
How Far Can Chord-Symbol Time-Series Adaptation Carry Genre Identity? Capabilities and Boundaries in Multi-Genre Chord-Symbol Modeling
Source: arXiv:2606.07334 · Published 2026-06-05 · By Jinju Lee
TL;DR
This paper investigates the extent to which chord-symbol sequences—compact, interpretable symbolic representations of harmony—carry genre identity in multi-genre chord prediction. The author adapts a frozen pop-jazz Music Transformer base model to eleven diverse target genres using five parameter-efficient fine-tuning (PEFT) methods (LoRA, IA3, BitFit, prefix tuning, full fine-tuning) and a control-token baseline. Through an extensive 165-experiment grid (5 methods × 11 genres × 3 seeds), all adaptation methods improve held-out next-chord prediction accuracy over the frozen base by 2.9 to 3.6 percentage points macro on top-1 accuracy. However, pairwise significance tests do not identify a clear winning method, indicating that gains arise largely from the chord-symbol representation and data rather than adapter-specific effects. Additional analyses, including a matched data-size control, wrong-genre adapter testing, chord-only genre classification, and real-song evaluation, consistently show that chord symbols contain partial but incomplete genre information. The results support a bounded view: chord-symbol adaptation reliably improves harmonic prediction in a genre-local manner but cannot fully encode genre identity, which depends on omitted musical layers like rhythm, timbre, voicing, and performance practice. This framing suggests chord symbols are a useful yet limited controllable layer for music AI.
Key findings
- All five adaptation methods improve held-out chord prediction over the frozen base with macro top-1 accuracy gains from +2.89 to +3.61 percentage points.
- LoRA and IA3 achieve the highest macro top-1 scores (82.51% and 82.41%), but pairwise Wilcoxon tests with Holm and Benjamini-Hochberg corrections show no statistically decisive winner.
- When data for each genre is sub-sampled to a common corpus size, IA3 remains strongest but LoRA's prior full-data lead disappears, dropping it to last among four tested methods, indicating method differences are partly data-driven.
- A control-token baseline achieves a strong 82.01% macro top-1, narrowing gaps to adapters and weakening claims that adapters are necessary for gains.
- Wrong-genre adapters often outperform the frozen base and approach matched-genre adapter scores (mean matched-minus-off-diagonal gain +3.07 pp), indicating adaptation captures general corpus effects beyond pure genre conditioning.
- Chord-only genre classification yields low macro F1 (0.171) above chance (0.091), confirming measurable but incomplete genre information in chord sequences.
- Generated outputs from adapted models show better alignment to target chord distributions but reduced chord vocabulary size and entropy, indicating adaptation sharpens style fidelity without increasing diversity.
- Real-song chord-chart evaluation with 10 songs per genre reflects held-out prediction gains, e.g., a +12.33 pp gain on Bach chorales, though samples are small and biased.
Threat model
The adversary is a user or system attempting to generate or predict chord progressions in specific genres using a frozen harmonic base model. The adversary can adapt the model with small parameter-efficient interfaces on genre-specific chord-symbol corpora but cannot modify or retrain the full model weights freely. They lack access to other musical non-chord features (rhythm, audio, lyrics). The threat is to assess how genre identity can be extracted or injected solely from chord-symbol sequences under these constraints.
