
Unsupervised Continual Clustering via Forward-Backward Knowledge Distillation
Source: arXiv:2606.07474 · Published 2026-06-05 · By Mohammadreza Sadeghi, Sareh Soleimani, Zihan Wang, Narges Armanfard
TL;DR
This paper addresses the problem of unsupervised continual clustering (UCC), where a neural network must cluster data from a sequence of distinct, unlabeled tasks without storing past data or labels. Catastrophic forgetting (CF) is especially challenging here because the model must discover and preserve cluster structures over time without replay buffers or supervision. The authors propose Forward-Backward Knowledge Distillation for Continual Clustering (FBCC), a novel framework which trains a large continual "teacher" network jointly learning representations and clustering assignments, assisted by multiple lightweight task-specific "student" networks. The teacher is trained on the current task with contrastive and clustering losses, while being regularized via knowledge distillation from frozen past student models to maintain prior knowledge. In turn, a new lightweight student is trained to mimic the teacher's current representations for later distillation. This dual forward-backward distillation reduces catastrophic forgetting without needing stored past data or large replay buffers.
The experiments on four benchmarks (CIFAR-10, CIFAR-100, Tiny-ImageNet, ImageNet100) show significant improvements over state-of-the-art unsupervised continual learning baselines (e.g., CaSSLe, POCON) and even outperform some supervised continual methods (Co2L, OCD-Net) in clustering accuracy and forgetting metrics. Ablations confirm the importance of prototypes and multiple lightweight students. Increasing the number of students improves retention up to a point. The method is memory efficient and stable. Overall, FBCC pioneers unsupervised continual clustering by integrating representation and clustering learning with an innovative knowledge distillation approach to mitigate forgetting without replay, enabling incremental clustering on sequential unlabeled tasks.
Key findings
- FBCC achieves average clustering accuracy (ACC) of 75.28% on CIFAR-10, 38.73% on CIFAR-100, 18.36% on Tiny-ImageNet, and 43.28% on ImageNet100, outperforming state-of-the-art unsupervised methods CaSSLe (max ACC 41.53% on CIFAR-10) and POCON (57.20% CIFAR-10) by +14-18% across datasets (Table 1).
- FBCC reduces average catastrophic forgetting (F) to as low as 2.29% on CIFAR-10 and 3.62% on CIFAR-100, significantly lower than CaSSLe (5.29% and 3.92%, respectively) and POCON (3.59% and 4.28%) (Table 1).
- Removing prototypes from forward distillation decreases ACC by up to ~7.7% and increases forgetting by ~1.9% across datasets, highlighting prototypes' role in preserving cluster separation (Table 2).
- Omitting knowledge distillation from students to teacher (Ldis) causes ACC drop of about 5.9% and forgetting increase of 7.1%, confirming distillation's critical role in knowledge retention (Table 2).
- Retaining multiple lightweight student models (M=⌈N/2⌉) balances memory and performance; increasing M beyond this yields marginal ACC improvements (<2%) but adds overhead, while smaller M reduces ACC and increases forgetting noticeably (Fig 2).
- Using deeper teacher architectures improves clustering performance (ResNet-50 reaches 41.06% ACC vs 38.73% for ResNet-18 on CIFAR-100), but ResNet-18 is retained for fair comparison (Table 3).
- FBCC uses ~15.1M to 17.5M parameters total versus 29M for CaSSLe, showing better memory efficiency by storing small student networks rather than large teachers for past tasks.
- Task-specific cluster projectors and prototypes allow cluster assignments to be preserved and evaluated post-training on all sequential tasks without retraining or replay.
Threat model
n/a (The paper does not consider an adversarial threat model; focus is on mitigating catastrophic forgetting in unsupervised sequential learning without access to previous task data or labels, rather than defending against attackers.)
Methodology — deep read
- Threat Model & Assumptions:
- Adversary model is implicit, focusing on the challenge of continual learning without labeled data or ability to replay past samples. There is no attacker model or threat beyond forgetting. The "attack" is catastrophic forgetting from sequential unsupervised tasks.
