
Bradley-Terry Rankings for Recommender Systems Across Dataset Taxonomies
Source: arXiv:2606.07492 · Published 2026-06-05 · By Ekaterina Grishina, Stepan Kuznetsov, Askar Tsyganov, Ilya Ivanov, Daria Korovaitceva, Margarita Rusanova et al.
TL;DR
This paper addresses the challenging problem of ranking recommendation algorithms fairly and robustly across diverse datasets that differ in characteristics such as sparsity, sequentiality, and scale. Traditional aggregation methods that average metrics like NDCG across datasets often produce misleading or unstable rankings because they do not account for dataset diversity or the relative strengths of algorithms against different opponents. To overcome this, the authors propose a probabilistic ranking methodology based on the Bradley-Terry (BT) model and its extensions, which models pairwise comparisons between algorithms on each dataset as a tournament to infer latent ability scores. They conduct a benchmark study involving 14 algorithms across 89 public recommendation datasets to demonstrate the effectiveness of the BT-based ranking framework. They introduce a novel metric—ratio of transitive triplets—to evaluate ranking consistency and show BT rankings are more stable and robust to missing comparison data than simple aggregation baselines. Furthermore, by incorporating dataset-specific covariates and BT trees, they enable prediction of algorithm rankings on new, unseen datasets without requiring costly model training and evaluation on those datasets. Results reveal that algorithm rankings vary substantially with dataset properties, motivating dataset-aware selection in practice.
Key findings
- Bradley-Terry (BT) rankings achieve a higher ratio of transitive triplets (up to 0.631 including ties) compared to mean (0.613) and sum (0.613) aggregation baselines on NDCG@10 metrics across all datasets.
- BT and Plackett-Luce (PL) models show substantially more robustness to missing pairwise comparison data, maintaining stable transitive triplet ratios as missing data proportion increases, unlike mean/sum aggregation methods where triplet ratio drops rapidly.
- Bayesian Bradley-Terry models provide uncertainty-aware ranking with confidence intervals for algorithm abilities, facilitating better interpretability than classical maximum likelihood BT or rank centrality methods.
- Algorithm rankings depend strongly on dataset characteristics: sequential datasets favor SASRec and GASATF (positions 1 and 2), while non-sequential datasets favor traditional matrix factorization and graph models such as ALS and UltraGCN.
- User interaction history length alters ranking: 'long history' datasets rank Seq-KNN and GASATF top, while 'short history' datasets promote LightGCN as best-performing.
- Simple aggregation methods (mean, sum of metrics) produce rankings differing by 3-4 rank positions compared to BT, especially misranking algorithms like BPR and EASEr, due to ignoring opponent strength.
- Shuffling timestamps in sequential datasets reduces BT weights and rank separation of sequential models like SASRec, validating BT's sensitivity to temporal data structure.
- BT tree models with covariates enable predicting rankings on unseen datasets using dataset meta-features, bypassing costly algorithm retraining.
Threat model
n/a — This is a benchmarking and evaluation methodology paper without an explicit adversarial threat model. The focus is on modeling pairwise performance comparisons across datasets rather than robustness against malicious attacks or data poisoning.
Methodology — deep read
The authors propose using the Bradley-Terry (BT) probabilistic model to rank recommender algorithms via pairwise comparisons. The threat model is not adversarial but assumes that recommender evaluation metrics vary across datasets with distinct properties such as sparsity, sequence structure, scale, etc. The goal is to build a fair and interpretable ranking methodology that aggregates results from heterogeneous datasets. Data provenance includes 89 benchmark recommendation datasets, mostly from the APS benchmark repository, filtered with a 5-core scheme. The datasets were grouped by key statistics: density, user-item ratio, average user interactions, and sequentiality measured via 2-gram statistics. The recommended algorithms include 14 diverse baselines: non-personalized heuristics (Random, PopRandom), neighborhood models (User-KNN, Item-KNN, Seq-KNN), matrix factorization and linear models (ALS, BPR, SGD MF, PureSVD, EASEr), graph-based models (LightGCN, UltraGCN), and sequential deep models (SASRec, GASATF).
Evaluation employed the global temporal split protocol with 90/5/5 train/validation/test splits based on timestamps or randomized timestamps if missing, and standard last-item validation and random-item test targets. Each algorithm was hyperparameter-optimized using Optuna’s TPE with 200 trials maximizing NDCG@10 on validation, then retrained on train+val; test metrics were gathered across 10 seeds.
