
Affordance-Based Hierarchical Reinforcement Learning for Quadruped Pedipulation
Source: arXiv:2606.07506 · Published 2026-06-05 · By Tuba Girgin, Jose Castelblanco, Gabriel Rodriguez, Emre Girgin, Cagri Kilic
TL;DR
This paper tackles the challenge of enabling autonomous object manipulation by quadruped robots in unstructured environments without expert-designed high-level trajectories. Prior work often focuses on low-level manipulation or requires manual guidance for task execution. The authors propose a novel three-level hierarchical reinforcement learning (RL) framework that explicitly leverages pose affordances—object- and terrain-aware features—to autonomously select feasible base robot poses and interaction points on objects for pedipulation, or leg-based manipulation. The framework integrates a vision-based affordance module for goal pose generation, a high-level navigation policy commanding locomotion, and a low-level pedipulation policy controlling end-effector joint positions. Training occurs in IsaacSim with domain randomization and sim-to-real transfer is demonstrated on a Unitree GO2 quadruped robot in outdoor environments on varied terrain with random obstacles.
Key findings include that the affordance-guided pose selection yields more efficient object interaction—quantified as displacement per applied force—versus baseline strategies lacking affordance reasoning. Moreover, selecting interaction points closest to the robot's end effector outperforms other surface contact selections. The method successfully transfers to real-world settings, autonomously generating navigation goals and pedipulation trajectories without human demonstrations. The authors also release a new object interaction dataset containing multi-modal robot telemetry and force feedback, enabling further research in open-world quadruped pedipulation.
Overall, this study advances quadruped manipulation by explicitly incorporating pose affordances into hierarchical RL for end-to-end autonomous pedipulation, significantly reducing reliance on expert intervention and enabling robust open-world operation.
Key findings
- The hierarchical framework autonomously identifies affordance-based robot base poses, enabling navigation and pedipulation without pre-designed trajectories.
- Selecting the surface contact point on the object closest to the robot's end effector yields the highest manipulation efficiency, with a mean efficiency of 0.4894 m/N compared to 0.2738 m/N when selecting points closest to the base and 0.2103 m/N for no explicit surface point selection (Fig 4, Table II).
- The system achieves stable pedipulation on sloped and uneven terrain by integrating terrain slope into affordance reasoning to generate feasible robot headings.
- Sim-to-real transfer is demonstrated by evaluation on a Unitree GO2 quadruped interacting with randomly positioned objects on outdoor terrain, validating the trained policies from simulation.
- Multi-modal data collection during navigation and pedipulation forms an open-world object interaction dataset providing joint positions, force feedback, target poses, and object features.
- Domain randomization of robot base mass, center of mass, and external disturbances during training improves policy robustness to real-world uncertainties.
- The pedipulation policy's reward combines end-effector position tracking and penalties on excessive velocities, accelerations, and joint torques, driving smooth, stable manipulation.
- The navigation policy receives afforded goal poses incorporating object geometry and terrain but does not rely on dynamic obstacle updates, assuming static targets.
Methodology — deep read
The authors develop a hierarchical reinforcement learning approach composed of three policy levels: navigation, locomotion, and pedipulation. Each task is modeled as a Markov Decision Process (MDP) with tailored observation and action spaces.
Threat Model & Assumptions: The adversary model is not explicitly defined as this is primarily a robotics manipulation contribution rather than security-focused. The environment assumes static obstacles and no dynamic adversarial interference. Sensors like LiDAR are used to generate point clouds for vision-based affordance analysis.
Data: Training and evaluation data are collected in the Isaac Sim environment using a Unitree GO2 quadruped model and various randomly oriented rock-shaped obstacles placed on sloped terrain. Domain randomization includes mass and center of mass variations as well as random external forces and perturbations to improve sim-to-real generalization. A real-world dataset of object interactions is collected during robot trials, which includes multi-modal telemetry, force feedback, and object point cloud features.
Architecture / Algorithm:
- The highest level is a vision-based pose affordance module that processes LiDAR-derived point clouds for terrain segmentation and object geometry estimation. It extracts affordance features to compute feasible robot base poses relative to the object and terrain slope.
- The navigation policy receives as observations the affordance-generated goal base pose, robot velocity, and gravity vector, outputting 3-DoF velocity commands that guide the locomotion policy.
