
Vortex: Efficient and Programmable Sparse Attention Serving for AI Agents
Source: arXiv:2606.06453 · Published 2026-06-04 · By Zhuoming Chen, Xinrui Zhong, Qilong Feng, Ranajoy Sadhukhan, Yang Zhou, Michael Qizhe Shieh et al.
TL;DR
Sparse attention methods have become essential for efficiently serving large language models (LLMs) with long generation lengths. However, engineering complexity and incompatibility with modern serving infrastructure hinder rapid iteration and deployment of new sparse attention algorithms. This paper introduces Vortex, a system combining a Python-embedded frontend language (vFlow) with a page-centric tensor abstraction (vTensor) and an optimized backend that integrates tightly with state-of-the-art LLM serving stacks. Vortex addresses programmability and efficiency challenges by enabling concise expression of diverse sparse attention patterns without exposing low-level memory layouts, while performing system-level optimizations such as workload planning and kernel fusion. AI agents using Vortex automatically generated and refined sparse attention algorithms that achieve up to 3.46× throughput improvement over full attention without accuracy loss. Moreover, Vortex supports emerging architectures and very large models, achieving up to 4.7× speedup on GLM-4.7-Flash and 1.37× speedup on a 229B parameter model across multi-GPU setups. Overall, Vortex bridges the gap between sparse attention research and practical serving deployments, accelerating algorithm innovation and real-world performance gains.
Key findings
- AI agents automatically generated sparse attention algorithms achieving up to 3.46× higher throughput than full attention with preserved accuracy (Section 6.1.2).
- On NVIDIA H200 SXM GPUs, Vortex improved throughput by 3.60× for block top-k and 2.98× for Quest algorithms compared to full attention, maintaining accuracy (Section 6.4.1).
- Vortex reduced P95 user latency by 11.7× for block top-k and 12.8× for Quest under 16K token prompts at 8 request rate (Section 6.4.2).
- For MLA-based GLM-4.7-Flash on NVIDIA B200, Vortex’s rope-aware sparse attention reached 4.7× throughput speedup over full attention (Section 6.2).
- On the 229B-parameter MiniMax-M2.7 model across 4 NVIDIA B200 GPUs, block top-k sparse attention outperformed full attention by 1.37× throughput with equal or better accuracy (Section 6.4).
- AI-generated sparse attention algorithms showed substantial structural diversity, with Sonnet 4.6 achieving the highest average pairwise structural distance of 0.789 (Figure 9).
- Vortex-enabled autonomous optimization loop continuously refined sparse attention parameters, improving throughput on AIME24 benchmark from ~3.4K to ~11.9K tokens/sec over 18 hours (Figure 11).
- Kernel fusion and stochastic early termination in radix top-k improved query-dependent sparse indexing efficiency (Section 5.1 and 5.2).
Threat model
The paper does not consider adversarial threats but addresses system-level bottlenecks in large language model serving pipelines, particularly memory fragmentation and inefficiency due to paged KV cache layouts which act as performance bottlenecks rather than a security adversary.
Methodology — deep read
Threat Model & Assumptions: The paper focuses on reducing inference latency and throughput bottlenecks in serving large language models during decoding, particularly addressing KV cache management and sparse attention deployment challenges. The 'adversary' here is analogous to the system bottleneck, i.e., memory fragmentation and inefficiency in paged KV lookups, not a hostile attacker. The goal is to design a programmable system that efficiently expresses and executes sparse attention algorithms on heterogeneous memory layouts compatible with modern serving.
Data: Benchmarks include several public and proprietary datasets: AMC23, AIME24, and RULER for evaluating accuracy and throughput of sparse attention algorithms during generation with Qwen3-1.7B model. Data splits or sizes are not deeply detailed but include generation sequences up to 16K tokens. Large models tested include GLM-4.7-Flash and a 229B-parameter MiniMax-M2.7 model on NVIDIA B200 GPUs.
Architecture / Algorithm:
- Frontend: vFlow, a Python-embedded domain-specific language exposing a single-request tensor abstraction (batch size 1 view) with modular primitives (GeMM, Softmax, Top-K, Gather, Reduce).
- Core abstraction: vTensor, extends PyTorch tensors by wrapping underlying data with layout metadata (batch size, index pointers, ragged page indices), enabling transparent execution over non-contiguous paged KV cache memory.
- Compilation: vFlow programs are compiled to sequences of vTensor operators preserving layout without unnecessary data rearrangement.
- Execution Backend: Integrates with existing optimized attention backends (flashinfer, trtllm_mha, trtllm_mla), plus a custom cuda_mla decode kernel extending vendor MLA kernel capabilities.
- Key optimizations include workload planning for balanced GPU thread scheduling, kernel fusion to reduce intermediate memory traffic, and stochastic early termination for radix top-k to reduce overhead.
