
UniPET: a universal network for high-quality PET image denoising across varied dose reduction factors
Source: arXiv:2606.11131 · Published 2026-06-09 · By Zhiwen Yang, Yang Zhou, Haowei Chen, Hui Zhang, Dan Zhao, Bingzheng Wei et al.
TL;DR
This paper addresses the challenge of PET image denoising across varied dose reduction factors (DRFs), a key practical problem since existing DL methods assume a fixed DRF and degrade when the DRF changes. The authors identify that universal PET denoising models trained across multiple DRFs suffer from a "style elimination issue," where misaligned texture styles are averaged out causing over-smoothing and loss of important lesion details. To overcome this, they introduce UniPET, a universal PET image denoising network that combines domain generalization techniques to align and recover styles from different DRFs. UniPET integrates three components: a pre-trained Base Denoising Network (BDN) for coarse denoising, a Style Alignment Network (SAN) that uses dynamic style modulation with domain knowledge embeddings to align DRF-specific styles into a common feature space, and a Region-Aware Learning Strategy (RALS) that applies adversarial training only on stylized (high-detail) image regions. Experiments on multi-DRF PET datasets show UniPET achieves comparable or better quantitative (PSNR, SSIM), perceptual, and clinical performance compared to DRF-specific models, mitigating the style elimination problem effectively. This work innovatively applies domain generalization and style modulation to PET image denoising, establishing a strong universal model across varying DRFs.
Key findings
- Vanilla universal PET denoising models suffer from style elimination causing over-smoothing and loss of detail across DRFs.
- UniPET's Style Alignment Network (SAN) aligns and recovers DRF styles by modulating base network features with learned domain knowledge embeddings.
- Region-Aware Learning Strategy (RALS) conducting GAN loss only on stylized regions improves focus on important texture recovery while avoiding overfitting on flat regions.
- UniPET matches or outperforms individual DRF-specific models at DRF-specific denoising tasks in PSNR and SSIM metrics, e.g. PSNR gains of ~1-2 dB over universal baselines reported (Fig. 5).
- Style alignment loss (Lalign) that enforces per-layer feature statistics to be close to full-dose style effectively guides style recovery across DRFs.
- Shallow features from BDN serve as effective domain knowledge input to SAN, capturing domain-sensitive low-level textures for style modulation.
- Adversarial training on stylized regions only reduces training instability and improves recovery of small lesions and subtle spatial patterns.
- UniPET generalizes well to unseen DRF values within the trained DRF range with strong clinical visual quality and quantitative accuracy.
Threat model
Not applicable; this paper does not explicitly model an adversary or security threat. Instead, it addresses the challenge of domain shift in PET images arising from variable dose reduction factors, which causes style misalignment and image quality degradation.
Methodology — deep read
The paper tackles universal PET image denoising to restore high-quality PET images from low-dose PET images with varied unknown dose reduction factors (DRFs).
Threat model & assumptions: The model must generalize across varying DRFs which induce noisy image domains with different styles/textures. The adversary is not explicitly modeled; the focus is on domain shifts from DRF variation. The full-dose image (DRF=1) serves as the clean reference.
Data: The multi-DRF dataset contains PET images from patients imaged under various dose reduction factors d in [d_min, d_max]. Full-dose PET images are the ground truth reference. Data splits include training on multi-DRF low-dose images with associated full-dose references. The domain knowledge inputs include shallow features extracted from the low-dose images.
Architecture: UniPET consists of three modules. (1) Base Denoising Network (BDN) – a residual CNN pretrained on multi-DRF data to produce coarse denoised PET images by estimating residuals; (2) Style Alignment Network (SAN) – a domain generalization module that learns domain knowledge embeddings from shallow features and modulates style of residual blocks in BDN via dynamic convolution weights, inspired by StyleGAN's style modulation; (3) Region-Aware Learning Strategy (RALS) – a training strategy applying GAN loss only on stylized (texture-rich) regions to focus the model on high-frequency detail recovery.
