
BrainSurgery: Reproducible and Reliable Declarative Weight Manipulations for Model Editing and Upcycling
Source: arXiv:2606.09707 · Published 2026-06-08 · By Gianluca Barmina, Annemette Broch Pirchert, Andrea Blasi Núñez, Lukas Galke Poech, Peter Schneider-Kamp
TL;DR
The paper addresses the growing complexity and fragility in modifying large neural network checkpoints, which increasingly hampers research workflows such as model merging, LoRA factorization, pruning, and continual learning. Existing approaches rely on brittle, ad-hoc Python scripts that are hard to audit, reproduce, or scale to very large models. To solve this, the authors introduce BRAINSURGERY, a declarative, framework-agnostic toolkit that expresses weight manipulations as reproducible YAML plans. It supports an expressive set of tensor operations including arithmetic, slicing, reshaping, low-rank factorization (PHLoRA), and dense-to-expert upcycling, verified by built-in assertions. The system also handles memory efficiently for large format checkpoints (safetensors, PyTorch), enabling out-of-core editing and sharded output. Validation against equivalent PyTorch implementations and reversible surgery checks demonstrate correctness and preservation of model inference. The tool includes a Web UI for interactive exploration and an audit trail for reproducibility. Experiments on multiple use cases show BRAINSURGERY significantly improves the rigor, reproducibility, and auditability of checkpoint surgery compared to imperative scripting.
Key findings
- BRAINSURGERY plans are over 4x more concise than equivalent PyTorch scripts (100 lines vs 421 lines) while producing identical tensor-level transformations (Section 4.2).
- The built-in assertion mechanism halts execution on any deviation, validating namespace isolation, in-place vs out-of-place arithmetic equivalence, and structural operations like reshape and concatenate (Section 4.1).
- Checkpoint modifications performed by BRAINSURGERY preserve model predictive behavior: mean last-token logit cosine similarity and perplexity ratios between original and post-surgery models are near perfect (approx. 1.0) with 100% top-1 next-token agreement on 50 test prompts (Section 4.3).
- Memory-mapped arena storage enables editing of models exceeding system RAM by mapping intermediate tensors and copies, not just weights, supporting scalable checkpoint editing beyond what safetensors offers (Section 3.2).
- The tool supports flexible tensor targeting using regex and structured pattern matching, enabling large-scale bulk edits with concise declarative expressions (Fig 3 example).
- PHLoRA factorization can be fully expressed and validated in a single declarative YAML plan that includes loading, factorization, dtype casting, deletion, and assertions, compared to a long imperative baseline (Fig 2).
- Sharded checkpoint loading and saving with customizable shard size enable efficient handling of large models for both input and output without format conversion (Section 3.2).
- The Web UI supports interactive checkpoint inspection, incremental transforms, visual diffing, and execution summaries, aiding exploratory research and auditability (Section 3.4, Appendix A).
Threat model
The adversary in scope is accidental errors, silent bugs, or reproducibility failures when performing large-scale post-hoc edits to neural network weights. The tool assumes a trusted user operator aiming to avoid inconsistent, incomplete, or irreversible transformations. It does not consider malicious actors actively attempting to subvert checkpoint integrity or insert backdoors.
Methodology — deep read
The authors’ threat model assumes the user wants to securely and reproducibly perform complex weight manipulations on a neural network checkpoint file without silent errors or data corruption. The adversary is primarily accidental errors or fragile scripting bugs rather than adversarial attackers.
Data provenance includes various neural network checkpoint files in safetensors or PyTorch .pt/.bin formats; specific public datasets are not the focus but rather the weight tensors inside these checkpoints. Model architectures are treated agnostically.
The core architectural contribution is a declarative DSL, OLY Grammar, that lets users express tensor surgical operations as YAML plans rather than imperative code. These plans specify an input checkpoint path, a sequence of transformations with regex/structural tensor targeting, parameters, and optional output settings. Transformations include arithmetic ops (add, subtract, scale), structural edits (copy, delete, concat), type and shape changes (reshape, permute, cast), initialization, and advanced factorization (PHLoRA).