Training Regime: Vortex does not train models but focuses on inference serving. The 'training' analog is an 18-hour autonomous iterative optimization loop where an AI agent (Claude Code) proposes sparse attention variants and system-level optimizations (block size, sparsity) for throughput maximization while maintaining accuracy. Experimental hardware include NVIDIA H200 SXM and B200 GPUs.
Evaluation Protocol:
- Metrics: Decoding throughput (tokens/sec), latency (P95), and reasoning accuracy (pass@16 mean accuracy) on AMC23 and AIME24 benchmarks.
- Baselines: Full dense attention serving, SGLang implementations of sparse attention (block top-k, Quest).
- Ablations: Kernel fusion and stochastic top-k optimizations confirms runtime benefit.
- AI agents are prompted with prior sparse attention papers to generate 20 algorithms each. Outputs are structurally analyzed by abstract syntax decomposition.
- Evaluation includes large-scale multi-GPU deployment on 229B-parameter model.
- Reproducibility: Code and documentation released at https://github.com/Infini-AI-Lab/vortex_torch. Datasets such as AMC23 and AIME24 are referenced but dataset splits and seeds not exhaustively detailed. Large proprietary models tested may not be public. Detailed operator and compiler internals described but may require substantial engineering to reproduce at scale.
Concrete Example: Block top-k attention is implemented using vFlow primitives: query-independent cache computation of block centroids; query-dependent top-k block selection via GeMM and top-k; final attention computation only on selected sparse tokens. This program maps to paged vTensor operators and executes efficiently with workload planning and kernel fusion, resulting in throughput improvements detailed above.
Technical innovations
- Design of vFlow, a composable Python-embedded DSL abstracting sparse attention algorithms over a logical tensor view independent of complex paged memory layouts.
- Introduction of vTensor, a page-centric tensor abstraction extending PyTorch tensors with explicit layout metadata to transparently support paged KV cache storage in LLM serving.
- Compiler and runtime optimizations including workload planning, kernel fusion, and stochastic early termination in radix top-k operators to improve sparse attention indexing efficiency.
- Seamless backend integration with highly optimized attention kernels (flashinfer, trtllm_mha, trtllm_mla) plus a novel cuda_mla kernel supporting flexible block sizes and latent geometries.
Datasets
- AMC23 — unspecified size — LLM decoding benchmark
- AIME24 — unspecified size — LLM decoding benchmark
- RULER — 4000 retrieval examples (approx) — public benchmark for reasoning tasks
- GLM-4.7-Flash — model benchmark — large multilingual language model
- MiniMax-M2.7 — 229B parameters — proprietary large model hosted on NVIDIA B200 GPUs
Baselines vs proposed
- SGLang full attention: throughput = baseline; Vortex block top-k: throughput = 3.60× baseline
- SGLang full attention: throughput = baseline; Vortex Quest: throughput = 2.98× baseline
- Full attention on 229B MiniMax-M2.7: throughput = baseline; Vortex block top-k: throughput = 1.37× baseline, accuracy equal or better
- Full attention on GLM-4.7-Flash: throughput = baseline; Vortex rope-aware sparse attention: throughput = 4.7× baseline
