
RunAgent SuperBrowser: A Theory of Autonomous Web Navigation Grounded in Human Browsing Behaviour
Source: arXiv:2606.09399 · Published 2026-06-08 · By Radeen Mostafa, Sawradip Saha
TL;DR
This paper introduces SUPERBROWSER, an autonomous web-navigation agent explicitly designed to mimic human browsing cognition rather than merely accumulating all observations in large prompt contexts as prior LLM web agents do. The authors ground the system on a cognitive theory of bounded working memory and episodic recall, operationalized as a perception–cognition–action triad. Perception uses a vision-first bounding-box pipeline to identify candidate interactive regions on screenshots, cognition separates strategic (Planner), tactical (Orchestrator), and operational (Worker) reasoning roles, and action executes clicks with a human-like multi-tier click cascade. Their structured episodic memory (Ledger) retains only a goal, recent actions, salient facts, dead-ends, and checkpoints, applying systematic eviction of stale context to keep prompt size steady. On the challenging Mind2Web Hard benchmark with 66 long-horizon tasks, SUPERBROWSER achieves an 89.47% success rate, ranking third overall and ahead of all published research/open-source baselines by a large margin. The results support their hypothesis that consistent application of a cognitive contract—representing human browsing constraints and memory limits—yields more robust and efficient autonomous web navigation than prior methods that naively accumulate context.
Key findings
- SUPERBROWSER achieves 89.47% success on the Mind2Web Hard benchmark (66 long-horizon tasks), placing third overall and outperforming every published open research baseline by a large margin.
- The six-phase eviction loop keeps live context roughly constant in token size across long trajectories (~20 steps), whereas naive accumulation causes prompt size to roughly triple and drops prompt-cache hit rates below 15% by iteration 20 (Fig 3).
- Asynchronous vision prefetching reduces per-step vision latency by ~900 ms, about a 30% wall-clock reduction at typical step rates, improving throughput without harming success rates.
- The three-role brain architecture with an Orchestrator (task routing), Planner (every-N-step progress evaluation), and Worker (per-step actions) enables effective separation of strategic, tactical, and operational reasoning.
- The structured Ledger retains only goal, last 3 actions, a fact dictionary, dead-ends, and checkpoints, reflecting human working-memory limits, and systematically evicts stale screenshots and reasoning traces to cap context size.
- The chevron-aware bounding-box snapper accurately resolves ambiguities where small sub-elements (e.g., dropdown arrows) are the intended targets rather than the dominant adjacent label text (prediction P3).
- Procedural clicks via the DOM cache reduce vision calls from ~20 to 5-7 over a 20-step task, reducing token cost and latency without measurable loss in reliability.
- Failure handling as ‘‘dead ends’’ prevents retrying known failing patches, consistent with the cognitive theory of information foraging (prediction P2).
Threat model
N/A — this paper does not focus on security adversaries but on cognitive architecture for autonomous web navigation agents mimicking human browsing behaviour. The adversary model is implicit: the environment is a naturalistic browsing setting without active malicious interference.
Methodology — deep read
The authors begin with a stated threat model of enabling autonomous web navigation tasks with reasonable human-like browsing cognition, not an adversarial threat model. The adversary model is not central here as the paper focuses on cognitive architectural design for robustness and efficiency.
Data comes mainly from the Mind2Web Hard benchmark of 66 long-horizon web tasks simulating realistic user goals involving multiple page visits and interactions across real websites. The benchmark evaluates autonomous agents in a large-scale crawl-and-replay environment.
The architecture features a vision-first candidate generator: screenshots are captured and passed asynchronously to a multimodal vision model (any OpenAI-compatible endpoint) which returns bounding boxes annotated with enriched DOM features (e.g., aria-expanded, active state) and page-type classifications. Bounding boxes are fed to the language models via labeled sets-of-marks, achieving perceptual continuity across steps.
Cognition splits into three LLM-driven roles: (1) Orchestrator classifies the task verb and routes it either to a Search worker (HTTP fetching only) or Browser worker (interactive browsing). (2) Planner runs every N=4 steps or when signaled, evaluating progress and proposing next steps or declaring done. (3) Worker emits concrete per-step actions (up to five before re-planning), examining current page state and vision bounding boxes.
Memory is maintained by a structured Ledger: a single per-task data structure holding the immutable goal, a plan of subgoals, a recent-action deque (length 3), a fact dictionary with source and confidence, a dead-ends list recording failures with causes/url, checkpoints of progress landmarks, and episodic notes. This episodic memory is persisted incrementally and acts as a schematic, compact representation.
