
Mitigating Proxy-to-Wild Domain Gap in Deepfake Speech
Source: arXiv:2606.07494 · Published 2026-06-05 · By Xuanjun Chen, Yun-Shing Wu, Wei-Chung Lu, Claire Lin, Haibin Wu, Hung-yi Lee et al.
TL;DR
This paper tackles the critical problem of poor generalization in deepfake speech detection when models trained on proxy resynthesized data (CoRS) encounter real-world synthesized speech (CodecFake) from diverse and unseen codec-based speech generation systems (CoSG). Although codec resynthesis data helps improve detection performance over conventional datasets, there remains a substantial proxy-to-wild domain gap that degrades performance against evolving in-the-wild attacks. To address this, the authors propose Domain-Shift Feature Augmentation (DSFA), a novel fine-tuning augmentation that models domain uncertainty by converting deterministic feature statistics into stochastic distributions, thereby simulating "in-the-wild" variations. This is combined with a post-trained self-supervised learning (SSL) backbone fine-tuned on proxy data to establish a domain-invariant, robust feature space. To rigorously evaluate the approach, they introduce a new CoSG Extension Evaluation dataset (CoSG ExtEval) with 40 previously unseen generative models and longer audio samples, thus providing a more challenging and realistic benchmark. Experimental results show that DSFA consistently narrows the proxy-to-wild domain gap, reducing equal error rates (EER) to 2.78% on the existing CoSG Eval and 21.80%-22.77% on the more difficult CoSG ExtEval dataset, advancing the state-of-the-art in CodecFake detection.
Key findings
- Post-trained SSL backbone achieves EERs of 3.95% on CoSG Eval and 22.19% on CoSG ExtEval, significantly outperforming conventional backbones such as Wav2Vec2-AASIST.
- DSFA augmentation with domain-shift sampling reduces EER from 3.00% to as low as 2.78% on CoSG Eval and improves CoSG ExtEval EER from 24.08% to 21.80%-22.77%.
- Uniform noise perturbation at SSL layer 24 achieves the best CoSG ExtEval EER of 22.85%, while Gaussian noise at layer 1 performs best on CoSG Eval (2.78%) and CoSG ExtEval (22.61%).
- Optimal DSFA application probability p=0.25 offers the best generalization tradeoff, improving ExtEval EER to 22.77% from 24.08% (no DSFA) without sacrificing CoSG Eval performance.
- Models trained with taxonomy-guided balanced sampling (DEC Balance) outperform other proxy data sampling methods, reaching 11.91% EER on CoSG Eval and 27.07% on CoSG ExtEval with Wav2Vec2-AASIST backbone.
- Naive model trained on proxy data shows severe EER degradation on CoSG ExtEval (up to 38.93%), exposing the proxy-to-wild domain gap severity.
- Visualizations reveal DSFA narrows feature distribution discrepancies between proxy (CoRS) and wild (CoSG) data in both mean and standard deviation statistics, e.g., mean overlap improved from 42.91% to 43.03% and STD overlap from 65.01% to 67.09%.
- SupCon loss improves compactness on CoSG Eval but slightly degrades robustness on CoSG ExtEval, indicating tradeoffs in loss design for generalization.
Threat model
The adversary is a malicious actor generating deepfake speech using unknown codec-based neural audio generation models that produce realistic spoofed audio with diverse, unseen codec signatures and speaker contents. The adversary's goal is to bypass deepfake detection systems trained on proxy resynthesized speech data lacking knowledge or access to the detection model internals or augmentation techniques. They cannot directly manipulate model features or training data. The defender assumes honest training on proxy datasets and aims to generalize to evolving spoofing attacks under unknown domain shifts.
Methodology — deep read
Threat Model & Assumptions: The adversary is a malicious entity who generates deepfake speech using diverse neural audio codec-based speech synthesis systems (CodecFake), including unseen codec designs and generation paradigms not covered during training. The defender trains deepfake detection models using proxy data composed of codec resynthesized speech (CoRS) but faces the challenge that the actual attack data distribution (wild domain) is unknown and may substantially differ with unique artifacts, varying silence patterns and speaker/content mismatches. The adversary cannot manipulate the feature statistics directly but produces audio from unknown generative systems.
