
From the microscope to High Performance Computing centers, a national effort toward automated data workflows for microscopy facility users in France
Source: arXiv:2606.10879 · Published 2026-06-09 · By Guillaume Gay, Théo Barnouin, Marc Mongy, Guillaume Maucort, Perrine Paul-Gilloteaux, Emmanuel Faure
TL;DR
The paper addresses the growing challenge of managing large and complex biological microscopy data which include multidimensional, multimodal, and time-resolved images. Despite advances in imaging technology, data management has lagged behind, often relying on fragmented, heterogeneous local solutions that are difficult to maintain, scale, and integrate with HPC centers and public archives. To overcome these limitations, France BioImaging (FBI) developed the FBI.DATA initiative and its BioImage Cloud platform, establishing a coordinated national infrastructure integrating 30 microscopy facilities, centralized data centers, HPC resources, and public repositories.
The architecture consolidates open-source services such as OMERO for image management, iRODS for distributed data orchestration, and Authentik for federated authentication, while adopting emerging community standards like OME-Zarr and REMBI metadata recommendations. Designed to support the complete data lifecycle—from acquisition through transfer, annotation, visualization, analysis, sharing, and archiving—the system represents a sustainable, scalable approach to FAIR-compliant microscopy data stewardship. Beyond technical design, the paper emphasizes organizational governance, interoperability, sustainability, and user adoption strategies. This national-scale integration lays foundation for future AI-driven bioimage analysis by enabling tighter proximity between imaging data and HPC resources.
Key findings
- FBI.DATA federates 30 microscopy facilities and supports approximately 8,000 users annually across France.
- The infrastructure uses OMERO, iRODS, and Authentik combined for flexible, scalable data management decoupling storage from applications.
- Centralized storage is hosted in two national data centers with local buffer servers facilitating data ingestion, reducing the need for local 'under-the-table' disks.
- Data lifecycle workflows cover acquisition, secure transfer, metadata annotation, visualization, analysis on HPC, sharing, and open archiving (BioImage Archive).
- Use of OME-Zarr as an emerging cloud-optimized file format supports handling massive chunked bioimaging arrays.
- A 3.8 full-time equivalent multidisciplinary team supports national infrastructure maintenance versus prior fragmented local strategies requiring more human resource investments per site.
- Unified federated authentication via Authentik and eduGAIN simplifies user onboarding and consistent PI/team access management.
- Governance includes national committees and coordination with international initiatives such as EuroBioImaging and Global BioImaging to maintain alignment and interoperability.
Threat model
The adversary model primarily considers threats to data confidentiality and integrity within a collaborative academic environment; adversaries aim to gain unauthorized access to microscopy data or metadata. The system counters with federated authentication, secure data transport, and centralized access control but does not explicitly consider active malicious attacks such as data poisoning or denial-of-service. Physical security relies on national data center infrastructure.
Methodology — deep read
Threat model & assumptions: The work assumes a benign research user environment focused on trusted academic users; primary adversarial concerns addressed are data security and access control, not active adversarial sabotage or circumvention. Federated identity management via Authentik secures credential handling.
Data provenance, size, labels, splits: Data originate from 30 distributed microscopy facilities spanning multiple imaging modalities and complexities (3D, time-lapse, multimodal). The system handles thousands of datasets yearly with diverse file formats and metadata. No explicit machine learning labels or supervised classification datasets are involved; instead, the emphasis is on structured acquisition metadata and harmonized annotation aligned with REMBI standards.
Architecture/algorithm: The platform integrates OMERO for image and metadata management, iRODS acting as a rule-oriented data system middleware decoupling physical storage from applications, and Authentik for unified federated authentication. Omero-Quay manages scheduling and orchestration of tasks. The design prioritizes modularity, with data ingestion via local buffer servers facilitating asynchronous and secure transfer to centralized HPC storage nodes. Metadata are enriched using standardized models (REMBI, ISA).
Training regime: The infrastructure is maintained by a multidisciplinary team of 3.8 full-time equivalents across institutions, with ongoing 'train-the-trainer' programs for local IT referents to scale user support and adoption. Frequent alpha/beta testing phases coordinate updates and new feature deployments across the national network.