To avoid exploding prompt size, a carefully designed six-phase context eviction loop pre-processes each prompt by (a) limiting screenshots to last 2 with older replaced by text captions, (b) collapsing old failures into one-line dead-ends updating the Ledger, (c) stripping stale session state from same-URL ‘‘stuck’’ slices, (d) compressing reasoning traces, and (e) bounding recent actions to 3—all maintaining a near-constant token footprint.
Action execution uses a three-tier cascade: Chrome DevTools Protocol mouse commands with humanized Bezier motion curves to mimic natural human movement, Puppeteer mediated calls, and fallback to scripted clicks. A chevron-aware snapper handles small adjacent UI controls (like dropdown arrows) preferentially over large text bounding boxes.
A DOM cache and gating predicate compute hashes over interactive element lists (DOM hash), text + scroll position, and iframe signatures to detect stable page states allowing procedural clicks without re-invoking vision. Asynchronous vision prefetching pipelines feature calls immediately after mutating actions to reduce vision latency overlapping with LLM reasoning.
The evaluation protocol runs SUPERBROWSER on Mind2Web Hard tasks, measuring success rates. Ablation slices test memory eviction vs naive prompt accumulation (Fig 3), vision prefetch impact, and sub-element preference via the snapper. They compare to baseline published research systems and OpenAI GPT-4V experimental results. Statistical tests are not explicitly described. The codebase and setup are publicly released on GitHub (https://github.com/runagent-dev/runagent-superbrowser), aiding reproducibility, though the Mind2Web dataset is closed.
One concrete example is a 20-step shopping task on an e-commerce domain: naive policies make a vision call per action (20 total), whereas SUPERBROWSER averages 5-7 vision calls by gating and caching, while maintaining success and drastically reducing context tokens and latency.
Technical innovations
- Recasting autonomous web navigation as a cognitive perception–cognition–action triad with bounded working-memory inspired episodic recall shaping memory and prompt context management.