Multiple memory providers back the execution engine. The arena provider memory maps not only model weights but also intermediate tensors and copies to scale beyond available physical memory. This enables out-of-core editing of very large checkpoints directly on disk.
Training or learning per se is not relevant; instead, the system executes these transformation plans step-by-step deterministically. Execution modes include an interactive CLI with history/autocomplete and a batch mode that applies YAML plans headlessly for reproducibility.
Validation comprised three main approaches: (1) Using BRAINSURGERY’s own assertion system to embed checks inside plans to catch runtime deviations in shape, dtype, and value transformations; (2) a lockstep comparison against a PyTorch implementation of the same edits, showing transform-by-transform equivalence; (3) inverse editing (forward and backward transforms) followed by inference tests on 50 prompts to confirm preserved model behavior quantitatively (logit cosine similarity, perplexity ratios, next-token accuracy) and qualitatively.
One concrete example is the PHLoRA factorization workflow which converts dense expert weight differences into low-rank adapters. The imperative baseline requires manual checkpoint loading, tensor cloning, subtraction, SVD factorization, casting, deletion of old tensors, and saving shards. The BRAINSURGERY plan expresses this as a compact YAML sequence with regex-based targeting and assert checks, automatically validating state and output.
Overall the system abstracts checkpoint format and memory management while supporting composable edits validated at runtime. Its declarative plans are human-readable, auditable, and reproducible, addressing the brittleness of existing Python script-based approaches. The core novelty lies in combining expressiveness, scalability, and safety for tensor-level model editing in a unified toolchain.
Code and example plans are publicly released under an open license. Models used in examples are standard checkpoints but are not the research focus. Datasets per se are not applicable. The core experiments focus on pipeline validation rather than extensive benchmarking on multiple models or adversarial cases.
Technical innovations
- Declarative domain-specific language (OLY Grammar) using YAML for specifying complex checkpoint tensor transformations without imperative code.
- Memory-mapped arena provider that supports out-of-core editing of model weights and intermediate tensors allowing manipulation of checkpoints larger than system RAM.
- Built-in assertion mechanism embedded inside transformation plans for real-time validation of tensor shapes, types, values, and namespace isolation to prevent silent errors.
- Flexible tensor targeting with regex and structured pattern matching enabling large-scale bulk edits and slice-level operations across layers and sub-tensors.
- Integration of advanced factorization workflows such as PHLoRA directly expressed and validated within declarative plans, replacing lengthy imperative implementations.
Baselines vs proposed
- Equivalent PyTorch scripts: 421 lines vs BRAINSURGERY plans: 100 lines, both producing identical transformations (Section 4.2).
- Post-surgery inference metrics on 50 prompts: original mean logit cosine similarity ≈ 1.0, perplexity ratio ≈ 1.0, top-1 token agreement = 100% (Section 4.3).
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.09707.
