
Piper: A Programmable Distributed Training System
Source: arXiv:2606.11169 · Published 2026-06-09 · By Megan Frisella, Shubham Tiwari, Andy Ruan, Yi Pan, Parker Gustafson, Mat Jacob et al.
TL;DR
Piper addresses the complexity and inflexibility in current large-scale distributed training systems that combine multiple parallelism strategies (data, pipeline, expert, tensor parallelism) and memory-saving optimizations like ZeRO. Traditionally, these strategies require domain experts to manually design both high-level parallelism schemes and low-level execution schedules—a laborious process that hinders adaptability to new model architectures and cluster setups. Existing general-purpose frameworks offer some flexibility but are limited by fixed sets of parallelism strategies and limited intra-device control, making it challenging to implement state-of-the-art or novel composed strategies such as DualPipe.
Piper introduces a programmable distributed training system that decouples parallelism strategy specification from runtime execution. Users annotate parts of their models and issue scheduling directives that transform a unified intermediate representation (an IR capturing a global training DAG of compute and communication). This decoupling allows Piper to compile flexible, per-device execution plans that jointly schedule compute and communication resources, including intra-GPU microbatch overlapping and multiple communication streams. The system runtime is agnostic to the parallelism strategy and efficiently executes the compiled plan. Piper matches performance of frameworks like Megatron and DeepSpeed on standard strategies (such as ZeRO) but enables 6-30% higher throughput and supports 3-8x larger batch sizes when composing parallelism strategies such as DeepSeek-V3 DualPipe with data/expert parallelism and ZeRO. This combination of expressivity and efficiency demonstrates how programmable training can enable future model training system innovations with less expert engineering effort.
Key findings
- Piper matches throughput performance parity with Megatron and DeepSpeed on commonly used parallelism strategies like ZeRO.
- Piper enables an overall 6-30% throughput improvement over baselines including Megatron and TorchTitan when using composed parallelism strategies like DeepSeek-V3's DualPipe.
- Piper supports 3-8x larger batch sizes compared to other generic training frameworks by jointly scheduling communication and compute across pipeline and ZeRO parallelism strategies.
- Using separate logical GPU streams for each communication type (e.g., pipeline parallelism, data parallelism, expert parallelism) reduces interference and improves communication overlap (Fig 4 shows up to 1.46x slowdown reduction in some cases).
- Piper's unified intermediate representation (IR) allows encoding all compute and communication dependencies as a global training DAG, enabling safe and efficient scheduling of arbitrary parallelism strategy compositions.
- The user scheduling API with annotations and scheduling directives concisely expresses complex strategies such as DualPipe with microbatch overlap and mixed parallelism dimensions (pipeline, expert, data).
- Piper's runtime achieves low scheduling overhead by using a centralized scheduler distributing local execution plans to workers that schedule GPU streams and communication without user intervention.
- The system can express and execute intra-device parallelism strategies that interleave forward and backward microbatches on the same GPU to effectively hide all-to-all communication latency (Fig 3).
Threat model
n/a - the paper does not consider adversarial threats but focuses on improving flexibility and performance of distributed model training systems through programmable scheduling abstractions.
Methodology — deep read
Threat Model & Assumptions: Piper assumes a distributed large-scale training environment where adversarial attacks are not the focus; rather, the adversary is the complexity and manual labor required to efficiently implement composed parallelism strategies. The system is designed for correctness and efficiency under complex scheduling demands rather than adversarial robustness.
Data: The evaluation uses publicly available large-scale transformer and mixture-of-experts models including DeepSeek-V3 MoE transformers. Exact dataset sizes and training data are not the central focus; the system targets scalable training workloads, and benchmarks run on clusters of accelerators (GPUs) sized to simulate real-world training environments.
Architecture / Algorithm: Piper implements a compiler and runtime for distributed training. The compiler extracts a single-device DAG from an annotated PyTorch model, then repeatedly applies user scheduling directives to transform it into a global distributed training DAG (IR) that unifies compute and communication operations as nodes. Nodes represent coarse-grained compute chunks or communication operations, each assigned device placements and logical GPU streams.
The user API includes annotations to mark model submodules along parallelism dimensions (e.g., pipeline stage, expert parallelism), plus scheduling directives to control device placement, replication/sharding, microbatch splitting, communication stream assignment, and ordering constraints. These transform the DAG by inserting communication nodes and temporal dependencies.
The runtime uses a centralized scheduler to produce per-device execution plans from the compiled IR. On each worker device, local scheduling assigns physical GPU streams to the logical streams and executes the queued operations. The runtime uses Ray for distributed coordination and supports pipelined, overlapped, and asynchronous execution.