- The locomotion policy outputs joint position commands for the quadruped legs conditioned on commanded velocities.
- The pedipulation policy receives a target end-effector trajectory defined by cubic spline interpolation between a home position and affordance-defined interaction points on the object surface.
- Each policy is an actor-critic network with three fully connected layers (128 units, ELU activation), trained using Proximal Policy Optimization (PPO).
The affordance pose generation algorithm composes transforms based on the object center, desired end-effector position, and robot pose to create navigation goals considering reachable end-effector workspace and local terrain slope.
Training Regime: All policies train for 4000 epochs in Isaac Sim with PPO hyperparameters including learning rate 1e-3 (adaptive), discount factor 0.99, GAE 0.95, batch size 4 minibatches per epoch, and adaptive entropy regularization. Domain randomization is included during training to improve robustness. Pedipulation target poses are uniformly sampled within reachable ranges around the right (or left) front leg.
Evaluation Protocol: The main evaluation sets consist of 225 simulated experiments testing the effect of navigation heading on object displacement and force applied (object relocation efficiency). Additionally, 150 simulations test three pedipulation point selection strategies: closest to end effector, closest to base, and object center, comparing efficiency. Real-world experiments deploy the final system on a GO2 robot in outdoor environments with varying terrain slopes and random rock obstacles. Performance metrics include contact forces, object displacement, and relocation efficiency. Qualitative comparisons and sim-to-real transfer are demonstrated.
Reproducibility: Policies were trained using PPO within Isaac Sim; however, code, trained weights, and datasets are not explicitly stated to be released. Due to reliance on the GO2 robot platform and custom state estimation and perception modules, full replication would require access to these components. The object interaction dataset collected during real-world experiments is claimed but no download link is provided in the paper details.
For a concrete example: Given a target object detected via LiDAR, the affordance module segments terrain and object surface, computes a feasible robot base pose aligned with reachable object interaction points considering terrain slope, then sends this goal pose to the navigation policy. The navigation policy generates velocity commands to drive the locomotion controller towards that base pose. Upon arrival within a threshold, the pedipulation module generates a cubic spline end-effector trajectory starting from a home position to the affordance-determined interaction point and back. The pedipulation policy outputs joint commands to follow this path and manipulate the object, with onboard force sensors providing feedback on interaction success.
Technical innovations
- A three-level hierarchical RL framework integrating affordance-based pose generation with navigation, locomotion, and pedipulation policies enabling fully autonomous quadruped object manipulation.
- Application of vision-based pose affordance estimation combining LiDAR point cloud segmentation and terrain slope analysis to autonomously generate feasible base poses and end-effector interaction points.
- Cubic spline-based trajectory generation for end-effector waypoints conditioned on affordance-derived contact points, enabling smooth pedipulation motions.
- Sim-to-real transfer of affordance-guided hierarchical RL policies demonstrated on real quadruped robots interacting with previously unseen objects on uneven, sloped terrain.
Datasets
- Object-Interaction Dataset — size not explicitly stated — collected from real-world quadruped pedipulation deployments, includes robot telemetry, force feedback, ground truth object features
Baselines vs proposed
- Closest surface point to end effector: mean efficiency = 0.4894 m/N
- Closest surface point to base: mean efficiency = 0.2738 m/N
- No explicit surface point selection (geometric center): mean efficiency = 0.2103 m/N
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.07506.
