
AetheRock: An Arm-Worn Robot Teaching System for Force-Guided Vision-Tactile Learning
Source: arXiv:2606.09777 · Published 2026-06-08 · By Hong Li, Yue Xu, Yihan Tang, Yankang Dong, Chenyuan Liu, Chenyang Yu et al.
TL;DR
This paper addresses significant challenges in robotic contact-rich manipulation that rely on force and tactile sensing. Existing tactile and force sensors, especially in handheld or wearable forms, suffer from manufacturing inconsistencies and high costs, limiting data collection and robustness. To tackle this, the authors present AetheRock, an arm-worn data collection system integrating a novel, modular, low-cost visuo-tactile sensor (GelSlim-MiniFab), a resistive pressure sensor for force, and a wearable ergonomic design enabling longer and more robust data collection sessions. They complement this hardware with ForceVT, a force-guided vision-tactile representation learning framework designed to be robust across sensors with varying fidelity caused by manufacturing differences or wear. Real-world experiments on multiple manipulation tasks show AetheRock successfully collects high-quality multimodal data with 100% usability over longer periods, while ForceVT significantly improves policy performance and robustness to tactile sensor variations compared to prior fusion baselines. Overall, this work advances force-aware robot learning by combining innovative hardware design with an algorithmic framework focused on tactile fidelity-agnostic representation learning.
Key findings
- AetheRock enables continuous force, vision, and tactile data collection in an arm-worn form factor with 100% data usability over sessions four times longer than prior UMI devices (Sec 3).
- GelSlim-MiniFab sensor allows low-cost manufacturing using 2D-cut acrylic and replaceable RGB/silicone parts, simplifying repairs and enabling multi-fidelity tactile sensors (Fig 2).
- ForceVT’s force-guided vision-tactile learning reduces performance degradation caused by tactile sensor inconsistencies, maintaining within 5% task progress across fidelities (100%, 75%, 50%) versus >20% drop for baselines (Table 3).
- ForceVT outperforms baselines (VisTacLinear, TacFiLM, TactileConcat) on four contact-rich tasks, improving average task progress from 31.25-35.8% to 52.6-56.0% (Tables 2 and 3).
- Tactile random masking augmentation enhances tactile representation robustness during training for diverse tactile inputs (Sec 4.1).
- Post-training scaling with larger datasets improves policy success, but global generalization remains challenging due to perception limits and dataset size (Fig 6).
- Visuo-tactile policies are more robust and avoid contactless phantom actions compared to vision-only policies, demonstrating the value of tactile sensing for status guidance (Fig 7).
- Modular PCBs, resistive pressure sensors, and armband wearable design enable ergonomic and stable long-duration data collection (Sec 3.2).
Threat model
The adversary is not explicitly adversarial but modeled as natural sensor inconsistencies due to manufacturing imperfections and wear that cause variability in tactile sensor fidelity and signal quality. The system assumes sensors may have degraded or varying conditions but does not consider deliberate attacks or tampering with sensor inputs.
Methodology — deep read
The paper’s threat model focuses on robotic learning from human demonstrations where sensor fidelity variations occur due to manufacturing inconsistencies and wear, not adversarial attacks.
Data is collected using AetheRock, an arm-worn system that records synchronized gripper force, vision (wrist camera), and tactile (GelSlim-MiniFab) signals during human finger-driven manipulations. The system supports parallel and adaptive grippers and uses modular PCBs, resistive pressure sensors, a high-exposure industrial camera, and a local NTP synchronization achieving 10 ms latency. Approximately 200 episodes per task across six contact-rich tasks were collected, with splits including fidelities at 100%, 75%, and 50% to simulate tactile sensor degradation.
GelSlim-MiniFab sensor is designed to reduce optical manufacturing costs by using 2D acrylic and replaceable RGB and silicone components, facilitating low-cost repair. The resistive pressure sensor is calibrated with piecewise linear mappings for force estimation. Tactile images are geometrically calibrated via adaptive thresholding and homography to remove distortions.