Training Regime: The system is implemented as a torch.compile backend and evaluated with real large-scale models on multi-GPU clusters. The paper does not specify epochs or seeds since the focus is system-level performance benchmarking rather than model accuracy.
Evaluation Protocol: Piper is compared against general-purpose frameworks including Megatron, DeepSpeed, and TorchTitan on standard strategies like ZeRO and more complex composed strategies such as DualPipe. Metrics include throughput (training samples per second), maximum batch size, and memory efficiency. Throughput improvements of 6-30% are reported for composed strategies. Scaling experiments show Piper supports significantly larger batch sizes when combining pipeline parallelism with ZeRO levels that other frameworks fail to support. The paper discusses ablations on communication stream placement and bucket sizes affecting interference.
Reproducibility: Piper is implemented as a torch.compile backend and the distributed runtime with Ray, but the paper does not explicitly state if code or weights are publicly released. Details sufficient for reproduction of the compiler, IR transformations and runtime scheduling are described. The datasets and model implementations used appear standard in the community.
End-to-End Example: The paper illustrates a simplified user schedule that applies annotations for pipeline and expert parallelism to an MoE transformer model. Scheduling directives place chunks on devices, replicate and shard weights for DP and EP, split the batch into microbatches, assign logical GPU streams for different communication types, and impose temporal orders that enable microbatch overlaps. The compiler transforms the single-device DAG into a global distributed DAG with inserted communication nodes. The runtime then schedules GPU streams and executes the plan, realizing efficient intra- and inter-device parallelism.
Technical innovations
- Decoupling user-specified high-level parallelism strategy declaration from runtime execution via an intermediate global training DAG IR.
- A compact user scheduling API combining annotations and scheduling directives that precisely transform the unified IR to express arbitrary compositions of DP, PP, EP, ZeRO, and microbatch overlap.
