
Adversarial Creation and Detection of AI-Generated Social Bot Content
Source: arXiv:2606.07219 · Published 2026-06-05 · By Mykola Trokhymovych, Ricardo Baeza-Yates, Alessandro Flammini, Diego Saez-Trumper, Filippo Menczer
TL;DR
This paper addresses the challenge of detecting AI-generated social media content produced by AI-powered social bots that impersonate real users. Prior work suffers from limited realistic training data and poor generalization, particularly for short, multilingual social media posts. To overcome this, the authors propose an adversarial data generation pipeline that conditions large language model outputs on detailed user personas, conversation context, and multilingual data from Reddit and Telegram. This approach yields a large-scale, multilingual, paired dataset of human and AI-generated messages. Using this data they train content-based classifiers that significantly outperform prior state-of-the-art detectors, especially on real-world, out-of-distribution benchmarks such as Fox8-23. The best transformer-based classifier achieves nearly 0.97 AUC at the user-level detection task on Fox8-23, showing strong robustness and generalization compared to prior datasets and methods. They also provide extensive sensitivity analyses across text length, platform, language, conversational context, and generation model size. Their adversarial, context-aware dataset construction represents a major advance in realistic training data, enabling substantially improved detection of AI-generated social bot content. The study demonstrates the importance of modeling user-specific nuances and conversation context for robust bot detection in modern multilingual social media scenarios.
Key findings
- Created a paired dataset with 263,594 human-AI message pairs across 17 languages, 6,326 users, 36 channels from Reddit and Telegram.
- Transformer classifiers trained on the adversarial data achieve up to 0.969 AUC for AI-generated text detection on the test set and 0.972 AUC user-level detection on out-of-distribution Fox8-23 benchmark.
- Training on datasets without adversarial/user-context modeling (MultiSocial, AIGT, OSM-Det) shows large accuracy drops on Fox8-23 (down to ~0.58 AUC) versus models trained on this paper’s data (~0.97 AUC).
- Detection accuracy increases with message length, improving up to about 7.5% AUC for texts >150 characters.
- Conversational context during message generation decreases detectability; models trained on context-aware data remain robust but lower by 3-5% AUC.
- Smaller generation LLMs produce easier-to-detect messages; detection AUC drops when trained/tested on content from larger LLMs like Qwen-235B.
- Cross-lingual evaluation shows high detection accuracy across 17 languages except Chinese, highlighting good multilingual capability.
- User-level classification (averaging multiple posts) yields higher AUC (up to 0.990) than message-level classification (around 0.969), underscoring importance of history aggregation.
Threat model
The adversary is a malicious social media actor who controls or impersonates social media accounts using large open-weight or commercial large language models to generate realistic human-like posts. They have access to the target user’s public historical messages and conversation threads, enabling sophisticated conditioned generation to evade detection. They do not have unlimited computational resources—thus the generation methods prioritize scalability and simplicity rather than costly fine-tuning or multi-modal attacks. The defender relies solely on content analysis without auxiliary metadata or network-based features to detect AI-generated bot content.
Methodology — deep read
The authors start by defining a threat model where malicious actors use large open-source or commercial LLMs to impersonate real social media users and generate realistic human-like posts, aiming to evade detection. The defender seeks to detect whether content is AI-generated purely using content analysis, without relying on metadata or network features.
They collect a large multilingual dataset from Reddit and Telegram, covering 17 languages and various subreddits/channels. Reddit data comes from pre-2018 posts using ConvoKit, selected to include English and non-English communities. Telegram chats chosen are large public channels in politics/news with full chat histories exported. They sample users with at least 15 threads to enable persona modeling.
The key novel methodology is an adversarial AI-text generation pipeline to produce AI-generated message pairs closely mimicking real user posts. Each user's historical messages are split into training and test sets (by timestamp). The training threads for each user are sampled (up to 10) to prompt an LLM (openai/gpt-oss-20b) to generate a structured user persona including languages used and sentiment-based topics. Conversation context is retrieved by embedding and nearest neighbor search of similar threads, which the LLM uses to generate more contextually appropriate responses. They generate AI responses for the user's messages in the test threads using two instruction-tuned LLMs (Gemma-3n-8B and Qwen3-235B), with and without context.
Generated texts are post-processed to remove obvious artifacts and filtered for language mismatch. Sampling is user-level train-test split to avoid leakage. This results in 263,594 paired human-AI messages from 6,326 users.