Methodology — deep read
The study begins with a frozen baseline Music Transformer trained on a mixed pop-jazz chord-symbol corpus (approx. 1,513 jazz and 10,000 pop sequences). The baseline checkpoint (referred to as 'F1') has 25.6 million parameters using relative position attention tuned for chord-symbol sequences. The core question framed as a threat model is whether small adaptation interfaces can specialize this frozen generic harmonic model to 11 diverse genres (blues, bossa nova, Bach chorales, country, electronic, folk, funk, gospel, hip-hop, R&B/soul, rock) using only chord-symbol data, without melody, timbre, rhythm, or audio features. The dataset provenance is mainly from the Chordonomicon dataset (CC BY-NC license, non-commercial use), except Bach chorales sourced from the public music21 corpus; total genre dataset sizes range from 296 Bach chorales to 152,509 rock sequences, with detailed corpus statistics analyzed for vocabulary size, sequence length, entropy, and overlap. The tokenizer maps chord symbols and structural tokens into a vocabulary expanded per genre to 359 tokens, with normalization to canonical chord spellings. Five adaptation methods are evaluated: LoRA (low-rank updates to transformer projections), IA3 (multiplicative activation scaling), BitFit (bias-only tuning), prefix tuning (learned virtual token prepending), and full fine-tuning (all parameters), plus a control-token baseline learned genre conditioning embedding only. Each genre receives independent adaptation for eight epochs with three random seeds, using hyperparameters such as LoRA rank selected via pre-run sweeps (ranks 4 to 64) and prefix tuning with 20 virtual tokens. Trainable parameter counts vary widely—BitFit (0.9% model params), IA3 (1.5%), prefix tuning (2.1%), LoRA (4.5%), full fine-tuning (100%). Next-chord token prediction accuracy on held-out splits is the primary metric, complemented by top-5 accuracy and loss. Statistical tests include Wilcoxon signed-rank with Holm-Bonferroni and Benjamini-Hochberg multiple comparison correction across 33 folds per method (11 genres × 3 seeds). Additional evaluations probe adapter robustness (wrong-genre rotations), chord-only genre classification with a diagnostic classifier, generated output statistical distances to training distributions, real-song chord progression matching for external validity, duplicate/near-duplicate rate analysis, and ablation comparing to an alternative pop-only base checkpoint. Data size effects were assessed by subsampling ten genres to the funk genre's corpus size to control for training size bias. Training and evaluation were reproducible on a consumer laptop GPU (NVIDIA RTX 4070 Laptop). Code, checkpoints, data splits, and evaluation scripts are publicly released.
Technical innovations
- Using multiple PEFT adaptation interfaces (LoRA, IA3, BitFit, prefix tuning, full fine-tuning) as genre-specific adapters to probe genre information in chord-symbol sequences.
- Establishing a large-scale 165-experiment grid (5 methods × 11 genres × 3 seeds) with controlled data regimes to separate representational limits from method performance.
- Employing a control-token baseline as a lightweight genre-conditioning interface to test adapter necessity and isolate effects of chord-symbol conditioning versus adapter capacity.
- Introducing comprehensive diagnostics including wrong-genre adapter rotations, chord-only genre classification, and generated output distribution analysis to bound the representational capacity of chord-symbol sequences for genre identity.
Datasets
- Chordonomicon-derived contemporary genres — 2,269 to 152,509 sequences per genre — CC BY-NC 4.0 (non-commercial research use)
- Bach chorales — 296 sequences — music21 public corpus
Baselines vs proposed
- Frozen F1 base (pop-jazz pretrained): macro top-1 = baseline for adaptation methods
- LoRA: macro top-1 = 82.51% (+3.61 pp vs frozen base)
- IA3: macro top-1 = 82.41% (+3.51 pp)
- Prefix tuning: macro top-1 = 82.23% (+3.33 pp)
- Full fine-tuning: macro top-1 = 81.97% (+3.07 pp)
- BitFit: macro top-1 = 81.79% (+2.89 pp)
- Control-token baseline: macro top-1 = 82.01% (+3.11 pp)
- At matched corpus size for 10 genres: IA3 leads (85.17%), LoRA drops to last (84.44%), full fine-tuning (85.09%), BitFit (84.78%).
- Wrong-genre adapters improve over frozen base on 81/110 off-diagonal tests, mean matched-versus-off-genre gain +3.07 pp.
- Chord-only genre classifier achieves macro F1 0.171 vs chance 0.091, confirming partial genre information but limited separability.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.07334.
