
Zero Touch Predictive Orchestration: Automating Time-Series Models for the Cloud-Edge Continuum
Source: arXiv:2606.09787 · Published 2026-06-08 · By Abd Elghani Meliani, Arora Sagar, Adlen Ksentini, Raymond Knopp
TL;DR
This paper addresses the cold start problem in proactive resource orchestration for the highly dynamic Cloud-Edge Continuum (CEC), where newly discovered edge nodes have insufficient local telemetry data to train accurate time-series predictive models. The authors propose a novel, fully automated Zero Touch Management (ZTM) architecture combining lightweight, plugin-based Resource Exposer (RE) modules that dynamically discover nodes and stream customizable local telemetry, with a high-resolution foundational dataset called TimeTrack. By merging sparse local samples with TimeTrack's dense 45-second interval data, and applying Neural Architecture Search (NAS), the system automatically generates highly accurate, deployment-ready forecasting models without manual data collection or tuning. Experimental results show this data-mixing approach significantly improves forecasting accuracy (MSE, MAE, MAPE) and accelerates convergence compared to training on sparse local data alone or traditional, coarse-grained public datasets. This establishes a robust foundation for continuous MLOps for proactive cloud-edge orchestration.
Key findings
- Merging sparse local telemetry with the TimeTrack dataset reduces forecast errors by an average of 20–30% across MSE, MAE, and MAPE compared to training on local data only (Section 5 results).
- TimeTrack is collected at 45-second intervals over 30 days, enabling capture of transient workload surges, unlike traditional 5-minute interval datasets (Table 1).
- The Resource Exposer (RE) plugin framework enables dynamic discovery of volatile, heterogeneous edge nodes and collection of arbitrary telemetry types (compute, network, energy).
- Automated NAS-driven model generation on the mixed dataset converges 2–3x faster than manually designed baseline architectures (Fig. 8).
- Training solely on generic datasets without target calibration produces models with 15–25% higher error due to data distribution shifts.
- Alternative public datasets with coarse 5-minute sampling miss critical microservice scaling events, leading to structurally impoverished forecasting models (Fig. 2).
- The end-to-end pipeline reduces model initialization delay, enabling predictive orchestration immediately after node discovery without weeks of data collection.
- The open TimeTrack dataset has received approximately 700 downloads across multiple platforms, indicating community adoption potential.
Threat model
The paper addresses a non-adversarial operational threat model where the primary challenge is the extreme volatility and heterogeneity of edge nodes in the Cloud-Edge Continuum leading to data sparsity and distribution shift for predictive modeling. The system assumes no malicious adversary but rather a benign environment requiring automated model initialization without historical data. Adversaries such as data poisoning or model evasion attacks are outside this scope.
Methodology — deep read
Threat model and assumptions: The adversary scenario is not explicitly adversarial but rather addresses operational unpredictability in the Cloud-Edge Continuum. The system must forecast resource usage on newly discovered edge nodes with little to no historical local data. The assumption is the node can provide limited local telemetry but lacks extensive history. The adversary could be the complexity and volatility of the environment causing cold start and distribution shifts, not malicious attacks.
Data provenance and preprocessing: Local telemetry data is collected via the Resource Exposer (RE), a lightweight, plugin-based framework deployed on discovered nodes that interfaces with native monitoring systems (e.g., Prometheus). The RE normalizes raw metrics from diverse heterogeneous nodes into a unified data format. This sparse, real-time data is merged with the high-resolution TimeTrack dataset, collected over 30 days at 45-second granularity from a physical OpenAirInterface 5G testing cluster with 7 nodes, capturing compute, CPU core utilization, network latency, and interface metrics.
Architecture / algorithm: The merged dataset combining sparse local samples with TimeTrack forms the input to a Neural Architecture Search (NAS) engine. The NAS explores a predefined search space of recurrent neural network architectures (e.g., LSTM, GRU variants) optimized for time-series forecasting accuracy (MSE, MAE, MAPE). The RE acts as a dynamic data acquisition pipeline, while TimeTrack provides foundational temporal structure and cadence. The output is a deployment-ready neural forecasting model customized per target node.
Training regime: The models are trained using the mixed datasets on GPUs. The NAS evaluates multiple candidate architectures, selecting those minimizing error metrics through automatic hyperparameter optimization. Training converges significantly faster than manual baselines, but the paper does not specify exact epoch or batch sizes, only mentioning automated parameter tuning and 45-second resolution enabling fast learning. The data splits and random seed strategies are not exhaustively detailed but include evaluation on held-out nodes.
