
Symmetric Divergence and Normalized Similarity: A Unified Topological Framework for Representation Analysis
Source: arXiv:2606.06342 · Published 2026-06-04 · By Yan Wang, Tianyang Hu
TL;DR
This paper addresses the limitations of existing topological data analysis (TDA) methods for comparing neural network representations, specifically the Representation Topology Divergence (RTD) framework. RTD and its variants suffer from theoretical asymmetry and unbounded, sample-size dependent divergence scores that complicate benchmarking across scenarios. The authors propose a unified topological toolkit consisting of two components: (1) Symmetric Representation Topology Divergence (SRTD) and its efficient variant SRTD-lite to provide a single, symmetric, and interpretable divergence measure that subsumes the asymmetric RTD and Max-RTD variants with better theoretical grounding and computational efficiency; and (2) Normalized Topological Similarity (NTS), a normalized, scale-invariant similarity metric bounded between -1 and 1, based on rank correlation of hierarchical merge orders using MST edge sets. Extensive experiments on synthetic hierarchical data, CNN layers, and large language model representations demonstrate that SRTD provides more stable and interpretable structural diagnosis than RTD, while NTS enables robust cross-scenario benchmarking and reveals functional hierarchical patterns that are missed or obscured by state-of-the-art geometric measures like CKA. Overall, this work significantly advances TDA representation analysis by resolving key prior weaknesses in symmetry, normalization, and interpretability.
Key findings
- SRTD resolves the asymmetry in RTD by unifying it with Max-RTD into a single symmetric cross-barcode measure (Fig 4e-f).
- SRTD-lite lies exactly between RTD-lite and Max-RTD-lite, satisfying: Max-RTD-lite ≥ SRTD-lite ≥ RTD-lite (Corollaries 3.4,3.5).
- NTS provides a normalized similarity bounded in [-1,1], robust to scale and sample size differences unlike RTD divergences.
- On synthetic clusters (300 points), NTS and SRTD track increasing structural dissimilarity smoothly, while RTD-lite shows anomalous inverted trends and CKA is insensitive (Fig 4).
- On UMAP embeddings of MNIST, NTS and SRTD-lite respond smoothly to varying neighbor parameters controlling local/global structure, outperforming CKA (Fig 5).
- In analysis of 45 TinyCNN model pairs on CIFAR-10, NTS and CKA produce coherent near-diagonal similarity landscapes indicating hierarchical consistency, whereas RTD measures show counter-intuitive irregularities (Fig 6).
- NTS uncovers consistent intra-family layer similarity patterns across multiple LLM families (Qwen, InternLM, Baichuan, Llama) even under distance saturation, where CKA heatmaps saturate or diverge (Fig 7).
- Inter-model similarity maps of 17 LLMs show NTS better differentiates families by avoiding CKA’s score saturation around max (Fig 8).
Threat model
n/a — the work is focused on intrinsic representation analysis and similarity metrics rather than security or adversarial threat modeling.
Methodology — deep read
Threat Model & Assumptions: The focus is on comparing paired neural representations drawn from the same set of inputs, i.e. sample-wise correspondences exist. There is no explicit adversarial model; rather, the methods assume the availability of paired, aligned sets of vector representations (e.g., activations from different layers or models). The goal is to assess similarity or divergence robustly across scenarios.
Data: Experiments use synthetic datasets including 300-point Gaussian clusters arranged with variable cluster counts; embeddings from MNIST using UMAP with controlled neighbor parameters; CIFAR-10 TinyCNN representations from 5,000 test images across 10 random-seed-trained models; and LLM representations from 17 diverse model families including Qwen, InternLM, Baichuan, Llama evaluated on TruthfulQA and ToxiGen datasets with 1,000 QA pairs sampled per model. Distances used include Euclidean and cosine dissimilarities.
Architecture / Algorithm: The central novelty is in the proposed SRTD and NTS metrics. SRTD is constructed from the auxiliary matrix Msym defined from element-wise min and max of two distance matrices w and ˜w. Persistent homology of this auxiliary filtration yields a symmetric cross-barcode summarizing topological discrepancies, bypassing dual directional RTD computations. SRTD-lite similarly computes differences of MST weights from min and max matrices, enabling scalable 0D analysis. NTS computes Spearman rank correlations of either MST edge weights (NTS-E) or merge times (NTS-M) on the union of MST edges from the two graphs, providing a normalized similarity value in [-1,1].
