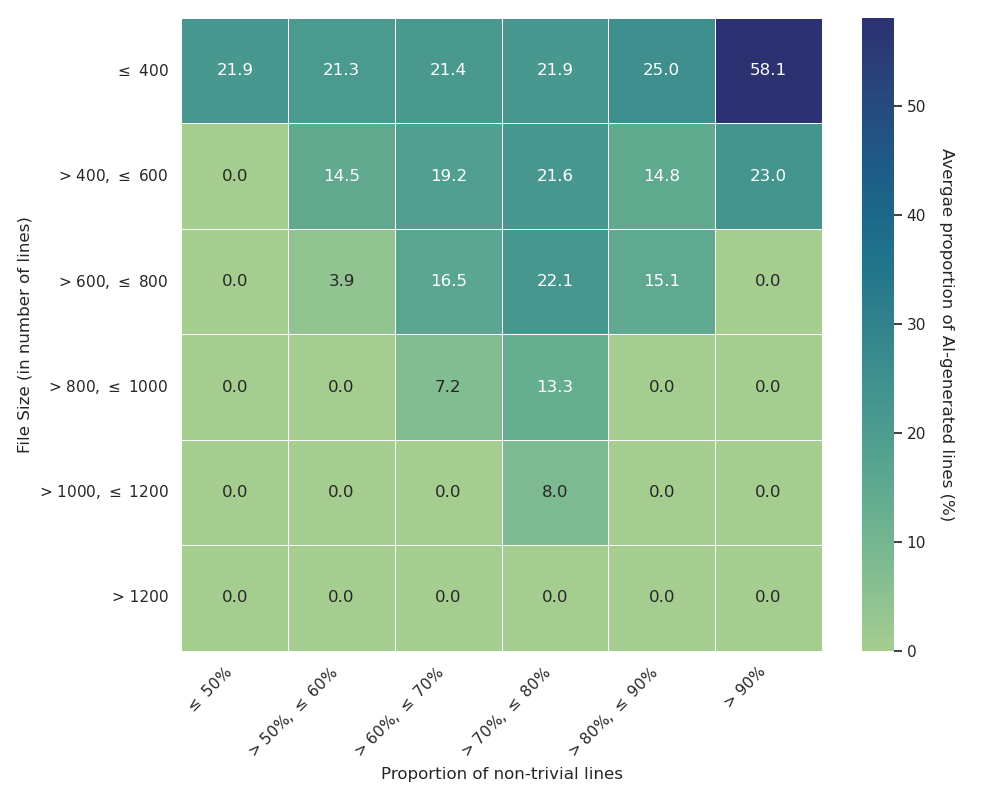
Fig 5 (page 8).
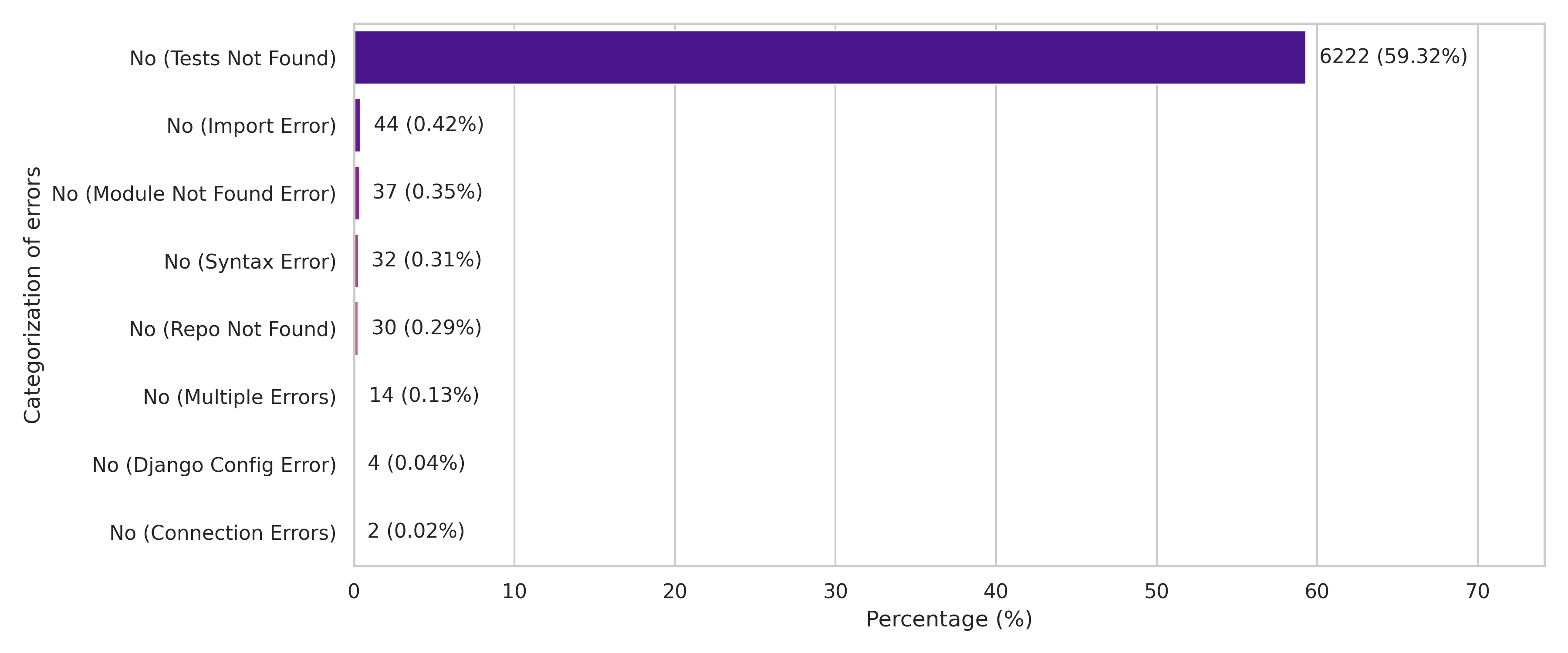
Fig 3: Error distribution in testing human-
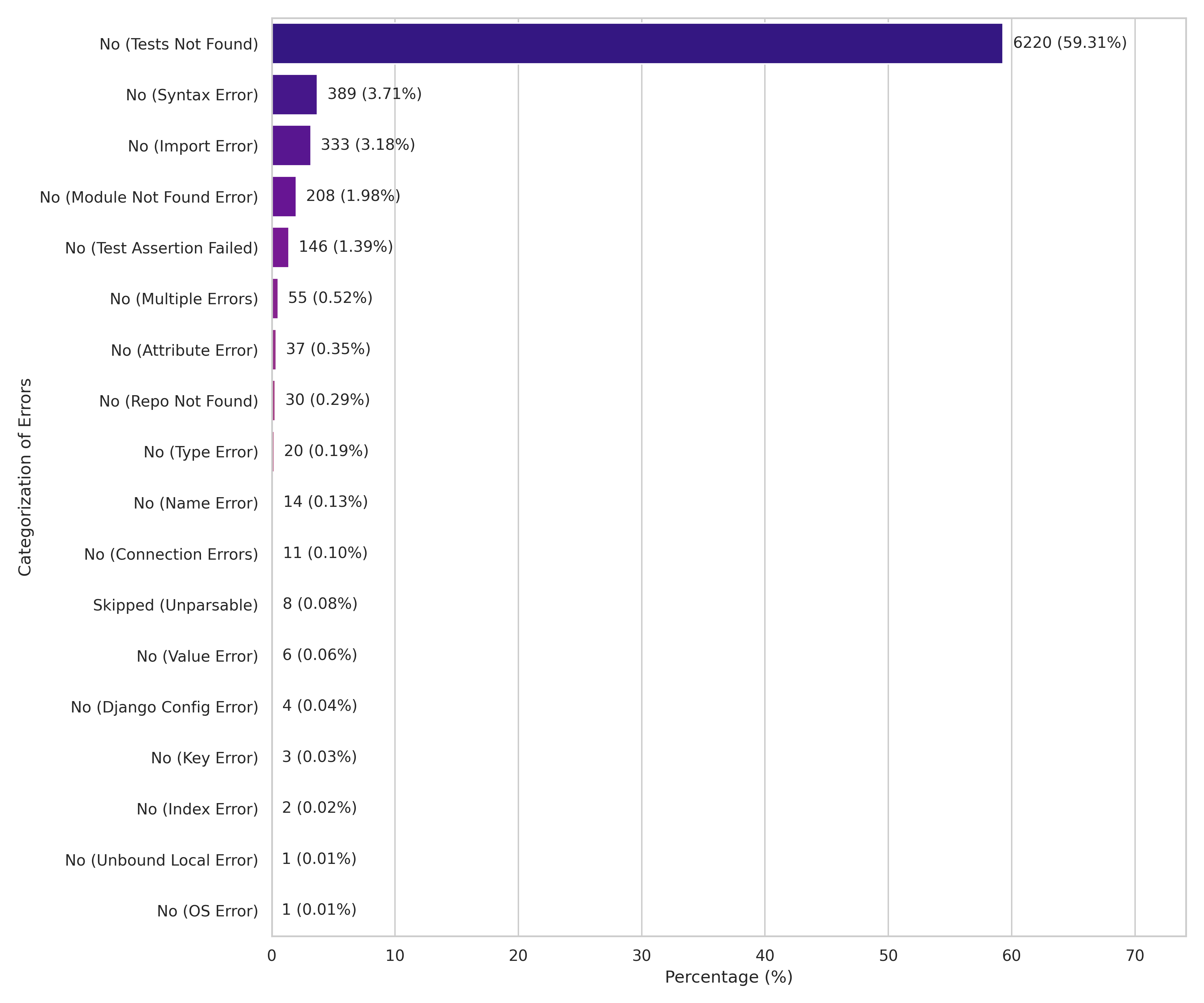
Fig 4: Error distribution in testing AI-modified
Limitations
- Unit testing does not fully capture legacy code incompatibilities, leading to some false negative filtering of valid code files.
- The finite LLM context windows caused failures processing very long source files, biasing the dataset toward shorter files.
- Dataset is limited to Python code from repositories 6+ years old, lacking contemporary or recently popularized libraries.
- Code interleaving and generation rely on compliance with instructions and LLM generation quality, which varies and causes partial pipeline failures.
- Detection performance remains modest, with F1 scores below 0.6 indicating significant room for improvement in AI/human code classification.
