
Mean Flow Distillation: Robust and Stable Distillation for Flow Matching Models
Source: arXiv:2606.11155 · Published 2026-06-09 · By An Zhao, Shengyuan Zhang, Zhongjian Sun, Yixiang Zhou, Zejian Li, Ling Yang et al.
TL;DR
Flow Matching (FM) models excel at generative tasks but suffer from slow ODE-based iterative sampling, limiting real-time use. Prior distillation methods for accelerating FM often adapt score-based diffusion techniques, which do not leverage FM's deterministic velocity field structure and suffer from instability and high variance. This paper introduces Mean Flow Distillation (MFD), a novel distillation framework that directly aligns time-integrated mean velocity fields rather than instantaneous velocities or scores. Theoretically, MFD acts as a temporal low-pass filter reducing high-frequency noise inherent in variational score distillation (VSD), and the authors prove a Mean Flow Matching Theorem showing that matching expected average velocities suffices for strict distribution alignment.
Empirically, MFD outperforms prior distillation methods on challenging tasks including 4D occupancy forecasting and text-to-image generation. Compared to 10-step teacher models, MFD achieves near-equal accuracy with single-step generation, increasing inference speed roughly 10x while maintaining high fidelity. Ablations confirm the importance of temporal integration for robustness. MFD enables stable training with lower gradient variance than VSD, enabling practical and effective speedup of flow matching generators.
Key findings
- MFD reduces the sampling steps from 10 to 1 on OccFM (4D occupancy forecasting) with only a 1.2% drop in IoU (37.07% vs 37.52%) and 4.4% drop in mean IoU while doubling FPS from 12.72 to 25.19 on a single RTX 3090 (Table 1).
- Compared to prior distillation baselines (Diff-Instruct, CD, AYF, DMD2, SenseFlow), MFD achieves the highest IoU and mIoU scores on 4D occupancy forecasting, exceeding AYF by 4.69% IoU and 5.56% mIoU.
- Matching the time-integrated average velocity (mean flow) yields lower gradient variance and more stable training dynamics than instantaneous velocity or score matching, as shown theoretically (Section C.3) and empirically (Fig 2, loss distribution).
- Ablation on ODE solver step size (for numerical integration in MFD) shows best performance with intermediate step sizes (0.005–0.02), indicating robustness to approximation precision (Table 2).
- In text-to-image generation on the LAION-aesthetic-6.5+ dataset, MFD outperforms multiple state-of-the-art baselines across five metrics (Aesthetic Score, PickScore, HPSv2, ImageReward, CLIP Score) and reduces FID relative to teacher samples, demonstrating superior generation quality.
- MFD training algorithm alternates between updating an auxiliary flow model and the student generator at a 10:1 ratio, ensuring the auxiliary flow closely tracks the evolving student distribution (Algorithm 1).
- Theoretical contributions include formal proofs of Instantaneous Velocity Field Matching (Theorem 4.1) and Mean Flow Matching Theorem (Theorem 4.3) establishing sufficient conditions for exact distributional alignment via velocity fields.
Threat model
n/a — the paper addresses distillation efficiency and stability for flow matching generative models rather than adversarial security. The adversary model typical to security or bot defense is not applicable here.
Methodology — deep read
Threat Model & Assumptions: The task is to distill a pretrained high-fidelity Flow Matching (FM) teacher model uQ, which defines deterministic ODE transport between a known source distribution p0 (standard Gaussian) and a complex target distribution Q, into a single-step student model Gθ. The adversary is an implicit generative setting; robustness to adversarial attacks is not studied. The assumption is that uQ is frozen and accurate, and the goal is to align the student distribution P to Q.
Data: Two primary tasks evaluated: 4D occupancy forecasting using the nuScenes dataset (~100k LiDAR sweeps) and text-to-image generation using SANA 1.6B model on LAION-aesthetic-6.5+ dataset (several million images). For occupancy forecasting, IoU and mIoU metrics measure spatial-temporal occupancy prediction quality. For text-to-image, multiple human-aligned and semantic metrics are used.