Training Regime: Not applicable, as methods analyze pretrained representations rather than training new models. For optimization experiments, SRTD and SRTD-lite were used as loss terms training autoencoders on F-MNIST and COIL-20 reducing to 16 dimensions.
Evaluation Protocol: Metrics include normalized divergences (SRTD, SRTD-lite) and normalized similarities (NTS-E, NTS-M) compared against RTD, RTD-lite, Max-RTD, Max-RTD-lite, and geometric baselines like CKA. Comparative sensitivity analysis was performed on synthetic datasets measuring trends against ground truth structural changes. CNN layer-wise similarity heatmaps and LLM intra-family and inter-model similarity maps evaluated interpretability and ability to capture hierarchical and lineage structure. Statistical significance or cross-validation is not explicitly stated.
Reproducibility: Code is publicly released at https://github.com/frankwy505/SRTD-NTS. The LLM datasets and some experimental details rely on prior published datasets (TruthfulQA, ToxiGen, CIFAR-10). Full algorithmic details and proofs provided in supplementary appendices.
Concrete end-to-end example: In the synthetic clusters experiment with 300 points arranged in k clusters, distance matrices w and ˜w were computed for different k values. For each pair, SRTD computes a symmetric barcode from the auxiliary matrix Msym and sums interval lengths as a divergence. NTS computes merged MST edge sets, extracts merge times or edge weights, and calculates Spearman rank correlations as similarity. Results show smooth increasing divergence and decreasing similarity matching ground truth increasing structural difference, unlike RTD-lite or CKA baselines which behave anomalously or insensitively. This illustrates the practical enhanced interpretability and cross-scenario robustness of the new metrics.
Technical innovations
- Symmetric Representation Topology Divergence (SRTD) introduces a single symmetric cross-barcode construction unifying RTD and Max-RTD, resolving prior heuristic asymmetry and providing a comprehensive structural discrepancy signature.
- SRTD-lite extends MST-based divergence formulations by comparing MSTs of min and max distance matrices to efficiently approximate full SRTD at 0D connectivity level.
- Normalized Topological Similarity (NTS) leverages rank correlations of MST merge orders (NTS-M) or edge weights (NTS-E) to produce a normalized, scale-invariant similarity bounded between -1 and 1, enabling robust cross-scenario benchmarking.
- Theoretical characterization of relationships between RTD, Max-RTD, and SRTD via long exact sequences and mapping cone homologies that mathematically explain RTD’s asymmetry origins.
- Integration of intrinsic topological summaries with representational similarity analysis (RSA) principles using MST merge orders to overcome limitations of unnormalized divergence sums.
Datasets
- Synthetic Gaussian Clusters — 300 points — synthetic
- MNIST — 10K images for UMAP embeddings — public
- CIFAR-10 — 5,000 test images — public
- F-MNIST — standard benchmark for autoencoder training — public
- COIL-20 — 1,440 images for autoencoder training — public
- TruthfulQA — 1,000 QA pairs sampled — public
- ToxiGen — 1,000 QA pairs sampled — public
- LLM model activations from 17 families including Qwen, InternLM, Baichuan, Llama — private models, data extraction protocol public
Baselines vs proposed
- RTD-lite: anomalous inverted sensitivity trend on synthetic Clusters dataset vs NTS and SRTD rising smoothly
- CKA: insensitive to structural changes on Clusters and UMAP embeddings vs NTS and SRTD variants showing smooth responses
- Intra-model TinyCNN layer similarity: CKA and NTS show consistent near-diagonal decay vs RTD family showing irregular heatmaps
- LLM intra-family similarity on TruthfulQA: CKA saturates around >0.8 for multiple families, NTS reveals clear hierarchical patterns and family-wise distinctions
- Inter-model similarity for 17 LLMs: NTS better differentiates families while CKA scores cluster near max saturating distinctiveness
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.06342.

Fig 4: Comprehensive analysis of the RTD framework on the synthetic Clusters dataset.