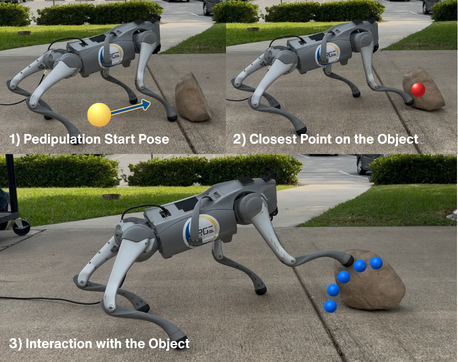
Fig 1: Pedipulation of the target object. After reaching the goal base pose
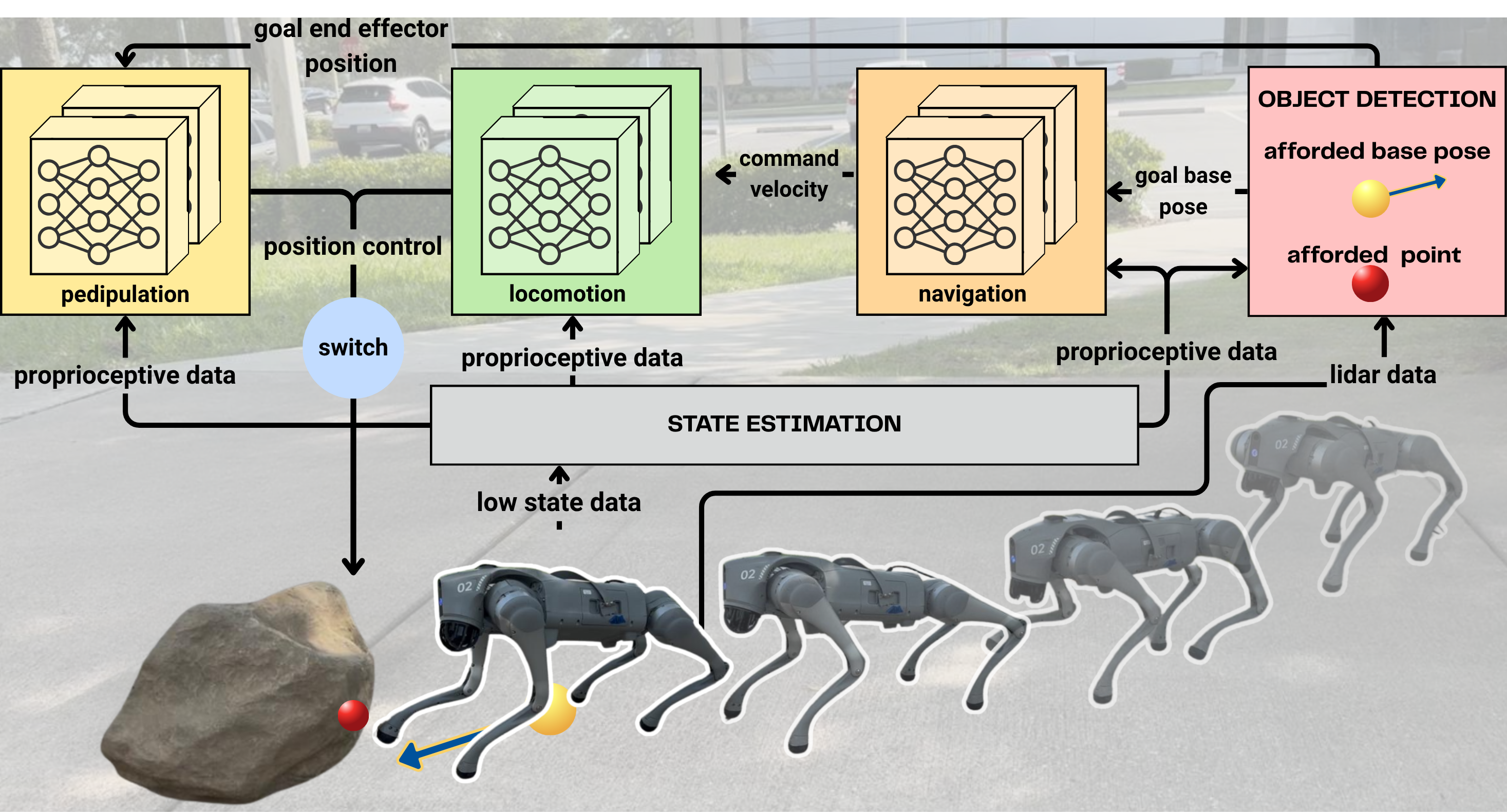
Fig 2: An illustration of the three-level hierarchical reinforcement learning framework. Our vision-based robot pose affordance model processes the point

Fig 3: Still frames of the execution of the pedipulation operation in both simulation (first row) and real-world outdoor experiments (second row). Similar
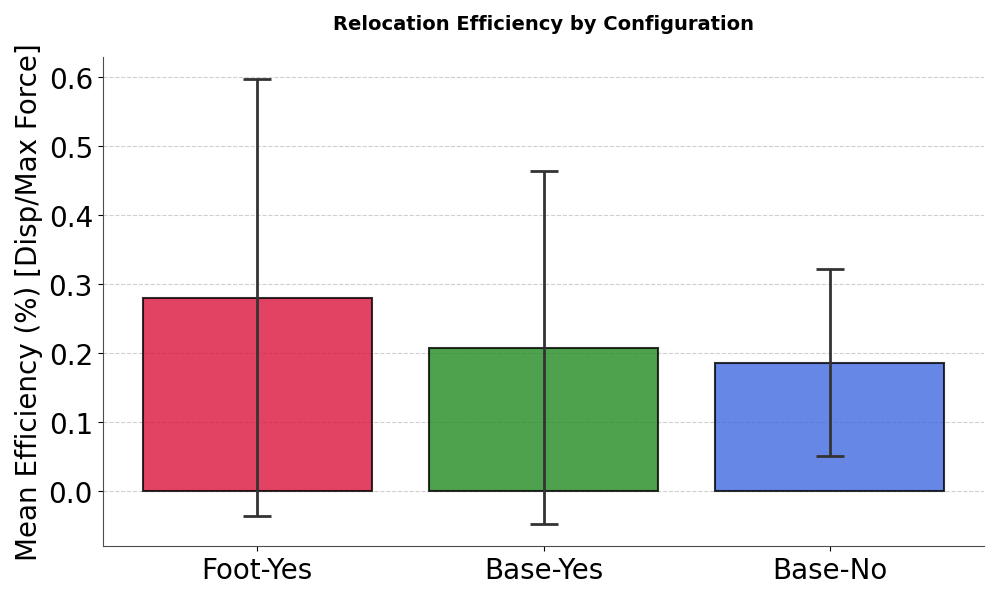
Fig 4: Mean relocation efficiency across three interaction point selections

Fig 5: Real-world execution of the proposed system in open environments with varying surface slopes. First, the vision-guided pose affordance module
Limitations
- The system assumes static objects and terrain with no dynamic obstacles, limiting applicability in cluttered or dynamic environments.
- No explicit adversarial robustness or failure mode analysis under sensor noise beyond domain randomization is presented.
- Evaluation primarily on single-object interaction tasks; multi-object or complex manipulation sequences remain unexplored.
- The object interaction dataset size and detailed statistics are not provided, limiting reproducibility.
- State estimation and perception modules rely on specialized sensor fusion and LiDAR setups, which may not generalize across platforms.
- No comparison with learning methods incorporating human demonstrations or alternative end-effector control strategies was reported.
Open questions / follow-ons
- Can the affordance-based hierarchical RL framework generalize to dynamic or multi-object manipulation scenarios with cluttered environments?