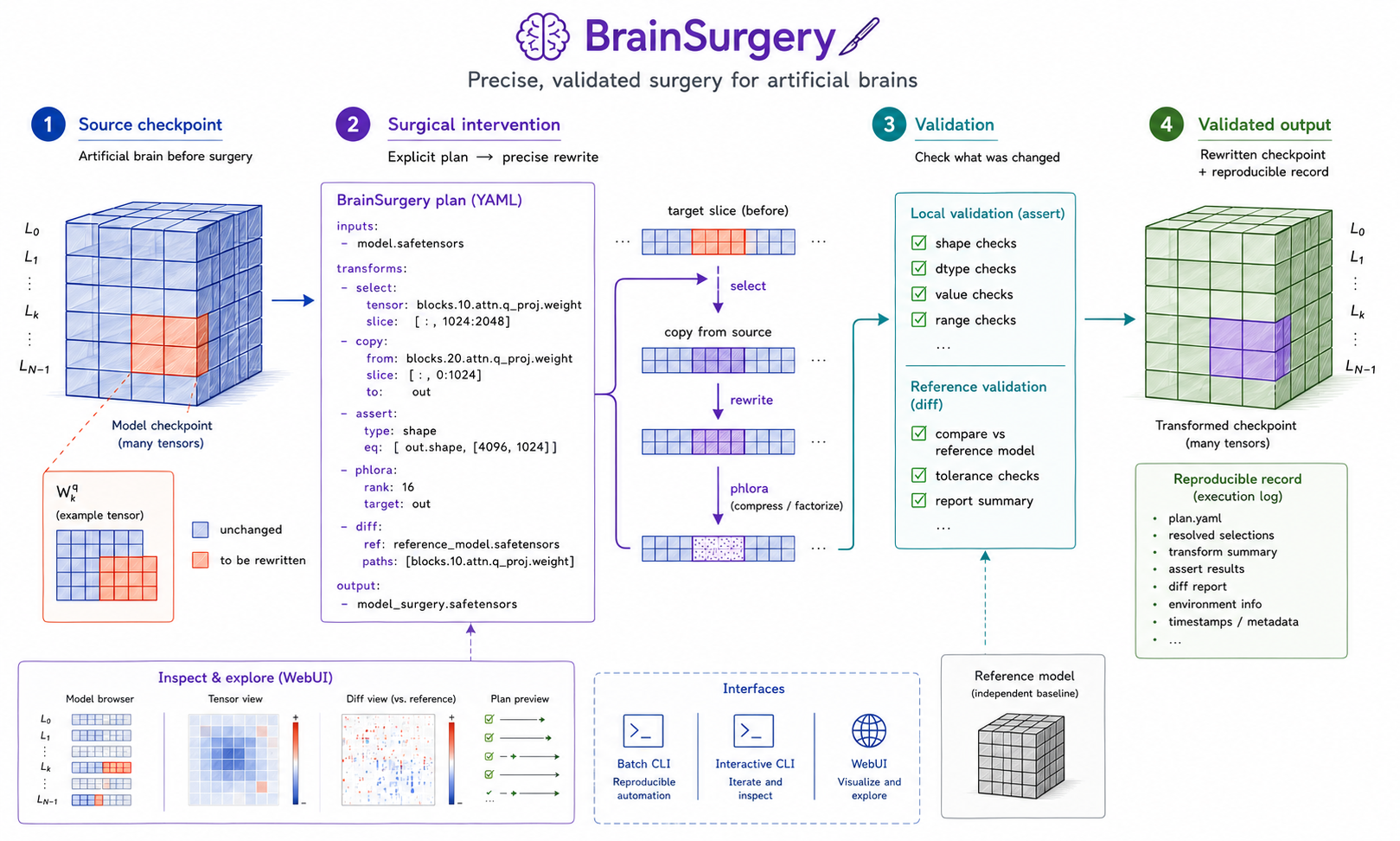
Fig 1: Overview of the BRAINSURGERY workflow. Checkpoint rewrites are expressed