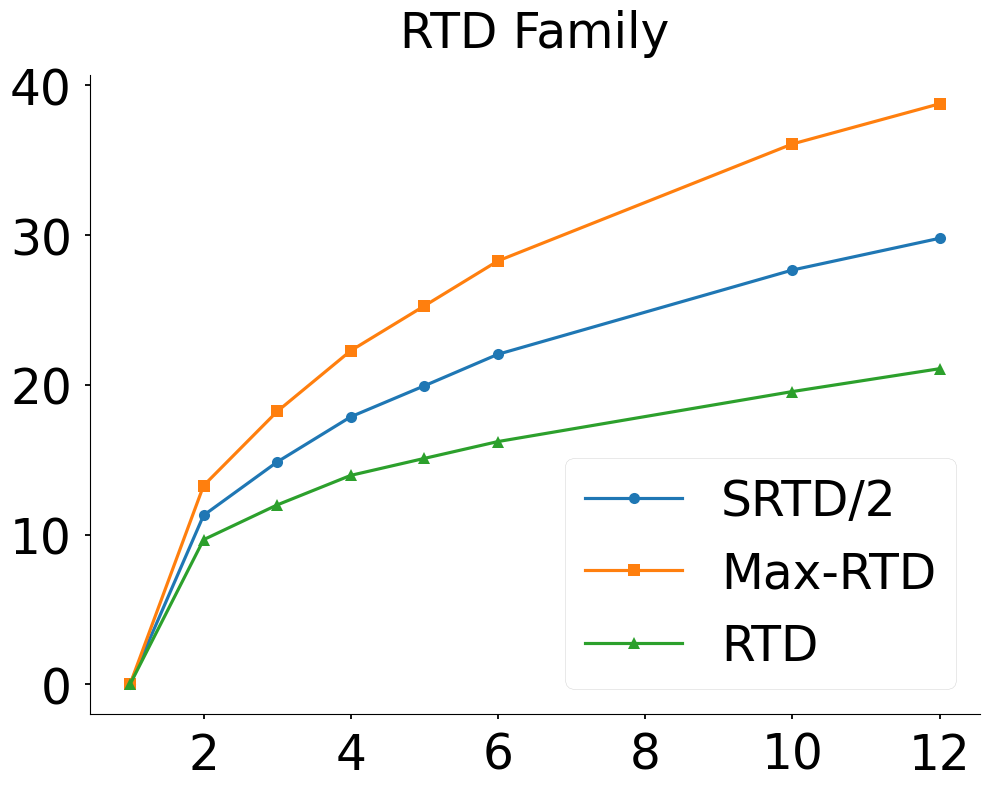
Fig 5: UMAP experiment
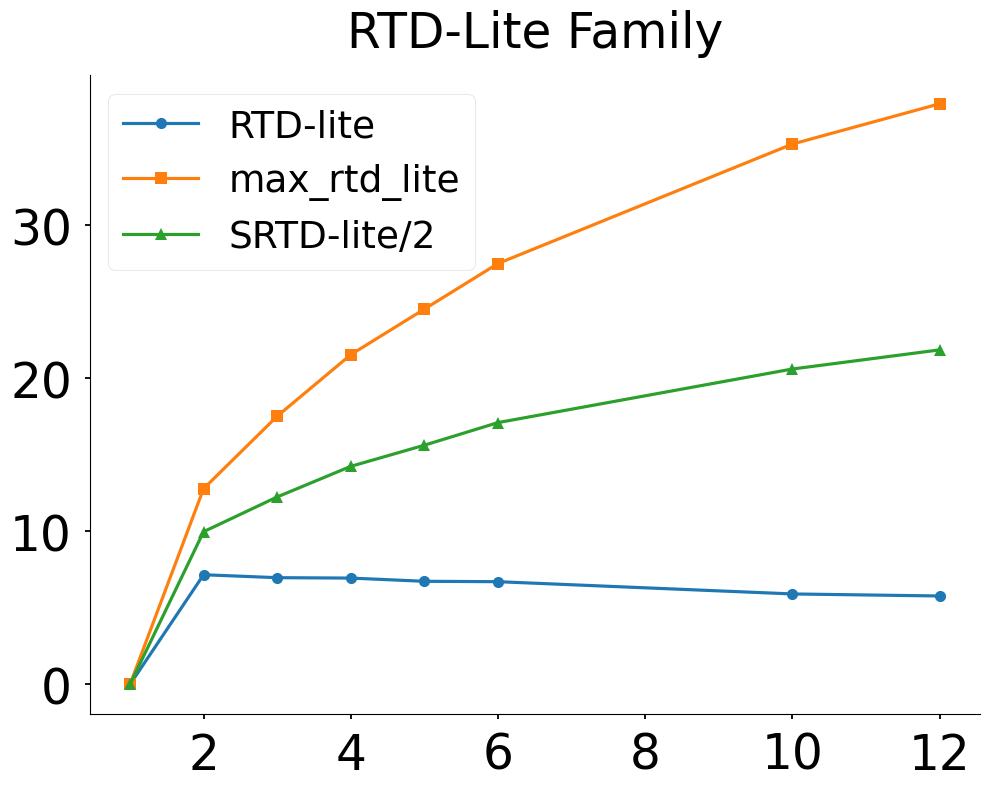
Fig 6: Average layer-wise similarity comparison over 45 pairs of trained TinyCNNs. While CKA (a) and
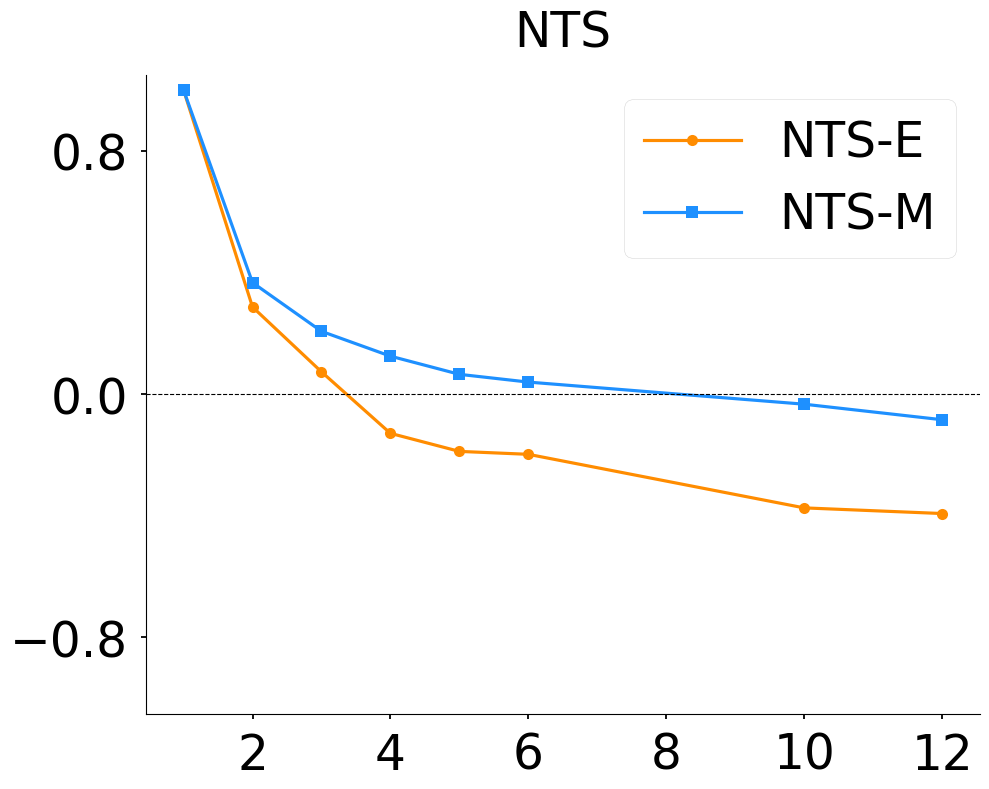
Fig 3: While Rep. A and Rep. B have distinct geometric layouts (CKA ≈0.68), their 0D merge events
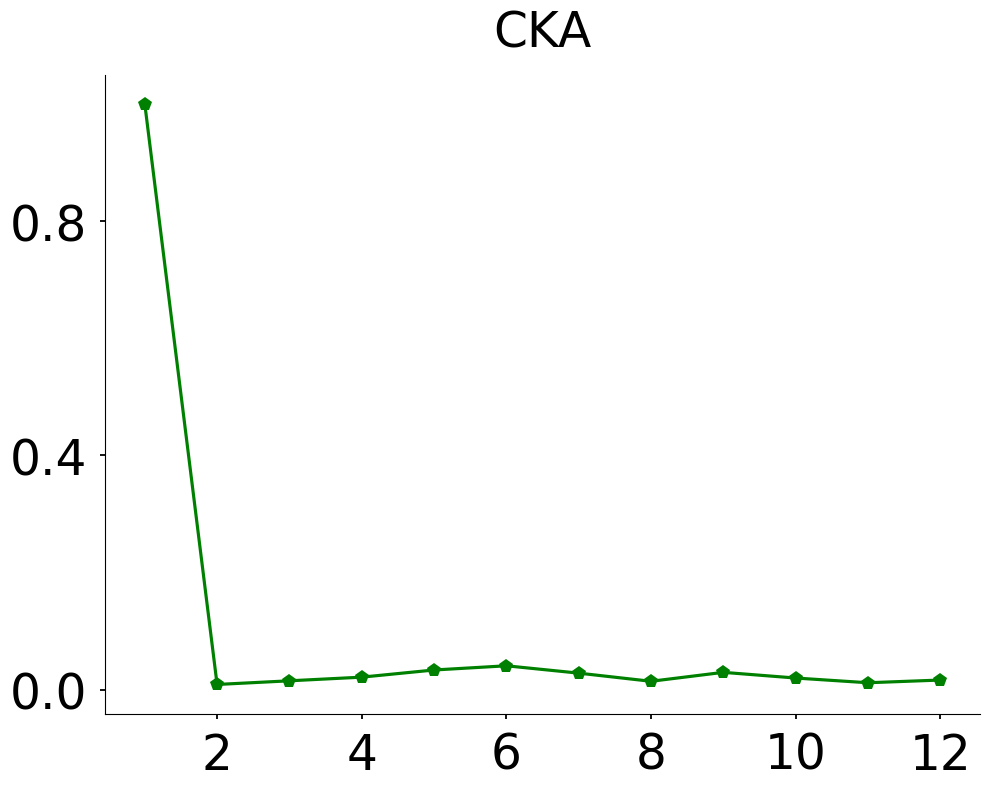
Fig 7: Intra-model layer similarity for LLM families on the TruthfulQA (top half) and ToxiGen (bottom
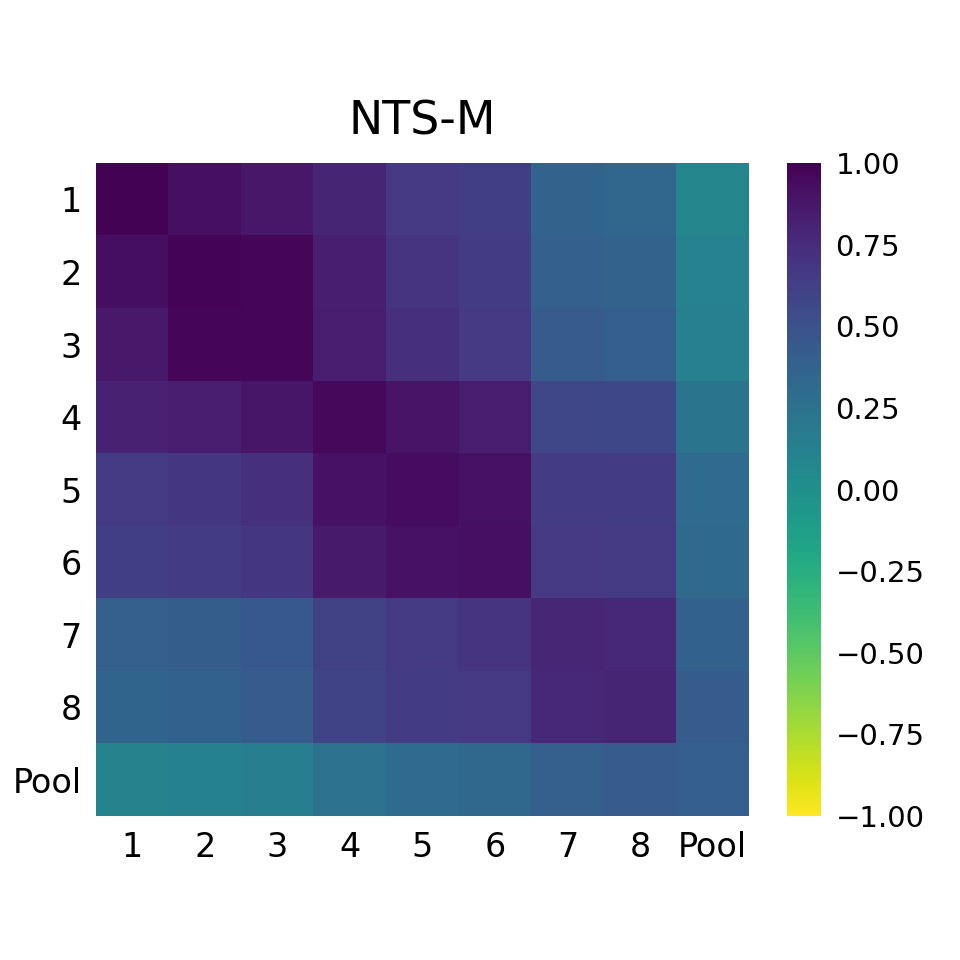
Fig 8: Inter-model similarity maps for 17 LLMs
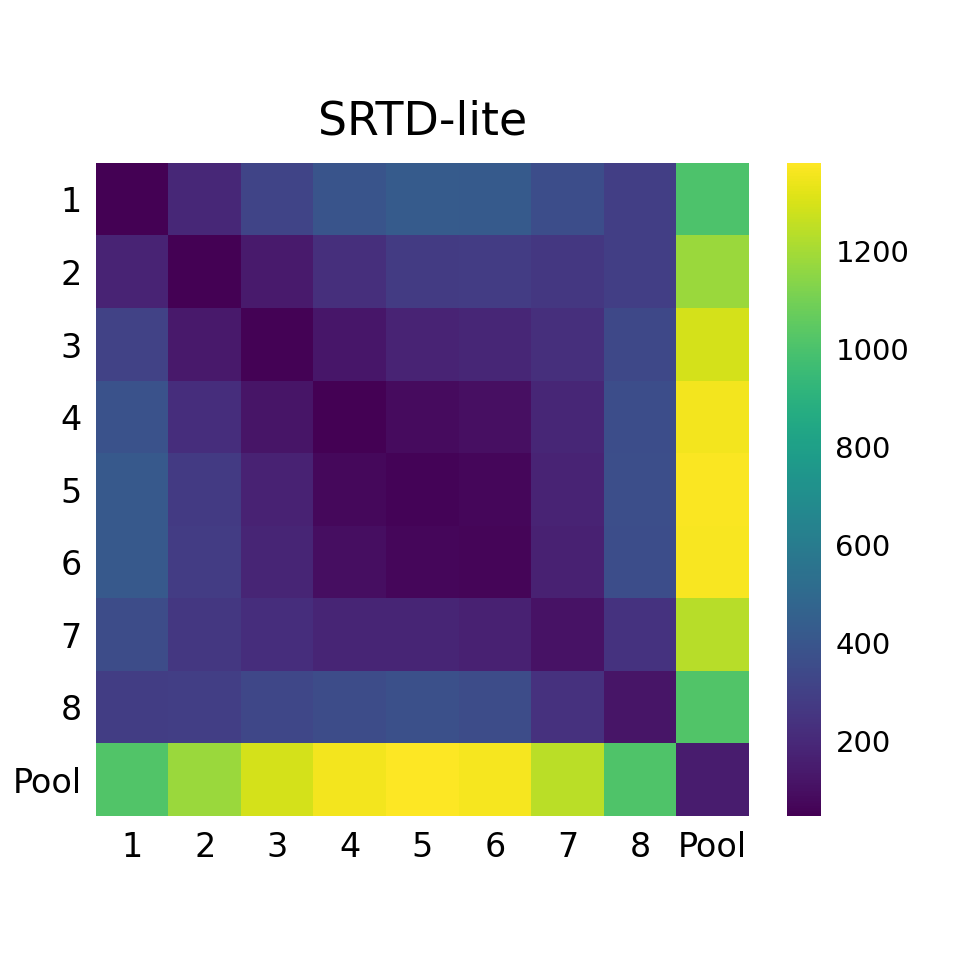
Fig 9: Runtime comparison on CIFAR-10 repre-
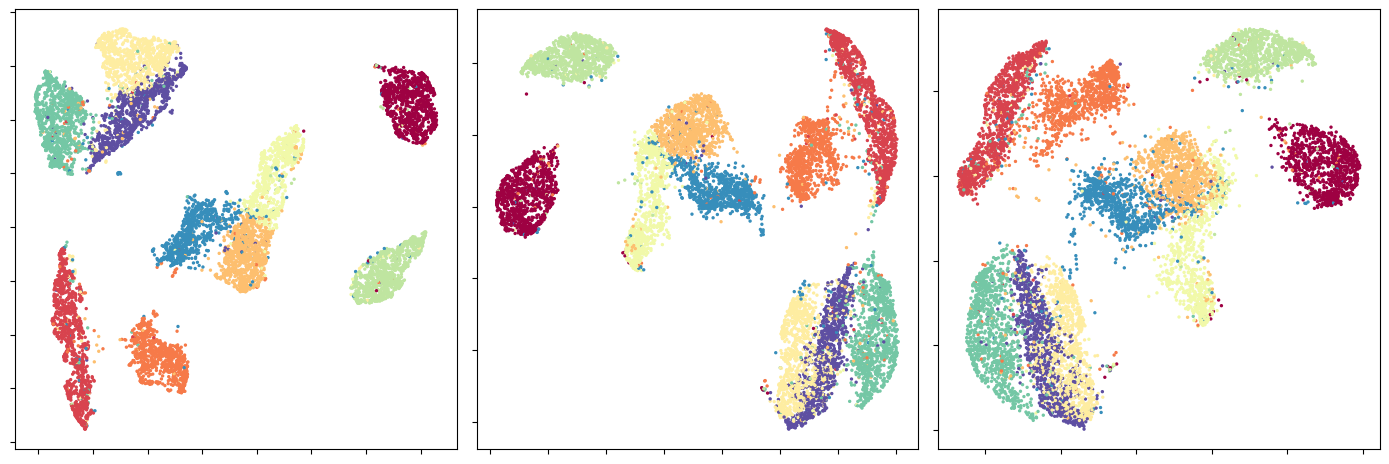
Fig 8 (page 10).
Limitations