- Assumes sequential arrival of data tasks D1...DN, each from distinct classes (mutually exclusive label sets Yi).
- No access to past task data or labels during training of new tasks.
- Number of clusters per task λt known for evaluation only, cluster identities and assignments are discovered by the model.
- Data:
- Four standard datasets: CIFAR-10 (10 classes, 5 tasks), CIFAR-100 (100 classes, 10 tasks), Tiny-ImageNet (200 classes, 10 tasks), ImageNet100 (100 classes, 10 tasks).
- Each task contains disjoint classes; class proportions vary per task producing non-stationary distribution.
- Train and test sets concatenated as standard practice in clustering benchmarks.
- Architecture & Algorithm:
Teacher network: ResNet-18 encoder (~11.5M params) producing latent embeddings hT.
Each task t has a clustering projector Ct(·), a 2-layer network mapping teacher's embeddings hT to cluster probability vectors (λt clusters).
Lightweight student networks: SqueezeNet 1.1 with added FC layer (~1.2M params) trained per task t as a compact model that reproduces teacher representations.
Instance-level projectors Ir(·) and predictors gr(·) are 2-layer FC networks mapping student and teacher embeddings to 128-d feature spaces used in contrastive and distillation losses.
Overall FBCC training loop alternates two phases:
- Forward Knowledge Distillation:
- Teacher trained on current task data augmented with stochastic transformations.
- Losses: (i) contrastive loss Lcon that pulls augmented views close, pushes other samples + stored prototypes apart; (ii) knowledge distillation loss Ldis aligning teacher's outputs to frozen multiple past student networks specialized for previous tasks; (iii) cluster-level contrastive loss Lclu on cluster assignment probabilities to enforce cluster separation.
- Prototypes Pt from all previous tasks stored as representatives appended to negative samples in contrastive loss to maintain cluster distinctiveness.
- Backward Knowledge Distillation:
- A fresh lightweight student network for task t is trained to mimic the current teacher via student loss Lstu that reproduces teacher features and their batch structural relations.
- The student is frozen after training and stored to assist knowledge retention in future tasks.
- Forward Knowledge Distillation:
Only a fixed number M ≤ N of recent student networks maintained for scalability; older students discarded.
At inference, cluster assignments obtained using task-specific cluster projectors learned and stored during training.
- Training Regime:
- Batch size 256, training epochs unspecified but standard for continual benchmarks.
- Data augmentations include random crop, horizontal flip, color jitter, grayscale.
- Optimizer and learning rates unspecified in summary; likely SGD or Adam.
- Multiple random seeds for 5 experiment runs to estimate performance with confidence intervals.
- Evaluation Protocol:
- Metrics: average clustering accuracy (ACC) across all sequential tasks after final task training; average forgetting (F) measuring performance drop on past tasks.
- Baselines: multiple UCL methods (CaSSLe, LUMP, STAM, etc.) and supervised continual learners (Co2L, OCD-Net).
- Spectral clustering applied on learned representations for cluster assignment in baseline methods.
- Ablations conducted removing prototypes, removing distillation loss, and replacing multiple students with single previous teacher as in CaSSLe.
- Varied M to study tradeoff between memory and performance.
- Teacher architectures ResNet-18, ResNet-34, ResNet-50 compared.
- Reproducibility:
- Full detailed formulations, pseudo-code, and implementation details deferred to appendix.
- Code and weights availability not stated, no mention if released or closed dataset.
- Datasets standard and publicly available.
Concrete Example End-to-End: Consider task t with dataset Dt comprising samples from new classes.
- Teacher takes augmented batch samples, maps via encoder + projector to embedding space.
- Computes contrastive loss including previous task prototypes to maintain separation.
- Teacher is regularized by distillation loss using multiple frozen student models from tasks 1 to t-1, each predicting representations for their task's data.
- Teacher optimized with combined loss.
- Backward, lightweight student model Lt trained to mimic teacher's output on current task.