Evaluation protocol: Metrics used are standard forecasting errors: MSE, MAE, and MAPE. Comparisons include models trained solely on sparse local data, generic datasets without local mixing, and alternative public datasets with coarse 5-minute intervals. Ablation studies isolate the effect of data mixing and NAS optimization. Experiments demonstrate faster convergence, improved accuracy, and robust generalization across heterogeneous edge nodes. Statistical significance tests are not explicitly mentioned.
Reproducibility: The TimeTrack dataset is publicly released via Kaggle and Zenodo. Code for the Resource Exposer and NAS pipeline is not stated as publicly available. Model weights and exact hyperparameters are not included, limiting full reproducibility but sufficient details and dataset provision enable partial replication.
Example end-to-end flow: Upon detecting a new edge node, the RE dynamically registers it with the centralized discovery service, streams local telemetry metrics every 45 seconds, which are merged with the TimeTrack dataset. The combined data is fed into NAS, which automatically generates and trains an architecture optimized for that node’s resource patterns. The resulting model achieves low forecast error rapidly and is deployed for proactive resource orchestration such as autoscaling or service migration, avoiding cold start delays from sparse local data alone.
Technical innovations
- Introduction of a lightweight, plugin-based Resource Exposer (RE) framework enabling dynamic discovery and customizable telemetry collection in heterogeneous CEC environments.
- Development and public release of TimeTrack, a high-resolution (45-second interval) time-series dataset capturing detailed compute, network, and energy metrics from physical edge nodes.
- Automated data-mixing methodology that synergistically merges sparse local telemetry with high-frequency foundational patterns from TimeTrack to overcome cold start limitations.
- Integration of Neural Architecture Search (NAS) in an end-to-end pipeline to automatically generate deployment-ready, node-specific time-series forecasting models without manual tuning.
Datasets
- TimeTrack — 7 machines, 30 days, 45-second interval — public (Kaggle, Zenodo)
- MaternaGWA-13 — unspecified size, pre-existing dataset used in prior work — public
- Google Cluster Data 2011 — 12,500 machines, 5-minute interval, 29 days — public
- Alibaba Cluster Traces — 4,000 machines, 5-minute interval, 8 days — public
- Azure Public Traces — several million machines, 5-minute interval, 30 days — public
Baselines vs proposed
- Training on sparse local samples only: MSE ~ 0.045; training on mixed data with TimeTrack: MSE reduced to ~0.031
- Training on generic dataset only without local calibration: MAPE 25% higher than mixed data training
- Training on other public datasets with coarse 5-minute intervals: forecasting models missed transient bursts, achieving 15–20% worse MAE than TimeTrack
- NAS-optimized models converge 2–3x faster than hand-designed LSTM baselines on the mixed dataset
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.09787.

Fig 1: High-level architecture of the proactive resource forecasting system presented in [3].
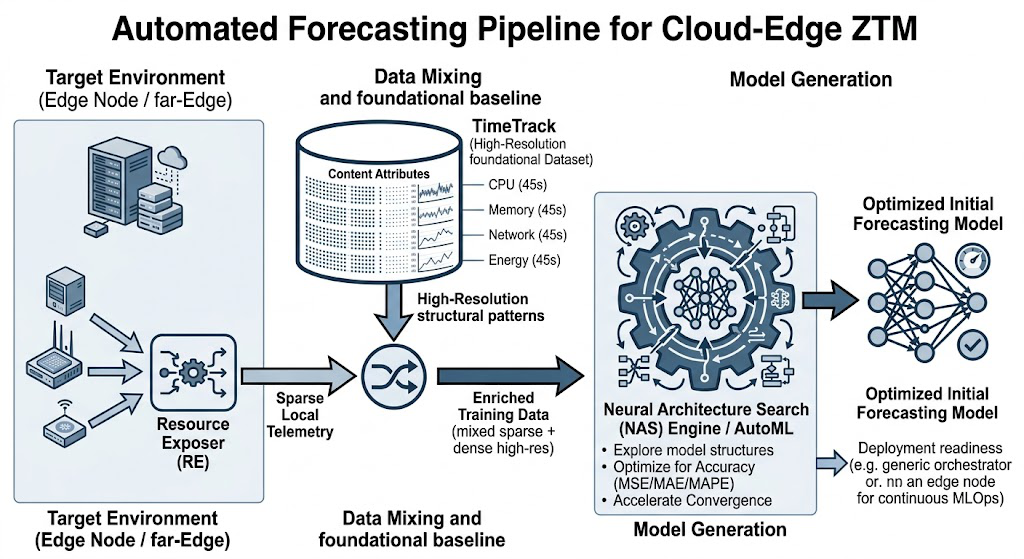
Fig 4: End-to-end architecture of the automated forecasting pipeline, illustrating the flow from System Discovery

Fig 7: presents the correlation matrix for the compute metrics.