Data: Training uses the CodecFake+ dataset, where 42,965 bona fide and 42,965 spoofed proxy samples (CoRS) are drawn from the VCTK corpus with 31 neural codecs. The testing is conducted on two evaluation sets: CoSG Eval with 17 unseen codec-based generation models (931 spoofed samples) and the newly collected CoSG ExtEval dataset with 40 unseen generative models (1366 spoofed samples). Both evaluation datasets contain longer audio clips, with average length 5-8 seconds (CoSG Eval) and up to nearly 150 seconds (CoSG ExtEval). Samples were sourced from official demos and public repositories, ensuring zero overlap with training data.
Architecture / Algorithm: The backbone model is a post-trained Wav2Vec2-Large SSL network fine-tuned on deepfake detection. DSFA is introduced as an augmentation module applied to latent SSL feature maps during fine-tuning. It computes channel-wise mean (μ) and standard deviation (σ) statistics per batch, then models their uncertainty as mini-batch variance (Σ²_{μ}, Σ²_{σ}). During training, DSFA perturbs μ and σ with uniform or Gaussian noise sampled from these estimated distributions, using a reparameterization trick for differentiability. The perturbed statistics are applied using adaptive instance normalization (AdaIN) to create augmented feature maps. This simulates domain shifts from proxy to wild data distributions. DSFA is applied with probability p (tuned between 0 and 1). The loss combines cross-entropy (CE) with supervised contrastive (SupCon) loss weighted by λ. This dual loss encourages compact, discriminative embeddings invariant to domain shifts.
Training Regime: Models are trained on Nvidia 3090 GPUs with batch size 14, Adam optimizer (LR=1e-6, weight decay=1e-4). Inputs are 4-second raw waveforms sampled at 16 kHz with basic Raw-Boost augmentation. DEC balanced subset sampling ensures equal representation across codec decoders. Fine-tuning occurs over multiple epochs (not explicitly detailed). DSFA is incorporated during fine-tuning, with ablations on which SSL layer to augment (layers 1, 6, 12, 18, 24 tested) and augmentation application probability p (0 to 1).
Evaluation Protocol: Performance measured by Equal Error Rate (EER %) on several test sets: ASVspoof19 LA as baseline, CoRS, CoSG Eval, and CoSG ExtEval. Comparisons are made against models trained on different proxy datasets and sampling strategies (balanced/unbalanced). Ablations test different DSFA noise distributions (uniform vs Gaussian), SSL layers to augment, and loss weighting (CE vs CE+SupCon). Cross-domain generalization to unseen codec generative models is the focus, with CoSG ExtEval serving as a rigorous unseen test set. Visualizations of latent feature statistics distributions analyze proxy-to-wild domain gap reduction.
Reproducibility: The authors state intentions to release the CoSG ExtEval dataset and code on Github after acceptance. The post-trained SSL backbone is publicly available (Wav2Vec2-Large-AntiDeepfake). Exact hyperparameters beyond optimizer and batch size are partly unspecified (e.g., epoch count). The paper provides sufficient methodological details for reproducing DSFA augmentation and evaluation on the CodecFake+ benchmark.
A Concrete Example: A 4-second audio sample from CoRS proxy data is passed through the post-trained Wav2Vec2 SSL model, generating latent feature maps with dimension B×C×T. The DSFA module computes the mean and STD feature statistics along channels and calculates batch-wise variance from the statistics. It samples noise vectors scaled by these variances (e.g., uniform noise) and perturbs the means and STDs accordingly. The perturbed statistics re-normalize the features via AdaIN, producing an augmented feature map that reflects potential unseen domain shifts. The model then updates weights using the joint CE + SupCon loss on this perturbed input, improving robustness to real wild fake samples. The model is evaluated on the CoSG ExtEval dataset containing long-form audio from 40 unseen codec synthesis models, resulting in a 21.8% EER versus baseline >30%.