For detection, they evaluate zero-shot training-free detectors (Binoculars, FastDetectGPT, and GECScore) adapted to multilingual settings using updated models and prompts, alongside supervised training-based classifiers: a linguistic feature classifier (LFC, gradient boosting on handcrafted LM features) and transformer classifiers (fine-tuned multilingual mBERT, XLM-RoBERTa, Gemma 3 1B).
They optimize hyperparameters on a 5% validation split and evaluate on held-out test sets and the out-of-distribution Fox8-23 dataset of real Twitter AI bots. The metric is ROC-AUC for binary classification of human vs AI-generated messages and user-level classification by aggregating message scores.
They conduct extensive sensitivity analyses by stratifying results by text length, platform, language, the LLM generation model, and the presence of conversational context during generation.
No frozen weights or code repositories are explicitly stated publicly. Some external datasets (MultiSocial, Fox8-23) are used for benchmarks. The pipeline emphasizes scalability and realism over fine-tuned, high-cost impersonation models.
Example: For one user, their historical Reddit messages are used to generate a persona summary describing their language use and topic preferences via GPT-OSS-20b. Similar prior conversations are retrieved via embedding similarity. Using these, the Gemma-3n-8B model is prompted to generate a realistic reply in a held-out conversation thread matching the user's style and stance. This generates a paired AI message for comparison with the real user message for classifier training.
Technical innovations
- A novel adversarial data generation pipeline that conditions LLM text generation on detailed user personas, conversation context, and messaging history to mimic real social media users.
- Creation of a large-scale, multilingual, cross-platform paired dataset of human and AI-generated social media messages covering 17 languages and two platforms (Reddit and Telegram).
- Comprehensive evaluation of multiple zero-shot and supervised detection models, demonstrating the critical value of the adversarial context-aware dataset for improving out-of-distribution generalization.
- Detailed sensitivity analyses showing how conversational context in generation, text length, generation model size, and language affect detection accuracy, highlighting concrete directions to improve robustness.
Datasets
- Multilingual Reddit-Telegram paired dataset — 263,594 message pairs — collected and generated by authors (not publicly released)
- Fox8-23 — real-world Twitter dataset with AI-powered bot users — used as out-of-distribution test benchmark
- MultiSocial — prior multilingual, multi-platform AI text dataset — public
- AIGTBench — English-only dataset of AI-generated text from social media and publishing — public
- OSM-Det training data — English AI text dataset — prior work
Baselines vs proposed
- GEC score: AUC 0.646 (our data test) vs 0.593 (Fox8-23) vs proposed TC (RoBERTa): 0.969 (our data) and 0.972 (Fox8-23)
- Binocular: AUC 0.665 vs 0.550 on Fox8-23 vs TC (RoBERTa): 0.969 vs 0.972
- FastDetect: AUC 0.681 vs 0.543 on Fox8-23 vs TC (RoBERTa): 0.969 vs 0.972
- OSM-Det: AUC 0.603 vs 0.620 on Fox8-23 vs TC (RoBERTa): 0.969 vs 0.972
- MultiSocial-trained TC: 0.974 (MultiSocial test) but drops to 0.582 on Fox8-23 vs current TC (RoBERTa): 0.969 (current test) and 0.972 (Fox8-23)
- User-level classification achieves up to 0.990 AUC on Fox8-23 with TC (RoBERTa), compared to ~0.969 at message-level
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.07219.