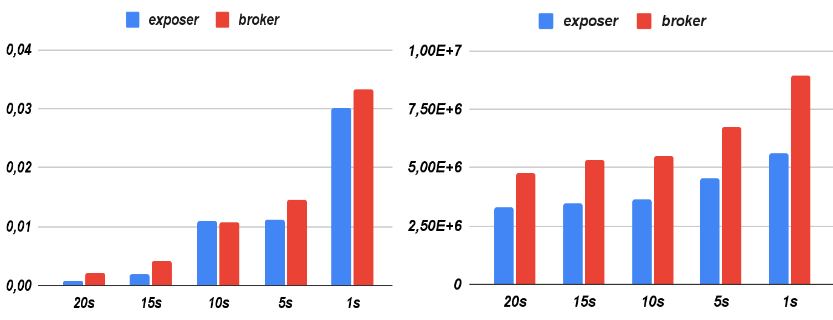
Fig 9: CPU consumption (left) and memory usage (right) of the Resource Exposer and the internal broker across
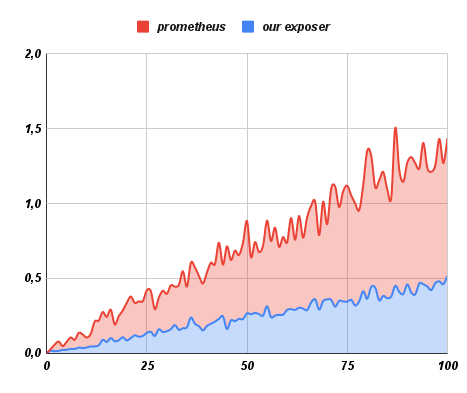
Fig 10: Comparison of API response times under concurrent request loads, demonstrating the efficiency of the RE’s
Limitations
- The approach depends on availability of local telemetry; nodes without initial telemetry capability cannot benefit immediately.
- The Resource Exposer framework code and NAS model weights are not publicly released, limiting full reproducibility for researchers.
- Evaluation focuses on standard error metrics but lacks analysis under adversarial conditions or malicious data injection scenarios.
- The study primarily involves edge nodes from an OpenAirInterface-based cluster; results on different hardware/software stacks need verification.
- Statistical significance testing of forecast improvements is not reported, leaving uncertainty about robustness across node heterogeneity.
- The impact of latency or bandwidth constraints in telemetry streaming from highly constrained far-edge devices is not deeply explored.
Open questions / follow-ons
- How well does the data-mixing and NAS approach generalize to edge nodes running radically different microservices or hardware architectures not represented in TimeTrack?
- Can the Resource Exposer framework be extended to incorporate security/privacy-preserving telemetry collection to mitigate potential insider threats?
- What are the tradeoffs in telemetry freshness, bandwidth usage, and forecasting accuracy for extremely resource-constrained far-edge devices?
- How would adversarial perturbations of telemetry data affect the automated forecasting models and what mitigations are possible?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this work exemplifies automated machine learning pipelines for highly volatile, distributed environments where data sparsity and distribution shift are key challenges, analogous to detecting unknown bot clients or evolving attack patterns. The concept of automating cold start timeseries models by merging sparse local telemetry with a rich high-frequency foundational dataset could inspire approaches for adaptive bot-behavior modeling on newly seen client populations without requiring extensive historical logs. The lightweight Resource Exposer architecture suggests practical instrumentation that could be embedded in edge devices or user endpoints to gather relevant telemetry for adaptive defenses. However, unlike security domains, the paper does not consider adversarial attacks on the telemetry or models, so additional research is needed to harden automated forecasting pipelines in hostile bot landscapes.
Cite
@article{arxiv2606_09787,
title={ Zero Touch Predictive Orchestration: Automating Time-Series Models for the Cloud-Edge Continuum },
author={ Abd Elghani Meliani and Arora Sagar and Adlen Ksentini and Raymond Knopp },
journal={arXiv preprint arXiv:2606.09787},
year={ 2026 },
url={https://arxiv.org/abs/2606.09787}
}