ForceVT is a post-training representation learning framework. It uses a tactile random masking augmentation (masking a random fraction of spatial patches in tactile images) to improve tactile robustness. Vision and force features are encoded separately and fused with a lightweight fusion module. Two losses guide tactile representation learning: a soft alignment loss encouraging relational similarity between fused vision-force and tactile representations across multiple tactile fidelities, and a contrastive loss for cross-modality alignment using cosine similarity. During inference, a policy predicts continuous gripper actions from combined tactile and vision features.
Training was done on π0.5 framework adapted for relative pose learning, with models evaluated on a Flexiv Rizon 4 robot and Flexiv Grav adaptive gripper. Evaluation metrics included mean task progress over 20 rollouts per model. Baselines included VisTacLinear (linear fusion), TacFiLM (early fusion with FiLM layers), and TactileConcat (late concatenation). Ablations tested scaling effects with 3, 5, and 7 groups of data and fidelity robustness.
The temporal alignment and tactile image calibration processes ensure spatial and temporal consistency essential for multimodal fusion. The tactile fidelity simulations allowed quantifying robustness to sensor degradation. Overall, the methodology combines hardware innovation for scalable data collection with an algorithm designed to generalize tactile learning across fidelity discrepancies.
Reproducibility is somewhat limited: the GelSlim-MiniFab details reference supplementary material, and the project page is mentioned (rhos.ai/research/AetheRock), but no explicit public code or datasets are noted in the paper.
Technical innovations
- GelSlim-MiniFab: a low-cost, modular visuo-tactile sensor using 2D-cut acrylic and replaceable RGB and silicone parts for easier manufacturing and repair compared to GelSlim 4.0.
- ForceVT: a force-guided representation learning framework with tactile random masking augmentation and soft alignment losses to achieve fidelity-agnostic tactile feature learning.
- Arm-worn multi-sensor data collection system integrating resistive pressure sensors for force, an industrial camera for vision, and wearable ergonomic design enabling 4x longer continuous collection than prior UMI systems.