- After training, student Lt frozen and stored.
- Prototype cluster centers for task t computed and added to prototype memory.
- At test time, samples from all tasks can be clustered using stored task-specific cluster projections.
Technical innovations
- Introduction of Forward-Backward Knowledge Distillation (FBCC), a dual-phase distillation approach where a continual teacher network learns new clusters while being guided by multiple lightweight student networks trained on past tasks, enabling knowledge retention without storing past data or large models.
- Joint integration of representation learning and clustering objectives in an unsupervised continual learning setting, producing cluster assignments that evolve and are preserved sequentially across tasks without labels or replay.
- Use of multiple specialized lightweight student networks to store knowledge of individual past tasks, which collectively regularize the teacher network to reduce catastrophic forgetting with much lower memory than replay or storing full past models.
- Incorporation of a prototype set representing previously discovered clusters as additional negatives in contrastive loss during teacher training, improving task separation and retention.
Datasets
- CIFAR-10 — 60,000 images — public
- CIFAR-100 — 60,000 images — public
- Tiny-ImageNet — 100,000 images — public
- ImageNet100 — subset of ImageNet with 100 classes — public
Baselines vs proposed
- CaSSLe: ACC = 40.56% (CIFAR-10), F = 3.28% vs FBCC: ACC = 75.28%, F = 2.29%
- POCON: ACC = 57.20%, F = 3.59% vs FBCC: ACC = 75.28%, F = 2.29% (CIFAR-10)
- CCL: ACC = 36.56%, F = 6.21% vs FBCC: ACC = 75.28%, F = 2.29% (CIFAR-10)
- Co2L (supervised): ACC = 28.35%, F = 14.05% vs FBCC: ACC = 75.28%, F = 2.29% (CIFAR-10)
- OCD-Net (supervised): ACC = 40.41%, F = 7.03% vs FBCC: ACC = 75.28%, F = 2.29% (CIFAR-10)
- FBCC + CaSSLe (single student) ablation: ACC = 70.69%, F = 4.63% vs FBCC (multiple students): ACC = 75.28%, F = 2.29% (CIFAR-10)
- Teacher architecture: ResNet-50: ACC = 41.06%, F = 3.07% vs ResNet-18: ACC = 38.73%, F = 3.62% (CIFAR-100)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.07474.
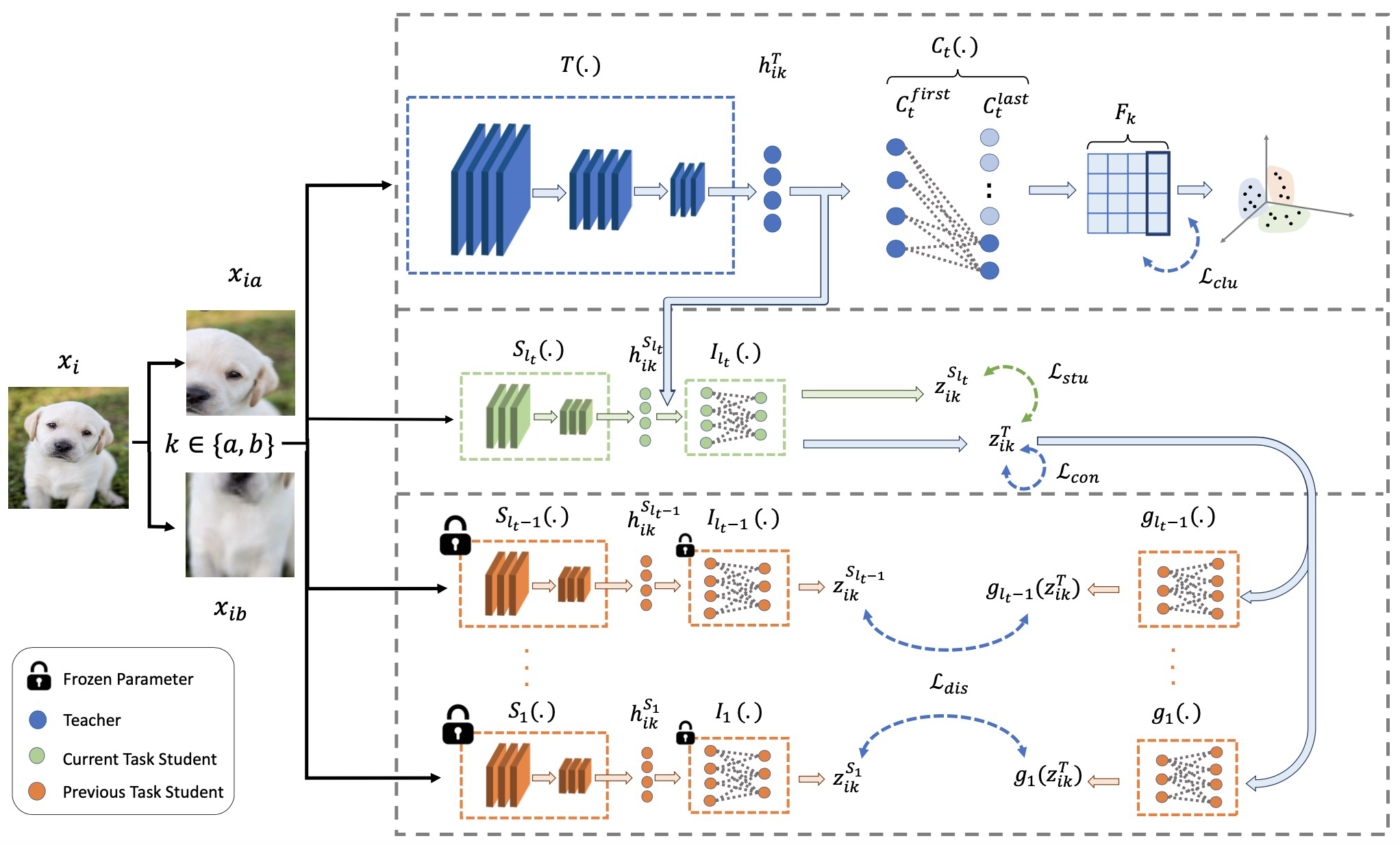
Fig 1: Overview of the FBCC Framework for Task t: The teacher network, shown in
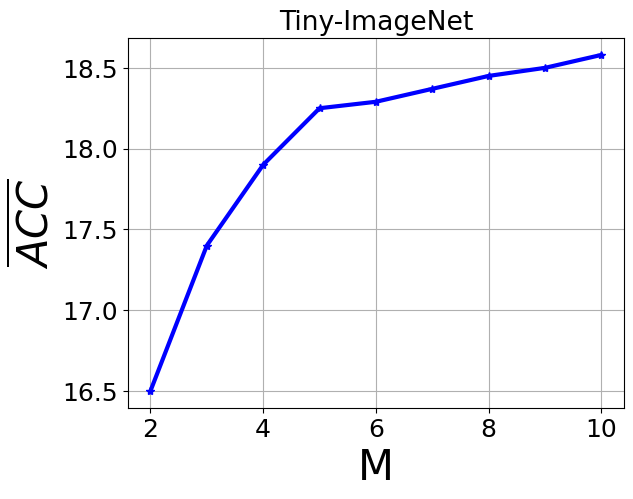
Fig 2: Average ACC and Average Forgetting of different values of M
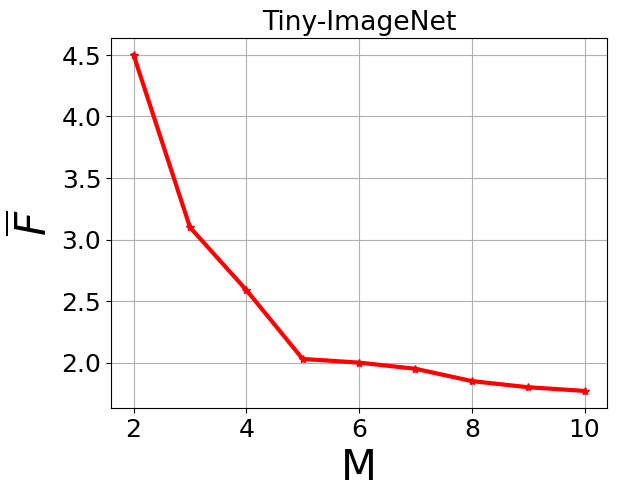
Fig 3 (page 12).