Evaluation protocol: The paper does not present quantitative benchmarking but evaluates success via qualitative impacts such as user adoption across 8,000 users, governance efficacy, and interoperability with international systems. User experience and administrative friction reduction are core success metrics. Compliance with FAIR principles and integration with BioImage Archive are indicators of archival and reproducibility effectiveness.
Reproducibility: The platform builds upon open-source components (OMERO, iRODS, Authentik) with public documentation and alignment to community standards like OME-Zarr and REMBI. Some modules such as Omero-Quay scheduler and BioImage Cloud services are available online. The paper does not report closed datasets or frozen weights as no ML models are trained.
Example end-to-end: A microscopy dataset generated at a local facility is initially stored on a local buffer server which extracts metadata and optionally converts raw files to OME-Zarr format. Data and metadata are securely transferred to the national HPC data center via iRODS. The dataset becomes accessible through OMERO interfaces for visualization and annotation. Users can then launch analysis pipelines using HPC compute resources linked to the dataset location, avoiding large downloads. Upon project conclusion, validated datasets may be seamlessly published to the BioImage Archive for long-term preservation and public sharing.
Technical innovations
- Decoupling of physical storage and software applications via iRODS middleware enables flexible hardware evolution without disrupting users.
- Integration of federated authentication using Authentik combined with eduGAIN simplifies uniform user access management across multiple institutions.
- Adoption and promotion of OME-Zarr as a cloud-optimized file format for scalable, chunked bioimaging datasets supports future-proofing massive data handling.
- Implementation of a national-scale data lifecycle workflow federating 30 microscopy facilities, centralized HPC storage, and public archives for FAIR-compliant data stewardship.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.10879.
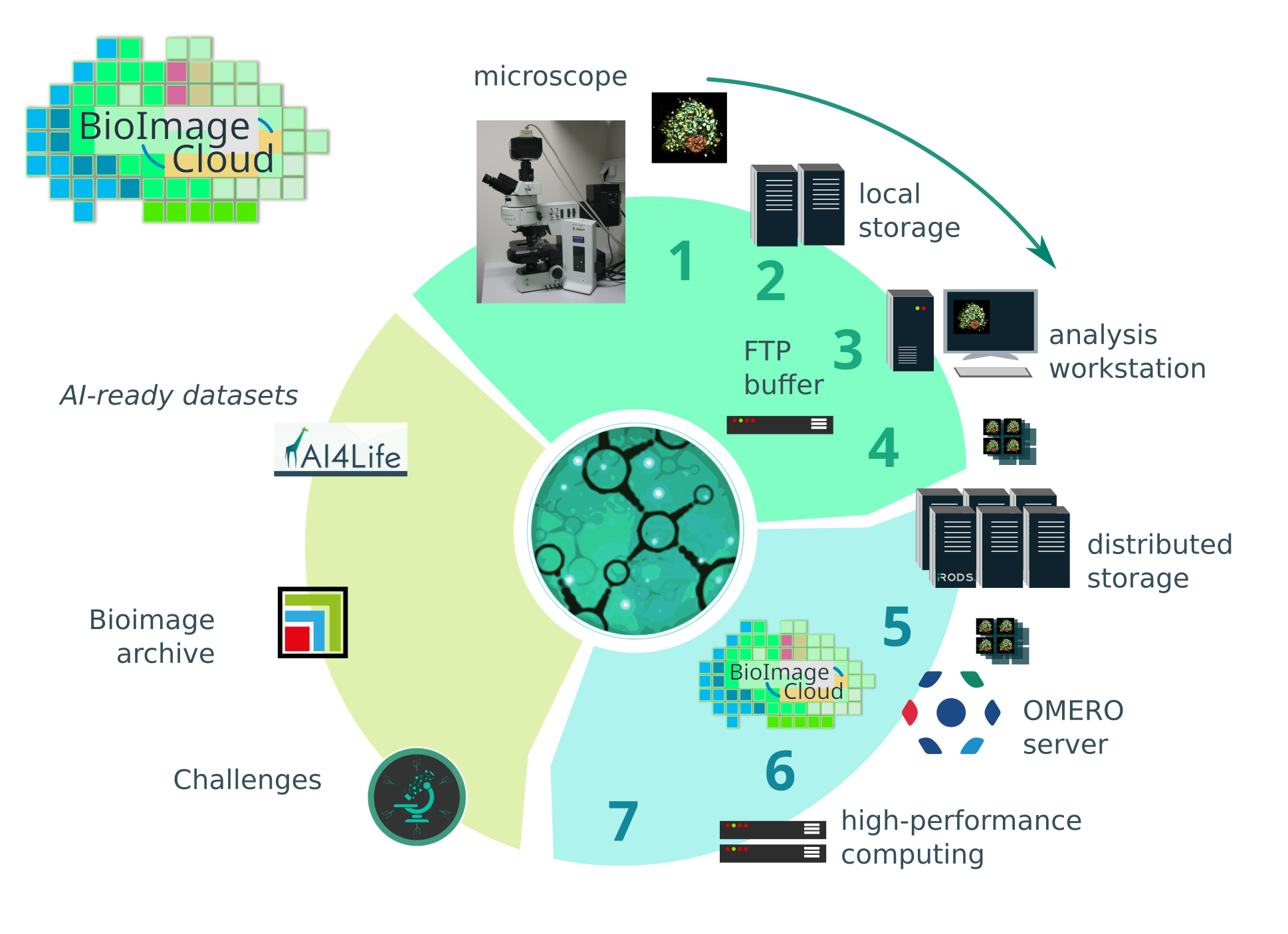
Fig 1: BioImage Cloud and the imaging data life cycle.