- Cross-modality soft alignment transferring relational similarity from fused vision-force embeddings to tactile embeddings to maintain robustness across different tactile sensor fidelities.
Datasets
- AetheRock multi-modal manipulation dataset — ~200 episodes per task across 6 tasks — collected with multi-fidelity tactile sensors (100%, 75%, 50%)
- Fidelity subsets for tactile robustness evaluation: 5 groups at 100% fidelity, 1 group each at 75% and 50% fidelity
Baselines vs proposed
- VisTacLinear: task progress on bottle-closing at 100% fidelity = 50.5% vs ForceVT = 58.0%
- TacFiLM [36]: task progress on bottle-closing at 100% fidelity = 39.0% vs ForceVT = 58.0%
- TactileConcat [46]: task progress on bottle-closing at 100% fidelity = 22.5% vs ForceVT = 58.0%
- VisTacLinear average task progress across six tasks = 31.25 - 35.8% vs ForceVT average = 49.0 - 56.0%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.09777.
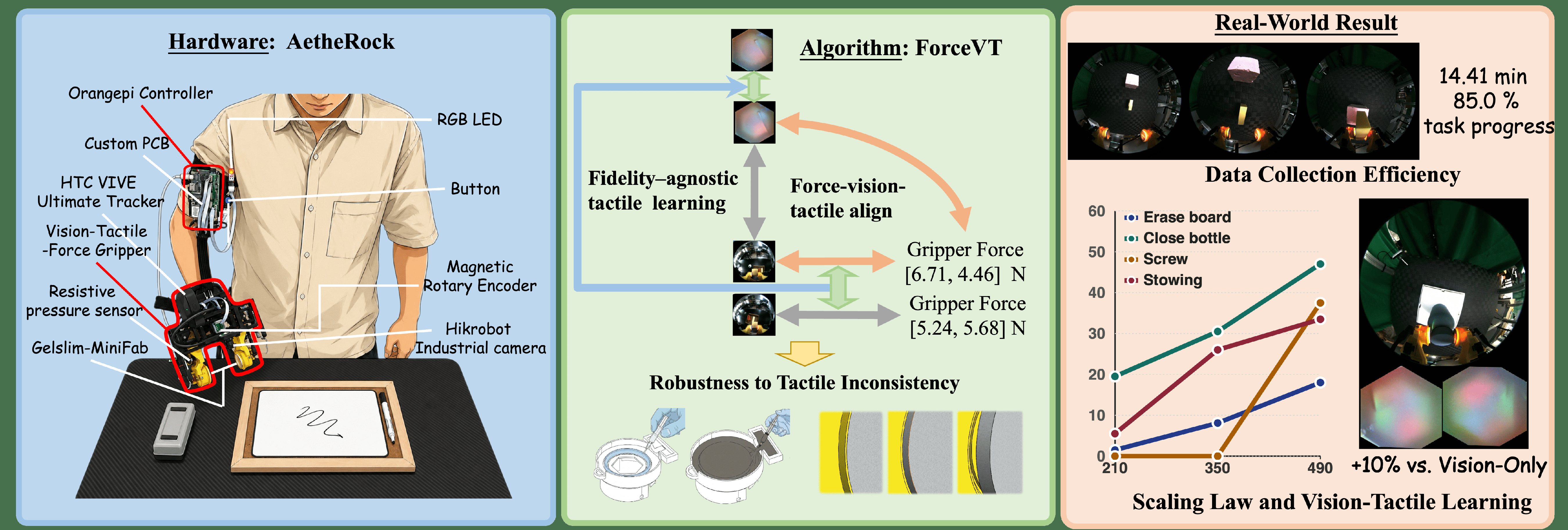
Fig 1: We present a hardware and algorithm co-design robot teaching system. We introduce
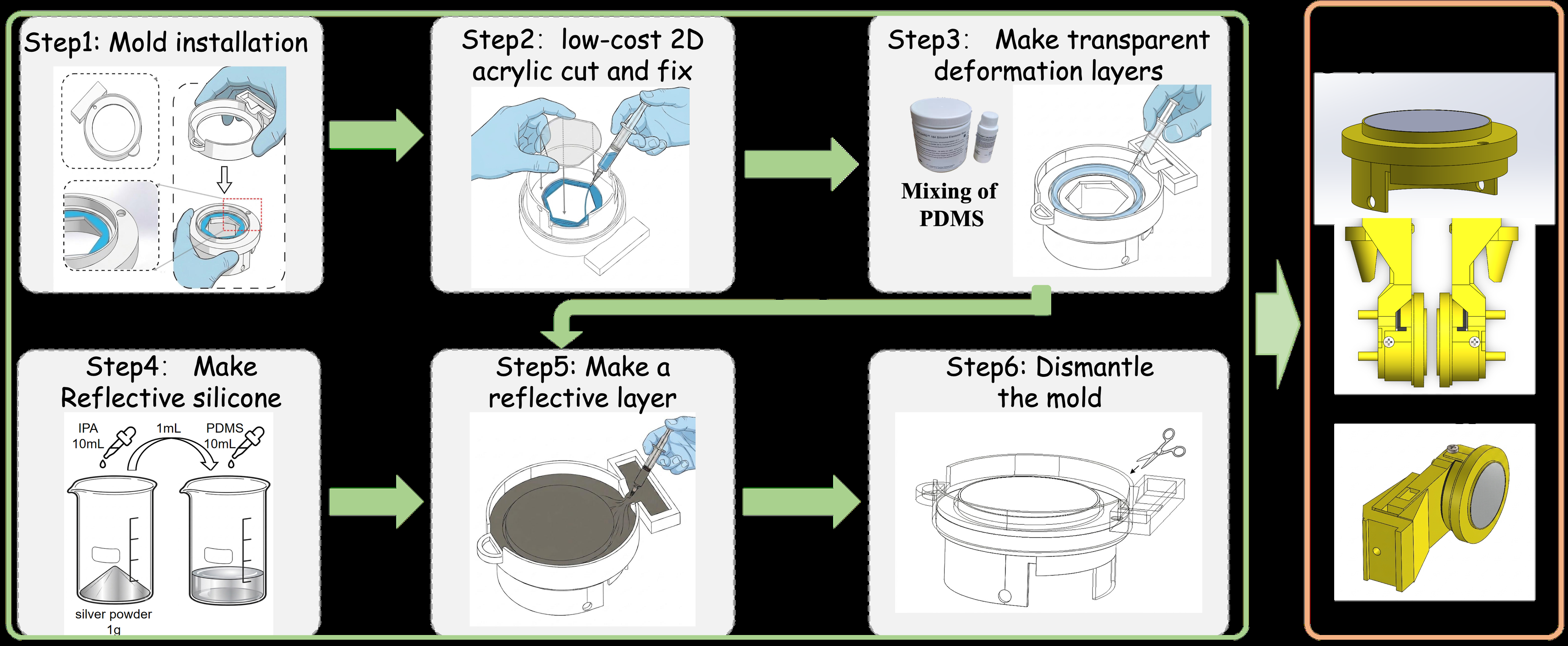