Technical innovations
- Domain-Shift Feature Augmentation (DSFA) transforms deterministic channel-wise feature statistics into stochastic distributions to simulate domain shifts during fine-tuning, enhancing model robustness to unseen codec-based speech generation artifacts.
- Integration of a post-trained self-supervised learning (SSL) backbone tailored for deepfake detection to provide a versatile latent feature space sensitive to both bona fide and spoof artifacts.
- Use of batch-wise variance of feature statistics as a data-driven uncertainty modeling technique to define perturbation distributions for domain-shift augmentation.
- Application of adaptive instance normalization (AdaIN) to apply sampled domain-shift perturbations to SSL latent features within an end-to-end differentiable framework.
- Introduction of the CoSG Extension Evaluation (CoSG ExtEval) dataset featuring 40 unseen generative models and long-form audio, enabling more realistic evaluation of domain generalization in CodecFake detection.
Datasets
- CoRS Proxy Training Subset — 85,930 samples (42,965 bona fide + 42,965 spoofed) — derived from neural audio codec resynthesis of VCTK corpus
- CoSG Eval — 1,781 samples (850 bona fide, 931 spoofed) from 17 unseen codec-based generative models — collected from public demo pages and repositories
- CoSG ExtEval — 2,588 samples (1,222 bona fide, 1,366 spoofed) from 40 unseen codec-based generative models including diverse architectures and long-form audio — collected similarly to CoSG Eval
Baselines vs proposed
- Wav2Vec2-AASIST backbone trained on CoRS (DEC Balance): EER = 11.91% on CoSG Eval vs proposed PT-Wav2Vec2-FT + DSFA: 3.00%
- Wav2Vec2-AASIST backbone trained on CoRS (DEC Balance): EER = 27.07% on CoSG ExtEval vs proposed PT-Wav2Vec2-FT + DSFA: 21.80%
- Post-trained Wav2Vec2 (no fine-tuning): EER = 3.95% on CoSG Eval and 22.19% on CoSG ExtEval, improved over Wav2Vec2-AASIST (e.g., 14.09% / 38.93% respectively)
- DSFA augmentation at SSL layer 24 with uniform noise: EER = 2.78% (CoSG Eval) vs baseline model without DSFA: 3.00%
- DSFA augmentation probability p=0.25 reduces EER on CoSG ExtEval from 24.08% (no DSFA) to 22.77%, maintaining CoSG Eval performance at 2.78%
- Adding SupCon loss lowers EER on CoSG Eval to 2.78% but slightly worsens CoSG ExtEval from 22.19% to 23.00%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.07494.
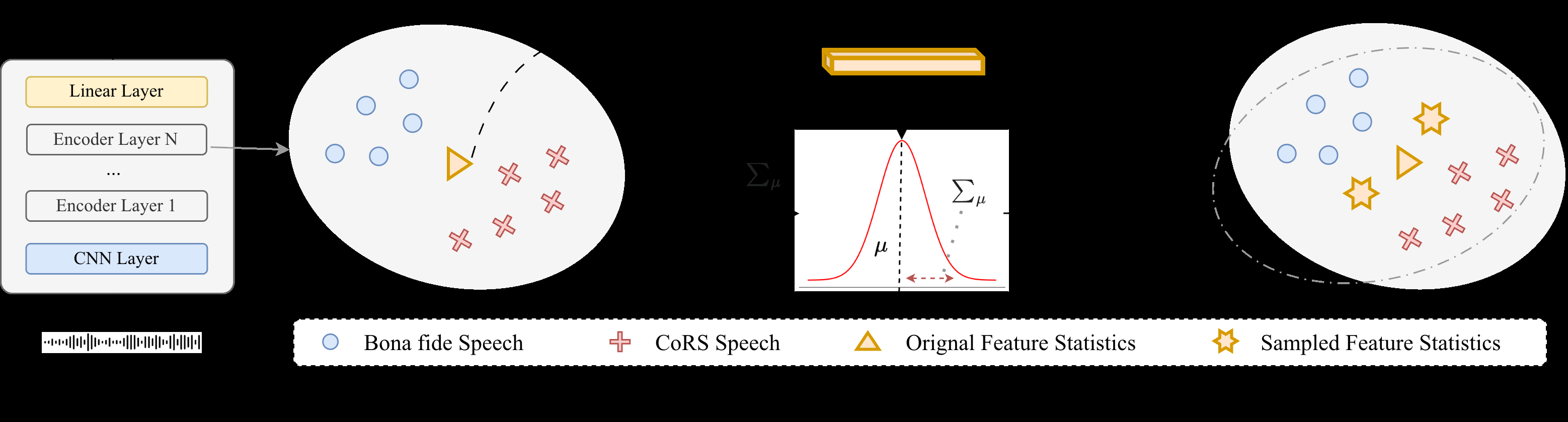
Fig 1: Overview of the Domain Shift Feature Augmentation (DSFA) method. The proposed method estimates feature statistics µ and
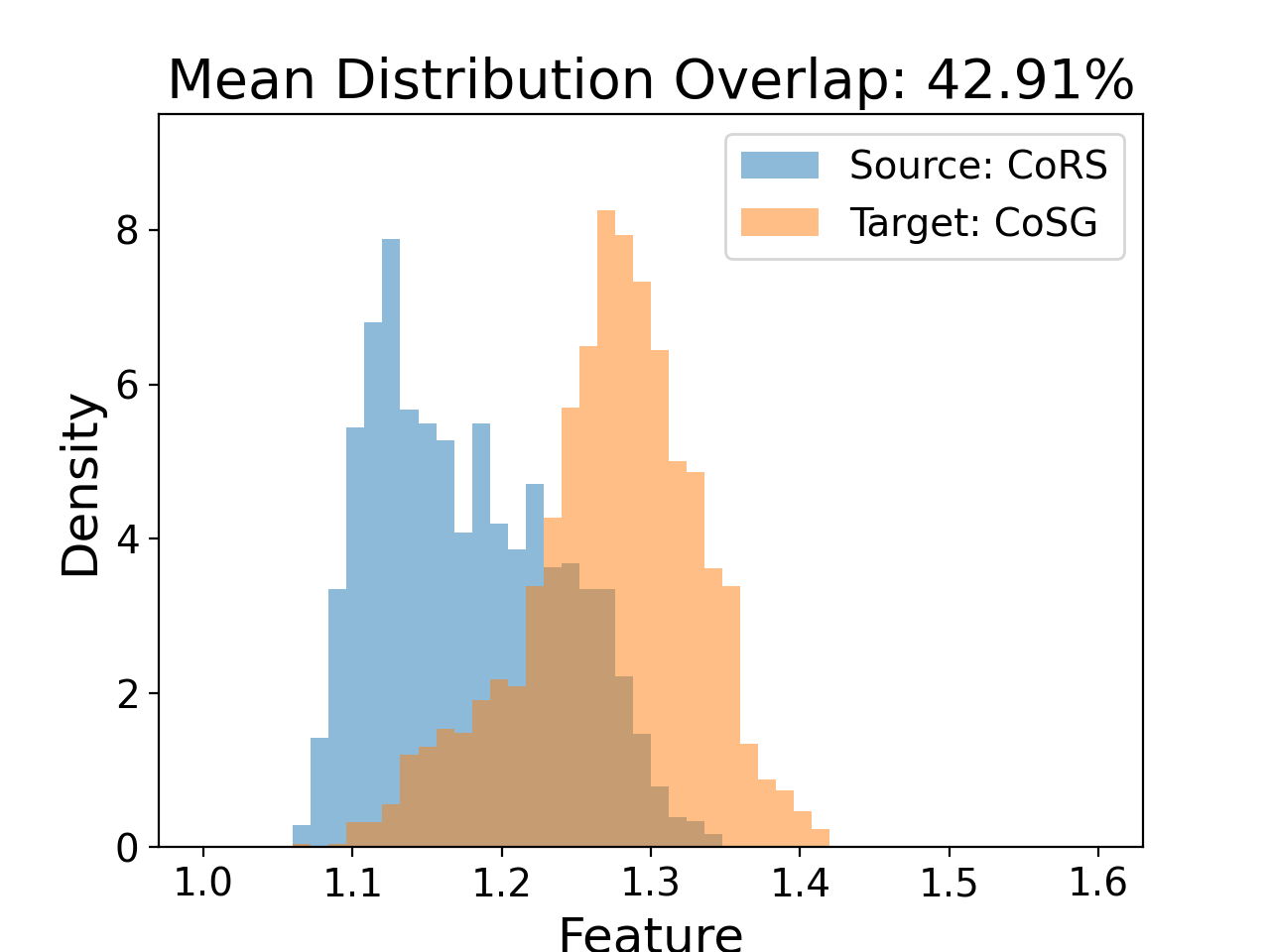
Fig 2: The Proxy-to-Wild Domain Gap Analysis.