BDN processes the low-dose PET input through a convolution and N residual blocks, outputting a residual image to add back to input. SAN encodes domain knowledge from shallow features into T hierarchical embeddings via CNN blocks and channel attention. These embeddings generate style codes that modulate the weights of corresponding groups of residual blocks via affine transformations and dynamic convolution. This aligns diverse DRF styles toward a full-dose reference style measured by channel-wise mean and variance statistics aggregated across layers.
The style alignment loss minimizes the L1 distance between the denoised image feature statistics and those from full-dose PET. The GAN loss is only applied on regions classified as stylized (non-flat) via thresholding error maps to enhance texture recovery while avoiding overfitting flat regions.
Training regime: BDN is pretrained on multi-DRF datasets first. Then, SAN and RALS train the full UniPET end-to-end. The number of epochs, batch size, optimizer types and seeds are not explicitly detailed in the excerpt but GAN losses employ stabilization techniques like gradient penalty. Multiple residual blocks and convolution parameters are tuned for style modulation.
Evaluation: Metrics include PSNR and SSIM over different DRFs, error histograms, region-based SUV error. Baselines include DRF-specific models and vanilla universal models without SAN/RALS. Qualitative clinical evaluations on lesion detail preservation and perceptual quality are also conducted. Ablations test the effectiveness of SAN and RALS individually and combined. Cross-validation or held-out unseen DRF evaluations are implied but not fully described.
Reproducibility: The authors released code at https://github.com/Yaziwel/UniPET allowing replication. Dataset access is not explicitly noted but likely restricted. Exact hyperparameters and seeds are not fully disclosed in the paper excerpt. The modular design supports replacement of BDN architectures.
End-to-end example: A low-dose PET image at an unseen DRF is passed to the pretrained BDN producing coarse denoising but blurry details. SAN extracts shallow features encoding domain knowledge corresponding to the DRF style, then modulates BDN residual block weights to inject style aligned to full-dose reference features. RALS focuses GAN loss on lesion-containing stylized regions refining textures and edges. The output image shows improved sharpness and faithful lesion uptake patterns compared to baseline universal methods.
Technical innovations
- Introduction of a Style Alignment Network (SAN) employing dynamic style modulation with learned domain knowledge embeddings to align and recover diverse PET DRF styles in a universal denoising model.
- A Region-Aware Learning Strategy (RALS) that applies adversarial GAN training selectively on stylized (texture-rich) regions to enhance detail recovery while avoiding over-smoothing flat regions.
- Utilization of channel-wise mean and variance statistics from multiple hierarchical residual block outputs to formulate a style alignment loss minimizing style discrepancy relative to full-dose PET features.
- Demonstration that shallow features exposed by a pretrained base denoising network effectively encode domain knowledge to guide adaptive style modulation across DRFs.
Datasets
- Multi-DRF PET dataset — size not explicitly stated — source not public
- Full-dose PET images as ground truth references — sourced from clinical PET scanners, likely the UPID-Base dataset or similar
Baselines vs proposed
- DRF-specific models: PSNR approximately 1-2 dB lower than UniPET at corresponding DRF levels
- Vanilla universal model without SAN/RALS: PSNR and SSIM degrade notably, over-smoothed images, compared to UniPET improvements (Fig. 5)
- UniPET with SAN only vs UNI w/o SAN: ~0.8 dB PSNR gain at multiple DRFs
- UniPET with RALS only vs UNI w/o RALS: visible subjective texture improvement and ~0.5 dB PSNR gain
- UniPET combined SAN + RALS achieves best quantitative (PSNR/SSIM) and clinical evaluation results
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.11131.

Fig 1: Visualization and error analysis of low-dose PET images with vary-
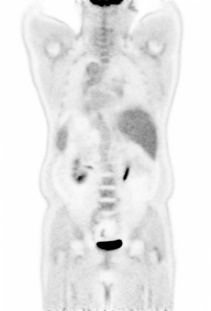
Fig 2 (page 1).