Fig 2: Manufacturing of GelSlim-MiniFab. Inspired by the GelSlim 4.0 [17] optics and PCB
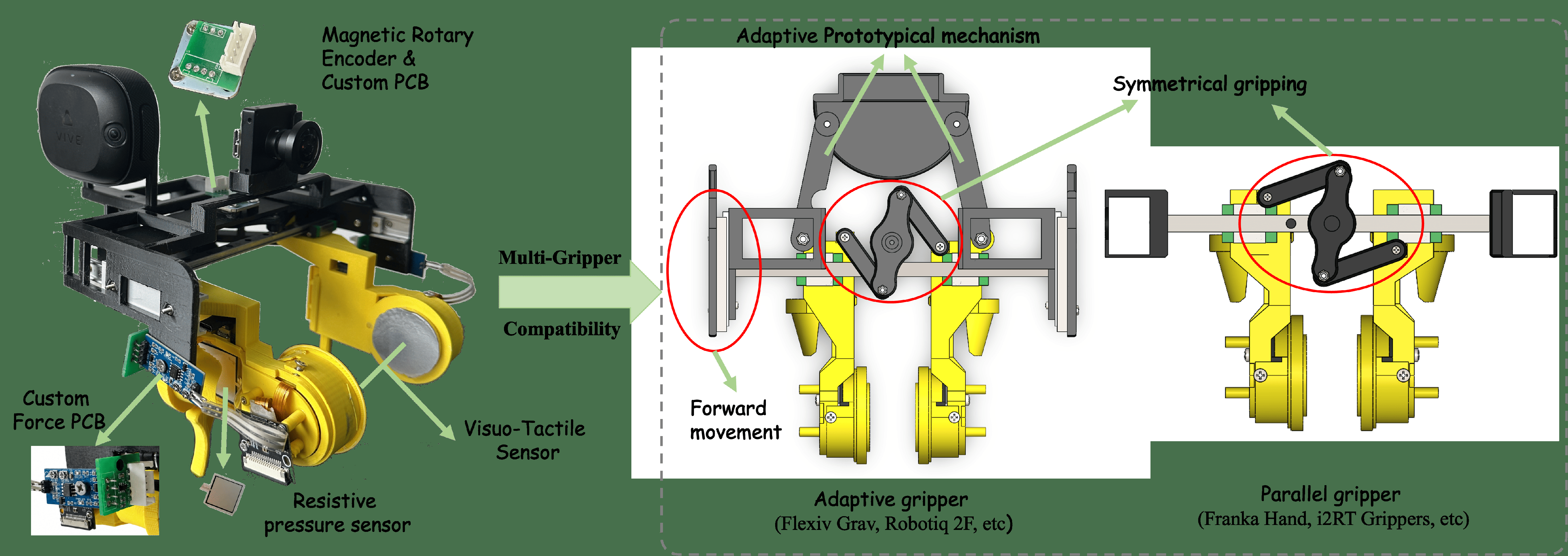
Fig 3: AetheRock hardware system. An arm-worn data collection system for force, vision,
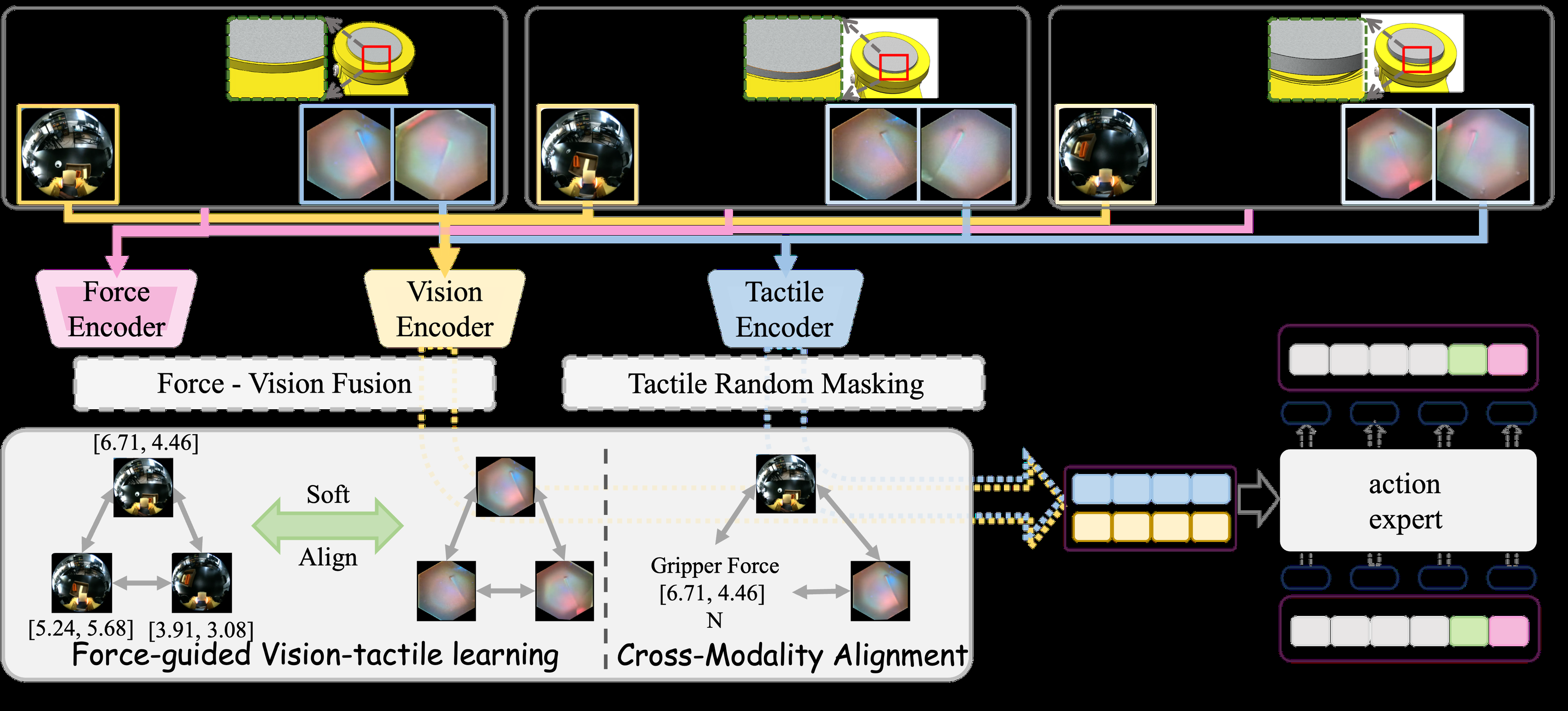
Fig 4: Schematic framework of the proposed ForceVT. Multi-fidelity tactile data are augmented

Fig 5: Real-world rollout of the data efficiency
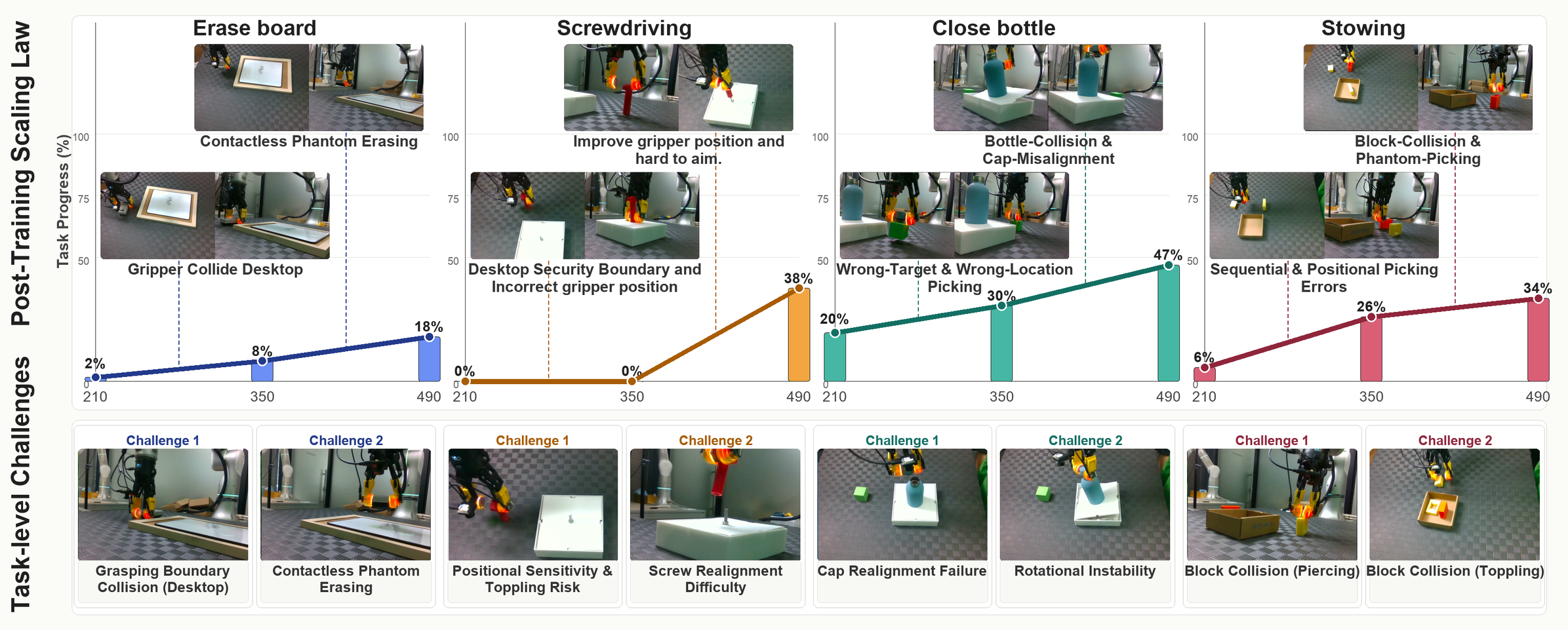
Fig 6: Post-training scaling law across four tasks. The bottom section details the challenges for
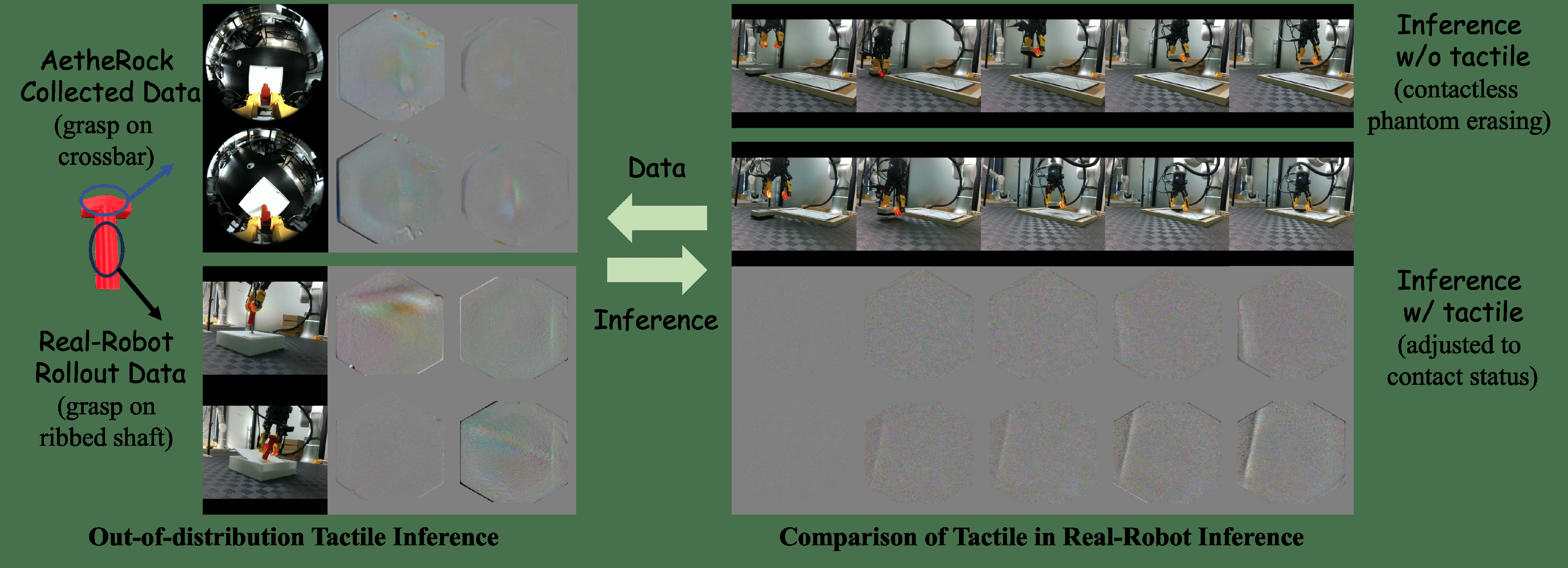
Fig 7: Visualization of tactile challenges in training and inference. The left shows grasp pose

Fig 8: Generalization setting on our task. The left shows single-direction generalization, where
Limitations
- Inconsistencies in tactile contact signals between training and inference, especially due to varied grasp poses causing distribution shifts.
- Current work focuses on post-training; pre-training with larger datasets may further improve tactile signal utilization.
- The resistive pressure sensor offers limited shear force sensing compared to more complex 6-axis force/torque sensors like Coin-FT.