Architecture/Algorithm: The student model Gθ is a single-step generator mapping noise X0 to X1. Because Gθ does not produce a velocity field, an auxiliary flow model vP (same input/output as the teacher's velocity field uQ) is introduced and trained to approximate the instantaneous velocity field of the student distribution P. Both uQ and vP are vector fields Rd×[0,1] → Rd.
Mean Flow Distillation operates by sampling intermediate time points s, t (0 ≤ s < t ≤ 1) and initial noise X0. Linear interpolation produces intermediate state Xs = (1−s)X0 + sX1. Then, numerical ODE solvers integrate the auxiliary and teacher velocity fields from Xs over [s,t] to compute average velocity vectors (mean flows) ˆU_P and ˆU_Q. The student Gθ is updated to minimize the squared difference of these average velocities, backpropagating gradients through samples but omitting the Jacobian of the integration for computational efficiency (Equation 20).
Training Regime: Algorithm 1 alternates between updating the auxiliary model vϕ and the student Gθ using a Two Time-Scale Update Rule (TTUR) of 10:1 (10 steps for auxiliary per student step). Each update uses batches sampled from p0 and uniform times s,t. Details on batch size, epochs, optimizer, and hyperparameters are in Appendix A.3 (not fully detailed in paper extract).
Evaluation Protocol: Metrics vary per task: IoU/mIoU and FPS for occupancy forecasting; Aesthetic Score, PickScore, HPSv2, ImageReward, CLIP Score, and FID for text-to-image. Baselines include multiple prior distillation approaches: Diff-Instruct (VSD-based), Consistency Distillation, AYF, DMD2, SenseFlow, and teacher with varying sampling steps. Ablations test ODE solver step size and Jacobian omission. Loss distributions and training stability are examined.
Reproducibility: Authors release code at https://github.com/happyw1nd/MFD. Models trained from pretrained teacher checkpoints (SANA for text-to-image, OccFM for occupancy). Datasets are publicly known (nuScenes, LAION). Numerical details for solver and hyperparameters partially reported in Appendix. Exact seeds not specified.
Example Workflow: Sample noise X0 ∼ N(0,I). Generate X1 = Gθ(X0). Sample s,t ∈ [0,1]. Compute intermediate interpolated state Xs = (1−s)X0 + sX1. Numerically integrate teacher and auxiliary velocity fields from Xs over [s,t] via ODE solver Φ to compute mean flows ˆU_Q and ˆU_P. Optimize student Gθ parameters θ to minimize L2 difference between ˆU_P and ˆU_Q via gradient descent, with auxiliary model vϕ updated more frequently to track student distribution velocity fields. Repeat for many steps until convergence with stable, low-variance gradients.
Technical innovations
- Formulation and proof of the Mean Flow Matching Theorem (Theorem 4.3) establishing that matching expected average velocity fields over time intervals suffices for strict distribution alignment between teacher and student flows.
- Introduction of the Mean Flow Distillation framework which supervises the student by matching time-integrated average velocity vectors computed via ODE integration, acting as a temporal low-pass filter to reduce gradient variance compared to instantaneous velocity or score-based distillation.
- Alternating optimization strategy employing an auxiliary flow model to approximate the student model's velocity field, enabling direct velocity-based supervision without converting velocity fields into scores as prior methods do.
- Simplified gradient computation that omits the Jacobian through the ODE solver during backpropagation, reducing computational complexity while maintaining theoretical soundness similar to Score Distillation Sampling (SDS).