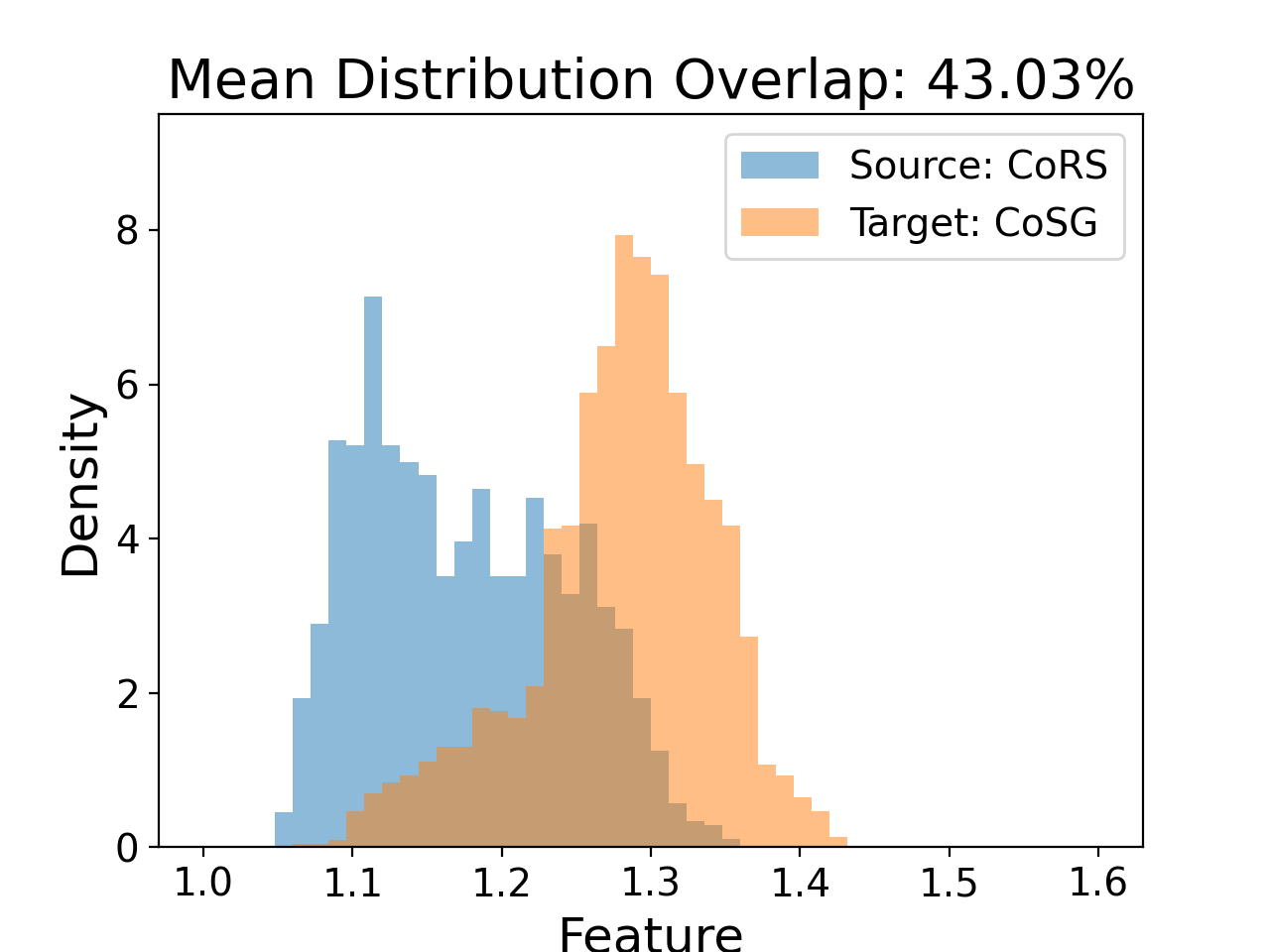
Fig 3 (page 4).