Pairwise comparisons were created from ranking algorithm performance on each dataset by NDCG@10, with ties defined where metric ± std intervals overlapped by adding 0.5 to wins for both algorithms in BT matrix W. BT model parameters p_i represent algorithm strengths estimated by maximum likelihood iterations (Zermelo’s method) or Bayesian MCMC (Metropolis-Hastings) to quantify posterior uncertainty, implemented for confidence intervals. Extensions include covariate-adjusted BT and BT trees that partition datasets by meta-features to model heterogeneous preferences.
Ranking quality was measured by a novel "transitive triplets" metric: the ratio of transitive triplets (algorithm triples consistent in pairwise wins) to all possible triples, sensitive to missing data better than Kendall’s tau or Spearman’s rho correlations. Robustness was tested by randomly deleting entries in W to simulate incomplete data.
Experiments compared BT rankings with simple aggregated baselines (mean, sum), Plackett-Luce model rankings, and investigated how rankings varied across dataset groups (sparse vs dense, short vs long user history, sequential vs non-sequential). The effects of timestamp shuffling on sequential dataset rankings, and use of covariates for predicting rankings on unseen datasets via BT tree models were also explored.
The methodology is reproducible with all code and benchmark data publicly released, including implementation details of models and hyperparameter search spaces. The Bayesian BT approach was preferred for its confidence intervals, although classical methods converge to similar point estimates in this data-rich setup. Overall, the paper presents a comprehensive empirical pipeline for rigorous and interpretable recommendation algorithm ranking across heterogeneous data contexts.
Technical innovations
- Introduction of a Bradley-Terry-based ranking framework for recommender systems benchmarked on a large and diverse dataset collection.
- Development of the 'transitive triplets' metric to robustly evaluate ranking consistency under missing and tied comparisons.
- Demonstration that rankings vary significantly with dataset meta-characteristics and proposal of BT tree and covariate-adjusted BT models to predict rankings on unseen datasets without rerunning algorithms.
- Comprehensive empirical benchmark showing BT-based rankings have better stability and interpretability than simple aggregation or Plackett-Luce models.
Datasets
- APS benchmark set — 89 datasets — public benchmark repository and additional public datasets.
Baselines vs proposed
- Mean aggregation: ratio of transitive triplets = 0.613 (with ties) vs BT model = 0.631 (with ties)
- Sum aggregation: ratio of transitive triplets = 0.613 (with ties) vs BT model = 0.631 (with ties)
- BT model vs PL model: rankings highly concordant overall but differ more on datasets with long user histories
- BT ranking of BPR differs by 4 ranks compared to sum aggregation (6 vs 10), EASEr differs by 3 ranks compared to sum aggregation on non-sequential datasets
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.07492.
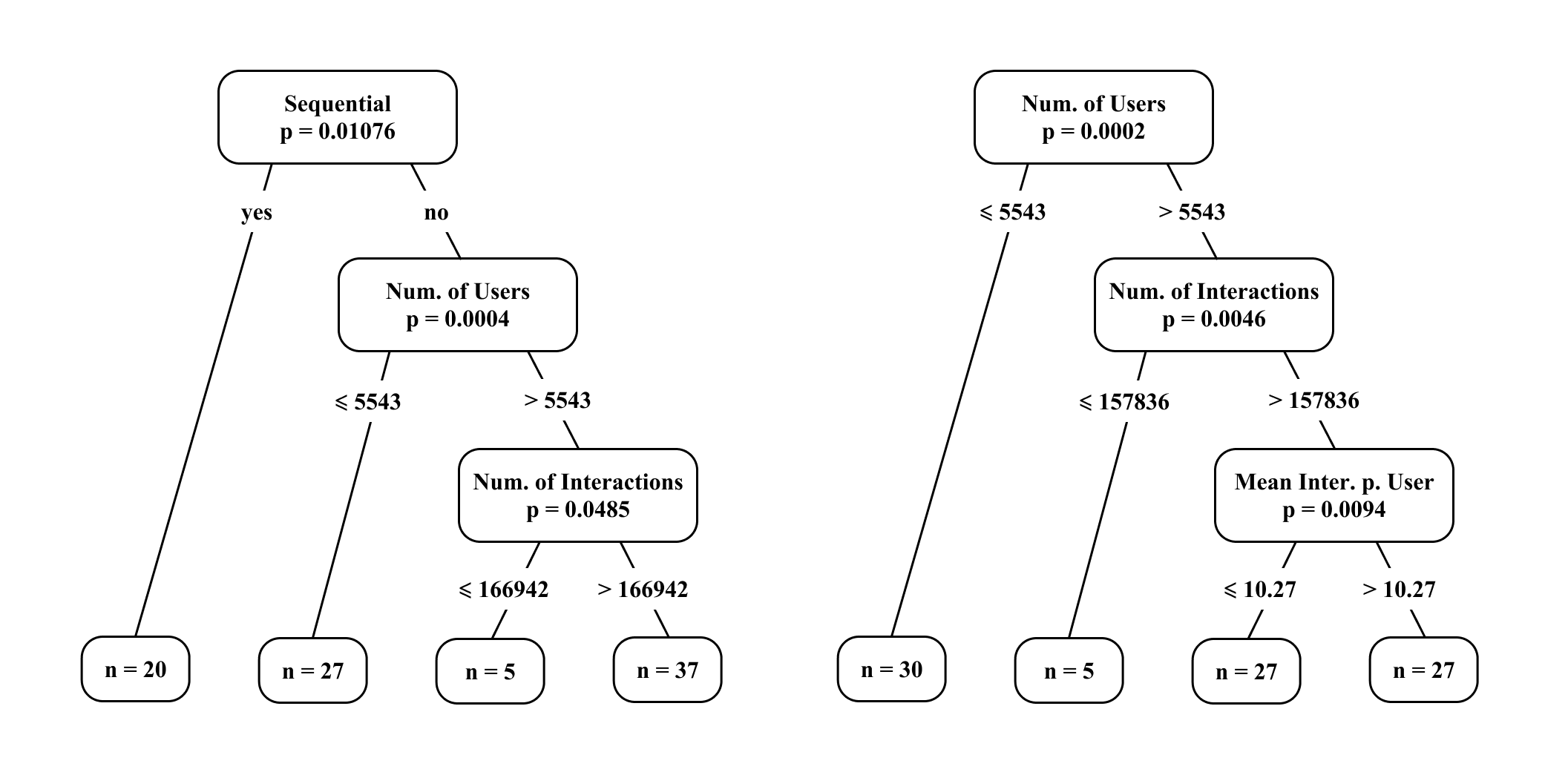