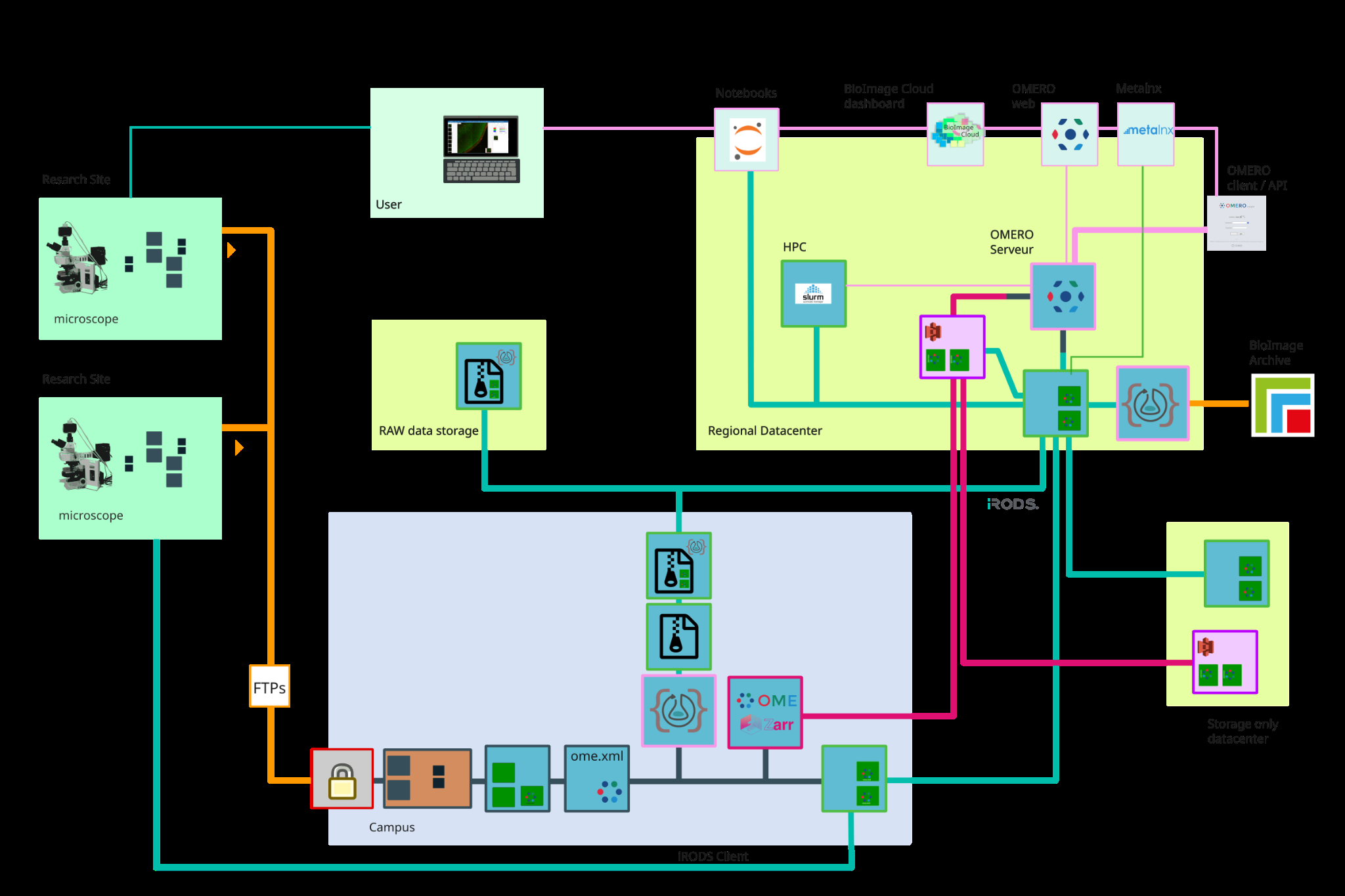
Fig 2: Data transport routes within the BioImage
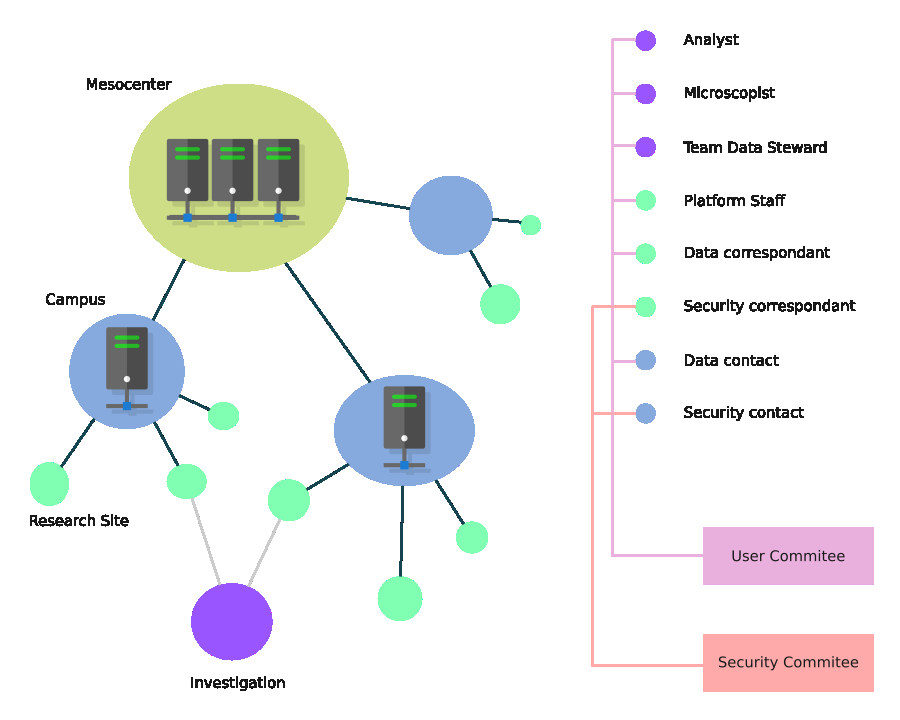
Fig 4: Detailed technical architecture of the BioImage
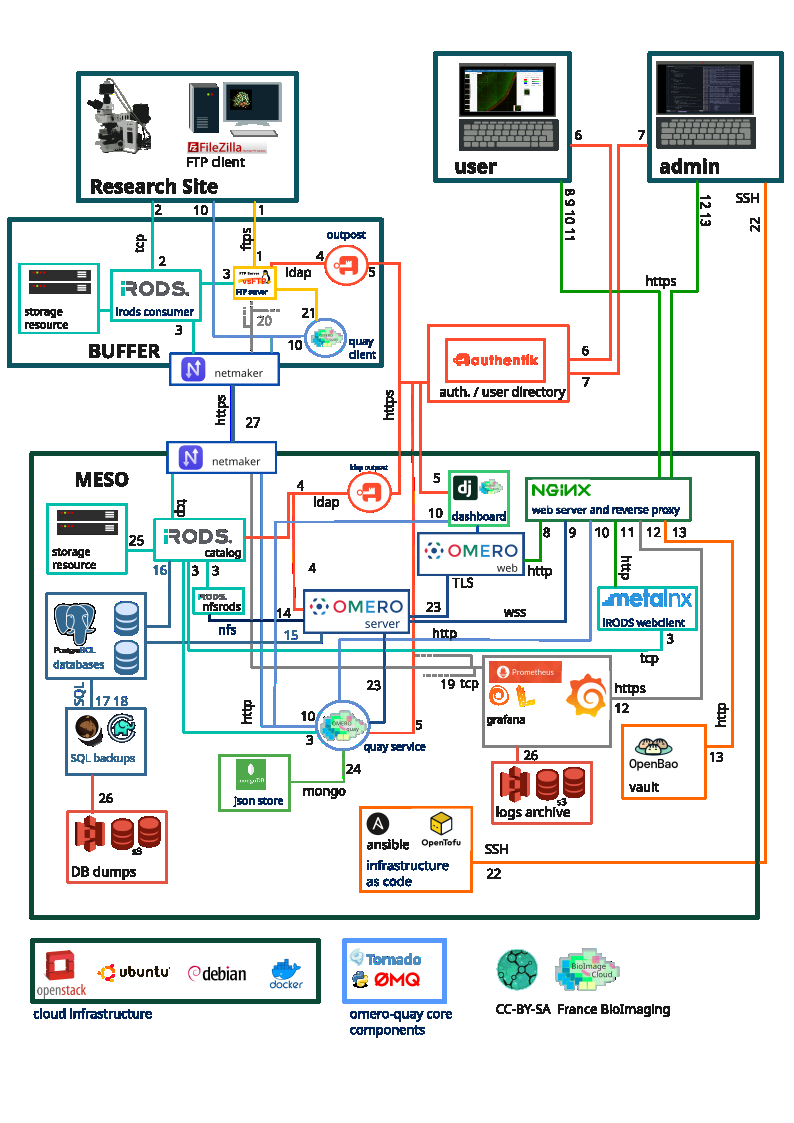
Fig 4 (page 24).
Limitations
- The paper lacks quantitative performance benchmarks or comparative metrics against prior local solutions or architectures.
- User adoption challenges remain significant; widespread community uptake is critical but not yet fully achieved.
- Long-term sustainability depends on continuous institutional funding and human resource commitments, which are subject to economic and organizational factors.
- Technological heterogeneity in microscopy data formats and metadata complexity present ongoing interoperability and standardization hurdles.
- Security threat modeling addresses secure data access but does not explore adversarial attacks on data integrity or confidentiality.
- Scalability beyond current 30 facilities and 8,000 users, especially under future 'big data' demands, remains to be demonstrated.
Open questions / follow-ons
