
Assumption-Lean Shrinkage and Model Averaging for Spatial Parameters
Source: arXiv:2606.12324 · Published 2026-06-10 · By Harvey Barnhard
TL;DR
This paper addresses the challenge of shrinkage estimation for spatially structured parameters when multiple plausible definitions of relatedness among units exist (e.g., geography, adjacency, or covariate similarity). Rather than committing to a single spatial model or adjacency rule, the author proposes a framework that uses Stein's Unbiased Risk Estimate (SURE) both to select among and to average over a library of candidate shrinkage estimators. This assumption-lean approach avoids relying on a single prior or covariance model and instead provides a disciplined, data-driven method that nearly matches the performance of the best candidate or weighted average in the class.
The paper introduces sufficient conditions under which SURE selection and SURE-based averaging achieve oracle inequalities—meaning their squared-error risk approaches that of the best fixed estimator or weighted average in the candidate set. It demonstrates the method on economic mobility data from the Opportunity Atlas, showing that the best spatial smoothing rule varies by region and that SURE-selected averages reduce estimated mean squared error by about 27% compared to the best non-spatial empirical Bayes benchmark. The results highlight the importance of empirically choosing spatial pooling relationships when denoising noisy local estimates.
Key findings
- SURE-selected shrinkage maps achieve squared-error risk nearly as low as the best single candidate in the family under mild regularity conditions (Section 3.1).
- SURE-chosen weighted averages over candidate shrinkage maps perform nearly as well as the best fixed convex combination of those maps (Section 3.2).
- In the Opportunity Atlas application with 20 commuting zones, the SURE-chosen average reduces SURE-estimated mean squared error by approximately 27% relative to the best-performing non-spatial empirical Bayes benchmark (CLOSE-GAUSS).
- The SURE-chosen average reduces SURE-estimated MSE by about 55% compared to the raw maximum-likelihood estimates (unshrunk tract estimates) in Cook County (Section 4).
- The best individual spatial shrinkage rule varies across commuting zones, confirming that spatial pooling structure is context-dependent.
- Value-similarity shrinkage estimators, which incorporate similarity of observed estimates in addition to geographic proximity, retain more local contrasts than purely geography-based smoothers (Figures 2 and 3).
- The proposed method accounts for tuning parameters learned from the same data by incorporating a learned-parameter correction term into the SURE calculation (Section 2.4).
- Automatic differentiation and randomized trace estimation allow efficient computation of SURE and its derivatives for nonlinear, data-dependent shrinkage maps.
Threat model
Not a security-focused paper; adversarial behavior is not modeled. The focus is on statistical estimation under noisy Gaussian observations of fixed latent parameters. There is no assumption that the adversary manipulates or knows the data; instead, the paper addresses how to choose or combine shrinkage estimators robustly without relying on restrictive model assumptions.
Methodology — deep read
Threat Model & Assumptions: The setting is estimation of a fixed but unknown parameter vector θ ∈ R^n from noisy Gaussian observations Y = θ + ε, where ε ∼ N(0, Σ) and Σ is known. The focus is on shrinkage estimators that pool information across spatially or otherwise related units. The adversary is not explicitly modeled; rather, robustness is enhanced by not assuming any one spatial or prior model is correct.
Data: The primary empirical dataset is the Opportunity Atlas economic mobility estimates at Census tract level within 20 commuting zones, with reported marginal variance estimates used as the diagonal of Σ. The dataset size varies by commuting zone but involves hundreds to thousands of tracts. Preprocessing includes preliminary covariate adjustments.
Architecture / Algorithm: Candidate shrinkage estimators are constructed as maps fγ(Y), parameterized by γ, which may specify smoothing scale, covariance parameters, or similarity thresholds. Examples include:
- Normal–normal empirical Bayes (NN-EB): global shrinkage toward a common mean without spatial structure.
- Gaussian process (GP) spatial shrinkage: posterior means using spatial covariance kernels K_γ indexed by geographic or adjacency-based distances.
- Value-similarity shrinkage: nonlinear, data-dependent covariance matrices that downweight smoothing between units with dissimilar observed estimates, implemented via bilateral-filter-like constructions.