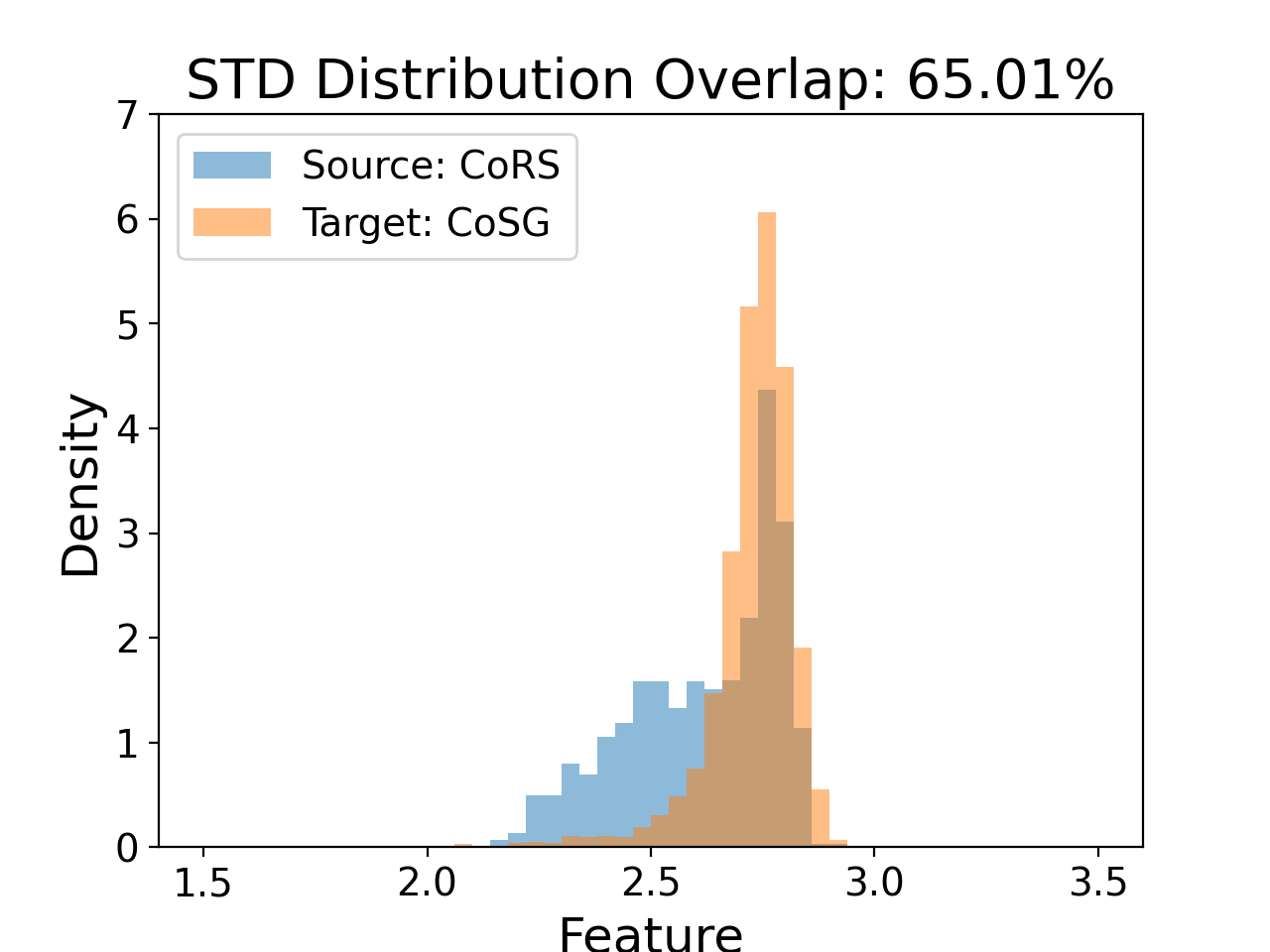
Fig 4 (page 4).