- How can the platform support more automated, AI-driven metadata annotation and assisted curation workflows at scale?
- What strategies will best ensure sustained user adoption across diverse biological domains and facilities over time?
- How will increasing demands for real-time analysis and highly complex multimodal datasets impact system scalability and HPC integration?
- Can advanced iRODS features like 'intelligent datawaves' or federated 'One Data' abstractions be practically implemented to further decouple data location from usage?
Why it matters for bot defense
While not directly addressing bot-defense or CAPTCHA challenges, the FBI.DATA initiative demonstrates key principles applicable to large-scale, distributed data infrastructure management relevant to bot-defense ecosystems. Its federated authentication system and centralized yet scalable architecture offer insights into managing access control and data workflows across multiple institutions and heterogeneous endpoints. Furthermore, the focus on interoperability, metadata standardization, and user-friendly workflows resonates with the need for reliable, maintainable systems when integrating diverse bot/detection telemetry or user interaction data.
Bot-defense practitioners could draw lessons from FBI.DATA's governance framework and iterative deployment model for implementing resilient, sustainable infrastructures that handle large volumes of complex data while ensuring secure, auditable user access — key for CAPTCHA analytics or bot behavioral dataset management. The emphasis on minimizing local overhead and centralizing compute resources may inspire similar approaches for scalable bot detection pipelines operating over federated data sources.
Cite
@article{arxiv2606_10879,
title={ From the microscope to High Performance Computing centers, a national effort toward automated data workflows for microscopy facility users in France },
author={ Guillaume Gay and Théo Barnouin and Marc Mongy and Guillaume Maucort and Perrine Paul-Gilloteaux and Emmanuel Faure },
journal={arXiv preprint arXiv:2606.10879},
year={ 2026 },
url={https://arxiv.org/abs/2606.10879}
}