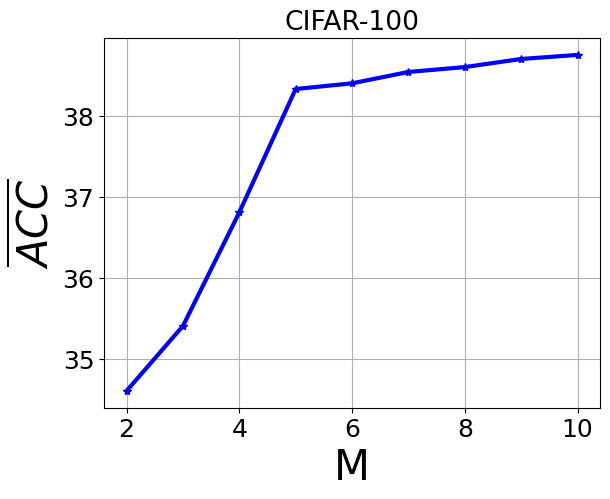
Fig 4 (page 12).
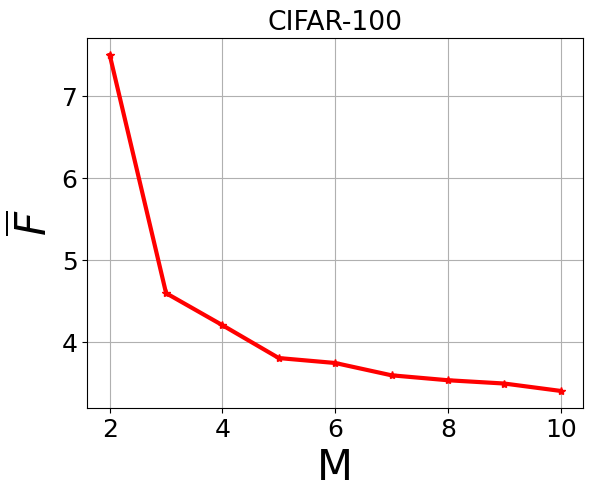
Fig 5 (page 12).
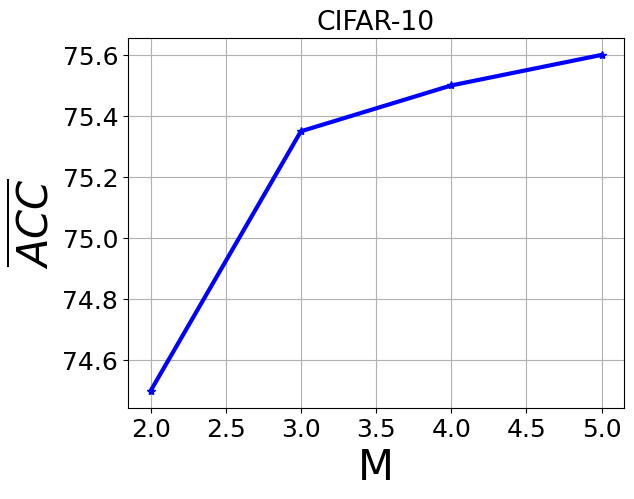
Fig 6 (page 12).
