
Optimizing 2D Input Representations and Sub-phase Fusion Strategies for Differential Diagnosis of Asthma and COPD Using CNN- and GRU-Based Networks
Source: arXiv:2606.10972 · Published 2026-06-09 · By Ipek Sen, Ozgur Ozdemir, Elena Battini Sonmez
TL;DR
This study addresses the challenge of differential diagnosis between asthma and COPD using acoustic analysis of multi-channel pulmonary sounds. Prior work showed good performance of a vector auto-regressive (VAR) model using classical machine learning on sub-phases of respiratory cycles, but comparisons with spectrogram-based input representations using deep learning were missing. The authors systematically investigate three 2D input representations derived from respiratory sounds: VAR coefficient matrices, mel-frequency cepstral coefficient (MFCC) matrices, and log-mel spectrograms, comparing the diagnosis performance between them. They also address the issue of varying temporal dimensions caused by variable respiratory cycle durations by comparing traditional trimming/zero-padding with an adaptive-length windowing method to fix input sizes. Different CNN architectures extract features from sub-phase or full-cycle inputs, which are then fused via direct concatenation, gated recurrent units (GRU), or GRU with attention. Data augmentation techniques were evaluated to combat limited data size. The best cycle-level F1-score of 0.877 was achieved with MFCC matrices using 13 coefficients and 64-point time resolution per sub-phase with direct feature concatenation. The best subject-level F1-score was 0.855 with MFCC using 256-point time resolution per full cycle. Notably, MFCC outperformed log-mel spectrogram and VAR, fusion strategies beyond simple concatenation did not improve performance, and data augmentation generally reduced accuracy, highlighting the importance of authentic data in pulmonary sound analysis.
Key findings
- Best respiratory cycle-based F1-score: 0.877 using MFCC matrices with 13 coefficients and 64-point time resolution per sub-phase, fused by direct concatenation.
- Best subject-based F1-score: 0.855 using MFCC matrices with 13 coefficients and 256-point time resolution per full-cycle, via adaptive-length windowing.
- MFCC outperformed both log-mel spectrogram and VAR model coefficients in asthma vs COPD differentiation.
- Adaptive-length windowing for temporal dimension equalization outperformed traditional trimming/padding, preserving more signal information.
- GRU and GRU with attention fusion strategies for sub-phase features did not improve diagnostic performance over simple concatenation.
- Mixup augmentation yielded the least performance degradation compared to other noise-based data augmentations, but overall augmentation reduced model accuracy.
- VAR method produced multiple 14x28 coefficient matrices per sub-phase due to stationarity windowing, complicating input compared to unified spectrogram matrices.
- Data comprised 228 full respiratory cycles from 50 subjects (30 asthma, 20 COPD) recorded with 14-channel lung sounds and flow signals, enabling sub-phase segmentation.
Methodology — deep read
Threat Model and Assumptions: The adversary context is not explicitly defined as this is a medical diagnostic study rather than a threat/attack-focused work. The main assumption is that the pulmonary sound signals contain discriminative patterns for asthma vs COPD diagnosis, and the classifiers can learn these from 2D representations despite data variability.
Data: The dataset includes multi-channel pulmonary sounds from 50 subjects (30 asthma, 20 COPD) recorded at a hospital in Istanbul. Recordings use 14 microphones on the posterior chest wall at 9600 Hz. Each 15-second recording contains multiple full respiratory cycles (228 full cycles total). Flow measurements enabled segmentation into six sub-phases per full cycle: early, mid, late inspiration and expiration, based on inhaled/exhaled air volume. The shortest full cycle was 1.31s, longest 6.15s. Sub-phase boundaries allow temporal localization of acoustic events.
Input Representations and Architecture: Three main 2D input types were computed per channel and merged: (a) VAR coefficient matrices derived by fitting a vector autoregressive model of order 2 on 250-sample (~26ms) overlapping segments, capturing spatio-temporal relationships across 14 channels; (b) MFCC matrices computed by STFT followed by mel filter banks and discrete cosine transform, producing time-frequency cepstral features; and (c) log-mel spectrograms computed similarly but without DCT.