as explicit declarative
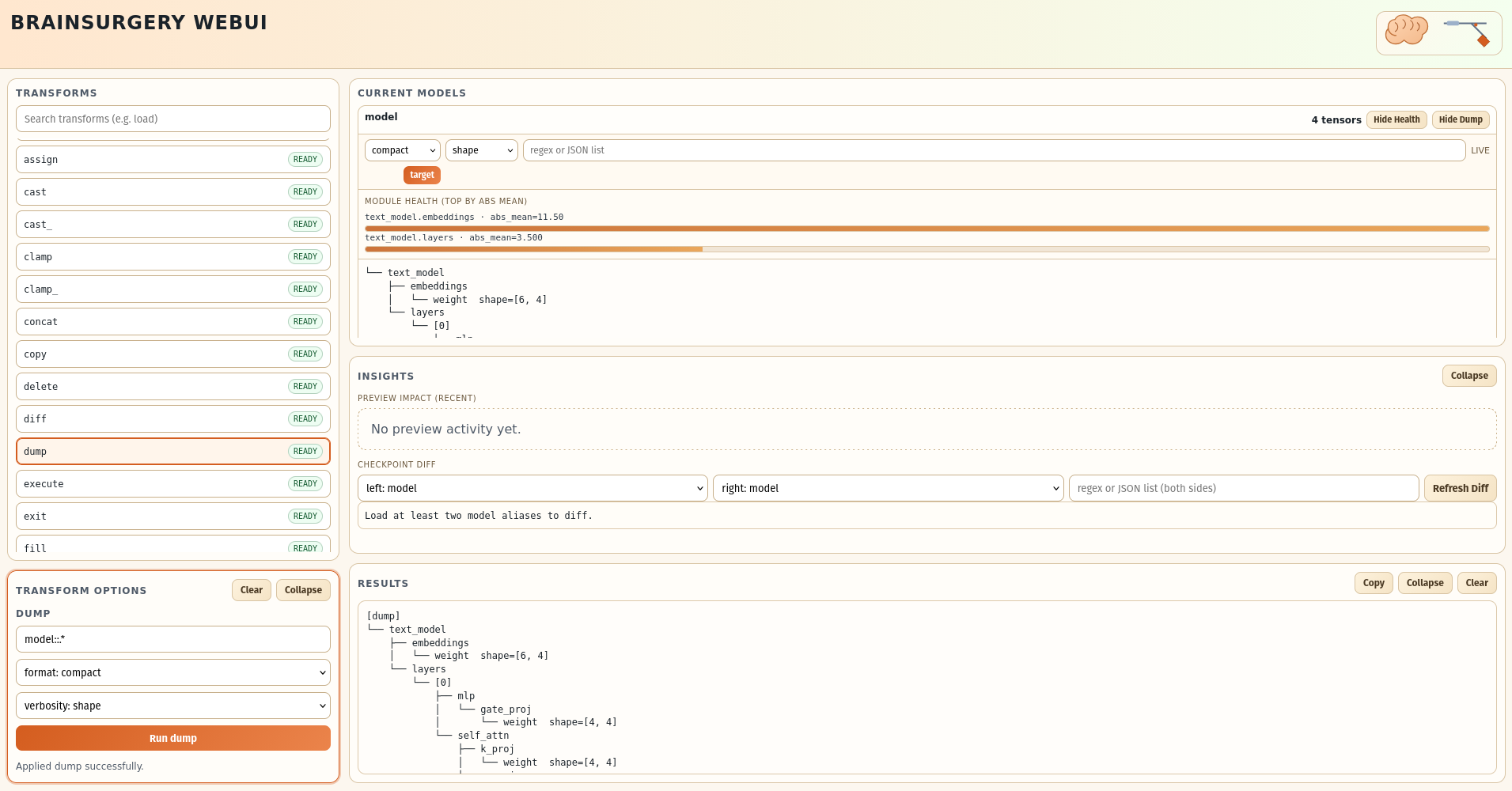
Fig 4: BRAINSURGERY Web UI figure showing model dump.