- No adversarial robustness or distribution-shift evaluation was conducted on the detection algorithms.
Open questions / follow-ons
- How well do detection algorithms generalize to hybrid code from newer LLMs optimized for code generation and larger context lengths?
- Can additional modalities (e.g., version control metadata or developer interaction traces) improve line-level AI code detection?
- What are effective methods to improve detection performance on trivial lines with minimal semantic content?
- How robust are detection algorithms to adversarial attempts to disguise AI-generated code as human-authored?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this paper's core relevance lies in its methodology and challenges of fine-grained detection of AI-generated artifacts within larger authentic human-produced content. Analogous to detecting automated or scripted inputs interspersed with genuine human activity, the HybridCodeAuthorship dataset and benchmark highlight the intricacies of distinguishing AI outputs blended seamlessly at the unit level rather than coarse binary classification. The perturbation-based detection techniques and line-level granularity may inspire analogous approaches for detecting minimal automated segments within textual or behavioral CAPTCHA contexts. However, performance gaps underscore detection difficulty, recommending pragmatic caution when deploying fine-grained AI-authorship detectors in adversarial environments. Monitoring AI content generation interleaved with human activity remains an open challenge critical for bot defense evolution.
Cite
@article{arxiv2606_12620,
title={ HybridCodeAuthorship: A Benchmark Dataset for Line-Level Code Authorship Detection },
author={ Luke Patterson and Li Wang and Adam Faulkner },
journal={arXiv preprint arXiv:2606.12620},
year={ 2026 },
url={https://arxiv.org/abs/2606.12620}
}