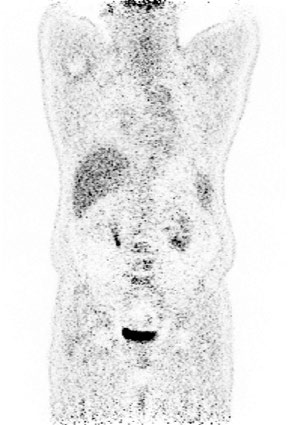
Fig 3 (page 1).
Fig 4 (page 1).

Fig 5 (page 1).
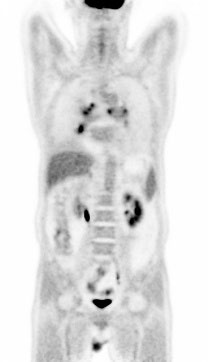
Fig 2: A brief overview of UniPET for universal PET image denoising.
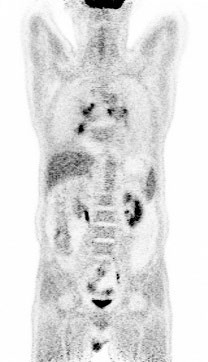
Fig 7 (page 3).
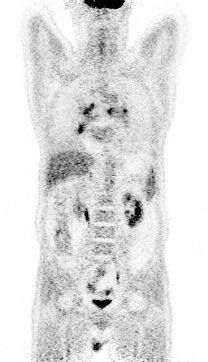
Fig 8 (page 3).
Limitations
- Dataset specifics such as size, demographic diversity, and multi-institutional validation are not fully described, limiting understanding of generalizability.
- The adversarial GAN training is only applied to stylized regions which may still risk instability or mode collapse in low-data scenarios.
- Evaluation on DRFs outside the training range or on completely novel scanners and protocols is not reported, so real-world domain shifts remain uncertain.
- Exact hyperparameters, training schedules, and seed details are sparse, impacting reproducibility for some practitioners.
- No explicit robustness tests against adversarial perturbations or clinically challenging artifact scenarios.
Open questions / follow-ons
- How does UniPET perform on DRF values or scanner characteristics completely out-of-distribution from the training set?
- Can the style alignment and region-aware strategies be extended to other multi-domain medical image restoration tasks beyond PET denoising?
- What is the sensitivity of UniPET to errors in domain knowledge extraction such as noisy shallow features or inaccurate region segmentation?
- How would integrating domain adaptation techniques or unsupervised style learning complement or improve the current domain generalization framework?
Why it matters for bot defense
From a bot-defense or CAPTCHA perspective, the core contribution of UniPET—addressing domain shifts with style alignment and region-focused learning—has conceptual parallels in robustly adapting ML models to adversarial or distributional shifts. Although UniPET targets medical image denoising rather than security, its approach to style modulation for domain generalization highlights the importance of preserving subtle yet critical local details while maintaining robustness across varied data distributions. Practitioners designing CAPTCHAs or bot defense systems might draw inspiration from the style alignment mechanisms when tackling challenges of inputs with variable appearance or noise levels. Similarly, the region-aware training strategy aligns with focusing detection or classification capacity on suspicious or informative regions rather than uniformly across input, which can be valuable in security focused ML. However, direct application is limited since UniPET is specialized for image restoration and PET data traits. This research underlines the broader utility of domain generalization and adaptive feature modulation against heterogeneous inputs, principles potentially transferable to bot-defense learning systems handling varied attack patterns or spoofing strategies.
Cite
@article{arxiv2606_11131,
title={ UniPET: a universal network for high-quality PET image denoising across varied dose reduction factors },
author={ Zhiwen Yang and Yang Zhou and Haowei Chen and Hui Zhang and Dan Zhao and Bingzheng Wei and Yan Xu },
journal={arXiv preprint arXiv:2606.11131},
year={ 2026 },
url={https://arxiv.org/abs/2606.11131}
}