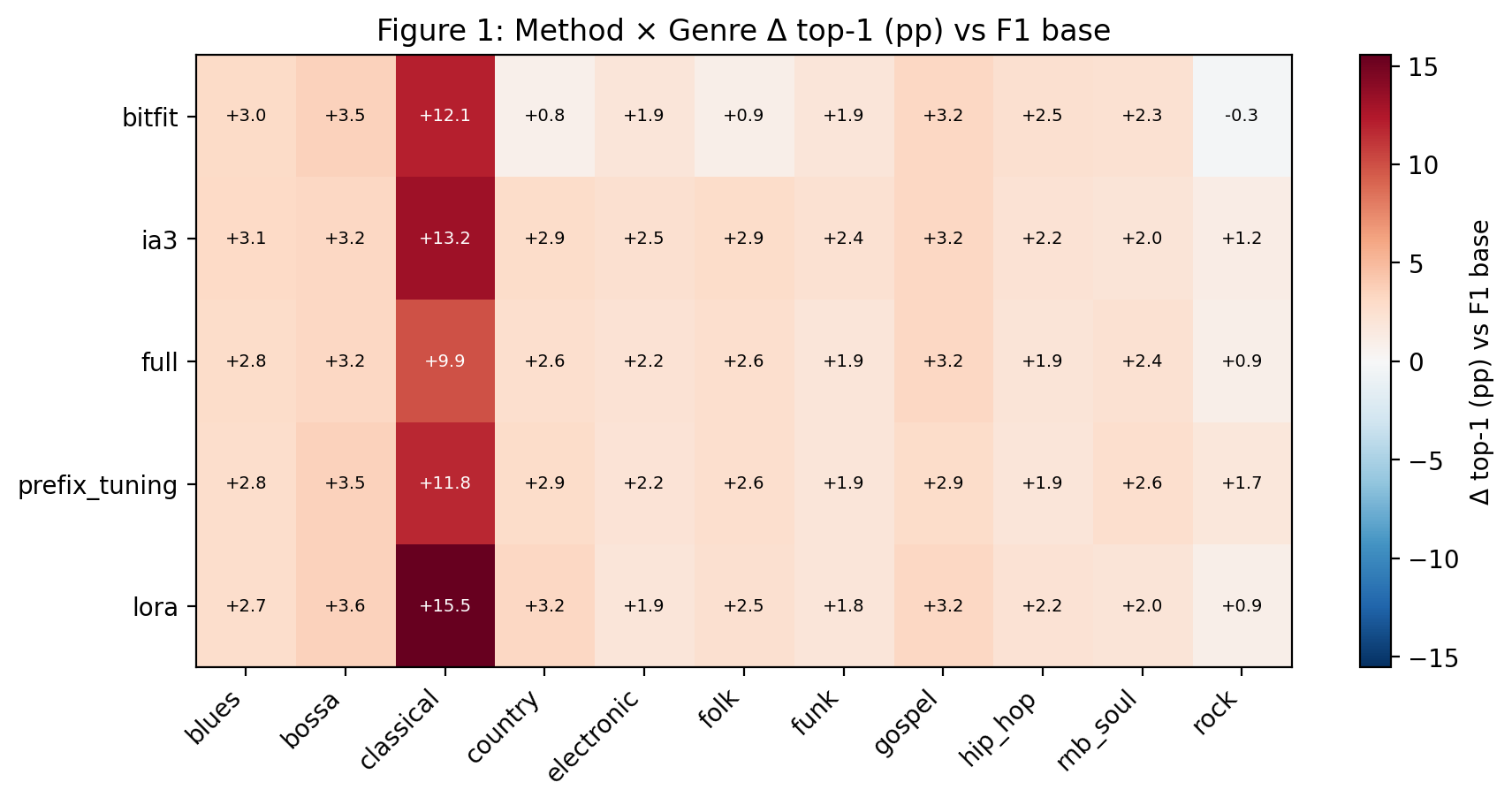
Fig 1: Method x genre Delta top-1 (pp) versus the frozen F1 base.
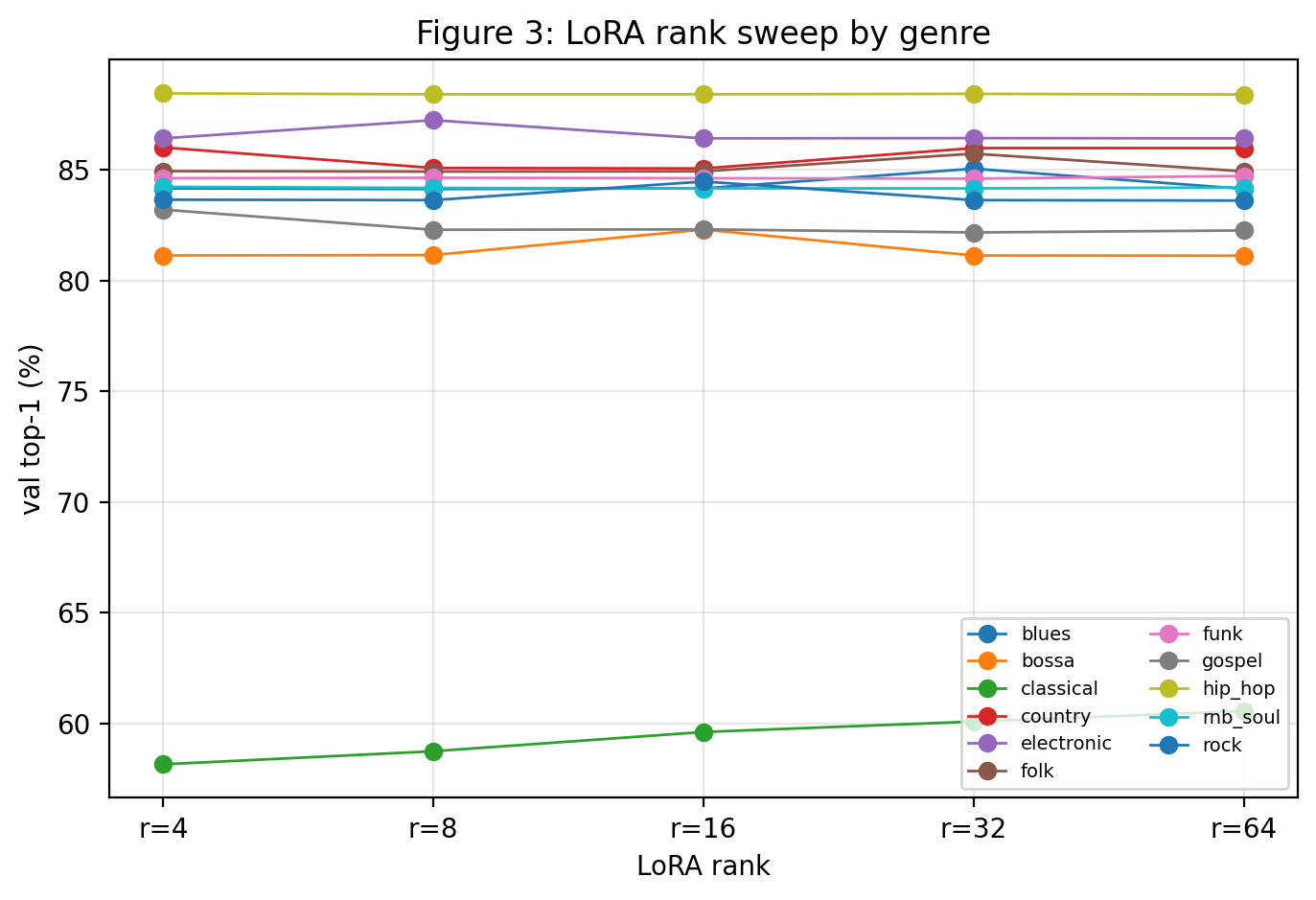
Fig 2: LoRA validation top-1 across rank for each genre.
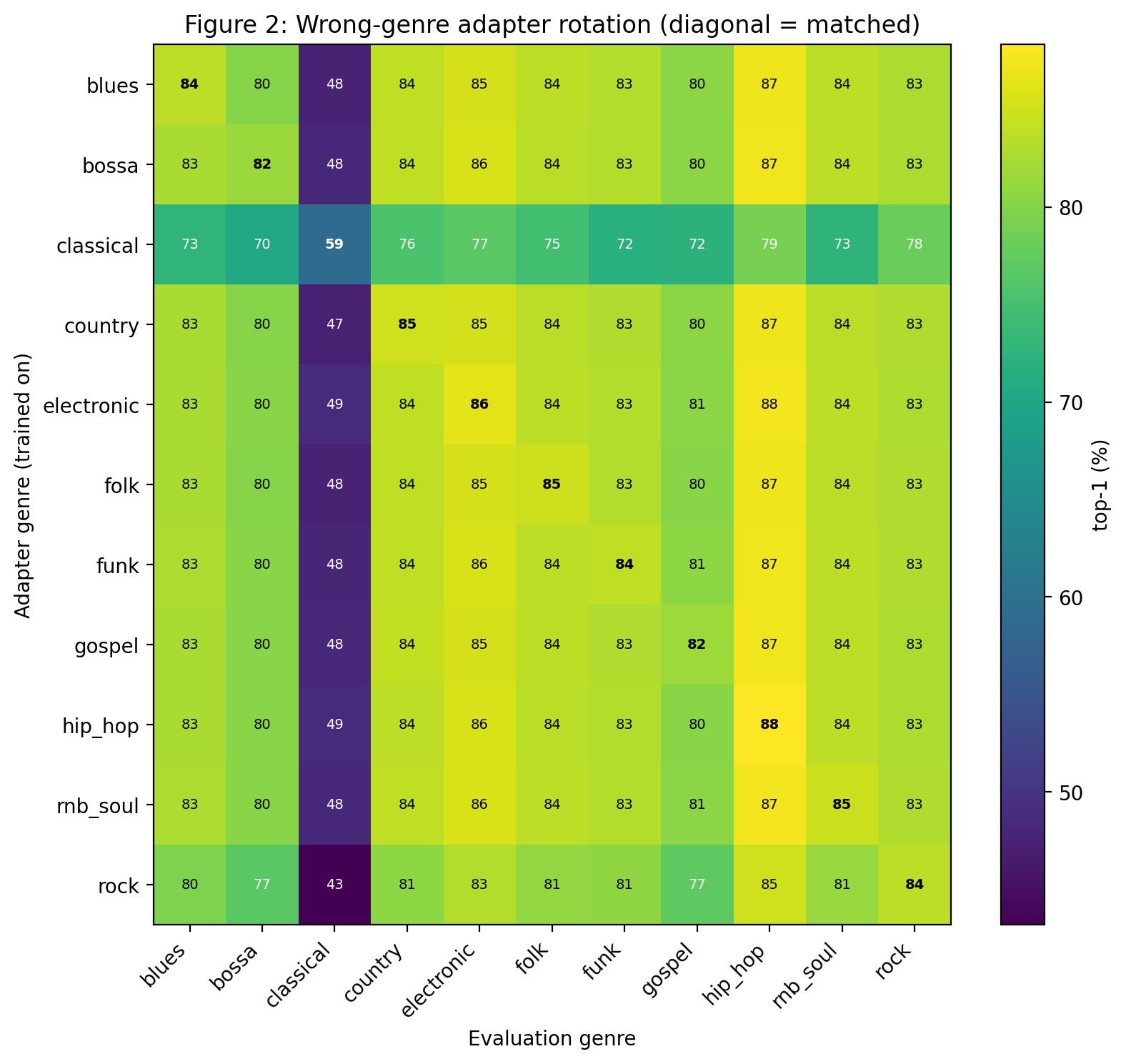
Fig 3: Wrong-genre adapter rotation; the diagonal is the matched adapter.
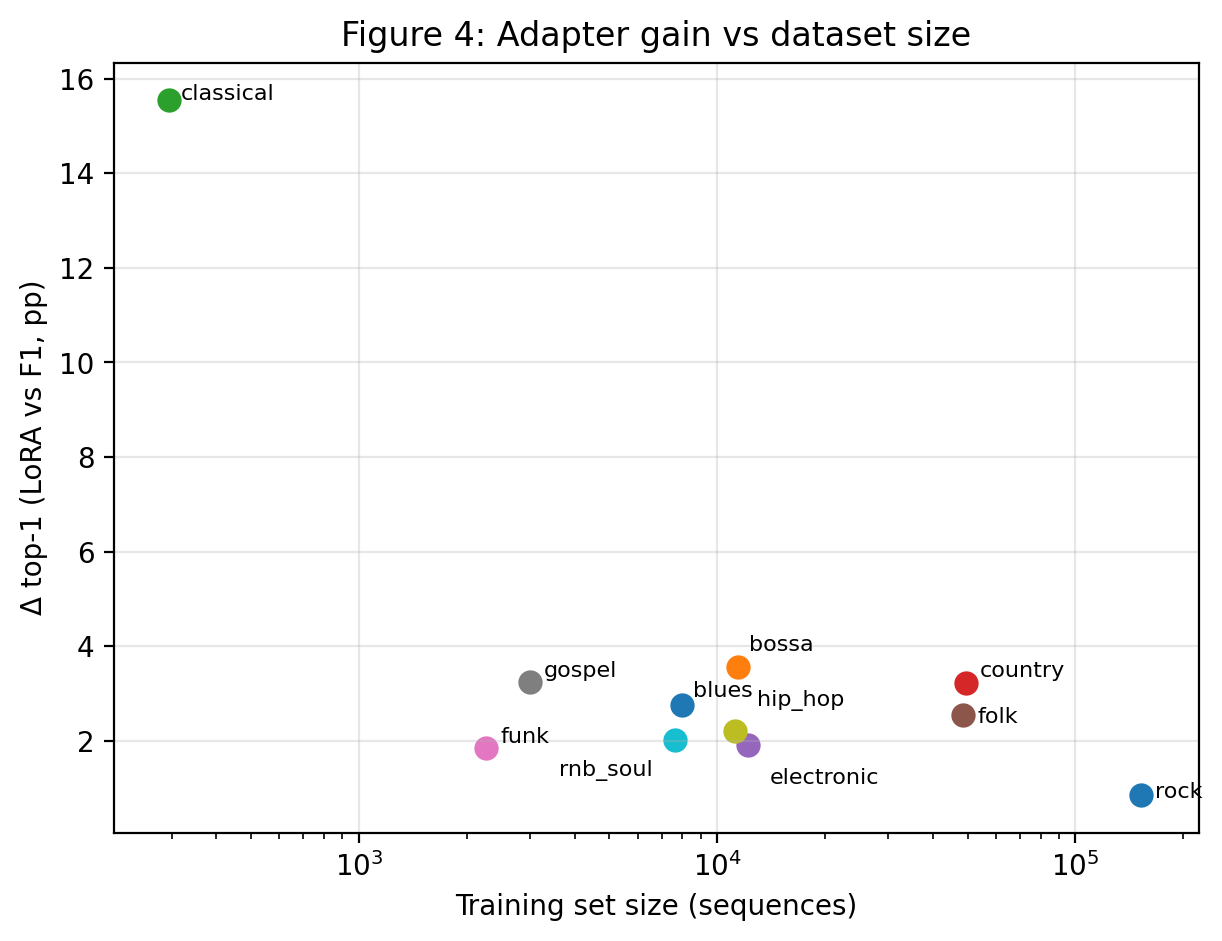
Fig 4: Per-genre LoRA gain over F1 versus training-set size.
Limitations
- Evaluation is purely automatic next-token prediction accuracy, not human perceptual or musical quality assessment.
- High training-test 4-gram near-duplication implies limited novelty/generalization; results reflect held-out distribution prediction within repetitive datasets rather than open-ended generation.
- Coarse genre labels conflate substyles and transcription practices, especially in diverse sets like 'rock' and 'country'; Bach chorales treated as tonal outlier rather than typical genre.