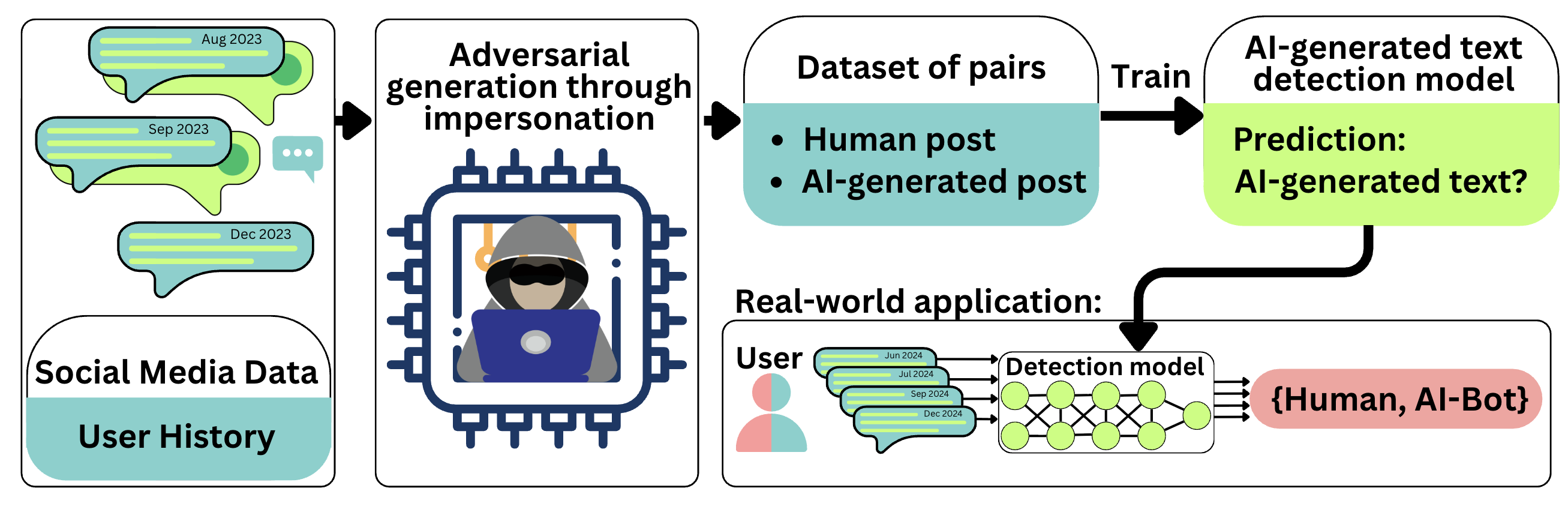
Fig 1: Pipeline for content-based detection of AI-
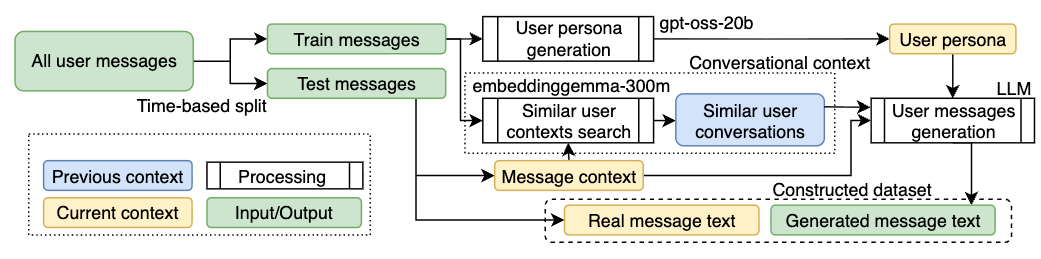
Fig 2: Diagram of dataset curation steps.
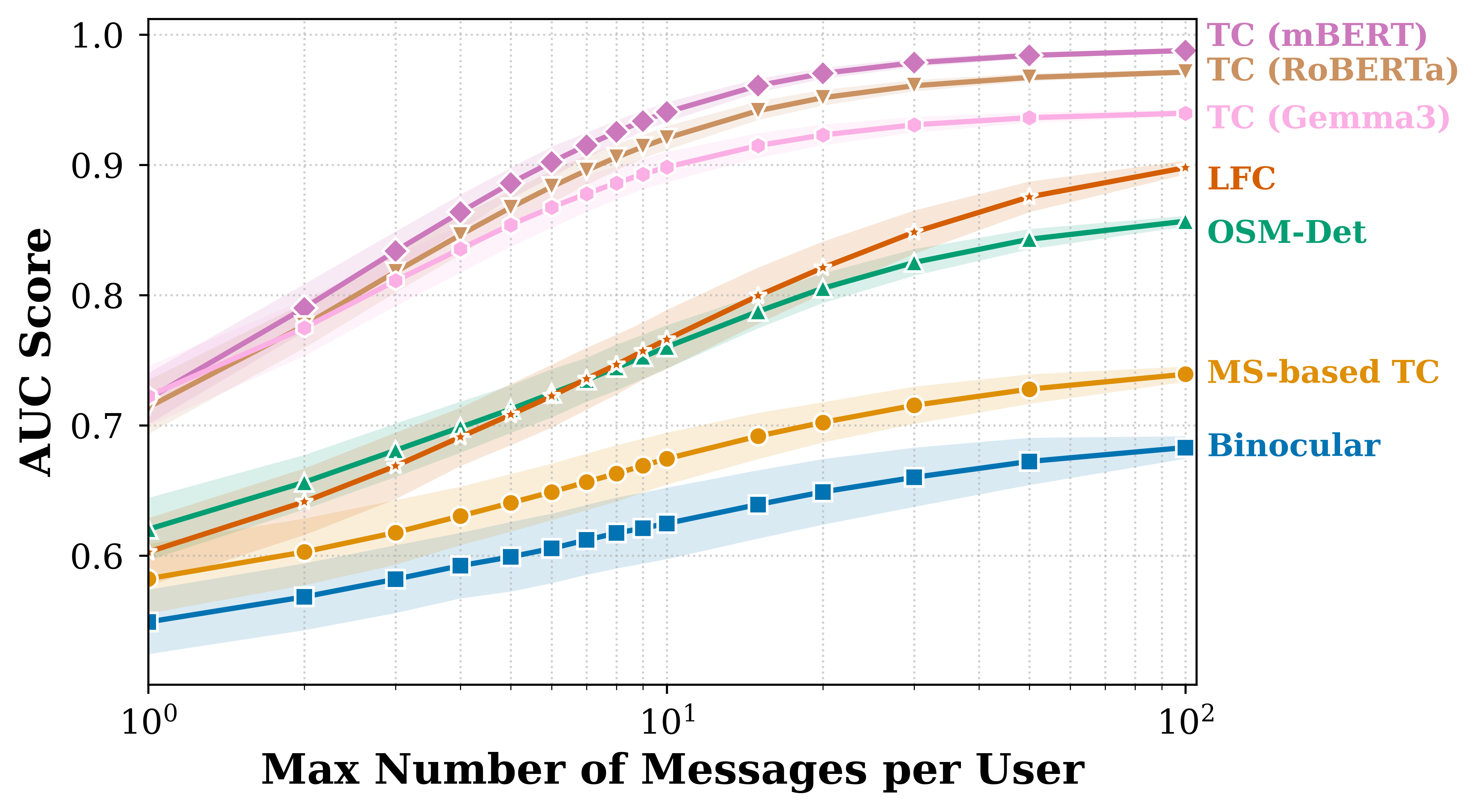
Fig 4: reports on the impact of the number
Limitations
- Data generation pipeline focuses on simplicity and scalability; more sophisticated fine-tuned impersonation models are not modeled, possibly underestimating detection difficulty.
- Human baseline data, especially from Telegram, may contain some undetected automated or bot-like content, potentially biasing results.
- Dataset covers only two platforms (Reddit and Telegram) and mostly mainstream topics like politics and news, introducing topical bias and limiting generalization to niche domains.
- Detection focuses exclusively on text content; multi-modal (images, video) and metadata signals are excluded but could enhance detection.
- Fox8-23 benchmark used for evaluation was collected before the recent AI generation sophistication peak, and contains self-revealed bots, posing a more optimistic scenario than current real-world data.
- Code and dataset release status is not clearly mentioned, which may limit reproducibility and wider adoption.
Open questions / follow-ons
- How can detection systems incorporate multi-modal signals and metadata alongside text to improve robustness against more subtle AI-powered bots?
- What approaches can effectively detect fine-tuned or personalized LLM generation that closely mimics individual user style beyond the persona/context used here?
- How do newer, more powerful LLMs with larger context windows influence detection difficulty and what adaptive training data strategies are required?