- A three-role LLM brain (Orchestrator, Planner, Worker) separating strategic task routing, tactical progress evaluation, and operational per-step action emission, each with sharply scoped context.
- The structured Ledger episodic memory retaining only a fixed-size recency deque, goal, facts, dead-ends, and checkpoints with a six-phase eviction loop to maintain near-constant live-context size.
- A vision-first asynchronous bounding-box pipeline providing perceptual continuity and subgoal-aware element emphasis, combined with a chevron-aware bounding-box snapper resolving frequent UI ambiguities.
- A three-tier human-like click cascade integrating Chrome DevTools Protocol with Bezier mouse movement, Puppeteer mediation, and scripted fallback to evade bot detection.
- A DOM-hash-based gating predicate enabling procedural clicks on cached known stable page states, reducing expensive vision calls per step by 60–75% without reliability loss.
Datasets
- Mind2Web Hard — 66 long-horizon web navigation tasks — closed benchmark dataset by Deng et al., 2023
Baselines vs proposed
- Published open research browser agents on Mind2Web Hard: success rates below 50%
- SUPERBROWSER: success rate = 89.47%, ranking 3rd overall, ahead of all published baselines by a large margin (Fig 7)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.09399.
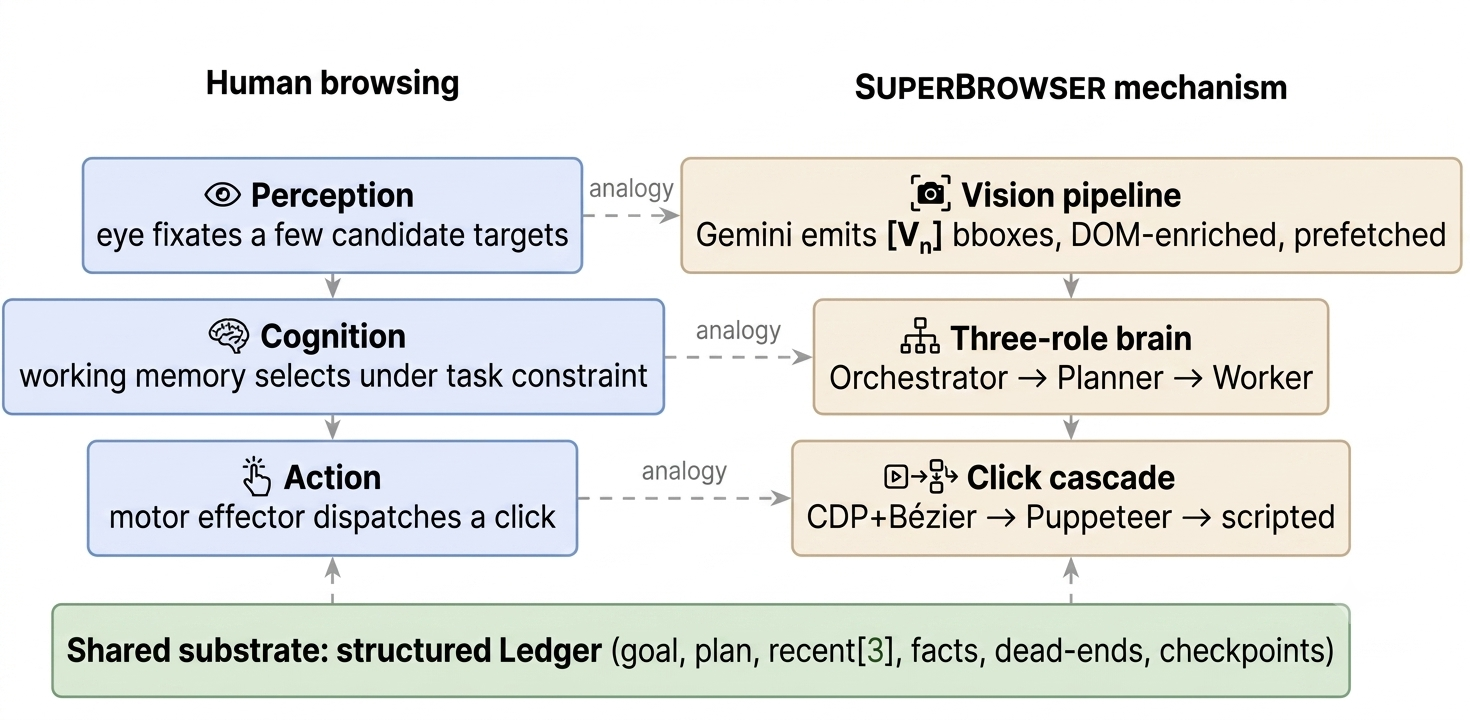
Fig 1: The perception–cognition–action triad as instantiated in SUPERBROWSER. The human
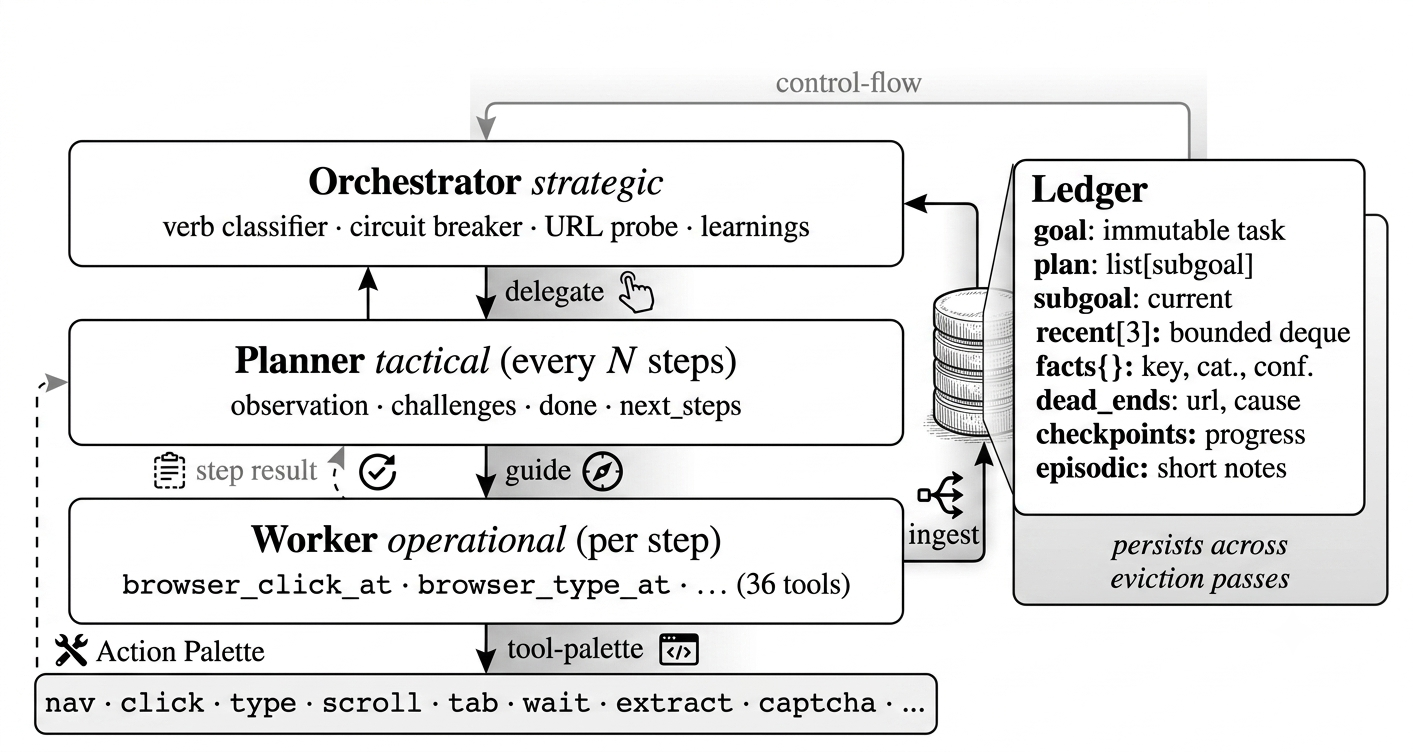
Fig 2: Three-role brain. The Orchestrator classifies and routes; the Planner re-evaluates progress
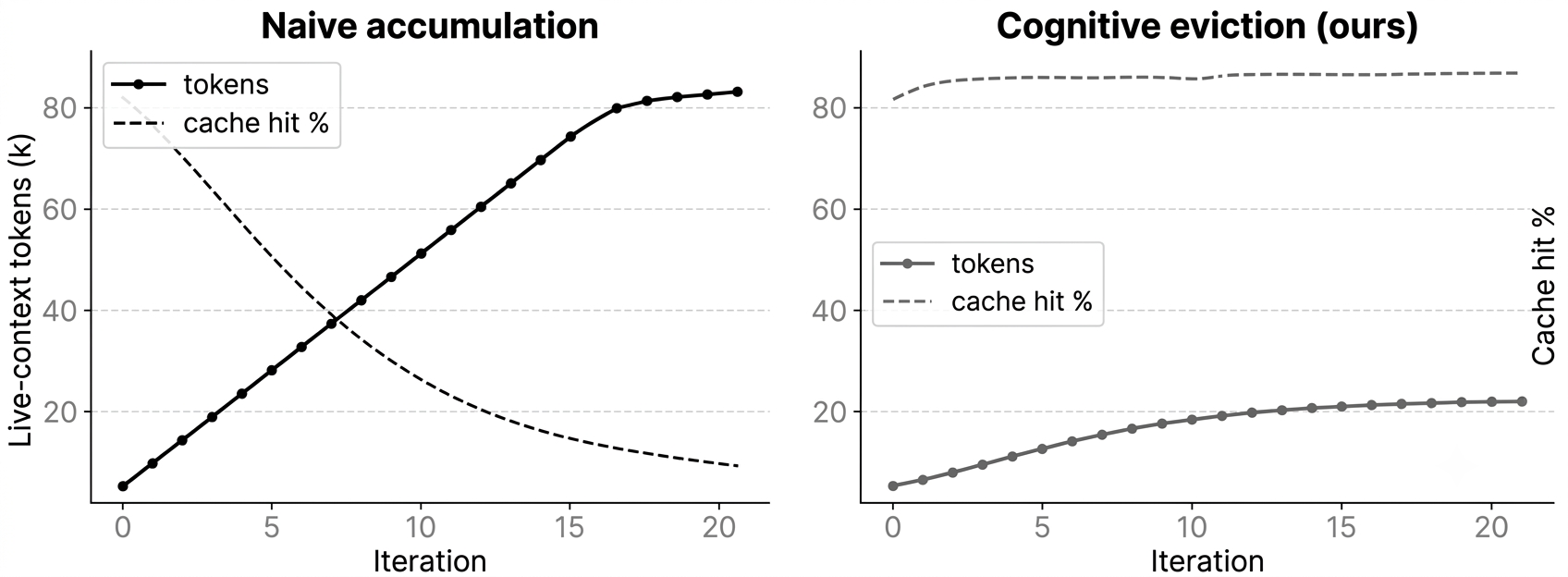
Fig 3: Naive accumulation (left) versus cognitive eviction (right) on a representative twenty-
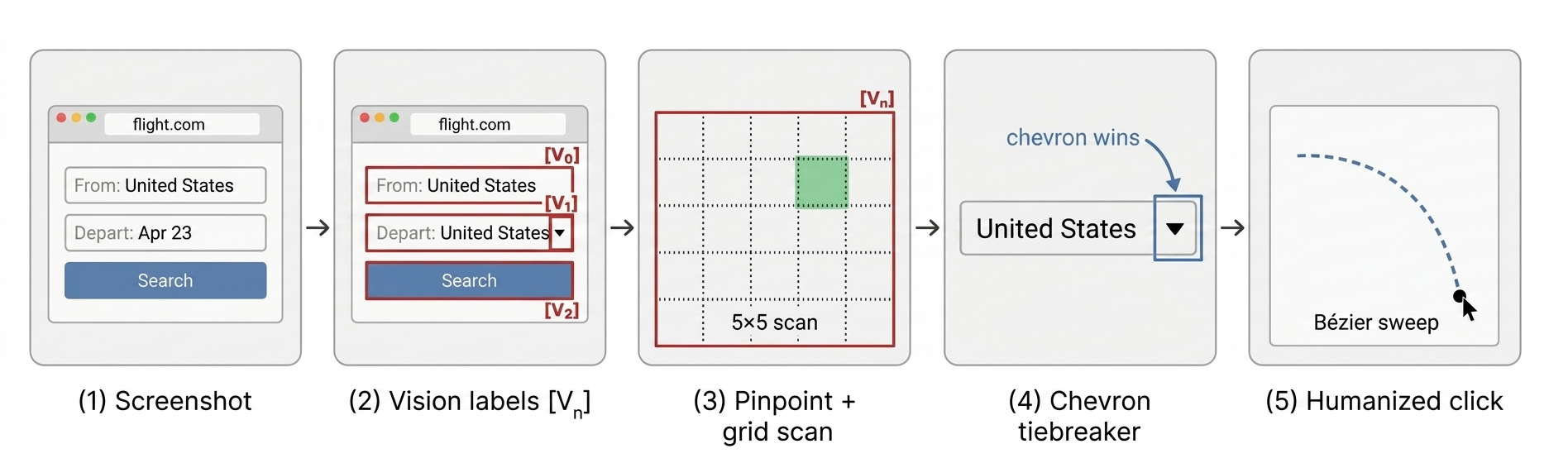
Fig 4: Vision-to-action pipeline. (1) screenshot, (2) vision model emits [Vn] bboxes, (3) snapper
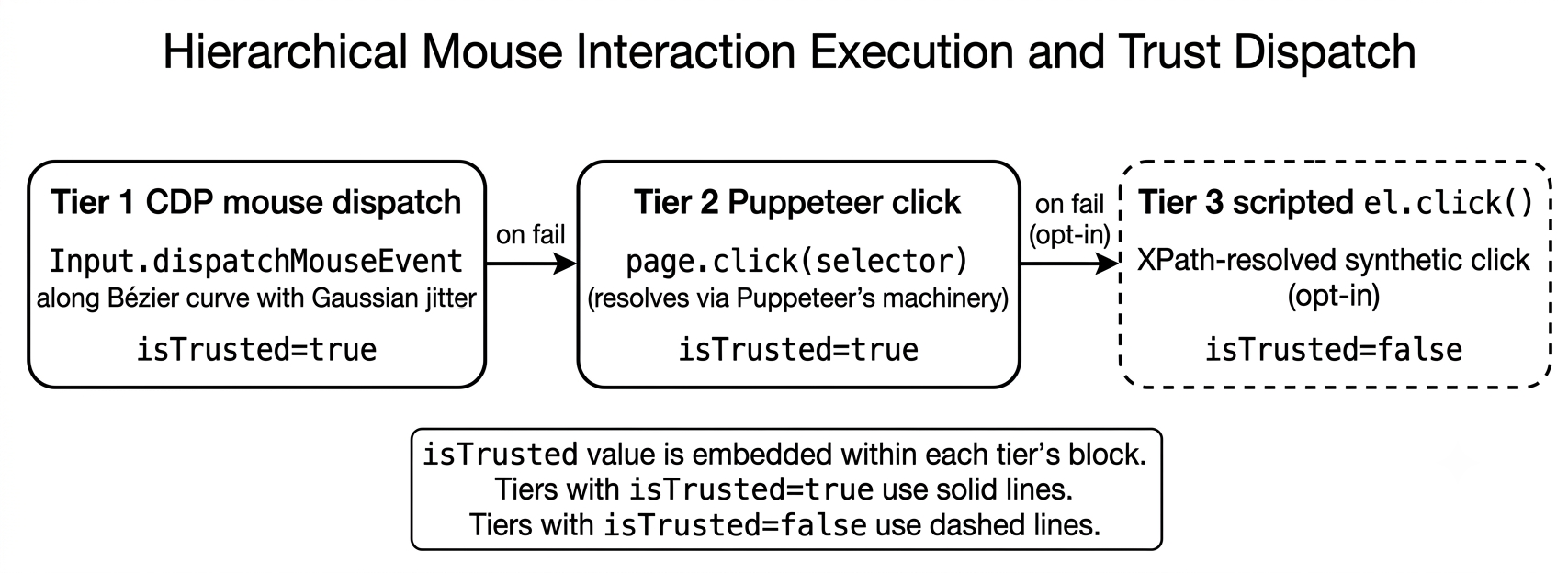
Fig 5: Three-tier click cascade. Tier 1 dispatches via the Chrome DevTools Protocol with a
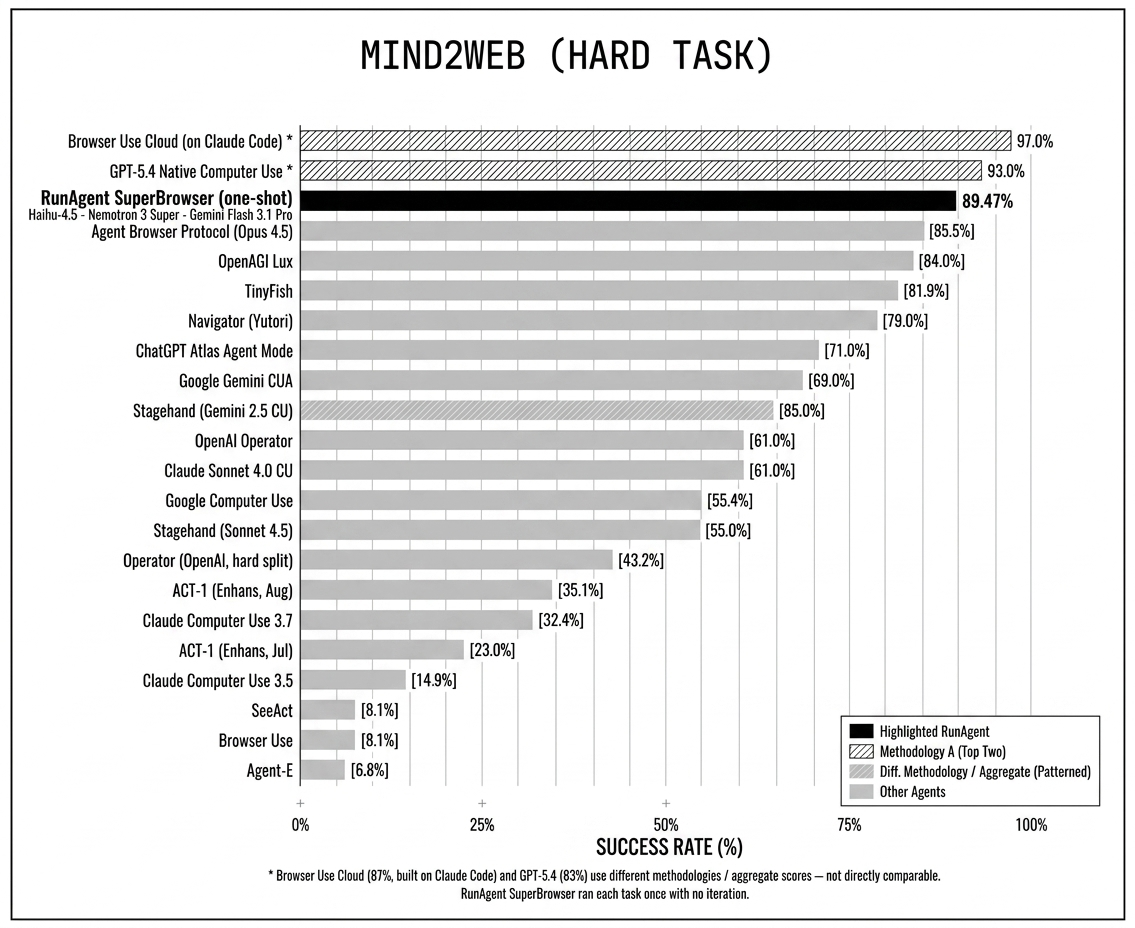
Fig 6: Task success on Mind2Web Hard (66 tasks). SUPERBROWSER is highlighted in the third