Datasets
- nuScenes — ≈100,000 LiDAR sweeps — public for 4D occupancy forecasting
- LAION-aesthetic-6.5+ — millions of image-caption pairs — public dataset commonly used for text-to-image generation
Baselines vs proposed
- OccFM Teacher (10 steps): IoU = 37.52%, mIoU = 28.49%, FPS = 12.72
- OccFM Teacher (1 step): IoU = 27.42%, mIoU = 8.15%, FPS = 24.92
- Diff-Instruct (1 step): IoU = 36.41%, mIoU = 26.42%, FPS = 25.21
- Consistency Distillation (CD) (1 step): IoU = 31.69%, mIoU = 20.70%, FPS = 25.08
- Align Your Flow (AYF) (1 step): IoU = 32.38%, mIoU = 21.69%
- DMD2 (1 step): IoU = 35.84%, mIoU = 24.27%, FPS = 25.11
- SenseFlow (1 step): IoU = 35.40%, mIoU = 23.91%, FPS = 25.09
- MFD (1 step): IoU = 37.07%, mIoU = 27.25%, FPS = 25.19
- FID (text-to-image, precise values not given) improved by MFD vs baselines such as Diff-Instruct, Consistency Distillation, AYF
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.11155.
Fig 1: Overview of Mean Flow Distillation (MFD). (1) Sample noise X0 ∼N(0, I), generate X1 via the single-step student model
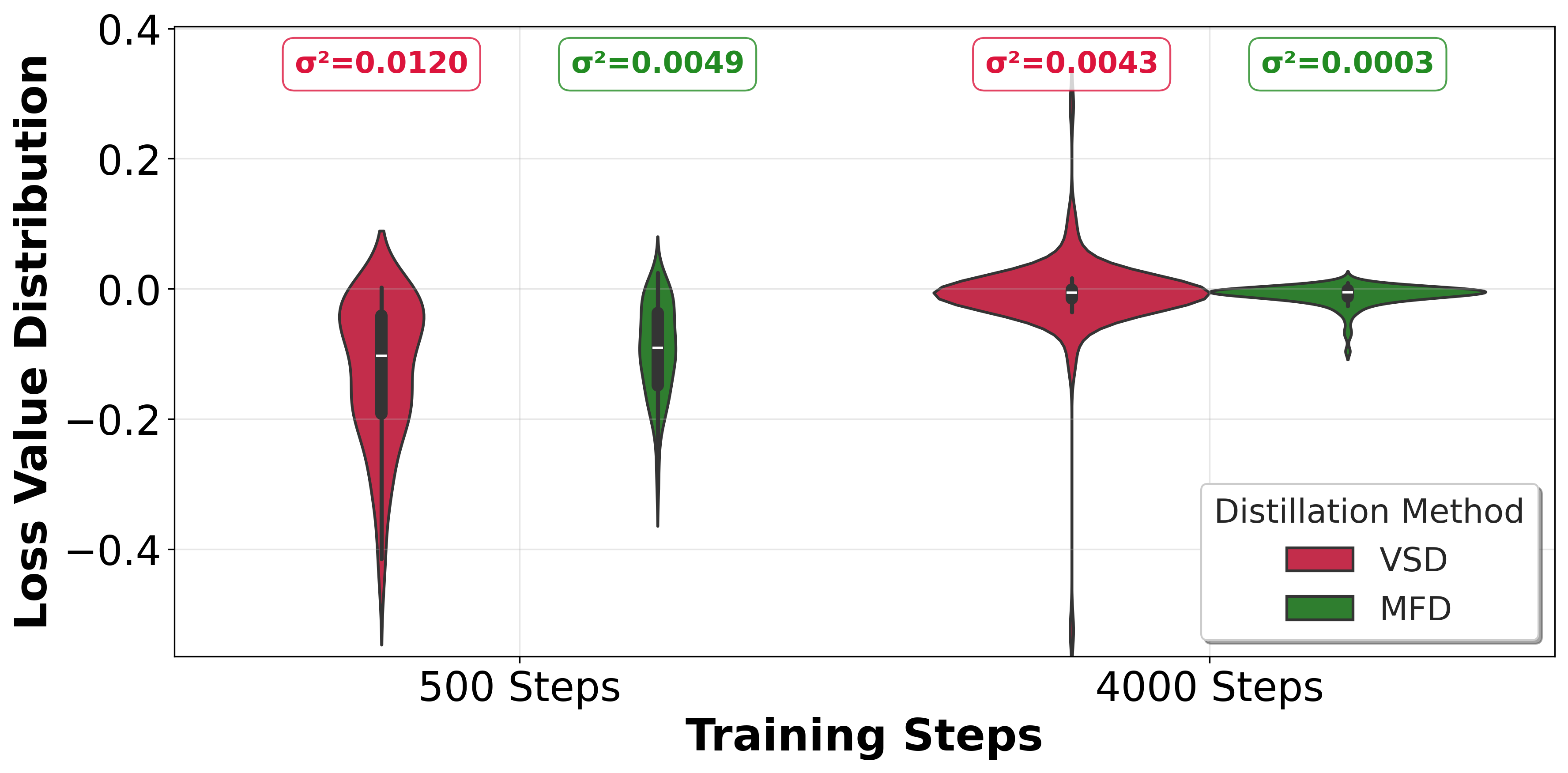
Fig 2: Loss distribution between MFD and Diff-Instruct on
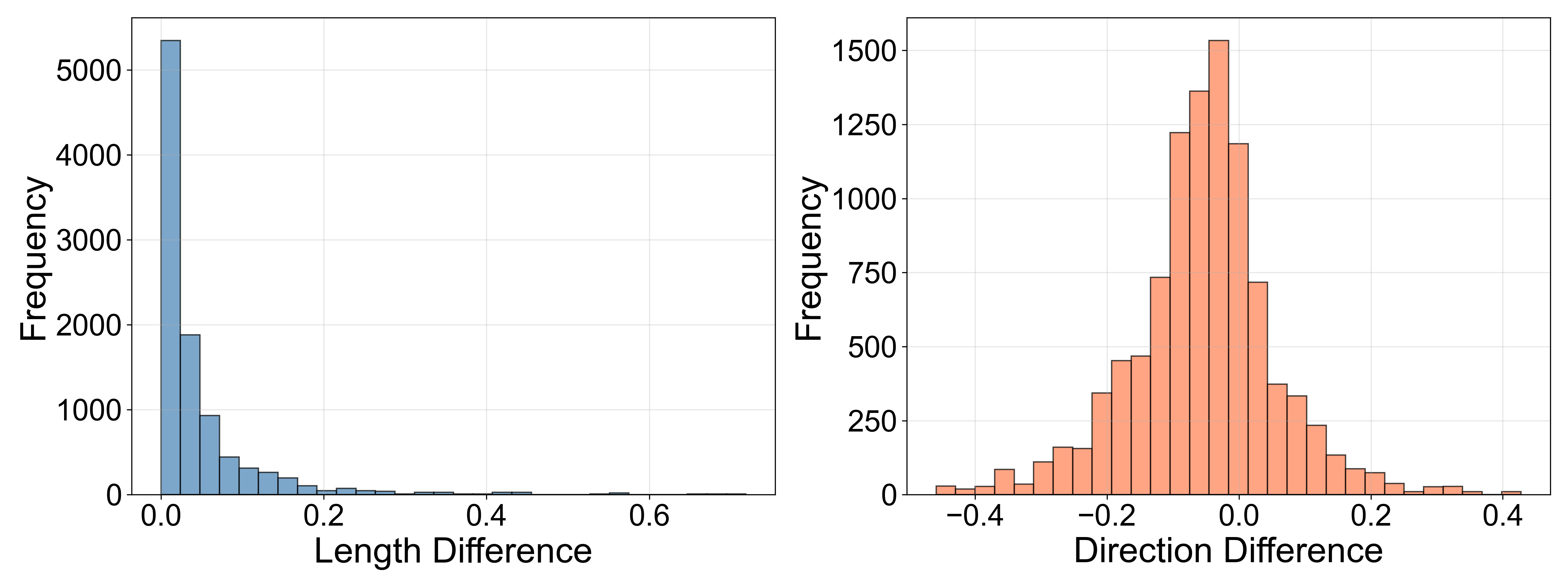
Fig 3: Comparison of gradient differences when computing vs. omitting the Jacobian term during backpropagation to Xs over 10,000