- Introduction of a unified IR that models all communication and computation nodes with data and temporal dependencies to enable joint scheduling and optimization of all resources across devices.
- A strategy-agnostic distributed runtime that executes per-device plans generated from IR with logical GPU stream abstractions to support fine-grained intra-device concurrency and communication overlap.
Baselines vs proposed
- Megatron: throughput = baseline vs Piper: throughput = +6-30% improvement on composed parallelism strategies (e.g., DualPipe)
- DeepSpeed: throughput = baseline vs Piper: throughput = matches on common strategies like ZeRO, outperforms on composed strategies
- TorchTitan: throughput = baseline vs Piper: throughput = +6-30% improvement on combined parallelism schemes
- Other frameworks: max batch size = baseline vs Piper: max batch size = up to 3-8x larger batch size when combining pipeline and ZeRO parallelism
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.11169.
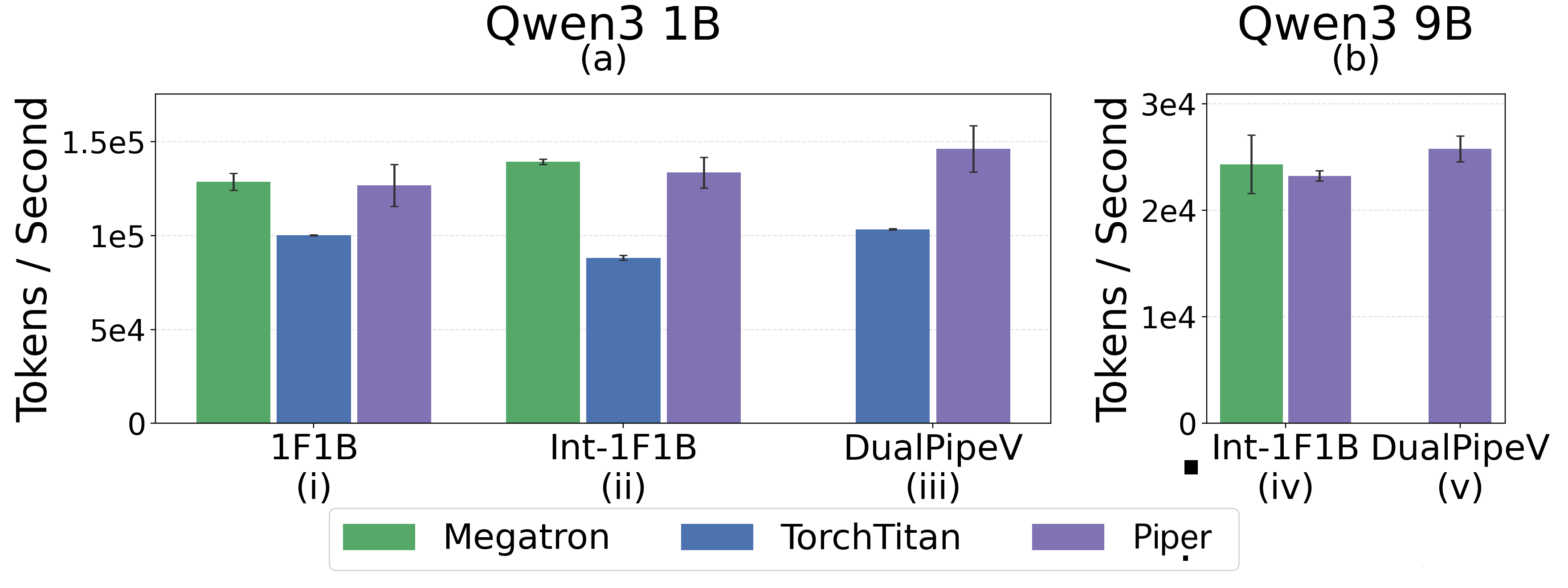
Fig 7: PP x EP throughput for 1F1B, Interleaved 1F1B
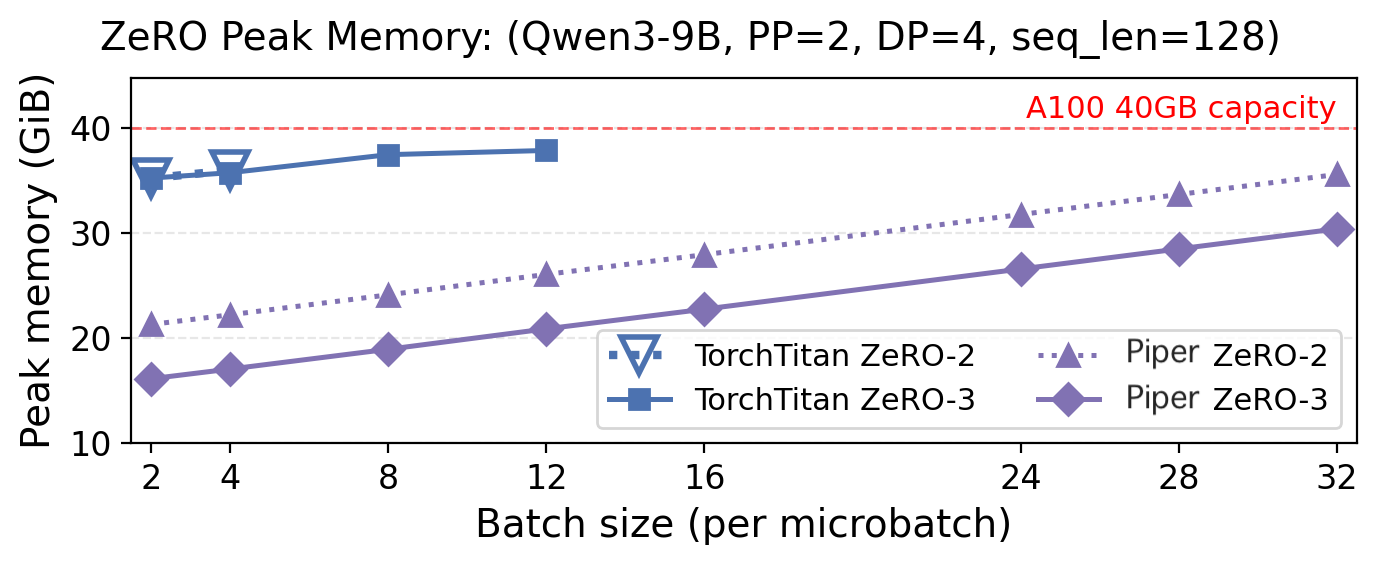
Fig 8: shows the results. Megatron, DeepSpeed, and
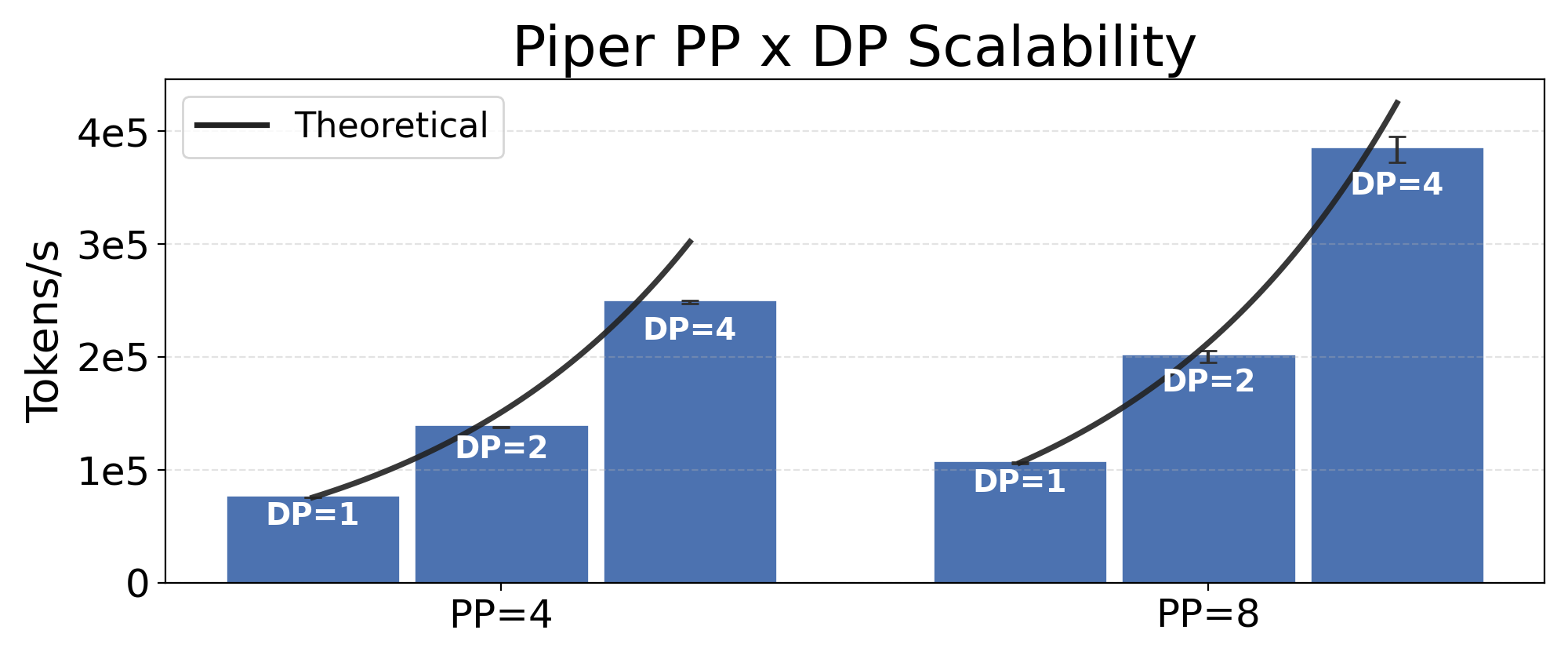
Fig 9: Piper PP x DP Scalability.
Limitations
- Paper does not provide open-source code or detailed instructions for replication, limiting reproducibility without proprietary internal components.
- No explicit adversarial or fault tolerance evaluation; system correctness and robustness under adverse failure conditions not studied.
- Limited discussion of overhead induced by the compiler and runtime scheduling latency, which may affect scalability in larger clusters.
- Performance results appear focused on a subset of composed parallel strategies (e.g., variants of DualPipe), with less coverage of tensor parallelism or emerging parallelism methods.
- User scheduling API requires manual annotation and directive specification, which could be complex for very large heterogeneous models without automation.
Open questions / follow-ons