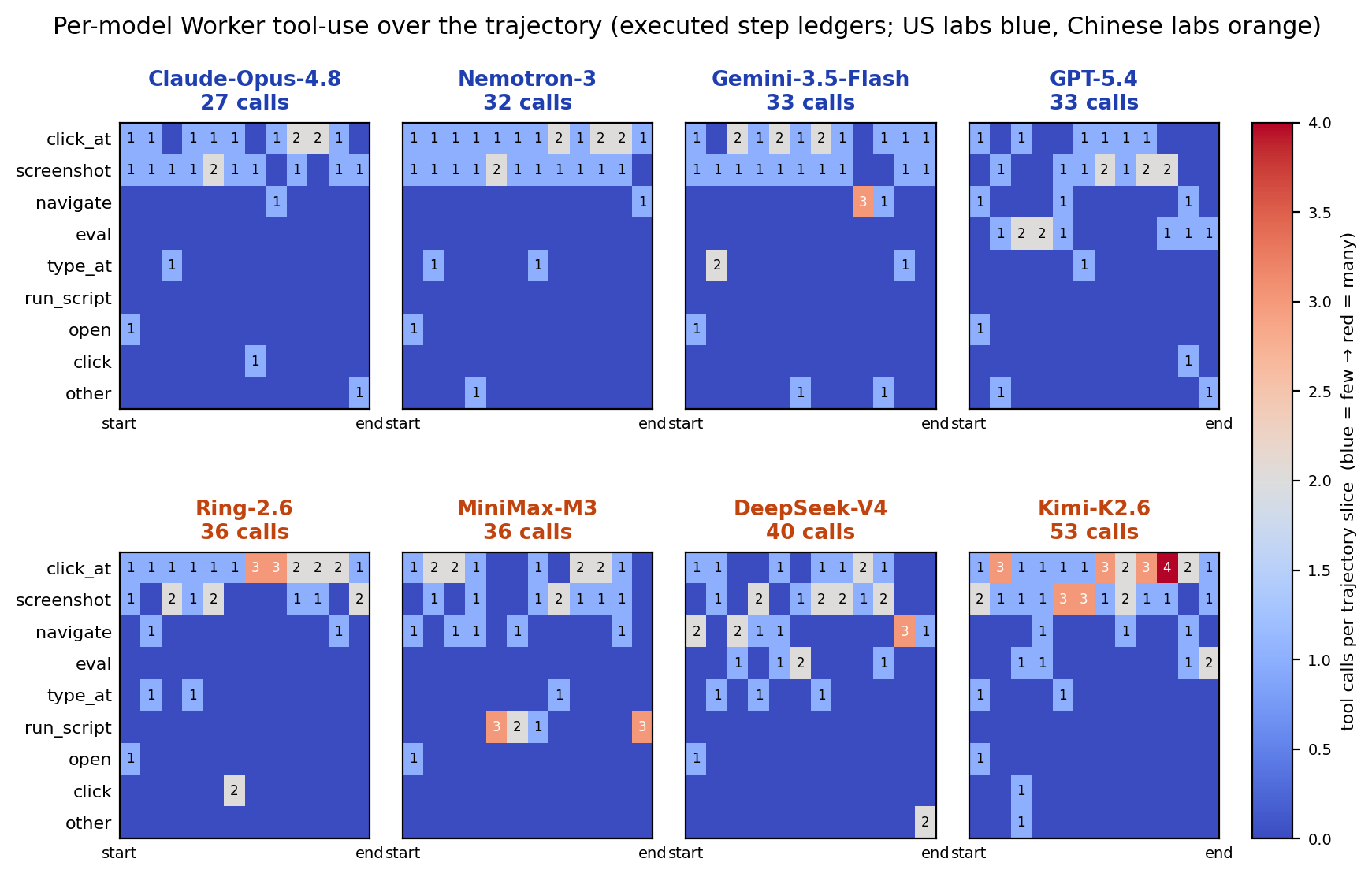
Fig 7: Per-model Worker tool-use over the trajectory on a representative web-navigation task
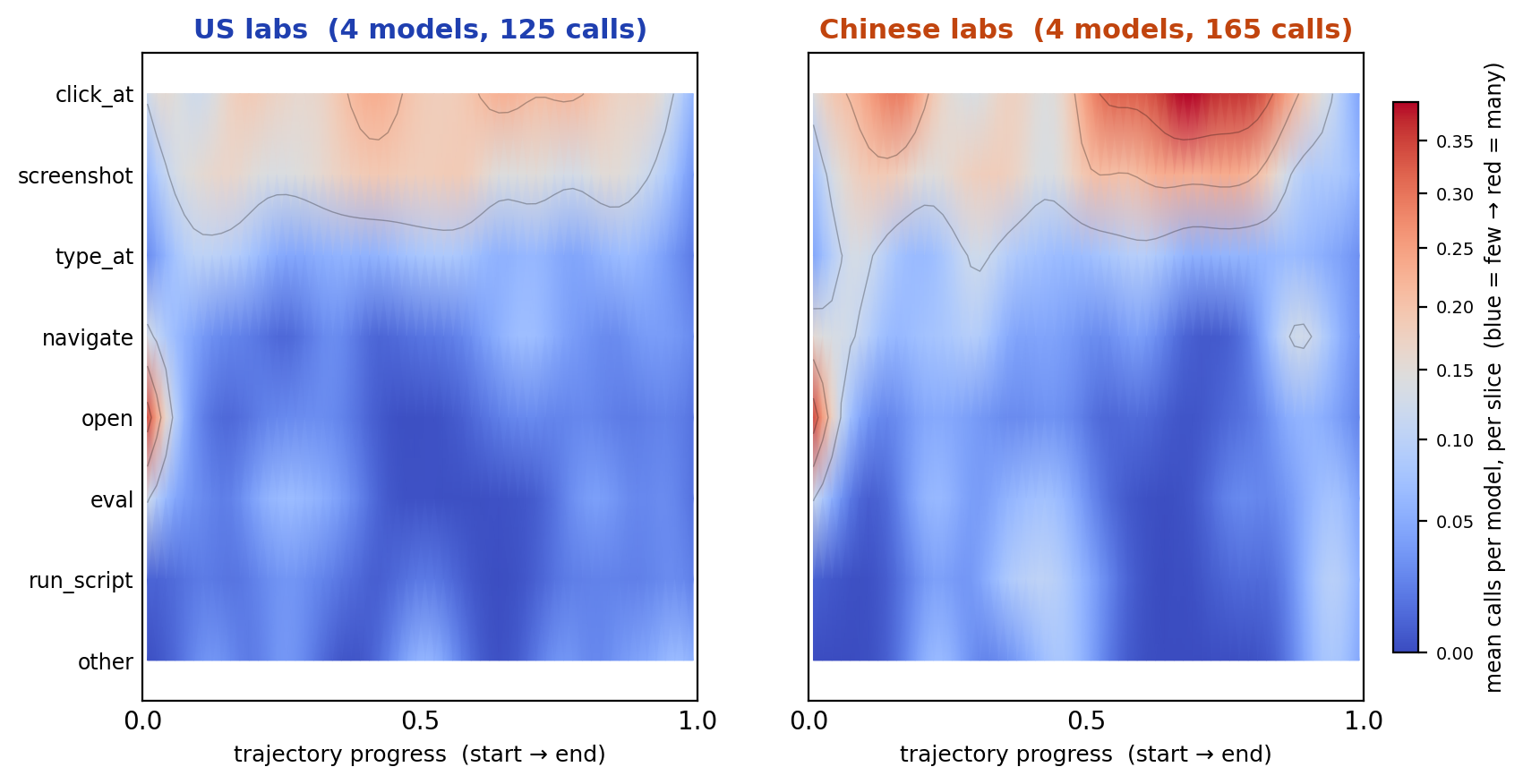
Fig 8: Smoothed density of where Worker tool calls land, pooled by lab on a representative
Limitations
- The paper does not evaluate adversarial bot detection scenarios or robustness to attackers manipulating UI states or vision inputs.
- Mind2Web tasks are realistic but limited to scripted replay environments; no evaluation on fully live diverse web interaction scenarios.
- Certain parameters (like recent action deque length=3) were fixed heuristically; sensitivity analysis is not detailed.
- No ablation on the impact of individual architectural components (e.g., removing the chevron snapper or eviction loop) beyond aggregate token/latency plots.
- Statistical significance testing or error bars on success metrics are not reported.
- The vision model used is described as a small flash-tier endpoint without detailed performance or ablation.
Open questions / follow-ons