Each candidate map can be linear or nonlinear, and its tuning parameters γ are estimated from data either by maximum marginal likelihood or minimizing SURE within candidate classes. The full estimator incorporates learned parameters.
Training Regime: Training involves optimizing tuning parameters γ (e.g., kernel length scale, variance components, regularization strength) using either maximum marginal likelihood or SURE as a proxy risk objective. Optimization algorithms (e.g., AdamW) and automatic differentiation are used to efficiently compute gradients and Jacobians needed for SURE and its complexity correction terms. Training is done per candidate class and per observed data vector Y.
Evaluation Protocol: The key evaluation metric is squared-error loss versus the latent true parameters θ, approximated by SURE, an unbiased estimator of risk derived from the data and the estimator's Jacobian w.r.t. inputs. The methodology includes:
- Computing SURE values for each candidate estimator map.
- Selecting the best candidate map by minimum SURE or forming convex SURE-minimizing weighted averages over candidate maps.
- Providing oracle inequalities showing the selected map or weighted average nearly matches the best possible in-class performance.
- Empirically comparing raw estimates, NN-EB, spatial GP smoothing, value-similarity smoothing, and SURE-weighted averages.
Cross-validation and explicit hold-out tests are not used due to a single observation per parameter, but SURE offers a principled risk estimate avoiding overfitting.
- Reproducibility: The paper discusses the use of automatic differentiation and randomized trace estimation to compute SURE terms but does not mention open-source code or releasing trained models. The Opportunity Atlas data is publicly available but the exact splits or preprocessing details may limit perfect reproducibility.
Concrete example end-to-end: For Cook County's tracts, the raw MLE vector Y with known variances Σ is available. Different candidate shrinkage maps fγ(Y) including NN-EB and spatial GP smoothers are fit by training γ with SURE or likelihood. SURE is computed for each candidate map, including corrections for tuning parameter sensitivity via Jacobians. The SURE-minimizing weighted average of these maps is then computed by minimizing a quadratic program in weights. The final averaged estimator reduces estimated MSE by ~55% relative to raw and by ~27% vs the best NN-EB benchmark. This workflow highlights the key role of using SURE to evaluate nonlinear spatial smoothers and aggregate across them with learned weights.
Technical innovations
- Extension of SURE-based model selection and model averaging from finite families of linear estimators (Bellec and Zhang, 2021) to compact classes of nonlinear, data-dependent shrinkage maps indexed by tuning parameters.
- Derivation of oracle inequalities guaranteeing that SURE selection performs nearly as well as the best candidate in a parameterized nonlinear class and that SURE-chosen weighted averages nearly match the best fixed convex combination.
- Incorporation of learned-parameter corrections within the SURE formula through chain-rule differentiation, allowing tuning parameters estimated from the same data to be accounted for in risk estimation.
- Application of complex spatial covariance models, including value-similarity kernels that depend nonlinearly on observed noisy estimates, combined with efficient differentiation and randomized trace estimation techniques to compute SURE for these forms.
- Unification of multiple shrinkage candidate classes—including classical empirical Bayes, Gaussian process spatial smoothers, and nonlinear bilateral-filter-inspired smoothers—into a common SURE evaluation and averaging framework.
Datasets
- Opportunity Atlas economic mobility estimates — hundreds to thousands of tracts per commuting zone across 20 zones — publicly available from Chetty et al. (2026)
Baselines vs proposed
- Raw maximum-likelihood estimates (MLE): SURE-estimated MSE = baseline; SURE-chosen average reduces MSE by 55%
- CLOSE-GAUSS (non-spatial empirical Bayes benchmark): SURE-estimated MSE = baseline; SURE-chosen average reduces MSE by 27%
- Best individual spatial shrinkage rule: SURE-estimated MSE = variable by zone; SURE selection performs nearly as well as best
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.12324.