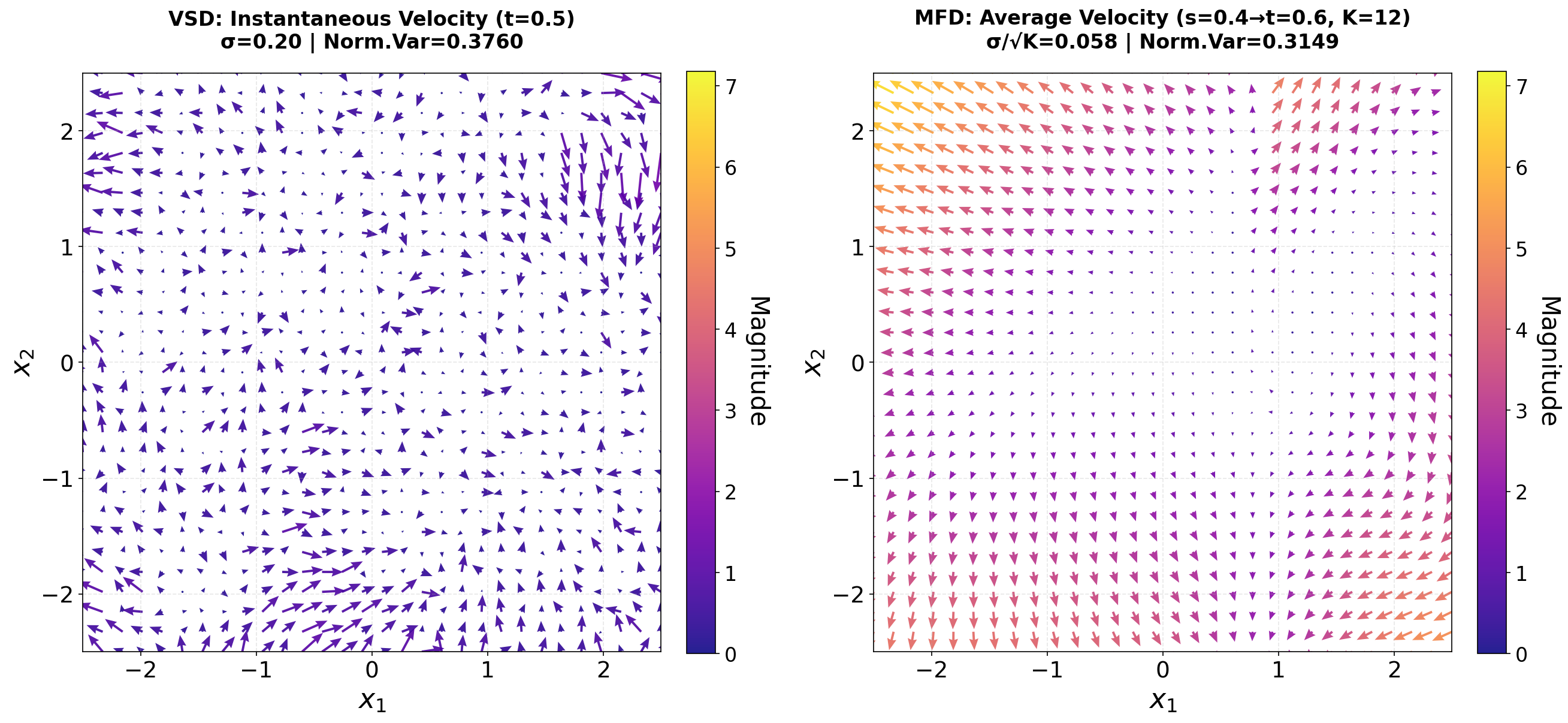
Fig 4: Comparison of gradient vector fields on a 2D toy example under equivalent noise conditions. Left: VSD with instantaneous

Fig 5: Qualitative comparison of 4D occupancy forecasting results on nuScenes. We visualize the predicted occupancy grids from (a)

Fig 6: Training loss curves comparing MFD and VSD-based Diff-Instruct on text-to-image generation. MFD exhibits significantly
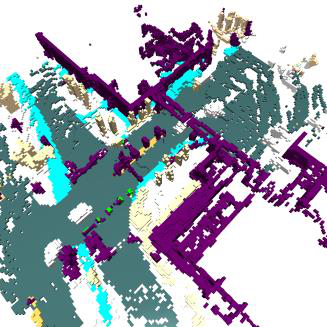
Fig 7: Evolution of L2 distance (in log scale) between teacher mean flow ˆU Q and auxiliary mean flow ˆU P during text-to-image

Fig 8 (page 28).
Limitations
- MFD requires an auxiliary flow model during training, increasing complexity; inference speed benefits are despite this auxiliary model being unused at run time.
- The approach relies on accurate numerical ODE integration for mean flow estimation; although robust to solver step size within a range, extreme step sizes degrade performance.
- The Jacobian term for gradient backpropagation through the ODE solver is omitted for efficiency, which is theoretically justified but could impact gradient accuracy in edge cases.
- Experiments focus on two domains (4D occupancy forecasting and text-to-image); generalization to other generative tasks or modalities is not demonstrated.