- How to automatically synthesize or optimize scheduling directives to minimize expert engineering effort and maximize throughput?
- Can Piper's IR and runtime efficiently support emerging parallelism paradigms such as tensor model parallelism or fine-grained operator fusion?
- What are the trade-offs and best practices for combining multiple layers of intra-device parallelism and communication stream scheduling to minimize interference?
- How will Piper integrate with automated hyperparameter and system tuning frameworks for adaptive, workload-aware scheduling?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners focused on accelerating the training of large models, Piper provides an extensible system to implement sophisticated distributed training strategies combining different parallelisms and optimizations. The ability to declaratively specify and jointly optimize inter- and intra-device communication and computation enables scaling to larger batch sizes and higher throughput without rewriting low-level execution kernels. This can facilitate training more complex models that underpin CAPTCHAs or adversarial detectors with greater efficiency. Moreover, Piper's modular IR abstraction can help teams experiment rapidly with novel parallelism strategies, possibly advancing defenses that require large-scale model training.
However, practitioners should note that Piper requires some user expertise for annotations and scheduling directives and does not fully automate strategy search, so integrating with existing ML pipelines will require development effort. Also, the lack of open-source availability may constrain accessibility for rapid prototyping. Still, the underlying principles of decoupled strategy specification and unified DAG compilation offer valuable design insights for building custom scalable training systems for CAPTCHA-related ML workloads.
Cite
@article{arxiv2606_11169,
title={ Piper: A Programmable Distributed Training System },
author={ Megan Frisella and Shubham Tiwari and Andy Ruan and Yi Pan and Parker Gustafson and Mat Jacob and Gilbert Bernstein and Stephanie Wang },
journal={arXiv preprint arXiv:2606.11169},
year={ 2026 },
url={https://arxiv.org/abs/2606.11169}
}