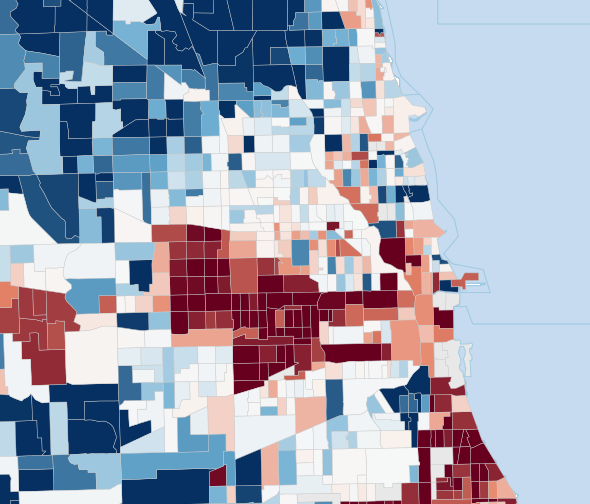
Fig 1: Choropleth maps of tract-level mobility estimates for Cook County tracts
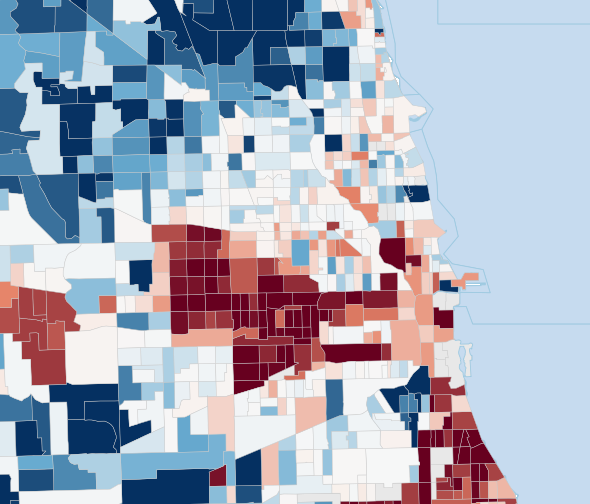
Fig 2: Competing shrinkage targets for the same Cook County tract-level mo-
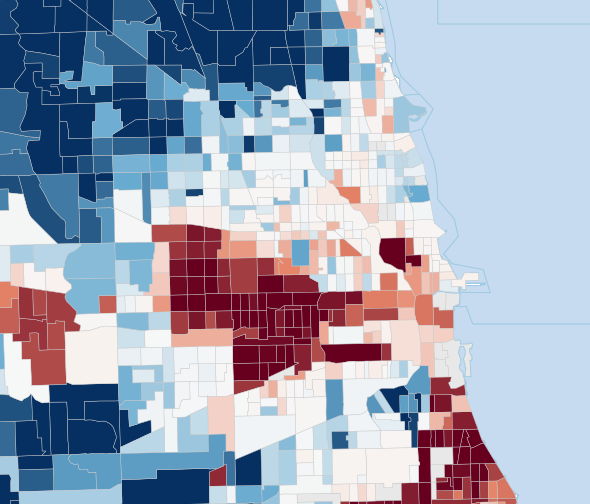
Fig 3: Leave-one-out shrinkage targets for geography-only and value-similarity
Fig 4 (page 10).
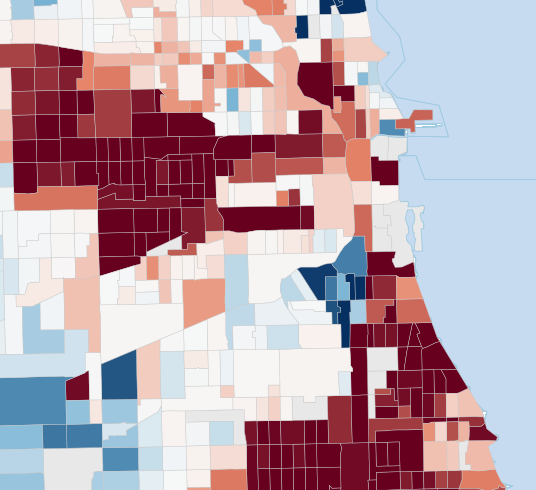
Fig 5 (page 11).
