
Twelve quick tips for designing AI-driven HPC workflows
Source: arXiv:2606.07491 · Published 2026-06-05 · By Jamie J. Alnasir
TL;DR
This paper addresses the growing challenges in designing high-performance computing (HPC) workflows that integrate artificial intelligence (AI) components, especially foundation models, which introduce iterative, probabilistic, and data-driven execution paradigms unlike traditional deterministic HPC pipelines. By presenting twelve practical tips, the author lays out best practices to architect AI-driven HPC workflows that are efficient, scalable, and reproducible. These tips encompass changes at multiple levels including resource allocation, data management, workflow orchestration, and experiment tracking.
The key contribution lies in conceptualizing AI as a core, dynamic part of the HPC workflow rather than a peripheral module, highlighting the need for intentional designs that accommodate data gravity, heterogeneous compute resource usage, explicit feedback mechanisms, and throughput-oriented optimization, among others. The tips collectively help researchers transition from rigid linear pipelines to adaptive workflows suited for complex scientific domains such as computational biology. Although qualitative, these guidelines synthesize prior scientific workflow research and AI workload characteristics into a cohesive design blueprint for HPC practitioners adopting AI.
Key findings
- AI-driven HPC workflows differ architecturally from traditional pipelines by being iterative, data-driven, and adaptive with dynamic control flow (Fig 1).
- Treating AI as integrated (not bolt-on) enables defining explicit training, validation, and feedback loops to improve reproducibility and coherence.
- Designing for data gravity (computation close to data) reduces costly data transfers and I/O bottlenecks common in AI workflows involving large datasets.
- Separating workflow phases (training, inference, simulation) allows matching task resource requirements to heterogeneous HPC resources (e.g., GPUs for training, CPUs for preprocessing).
- Job arrays facilitate scalable execution of parallel inference or hyperparameter tuning tasks with minimal scheduler overhead; distributed training accelerates large model training but requires careful synchronization.
- Containerization (e.g., Apptainer) ensures reproducible software environments across dynamically evolving AI and HPC software stacks.
- Explicit experiment tracking of models, hyperparameters, data versions, and metrics is critical for experiment provenance and reproducibility.
- Workflow engines (e.g. Nextflow, Snakemake, Parsl) are essential to orchestrate dynamic feedback loops and adaptive workflows beyond static pipelines.
Threat model
n/a - The paper is focused on computational and architectural design principles for AI-driven workflows in HPC environments, rather than on security or adversarial threat modeling.
Methodology — deep read
The paper does not present new empirical experiments but synthesizes practical insights into a structured set of design principles. The methodology can be understood as follows:
Threat Model & Assumptions: The focus is on the computational challenges posed by integrating AI into HPC workflows rather than on adversarial threats. Assumptions include shared HPC systems with heterogeneous compute and shared storage subject to contention.
Data: The paper discusses typical scientific datasets used in computational biology (large simulations, omics data, image data) but does not analyze specific datasets. The referred data scales highlight challenges around repeated data access and I/O.
Architecture / Algorithm: The workflow is conceptualized as an adaptive feedback loop (Fig 1) where AI models continuously evolve using outputs from simulations and in turn influence subsequent steps. The design advocates disaggregation of workflows into phases (training, inference, simulation) matched to resource types, and explicit encoding of feedback loops and resource requests.
Training Regime: No specific training details since no novel models are trained. However, recommended practices emphasize segregating GPU-intensive training jobs from CPU-bound preprocessing and inference.
Evaluation Protocol: Rather than benchmarks, evaluation is conceptual and experiential, focusing on efficiency, throughput, reproducibility, and manageability in live HPC environments. Performance considerations include scheduler overhead, data movement costs, and scalability.
Reproducibility: Strong emphasis on containerization to guarantee software environment consistency, and on structured experiment metadata tracking. Workflow engines enable reproducible, auditable execution. Practical tools cited include Apptainer, MLflow, Nextflow, Snakemake.
For example, a typical adaptive workflow would stage data locally to minimize I/O, use job arrays for massively parallel inference tasks, containerize the software stack including CUDA and Python libraries, and use a workflow engine like Nextflow to explicitly encode iterative feedback loops, enabling reproducible and scalable execution on shared HPC clusters.
Technical innovations
- Conceptualizing AI as a co-evolving, integral component of HPC workflows rather than an add-on step.
- Explicit emphasis on designing workflows around data gravity to reduce costly data movement bottlenecks in AI-HPC pipelines.
- Separating distinct computation phases (training, inference, simulation) for optimized resource scheduling on heterogeneous HPC environments.
- Promoting job arrays and distributed training as complementary primitives for scalable AI task orchestration within HPC schedulers.
- Use of workflow engines to implement dynamic, adaptive feedback loops supporting iterative, conditional HPC workflow execution.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.07491.