- Robustness against adversarial inputs or out-of-distribution conditions is not analyzed.
- The auxiliary model capacity and training stability at very large scale or with very complex velocity fields would require further study.
Open questions / follow-ons
- How does Mean Flow Distillation scale to even larger flow matching models or higher-dimensional generative tasks beyond text-to-image and 4D occupancy forecasting?
- Can the auxiliary flow model be fully removed or integrated into the student model to simplify training and reduce overhead?
- What are the theoretical limits of variance reduction achievable by temporal integration, and can alternative integration or filtering strategies improve stability further?
- Could the concept of mean flow matching be extended to conditional generative models or other continuous normalizing flow variants with more complex geometries?
Why it matters for bot defense
For practitioners in bot defense and CAPTCHA design aiming to accelerate high-fidelity generative models (for example, in generating synthetic data or challenges), MFD offers a theoretically grounded method to distill expensive iterative flow matching models into efficient single-step generators without sacrificing distributional fidelity. By working directly in velocity space matching integrated flow trajectories, MFD provides more stable training signals and lower variance gradients compared to prior score-distillation approaches. This can enable practical deployment of high-quality generative components in real-time environments requiring rapid generation.
Moreover, the mean flow idea highlights the importance of leveraging temporal integration and global geometric constraints in distillation. Captcha or bot detection systems involving generative models could benefit from more stable and robust distilled models that maintain fine feature quality with greatly reduced inference cost. The auxiliary flow model concept may also inspire augmentation strategies for stability in production pipelines. However, implementation complexity and numerical integration costs should be carefully balanced depending on application constraints.
Cite
@article{arxiv2606_11155,
title={ Mean Flow Distillation: Robust and Stable Distillation for Flow Matching Models },
author={ An Zhao and Shengyuan Zhang and Zhongjian Sun and Yixiang Zhou and Zejian Li and Ling Yang and Tianrun Chen and Lingyun Sun },
journal={arXiv preprint arXiv:2606.11155},
year={ 2026 },
url={https://arxiv.org/abs/2606.11155}
}