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.06453.

Fig 1: (a). A workflow to study sparse attention algorithms using Vortex. Vortex bridges sparse
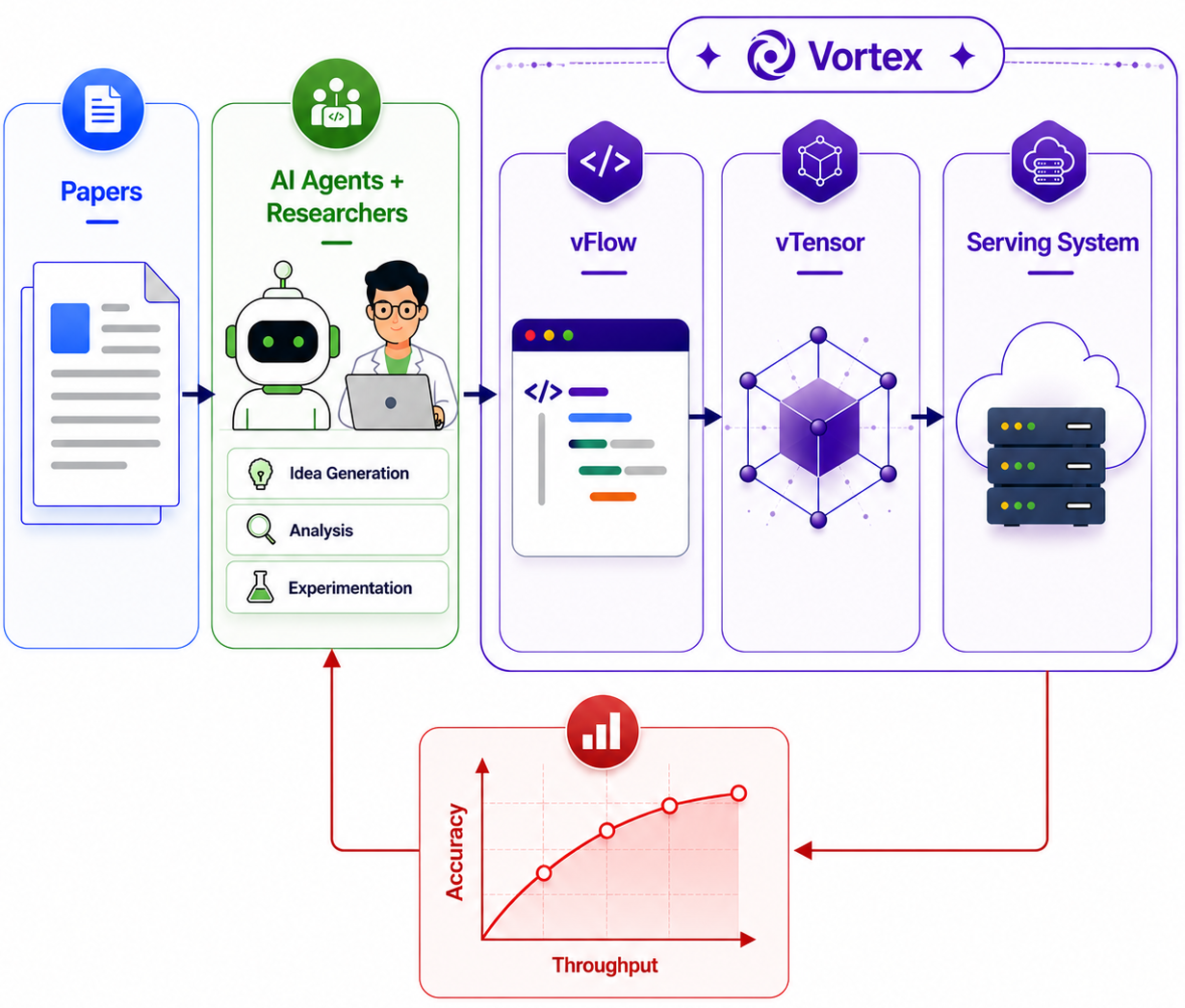
Fig 2: Illustration of paged layouts.

Fig 9: Structural diversity of AI-agent-generated sparse attention algorithms. Higher values indicate
Fig 10: Performance of AI-agent-generated sparse attention algorithms. Each point corresponds to one

Fig 11: Long-horizon autonomous optimization on AIME24 (Claude Opus 4.7, Qwen3-1.7B, 23 iterations,
Limitations
- No extensive adversarial analysis or robustness testing against input distribution shifts or adversarial prompts.
- Primary focus on decoding phase; prefix filling phase optimization left for future work.
- Large-scale deployment results reported on proprietary models and hardware, potentially limiting reproducibility.
- Accuracy preservation mainly evaluated on pass@16 metrics; effects on other downstream tasks less explored.
- AI-generated sparse attention search focused on throughput and did not substantially discover radically new sparse attention paradigms beyond block top-k.
- Kernel fusion and stochastic top-k trade-offs require user tuning; stochastic early termination introduces approximation errors not fully quantified.
Open questions / follow-ons
- How can Vortex be extended to optimize the prefix filling phase of LLM decoding, which involves different caching patterns and bottlenecks?
- Can stochastic approximations in radix top-k indexing be further tuned or combined with error correction to guarantee tighter accuracy-performance trade-offs?
- How well do AI agents generalize in generating novel sparse attention algorithms when applied to multi-modal or instruction-tuned large models?
- What are the impacts of sparse attention on downstream tasks beyond benchmarks like AMC23 and AIME24, especially for tasks requiring fine-grained token interactions?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, Vortex showcases a scalable, programmable framework to efficiently implement and evaluate sparse attention mechanisms in large language models. This can reduce the latency and resource costs of deploying LLM-powered CAPTCHAs or verification agents that rely on language understanding at large prompt lengths. The ability to rapidly prototype and iterate sparse attention patterns enables developers to tailor attention mechanisms that optimize trade-offs between throughput and accuracy specific to bot-distinguishing tasks. Vortex’s tight integration with existing serving stacks ensures that theoretical improvements translate into practical latency gains, critical for responsive user interactions in CAPTCHA challenges. Additionally, the autonomous AI agent-driven algorithm design hints at future directions where system-level optimizations for LLMs powering bot detection can be automated, improving adaptability against evolving bot behaviors.
Cite
@article{arxiv2606_06453,
title={ Vortex: Efficient and Programmable Sparse Attention Serving for AI Agents },
author={ Zhuoming Chen and Xinrui Zhong and Qilong Feng and Ranajoy Sadhukhan and Yang Zhou and Michael Qizhe Shieh and Zhihao Jia and Beidi Chen },
journal={arXiv preprint arXiv:2606.06453},
year={ 2026 },
url={https://arxiv.org/abs/2606.06453}
}