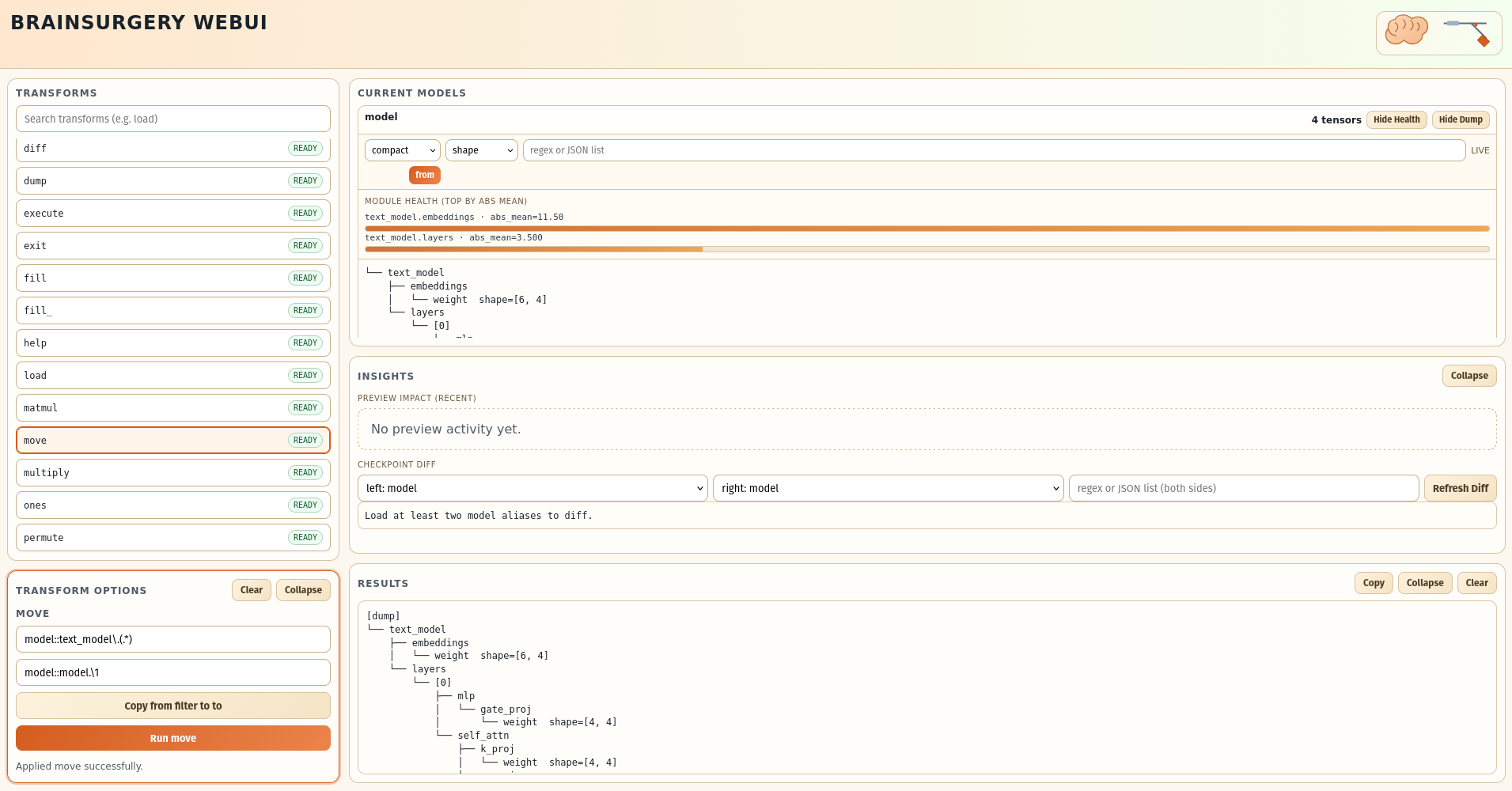
Fig 5: BRAINSURGERY Web UI figure showing model move.