- How robust is the system under more challenging real-world perception noise, partial occlusions, or varying lighting conditions affecting point cloud quality?
- Would incorporating force- or tactile-based affordance estimation further improve interaction success rates and policy robustness?
- Can the approach be extended to simultaneous multi-limb coordination for more complex whole-body manipulation tasks?
Why it matters for bot defense
Although the paper is focused on autonomous quadruped manipulation, the principle of affordance-based hierarchical decision making is relevant for distributed and modular bot-defense systems that require layered policy control. The vision-based affordance extraction from sensor data parallels challenges in robust environment understanding, which is key in bot-detection and CAPTCHA systems reliant on 3D scene or gesture analysis. The hierarchical RL approach, decomposing high-level intent, navigation, and fine-grained action execution, mirrors multi-stage analysis in bot-defenses where coarse filtering feeds finer interaction models. However, this paper does not address adversarial threat models or mimicry attacks, which are crucial in bot-defense. Bot-defense engineers may find inspiration in the affordance-driven autonomous pose and interaction selection concepts for dynamic challenge generation and resilient interaction sequencing in CAPTCHA designs, but direct application would require adaptations for adversarial contexts and user interaction constraints.
Cite
@article{arxiv2606_07506,
title={ Affordance-Based Hierarchical Reinforcement Learning for Quadruped Pedipulation },
author={ Tuba Girgin and Jose Castelblanco and Gabriel Rodriguez and Emre Girgin and Cagri Kilic },
journal={arXiv preprint arXiv:2606.07506},
year={ 2026 },
url={https://arxiv.org/abs/2606.07506}
}