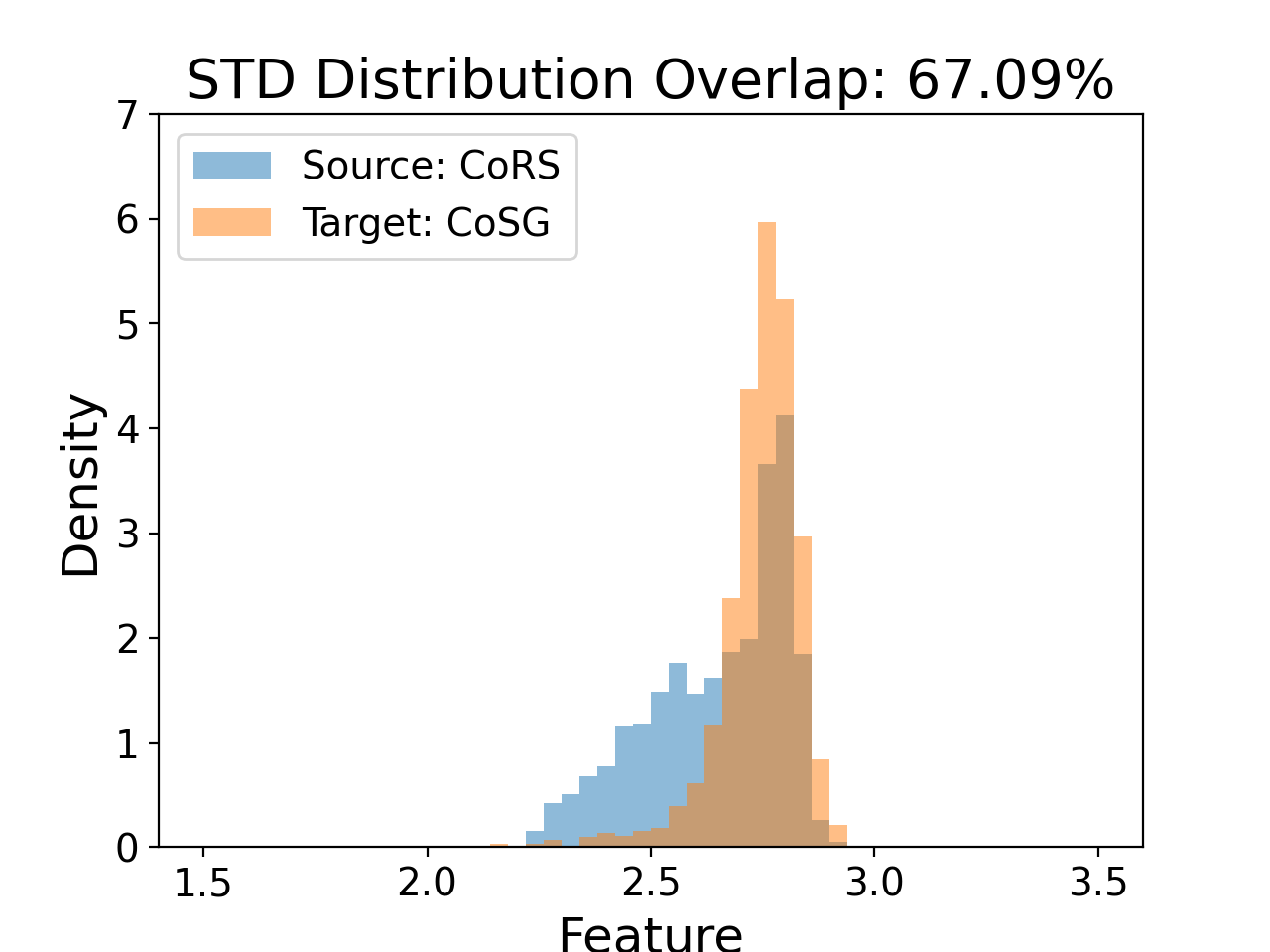
Fig 5 (page 4).