- Global generalization capability is limited; policies trained on local scenes struggle when objects are relocated randomly.
- The work lacks extensive adversarial or out-of-distribution robustness evaluation beyond tactile fidelity simulation.
- No public release of code or datasets currently limits reproducibility and external validation.
Open questions / follow-ons
- How can active data collection or inference feedback be integrated to mitigate tactile signal distribution shifts for improved real-robot generalization?
- What benefits could pre-training vision-tactile representations on large-scale multi-fidelity tactile datasets provide for downstream policy learning?
- How can shear and multi-axis force sensing (e.g., using Coin-FT sensors) be incorporated to further enhance tactile representation robustness?
- What are the limits of the proposed soft alignment framework with more extreme tactile degradation or in highly unstructured environments?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners focused on physical interactions or robotics-assisted challenge generation, AetheRock provides a useful hardware-software combination for robust multimodal tactile and force data collection. The modular, low-cost sensor design and the ForceVT algorithm demonstrate how to overcome fidelity variations that could analogously affect sensor data integrity in physical challenge systems. Practitioners can draw lessons in ensuring robustness to sensor degradation and combining multiple sensory modalities (vision, force, tactile) to maintain consistent sensing even under hardware imperfections. The fidelity-agnostic representation learning may inspire approaches to handle noisy or partially corrupted sensory inputs in real-world bot-defense sensor setups. However, the direct application to CAPTCHA scenarios depends on use cases involving physical manipulation or tactile sensing.
Cite
@article{arxiv2606_09777,
title={ AetheRock: An Arm-Worn Robot Teaching System for Force-Guided Vision-Tactile Learning },
author={ Hong Li and Yue Xu and Yihan Tang and Yankang Dong and Chenyuan Liu and Chenyang Yu and Xuyang Li and Siyuan Huang and Yujun Shen and Nan Xue and Yong-Lu Li },
journal={arXiv preprint arXiv:2606.09777},
year={ 2026 },
url={https://arxiv.org/abs/2606.09777}
}