- SRTD and NTS focus primarily on paired representations with one-to-one sample correspondence; applicability to unpaired or partial data unknown.
- Experiments do not evaluate the robustness of these measures under adversarial perturbations or distributional shifts besides controlled synthetic or domain shifts.
- The approach relies on MST-based summaries for efficiency, which captures only 0D connectivity and may miss higher-dimensional topological features.
- As with many TDA tools, interpretability of barcodes and topological features beyond 0D requires domain expertise; the practical utility in complex real-world pipelines remains to be fully demonstrated.
- Theoretical analysis of Max-RTD and SRTD relationships is primarily for idealized settings; real data high dimensionality and noise effects are less characterized.
Open questions / follow-ons
- How do SRTD and NTS perform under adversarial or corrupted input representations, e.g., adversarially perturbed activations?
- Can the framework be extended to incorporate higher-dimensional persistent homology features beyond 0D connectivity to capture richer topological signatures?
- What are the implications and applications of SRTD and NTS in continual learning or domain adaptation settings where representation shifts occur?
- How does the choice of distance metric (Euclidean, cosine, others) influence the stability and interpretability of SRTD and NTS?
Why it matters for bot defense
Bot-defense and CAPTCHA systems increasingly rely on nuanced analyses of internal representation differences, for example to detect subtle automated behaviors or model drift. The unified topological framework here offers tools that overcome existing limitations of asymmetry and unnormalized scoring in comparing neural activations. SRTD provides more robust, interpretable structural discrepancy signals that could be leveraged to identify nuanced representation shifts indicative of bot tactics. The normalized similarity metric NTS enables reliable benchmarking across diverse attack or environment conditions without confounding scale or sample size effects, a common challenge in security-focused evaluation. Furthermore, the rank-based, topology-aware similarity complements standard geometric measures like CKA that can saturate or lose sensitivity, offering an orthogonal lens for profiling model behavior over time or across configurations. While the work does not directly target adversarial settings, the enhanced diagnostic and comparative capabilities offered by this method provide a promising foundation for developing more resilient representation-based bot detection features or CAPTCHA challenge adaptation strategies.
Cite
@article{arxiv2606_06342,
title={ Symmetric Divergence and Normalized Similarity: A Unified Topological Framework for Representation Analysis },
author={ Yan Wang and Tianyang Hu },
journal={arXiv preprint arXiv:2606.06342},
year={ 2026 },
url={https://arxiv.org/abs/2606.06342}
}