Limitations
- CoSG ExtEval dataset and code are not currently publicly released, limiting immediate reproducibility and external benchmarking.
- Experiments focus on EER metric without reporting other metrics like detection error tradeoff (DET) curves or robustness against adversarial perturbations.
- While DSFA models domain uncertainty via batch-wise variance, more explicit adversarial or generative domain shift modeling could potentially offer further gains.
- Long-form audio impacts generalization but analysis on how temporal dependencies affect detection robustness remains preliminary and future work is needed.
- The study lacks detailed analysis on computational cost and inference latency ramifications of DSFA augmentation and SSL backbone.
- Use of SupCon loss produces mixed results on generalization; full impact of multi-objective training schedules requires further investigation.
Open questions / follow-ons
- How can domain-shift augmentation methods be extended to explicitly incorporate temporal dynamics and long-form audio modeling in deepfake detection?
- What is the impact of adversarial attacks crafted to exploit residual proxy-to-wild domain gaps on DSFA-augmented models?
- Could generative adversarial training or domain adaptation techniques better bridge proxy and wild distributions compared to static feature perturbation?
- How does DSFA perform in multilingual, cross-lingual, or multi-speaker settings beyond the primarily English VCTK corpus used here?
Why it matters for bot defense
This work is highly relevant for bot-defense and CAPTCHA practitioners focused on audio deepfake detection and forgery prevention. It explicitly addresses the challenge of distributional mismatch when training deepfake detectors using proxy data (codec resynthesis) but deploying them on real-world spoofed speech from diverse and evolving generative models. The proposed Domain-Shift Feature Augmentation (DSFA) method is a practical approach to simulate domain uncertainty during model fine-tuning, making detection models more robust to unseen codec-based speech synthesis. Furthermore, the introduction of the CoSG ExtEval dataset with long-form audio and a broad variety of codecs provides a more realistic benchmark, enabling practitioners to test generalization explicitly.
Adapting SSL representations with such stochastic feature augmentations could be integrated into existing audio authentication pipelines or anti-spoofing layers in CAPTCHA systems that verify human vs. synthetic speech. However, careful attention is needed to balance augmentation strength and maintain stable false positive rates, especially in real-world environments with long or noisy audio. While not a turnkey solution for all audio deepfake scenarios, the principles demonstrated here provide valuable insights into modeling domain uncertainty and reducing proxy-to-wild gaps that commonly undermine deepfake countermeasure deployment.
Cite
@article{arxiv2606_07494,
title={ Mitigating Proxy-to-Wild Domain Gap in Deepfake Speech },
author={ Xuanjun Chen and Yun-Shing Wu and Wei-Chung Lu and Claire Lin and Haibin Wu and Hung-yi Lee and Jyh-Shing Roger Jang },
journal={arXiv preprint arXiv:2606.07494},
year={ 2026 },
url={https://arxiv.org/abs/2606.07494}
}