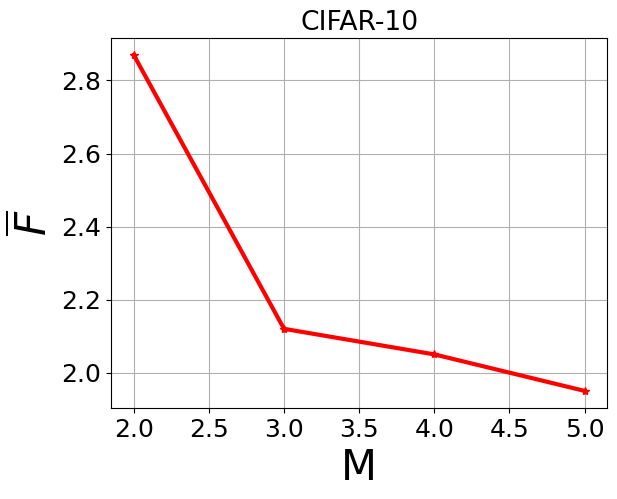
Fig 7 (page 12).
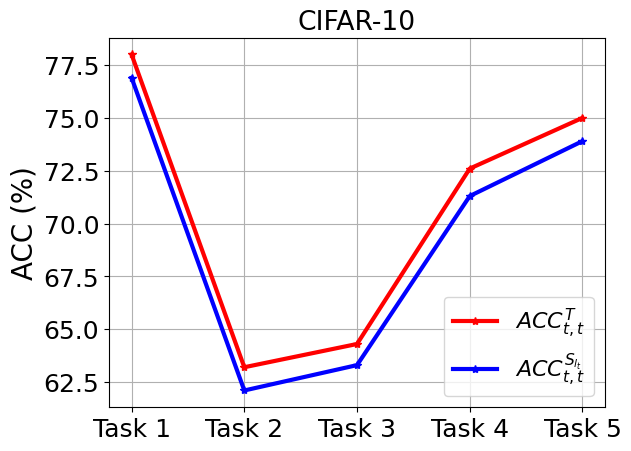
Fig 3: Experiments on imbalanced data.
Limitations
- Evaluation limited to vision datasets with known number of clusters per task; no exploration on other modalities or unknown cluster counts during training.
- Relies on predetermined cluster count λt per task, which may not be realistic in some unsupervised continual learning scenarios.
- No adversarial or robust evaluation against malicious attacks or noisy data streams.
- Details on training epochs, optimizer hyperparameters, and training time/performance tradeoffs are sparse or deferred to appendix.
- The approach assumes disjoint class sets per task; effectiveness unclear if class overlap or domain shifts between tasks occur.
- While memory efficient compared to replay or large model storage, the method still requires storing multiple student networks; scaling to very large number of tasks may be constrained.
Open questions / follow-ons
- How would FBCC perform if the number of clusters per task is unknown or varies dynamically during continual learning?
- Can the forward-backward distillation framework be extended to other modalities such as text or time series data streams?
- What is the impact of domain shifts or overlapping classes between sequential tasks on clustering stability and forgetting in FBCC?
- Is there a theoretical analysis of the knowledge consolidation process through multiple lightweight students and its limits?
Why it matters for bot defense
From a bot-defense and CAPTCHA perspective, FBCC presents important insights for designing systems that must learn evolving user behavior or bot patterns without labeled data or storing extensive historical logs, due to privacy or memory constraints. Its dual-phase knowledge distillation approach could inform continual adaptation of challenge-response models that cluster behavioral features over time, mitigating degradation caused by distribution shifts. Prototypes and specialized lightweight models might serve as compact memories preserving important latent structures relevant to bot detection. However, practical application would require extension to handle unknown cluster numbers, concept drift common in adversarial contexts, and potentially adversarially corrupted inputs. The framework's emphasis on unsupervised incremental clustering addresses a core need for bot-defense systems to update detection criteria on-the-fly without costly retraining or sensitive data retention.
Cite
@article{arxiv2606_07474,
title={ Unsupervised Continual Clustering via Forward-Backward Knowledge Distillation },
author={ Mohammadreza Sadeghi and Sareh Soleimani and Zihan Wang and Narges Armanfard },
journal={arXiv preprint arXiv:2606.07474},
year={ 2026 },
url={https://arxiv.org/abs/2606.07474}
}