- Chord-symbol sequences omit key musical layers integral to perceived genre identity including rhythm, voicing, instrumentation, timbre, performance practice, and production.
- Adaptation benefits may reflect generic corpus training effects, as indicated by strong wrong-genre adaptation performance.
- Base model choice (pop-jazz mix) affects harmonic richness but not accuracy; other bases and multimodal inputs were not explored.
- Generative evaluation reveals some post-adaptation decoding artifacts such as premature sequence termination, indicating top-1 accuracy is an imperfect proxy for generation quality.
Open questions / follow-ons
- How well do chord-symbol genre adaptations correspond to perceived genre authenticity and musical quality as judged by human listeners or musicians?
- Can stricter train-test splits (e.g., novel progression or family splits with low overlap) validate whether adaptation gains represent genuine generalization rather than memorization of repetitive patterns?
- What is the impact of adding other musical modalities (rhythm, voicing, instrumentation, timbre) alongside chords on genre identity modeling and control?
- Could non-neural baselines (such as genre-conditioned n-gram or Markov chord models) help disentangle neural adaptation improvements from local transition dependencies?
Why it matters for bot defense
For bot-defense or CAPTCHAs that rely on analyzing or generating symbolic time series with style or pattern constraints, this work provides a detailed example of assessing the representational boundaries of a compact symbolic sequence (chord symbols) for class or style identity. The methodology highlights that even strong next-token predictive improvements via small parameter-efficient adaptation modules do not guarantee full semantic or stylistic discrimination of complex classes like musical genres. Similarly, in CAPTCHA or bot-detection scenarios, simple sequence-level features may carry partial but limited identity signals. The finding that lightweight conditioning (control tokens) can rival more complex adapters suggests that subtle conditioning signals may suffice to shift model behavior, a factor to consider when designing robust challenge-response tasks. Finally, the emphasis on multiple diagnostics and controlled data regimes serves as a best practice for evaluating whether model improvements genuinely reflect class-specific knowledge or just generic corpus adaptation, which is important when validating security-critical pattern classifiers.
Cite
@article{arxiv2606_07334,
title={ How Far Can Chord-Symbol Time-Series Adaptation Carry Genre Identity? Capabilities and Boundaries in Multi-Genre Chord-Symbol Modeling },
author={ Jinju Lee },
journal={arXiv preprint arXiv:2606.07334},
year={ 2026 },
url={https://arxiv.org/abs/2606.07334}
}