For MFCC and log-mel spectrograms, the temporal dimension varies with respiratory phase length, posing input size challenges for CNNs requiring fixed input dimension. Two strategies addressed this: trimming/padding all signals to fixed duration, or adaptive-length windowing where the STFT window length is adjusted per signal to achieve fixed temporal resolution (number of time frames) in the representations.
CNN architectures for feature extraction included ResNet, Wide-ResNet, DenseNet, VGG, a custom CNN, and temporal convolutional networks (TCN). Input tensors had dimensions time x frequency x channels. Sub-phase or full-cycle inputs were processed differently.
For fusing sub-phase features, three approaches were tested: direct concatenation of CNN-extracted features from all six sub-phases, GRU networks to model temporal relationships across sub-phases, and GRU with attention mechanisms.
Training Regime: Models were trained with cross-validation using respiratory-cycle-based or subject-based splits. Data augmentation techniques including noise injection and mixup were evaluated. The study tested different hyperparameters for spectral (number of mel filters: 13, 26, 39) and temporal resolutions (number of time frames: 64, 256, etc). CNNs were trained to minimize classification loss; specific optimizers, epochs, batch sizes, and hardware were not detailed.
Evaluation Protocol: Performance metrics were primarily F1-score at the respiratory cycle level and subject level. Subject decisions were derived by majority voting over multiple cycle predictions. Comparisons were made between input representations, temporal dimension fixing methods, fusion strategies, and augmentation scenarios.
Reproducibility: The dataset is local and not publicly available. The paper does not mention public code or pretrained weights being released. Parameter grids and designs are described in detail permitting partial reproduction.
Example Walkthrough: A respiratory cycle from a subject is segmented into six sub-phases based on flow signal. For each sub-phase, MFCC matrices with 13 mel filters are computed using adaptive-length windowing to normalize temporal dimension to 64 frames. Each resulting 2D matrix (time x frequency) is multi-channel (14 channels). These are input separately into a CNN feature extractor producing per sub-phase features. The six feature vectors are concatenated and fed to a final classifier layer producing the class prediction for that respiratory cycle. This cycle-level prediction contributes to the subject-level diagnosis via majority vote.
Technical innovations
- Application and comparative evaluation of VAR coefficient matrices versus spectrogram-based 2D representations (MFCC, log-mel) for multi-channel pulmonary sound classification.
- Introduction and optimization of an adaptive-length windowing approach to equalize temporal dimensions of spectro-temporal inputs derived from variable-length respiratory sub-phases.
- Novel evaluation of sub-phase fusion strategies including direct concatenation, GRU, and GRU with attention mechanisms for improved temporal modeling of respiratory cycle segments.
- Systematic optimization of spectral and temporal resolution hyperparameters (e.g., mel filter counts and time frames) tailored specifically to pulmonary sound diagnosis.
Datasets
- Local 14-channel pulmonary sound dataset — 50 subjects, 228 full respiratory cycles — Yedikule Chest Disease Hospital, Istanbul
Baselines vs proposed
- VAR model (cycle-level F1): 0.830 vs MFCC adaptive windowing with concatenation: 0.877
- Log-mel spectrogram (cycle-level F1): not explicitly stated but lower than MFCC
- Direct concatenation fusion (F1): 0.877 vs GRU fusion (F1): no improvement (exact numbers not given)
- No augmentation (F1): 0.877 vs mixup augmentation (best augmentation) (F1): lower
- Subject-based evaluation MFCC (F1): 0.855 (best) vs baseline VAR model: lower (exact number not specified)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.10972.