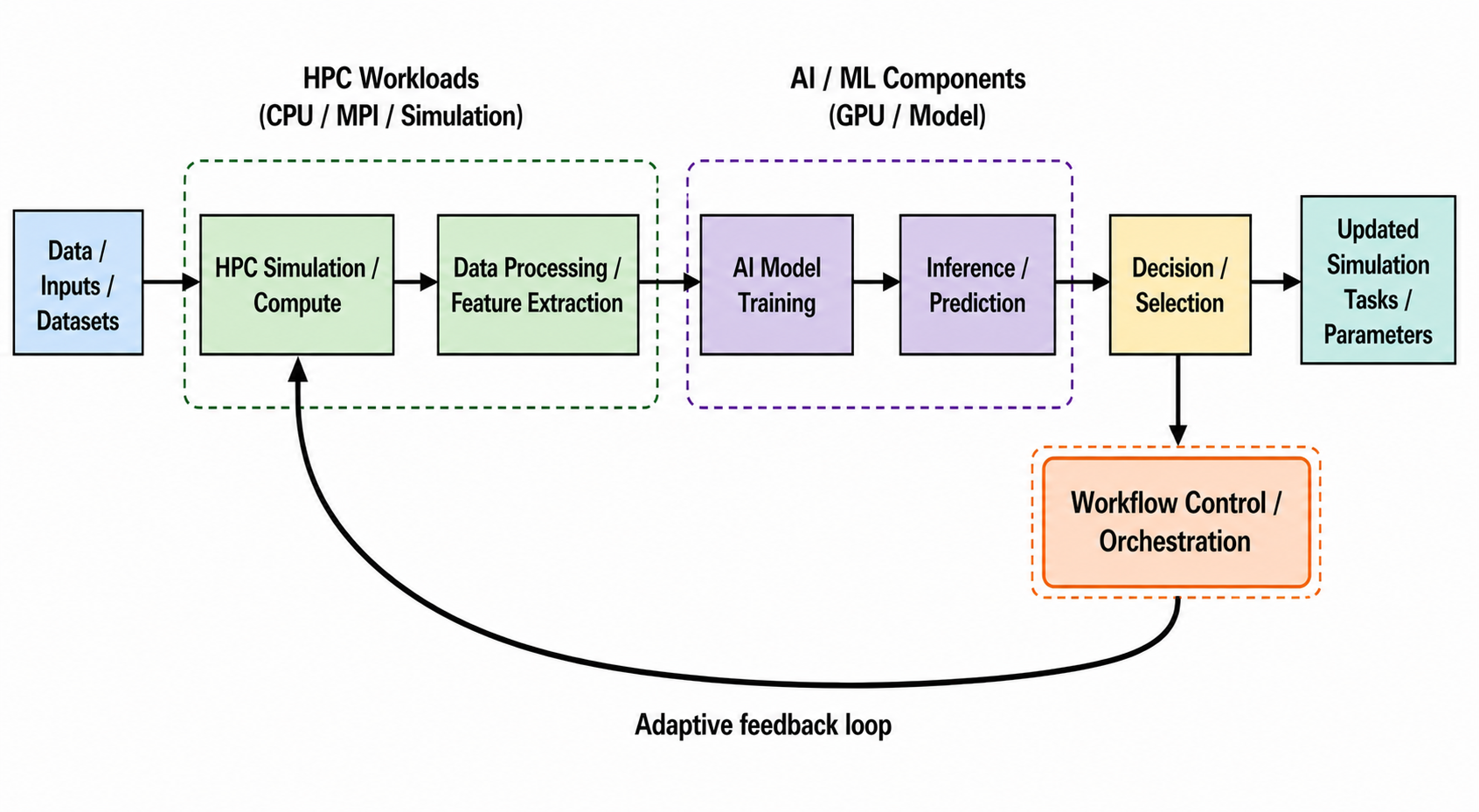
Fig 1: Conceptual architecture of an AI-driven HPC workflow with an adaptive feedback loop.
Limitations
- The paper is conceptual and does not provide quantitative performance evaluations or benchmarks of the proposed guidelines.
- No adversarial or attacker threat model is evaluated despite increasing use of AI in security-sensitive HPC settings.
- Recommendations may require substantial changes to existing HPC operational practices, which may not be straightforward for all sites.
- The guidance focuses mainly on computational biology but generality to other scientific domains, though suggested, is not empirically validated.
- Does not address robustness or fault tolerance of these adaptive workflows under resource contention or failures.
Open questions / follow-ons
- How do these design principles quantitatively impact HPC cluster utilization, throughput, and user wait times across diverse real workloads?
- What are the best practices for fault tolerance and recovery in dynamic, adaptive AI-HPC workflows incorporating feedback loops?
- How to extend containerization and workflow orchestration standards to support rapidly evolving foundation models and emerging AI hardware accelerators?
- Can explicit modeling of data gravity and compute locality be incorporated into automated scheduler heuristics for improved resource efficiency?
Why it matters for bot defense
While focused on scientific HPC workflows, the principles outlined in this paper have important implications for bot-defense and CAPTCHA practitioners building AI-driven high-throughput systems. Understanding the shift from linear to adaptive, feedback-driven workflows encourages security engineers to architect bot detection or CAPTCHA validation pipelines that dynamically iterate using AI predictions to improve precision. The emphasis on data gravity, resource heterogeneity, and throughput optimization informs infrastructure choices for scaling AI models in production, minimizing data movement costs that can otherwise become bottlenecks.
Moreover, the recommendation to adopt workflow engines to orchestrate these complex processes reduces operational complexity and improves reproducibility, which is critical in adversarial settings where consistent behavior and auditability are key. Experiment tracking and containerization also ensure that bot-defense models can be reliably retrained and deployed across diverse environments. Hence, bot-defense engineers tackling AI-powered CAPTCHA pipelines on HPC or cloud clusters can adapt many of these architectural tips to improve scalability and maintainability.
Cite
@article{arxiv2606_07491,
title={ Twelve quick tips for designing AI-driven HPC workflows },
author={ Jamie J. Alnasir },
journal={arXiv preprint arXiv:2606.07491},
year={ 2026 },
url={https://arxiv.org/abs/2606.07491}
}