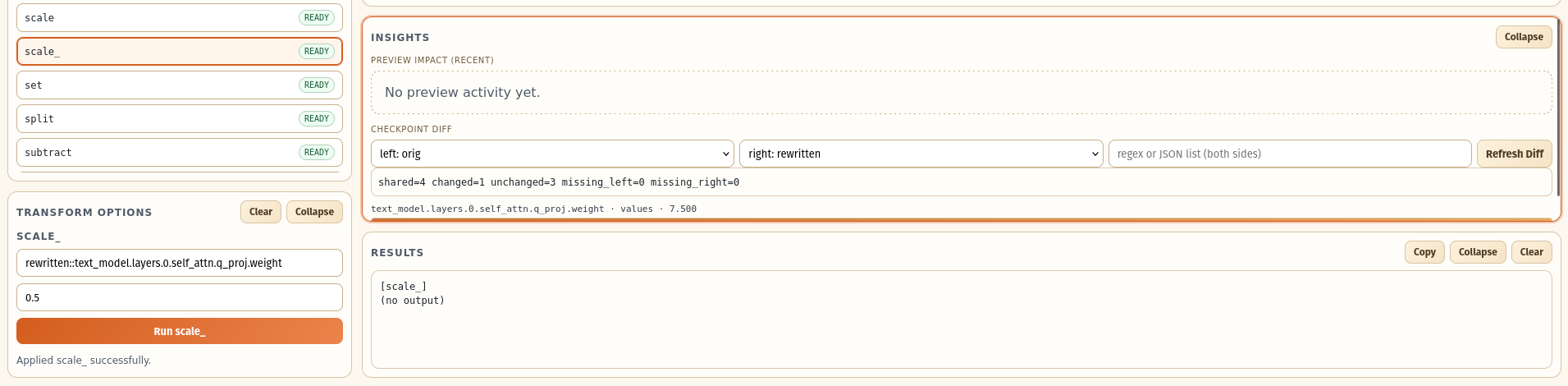
Fig 6: BRAINSURGERY Web UI figure showing zoom-in on diff between the original model and the rewritten
Limitations
- BRAINSURGERY does not remove the need for model-specific expertise in designing appropriate weight transformations.
- Validation ensures equivalence to reference transformations but does not guarantee downstream task performance, training stability, or runtime compatibility across all frameworks.
- Some complex rewrites, especially factorized formats like PHLoRA, may still require manual adjustments of framework-specific metadata or loader support.
- Current evaluation is limited to checkpoint surgery correctness and does not benchmark performance or robustness on extremely large models, distributed or multi-node settings.
- The tool focuses on internal tensor manipulations and provides no direct mechanisms for adversarial attack resistance or security beyond operational correctness checks.
Open questions / follow-ons
- How can BRAINSURGERY’s declarative model editing workflows be extended and integrated with distributed multi-GPU training pipelines and checkpoint formats?
- Can the assertion and validation framework be expanded to include deeper semantic checks, such as partial retraining or functional tests to predict downstream performance?
- How effective are the declarative plans in supporting emerging neural architectures and novel compression or adaptation methods beyond PHLoRA?
- What tooling and abstractions would be needed to facilitate integration with model deployment systems and runtime environments to ensure edited checkpoints remain compatible?
Why it matters for bot defense
For bot defense and CAPTCHA practitioners who rely on large pretrained models for challenge generation, user behavior classification, or anomaly detection, safe and reproducible checkpoint manipulation is critical. BRAINSURGERY provides a means to declaratively specify and audit transformations such as pruning, low-rank adaptation, or layer merging without fragile scripts. This reduces human error in modifying weights for domain adaptation or compression, which could otherwise degrade security model performance unpredictably. The system’s validation framework and runtime assertions help maintain trust in edited models by preventing silent data corruption and allowing reversible checkpoint edits. Furthermore, its out-of-core memory management enables handling large models commonly used in advanced bot detection architectures. Practitioners can apply BRAINSURGERY to upcycle or fine-tune models deployed in security contexts while maintaining rigorous audit trails, which are critical in adversarial detection applications requiring explainability and accountability. However, knowledge of task-specific effects of edits remains essential, as BRAINSURGERY focuses on correctness and reproducibility rather than semantic evaluation of robustness to attack or downstream accuracy.
Cite
@article{arxiv2606_09707,
title={ BrainSurgery: Reproducible and Reliable Declarative Weight Manipulations for Model Editing and Upcycling },
author={ Gianluca Barmina and Annemette Broch Pirchert and Andrea Blasi Núñez and Lukas Galke Poech and Peter Schneider-Kamp },
journal={arXiv preprint arXiv:2606.09707},
year={ 2026 },
url={https://arxiv.org/abs/2606.09707}
}