- Can adversarial generation pipelines be extended to model coordinated social bot behaviors at the network level?
Why it matters for bot defense
For bot-defense practitioners, this work highlights the critical importance of training detection systems on realistic, adversarially generated AI content that mimics genuine users at a detailed persona and conversational context level. Simple supervised training on generic or paraphrased AI data, or out-of-context synthesis, fails to generalize to real-world bot behaviors. The multilingual, cross-platform dataset and demonstrated strong gains in user-level detection accuracy suggest that incorporating context-aware content analysis is crucial for distinguishing AI-generated social bots in the wild. Captcha engineers can view these findings as complementary signals to combine with interaction metrics and behavior analysis for robust bot attribution and filtering. The sensitivity analysis results suggest that message length and language variability are important operational considerations. While not directly a captcha design paper, the adversarial data methodology and detection model evaluation provide valuable insights for improving content-based bot detectors used to gate suspicious sessions or interaction flows.
Cite
@article{arxiv2606_07219,
title={ Adversarial Creation and Detection of AI-Generated Social Bot Content },
author={ Mykola Trokhymovych and Ricardo Baeza-Yates and Alessandro Flammini and Diego Saez-Trumper and Filippo Menczer },
journal={arXiv preprint arXiv:2606.07219},
year={ 2026 },
url={https://arxiv.org/abs/2606.07219}
}