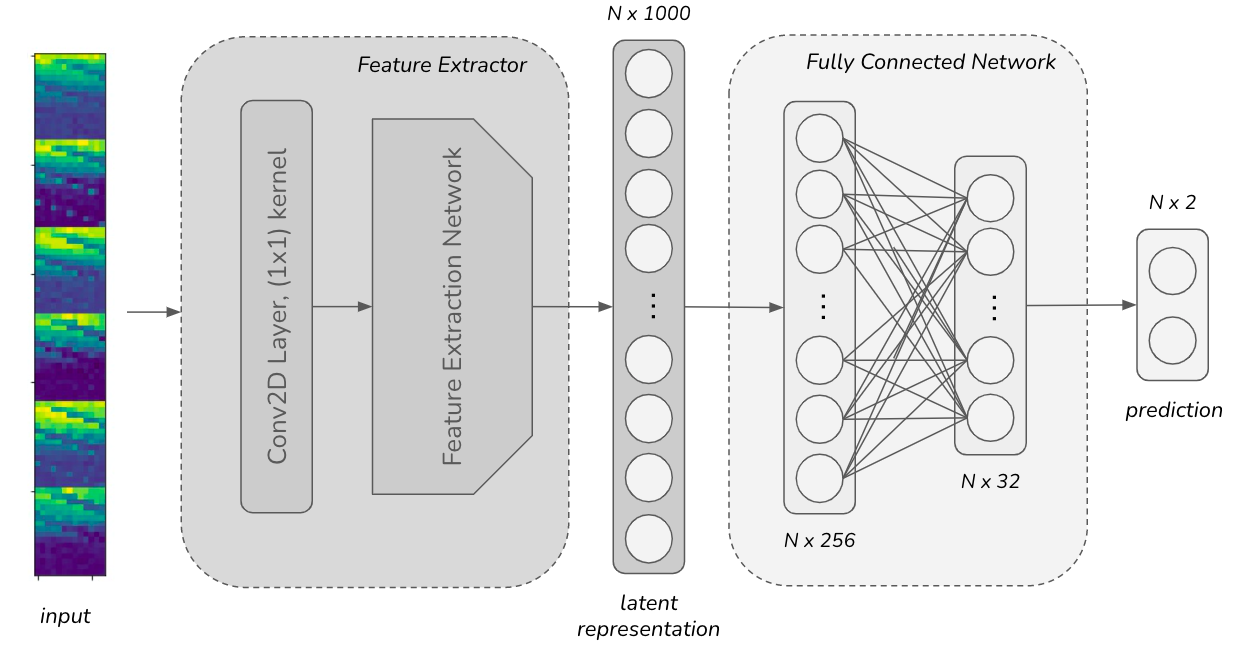
*Fig 1: Overall structure of the networks. FE: Feature extractor
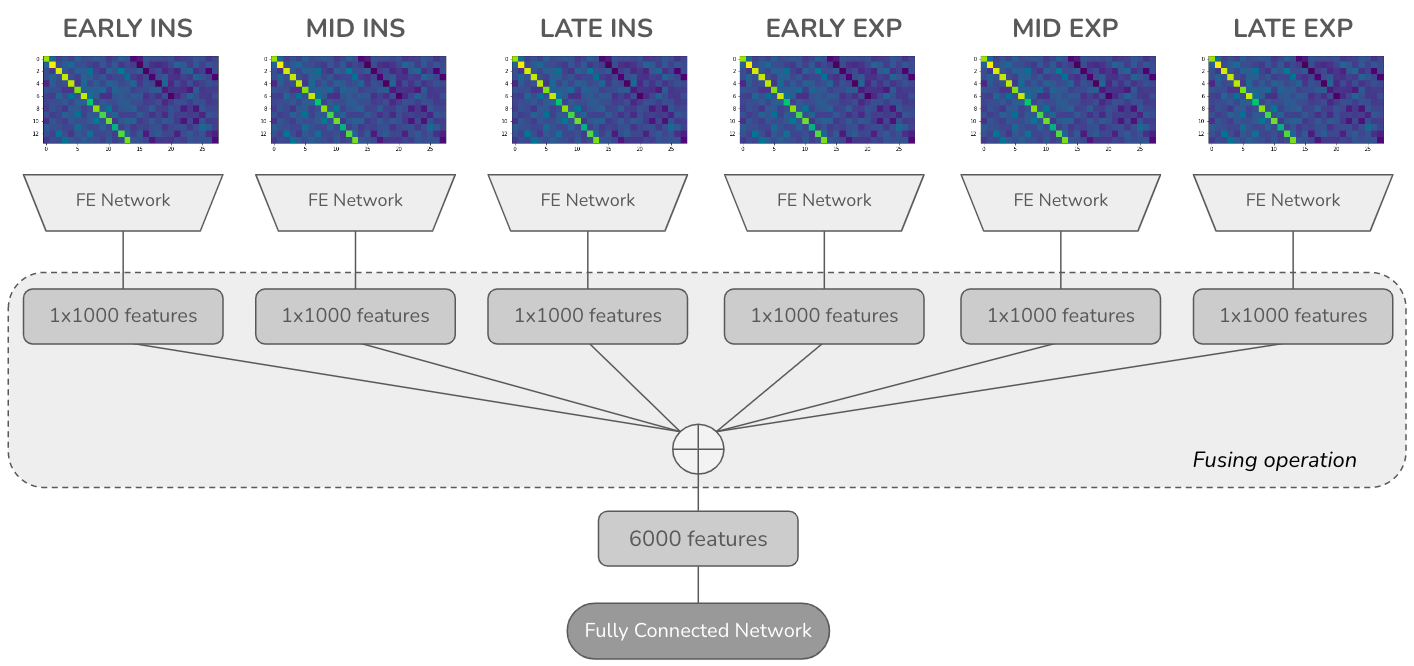
Fig 2 (page 9).
Limitations
- Dataset limited to 50 subjects from a single hospital with a class imbalance (30 asthma, 20 COPD), limiting generalizability.
- No external or multi-site validation; results may not transfer to other recording setups or populations.
- Data augmentation techniques did not improve performance, but only a few methods were tested; other augmentation approaches remain unexplored.
- The VAR model input requires multiple overlapping segments and complex fusion, increasing computational demands compared to spectrogram inputs.
- Details on training hyperparameters, optimizer, epochs, and statistical significance tests are sparse or missing, limiting reproducibility.
- No explicit adversarial robustness or noise sensitivity testing was performed on the models.
Open questions / follow-ons
- Can larger, more diverse multi-center pulmonary sound datasets validate the superiority of MFCC with adaptive windowing in clinical practice?
- Would alternative or more advanced data augmentation methods improve robustness without degrading performance?
- Could joint learning of sub-phase segmentation and classification in an end-to-end neural architecture further improve diagnosis accuracy?
- How do environmental noise and varied recording conditions affect the comparative performance of VAR vs spectrogram-based methods?
Why it matters for bot defense
For bot-defense or CAPTCHA practitioners, this paper offers insights into handling variable-length time series data for classification via adaptive windowing to normalize input dimensions. The demonstrated benefits of MFCC spectrogram representations and simple feature concatenation over more sophisticated fusion mechanisms emphasize the value of straightforward architectures when modeling multi-phase structured data. The negative impact of data augmentation underscores a cautionary note: synthetic transformations may degrade model effectiveness when authentic signal variability is critical, mirroring challenges in bot detection where realistic samples matter. Although focused on medical sound classification, principles around multi-channel temporal feature extraction, segment-level fusion, and temporal dimension equalization can inspire analogous strategies in bot and CAPTCHA behavioral signal processing pipelines.
Cite
@article{arxiv2606_10972,
title={ Optimizing 2D Input Representations and Sub-phase Fusion Strategies for Differential Diagnosis of Asthma and COPD Using CNN- and GRU-Based Networks },
author={ Ipek Sen and Ozgur Ozdemir and Elena Battini Sonmez },
journal={arXiv preprint arXiv:2606.10972},
year={ 2026 },
url={https://arxiv.org/abs/2606.10972}
}