Fig 6: BT trees for datasets. Each node displays the split
Limitations
- No adversarial evaluation; applicability assumes honest benchmarking data without strategic manipulation.
- Covariate-adjusted BT models depend on quality and completeness of dataset meta-features; may degrade with incomplete or noisy metadata.
- Empirical results predominantly cover standard public datasets; performance on proprietary or emerging domains not validated.
- Ranking quality validation focuses on NDCG@10 metric; other recommendation quality measures may yield different results.
- Computational expense prohibits full hyperparameter tuning exhaustiveness for some algorithms on largest datasets.
- Sequentiality measured by 2-gram statistics; may not fully capture complex temporal dynamics affecting ranking.
Open questions / follow-ons
- How well do covariate-adjusted BT models generalize to recommending algorithms in evolving or out-of-domain datasets?
- Can the transitive triplets metric be extended or adapted to incorporate more nuanced tie or uncertainty treatment?
- How might BT-based ranking interact with advanced uncertainty quantification or Bayesian model averaging methods for algorithm evaluation?
- What is the impact of alternative dataset meta-features or higher-order dataset taxonomies on the precision of BT tree-based predictions?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this paper offers a rigorous statistical framework for ranking algorithms across datasets whose characteristics may vary widely. While the domain is recommender systems, the core insight—that naive metric aggregation can mislead ranking due to dataset heterogeneity—applies broadly to bot defense benchmarking as well. The Bradley-Terry model and its extensions provide a principled approach to aggregating pairwise algorithm comparisons that account for opponent strengths and dataset features, enhancing ranking robustness especially when benchmark data is incomplete or heterogeneous.
In practice, CAPTCHA and bot detection solutions are often evaluated on diverse datasets with varying bot behaviors and traffic patterns. Applying Bradley-Terry based ranking can help identify which defenses perform best across different operational scenarios rather than just on average. Further, covariate-adjusted BT models allow predicting defense effectiveness on new datasets given only metadata, reducing costly re-evaluations. The transitive triplets metric also gives a practical tool for assessing stability and consistency of algorithm rankings in the face of missing or noisy evaluation data. Thus, bot-defense researchers should consider this methodology to improve fairness, interpretability, and robustness in benchmarking CAPTCHA and bot detection algorithms.
Cite
@article{arxiv2606_07492,
title={ Bradley-Terry Rankings for Recommender Systems Across Dataset Taxonomies },
author={ Ekaterina Grishina and Stepan Kuznetsov and Askar Tsyganov and Ilya Ivanov and Daria Korovaitceva and Margarita Rusanova and Uliana Parkina and Alexander Derevyagin and Evgeny Frolov and Sergey Samsonov and Anton Lysenko },
journal={arXiv preprint arXiv:2606.07492},
year={ 2026 },
url={https://arxiv.org/abs/2606.07492}
}