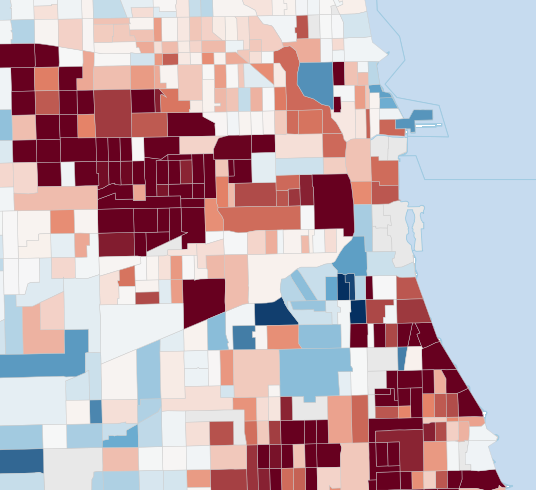
Fig 6 (page 11).
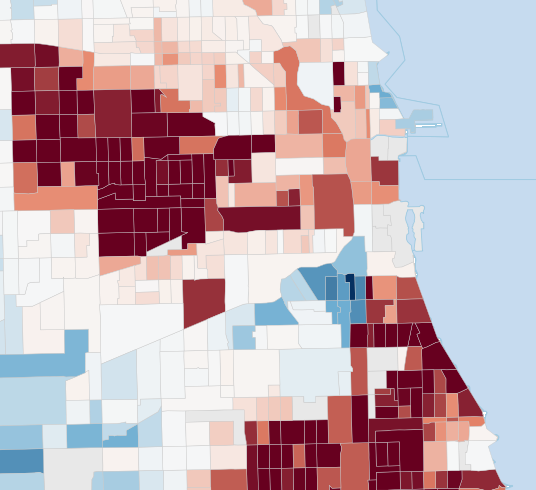
Fig 7 (page 11).
Limitations
- Results rely on the assumption of known noise covariance matrix Σ, though real-world estimates may have misspecification or dependence.
- Empirical validation focused on Opportunity Atlas data; generalization to other spatial estimation settings requires further study.
- No explicit adversarial or worst-case robustness evaluation of shrinkage estimators; methodology assumes Gaussian noise model.
- SURE depends on differentiability conditions which may not hold exactly for all nonlinear maps; sufficient conditions are mostly theoretical.
- Computational complexity grows with number of candidates and sample size due to Jacobian and trace calculations, despite randomized trace estimation.
- The approach assumes a single observation per unit, limiting explicit cross-validation or external validation possibilities.
Open questions / follow-ons
- How does the SURE-based selection and averaging perform under model misspecification, e.g., if covariance Σ is estimated with error or if noise deviates from Gaussianity?
- Can this framework be extended to handle dependencies or clusters among units beyond spatial adjacency, such as social networks or hierarchical groupings?
- How sensitive are the oracle inequalities and empirical gains to different choices of candidate classes or tuning parameter spaces?
- What are the computational trade-offs and scalability limits as the number of units and candidate estimators grows very large?
Why it matters for bot defense
Bot-defense and CAPTCHA practitioners often confront data aggregation or score smoothing problems across entities with latent parameters obscured by noise. This work provides a principled framework for selecting and averaging spatially structured shrinkage estimators using an unbiased, data-driven risk estimate (SURE), without assuming a correct spatial model upfront. The methodology's focus on assumption-lean, flexible spatial smoothing maps could inspire analogous approaches to denoise or calibrate bot or user risk scores where multiple similarity metrics (e.g., IP proximity, behavior similarity) compete.
Moreover, the differentiation and efficient risk assessment of nonlinear, data-adaptive estimators may inform automated tuning of defense thresholds or aggregation rules under uncertainty. While this is statistically focused rather than adversarial in a security sense, the rigorous approach to estimator selection and averaging under noisy cross-sectional observations could be adapted or extended by bot-defense engineers to improve robustness and reduce overfitting of suspiciousness models that aggregate signals with structural unknowns.
Cite
@article{arxiv2606_12324,
title={ Assumption-Lean Shrinkage and Model Averaging for Spatial Parameters },
author={ Harvey Barnhard },
journal={arXiv preprint arXiv:2606.12324},
year={ 2026 },
url={https://arxiv.org/abs/2606.12324}
}