- How does SUPERBROWSER perform under adversarial UI manipulations designed to confuse vision or memory eviction procedures?
- Can the cognitive architecture generalize effectively to multi-tab or multi-task browsing environments with richer user goals?
- What is the impact of different vision model architectures or higher resolution inputs on candidate bounding box quality and downstream success?
- To what extent can the procedural/ declarative click gating predicate be learned or adapted online for novel site dynamics?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, SUPERBROWSER demonstrates that autonomous web agents adopting human-like bounded memory and selective attention strategies can operate more efficiently and robustly than accumulating vast raw observation histories. This design philosophy may inform defenses targeting scripted bots that naively accumulate state with large prompts, as such bots may be more brittle and easier to fingerprint. The humanized click trajectories generated by the three-tier click cascade with Bezier motion curves and sub-element-aware snapping also highlight subtle signals that can cause or evade bot detection heuristics based on mechanical mouse patterns or coarse click targeting. Deploying or detecting similar architectures requires understanding the cognitive contract constraints embedded in SUPERBROWSER’s memory management and vision gating, as these result in different temporal patterns of site queries and action distributions compared to vanilla LLM browser agents. However, limitations remain: the evaluation does not address adversarial evasions targeting vision, memory, or procedural caching, so practitioners should consider these gaps when developing bot detection rules. Finally, the structured memory eviction techniques could inspire defense mechanisms that limit the context state available to suspect agents, impairing their long-horizon task performance.
Cite
@article{arxiv2606_09399,
title={ RunAgent SuperBrowser: A Theory of Autonomous Web Navigation Grounded in Human Browsing Behaviour },
author={ Radeen Mostafa and Sawradip Saha },
journal={arXiv preprint arXiv:2606.09399},
year={ 2026 },
url={https://arxiv.org/abs/2606.09399}
}