
Humans' ALMANAC: A Human Collaboration Dataset of Action-Level Mental Model Annotations for Agent Collaboration
Source: arXiv:2606.06388 · Published 2026-06-04 · By Jiaju Chen, Yuxuan Lu, Jiayi Su, Chaoran Chen, Songlin Xiao, Zheng Zhang et al.
TL;DR
The paper introduces ALMANAC, a novel dataset designed to address a critical gap in human-agent collaboration research: the lack of human collaboration data annotated with detailed, action-level mental models. While recent large language model (LLM) agents demonstrate impressive task-solving capabilities, they rarely model collaborators' ongoing reasoning, intentions, or shared goals dynamically, which limits their ability to authentically collaborate with humans. ALMANAC is built on the classic Map Task dyadic routing paradigm, capturing 2,987 collaboration actions from 25 pairs of participants, each paired with structured mental model annotations including self-reasoning, perceived partner intent, perceived team goal, and free-form rationales.
The authors benchmark six state-of-the-art LLMs on two tasks — next-turn behavior prediction and mental model prediction — showing that mental model annotations provide useful signals for predicting human collaborative behavior but that current LLMs struggle most with inferring private reasoning (self-reasoning) as opposed to shared states like team goal or partner intent. The dataset and evaluation reveal a role- and visibility-dependent tradeoff: Guides’ mental models are harder to predict but their actions easier to anticipate, while Followers show the opposite pattern. Fine-tuned smaller models on ALMANAC approach larger models’ performance, highlighting the dataset’s value for training collaboration-aware agents. ALMANAC opens foundational pathways for nurturing LLM agents beyond task completion toward genuine, theory-grounded collaboration.
Key findings
- ALMANAC contains 2,987 collaboration actions from 25 dyadic sessions with detailed mental model annotations (self-reasoning, partner intent, team goal).
- Participants averaged 0.66 drawing accuracy reproducing routes; performance was similar whether the Guide could see the Follower’s canvas (Cvisible = 0.65, Cnot_visible = 0.67).
- Mental model alignment (team goal, partner intent, self-reasoning) increased over time and was higher when the Guide could see the Follower’s canvas (Fig 4).
- Six LLMs benchmarked include Qwen3.6-35B, Llama 3.3 70B, GPT-5.5, Claude 4.6 Sonnet, and fine-tuned Qwen3-4B/30B.
- Adding mental model annotations to input improves Followers’ next action prediction accuracy (e.g., GPT-5.5 drawing accuracy improved from 0.43 to 0.47 in Cnot_visible).
- Mental model prediction accuracy for team goal and partner intent ranges from 0.35 to 0.76, with Followers generally easier to predict than Guides.
- Self-reasoning was the hardest mental model component to predict, with accuracy often below 0.5 across models and conditions.
- Fine-tuned Qwen3-4B matched or exceeded larger models in Followers’ mental model prediction and rationale similarity (SBERT), showing the benefit of targeted supervision.
Threat model
The adversary in this work is not adversarial but collaborative human participants operating under controlled conditions. The threat model focuses on authentic capture of human collaboration processes without manipulation or deception. Adversaries do not attempt to deceive or mislead agents, and agents lack adversarial capabilities or intent.
Methodology — deep read
The paper’s methodology centers on collecting and annotating a rich human collaboration dataset (ALMANAC) based on the Map Task, adapted for remote, text-based human collaboration. The threat model assumes collaboration between two human participants, one acting as Guide and the other as Follower, communicating solely via text and workspace actions without non-verbal cues. No adversarial setting is considered.
Data collection involved 50 participants paired into 25 dyads completing the Map Task under two conditions: Cvisible, where the Guide can see the Follower’s drawing canvas in real time, and Cnot_visible, where the Guide cannot. The task required reproducing a route on a grid map featuring landmarks, with participants using chat messages and drawing tools. Sessions averaged 28.25 minutes. Collected interaction data included timed action traces (messages, draws, erases, undos, resets) along with participant personas and collaboration tendencies.
The annotation framework comprised two phases: (1) In-session checkpoints at 25%, 50%, and 75% completion, where participants briefly describe their current mental state (team goal, perceived partner intent, self-reasoning) recorded via voice and transcribed; (2) Post-session retrospective annotation, supported by showing the full action trajectory, screenshots, and corresponding in-session checkpoint to aid recall. Participants annotate each action with mental model components plus a free-form rationale and an alignment rating.
Data was then standardized: spatial maps converted to discrete grids aligned to cells, allowing each drawing state to be encoded as a binary matrix. Personal information was scrubbed. Mental model annotations compose tuples (team goal, partner intent, self-reasoning, alignment, rationale) per action.
For benchmarking, six LLMs were evaluated under two main tasks: next-turn behavior prediction (predict the participant’s next action given interaction history and persona) and mental model prediction (predict the participant’s mental states at next action). Evaluations were done both with and without annotated mental model input, and with chain-of-thought prompting as an ablation. LLMs included open models (Qwen3.6-35B-A3B, Llama 3.3 70B), proprietary GPT-5.5 and Claude 4.6 Sonnet, and models fine-tuned on ALMANAC data (Qwen3-4B and Qwen3-30B-A3B).
Metrics included classification accuracy and recall on action types and mental model categories, semantic similarity (SBERT) for message and rationale generation, and a spatial drawing accuracy metric based on Chebyshev distance from ground-truth routes. Baselines included zero-shot LLMs and fine-tuned smaller models. Inter-annotator agreement for grounding act labels showed strong reliability (Fleiss’ κ = 0.81), and GPT-5.5 automated annotation achieved κ = 0.76.
An example end-to-end process: a participant takes an action at time t (e.g. draws a route segment). During the session, they report mental model states at checkpoints. Post-session, they annotate mental models for each action aided by contextual information. A model is then given the interaction and persona history up to t-1 to predict the next action and mental states at t, optionally with ground-truth mental model context, evaluated against the human annotation.
Reproducibility is supported by public dataset release on HuggingFace and model prompt details in appendix. However, hardware details for training or seeds are not specified, and some LLMs are proprietary.
Technical innovations
- A novel action-level annotation framework capturing three key components of mental models—self-reasoning, perceived partner intent, and perceived team goal—paired with free-form rationales.
- Integration of in-session real-time mental state checkpoints as memory anchors to improve fidelity of retrospective post-session mental model annotation.
- Encoding dyadic collaboration data from a classic social science Map Task into a text-encodable spatial grid format suitable for LLM-based modeling.
- Benchmarking multiple state-of-the-art large and fine-tuned language models in complementary next action and mental model prediction tasks to empirically measure collaborative cognition inference capabilities.
Datasets
- ALMANAC — 2,987 collaboration actions with mental model annotations — collected from 25 dyadic Map Task sessions involving 50 participants, publicly available on HuggingFace
Baselines vs proposed
- Qwen3.6-35B-A3B next action prediction accuracy: ~0.54 Follower Action Type vs +Mental Model: ~0.55
- GPT-5.5 Follower drawing accuracy improved from 0.43 to 0.47 with mental model input in Cnot_visible condition
- Claude 4.6 Sonnet Follower Team Goal mental model prediction accuracy up to 0.75 in Cvisible vs 0.48 for Guide
- Fine-tuned Qwen3-4B mental model prediction accuracy achieves 0.81 Team Goal accuracy for Follower in Cnot_visible, outperforming base LLMs
- SBERT semantic similarity for rationale generation ranges approx 0.40–0.55 across models, with fine-tuning improving scores
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.06388.
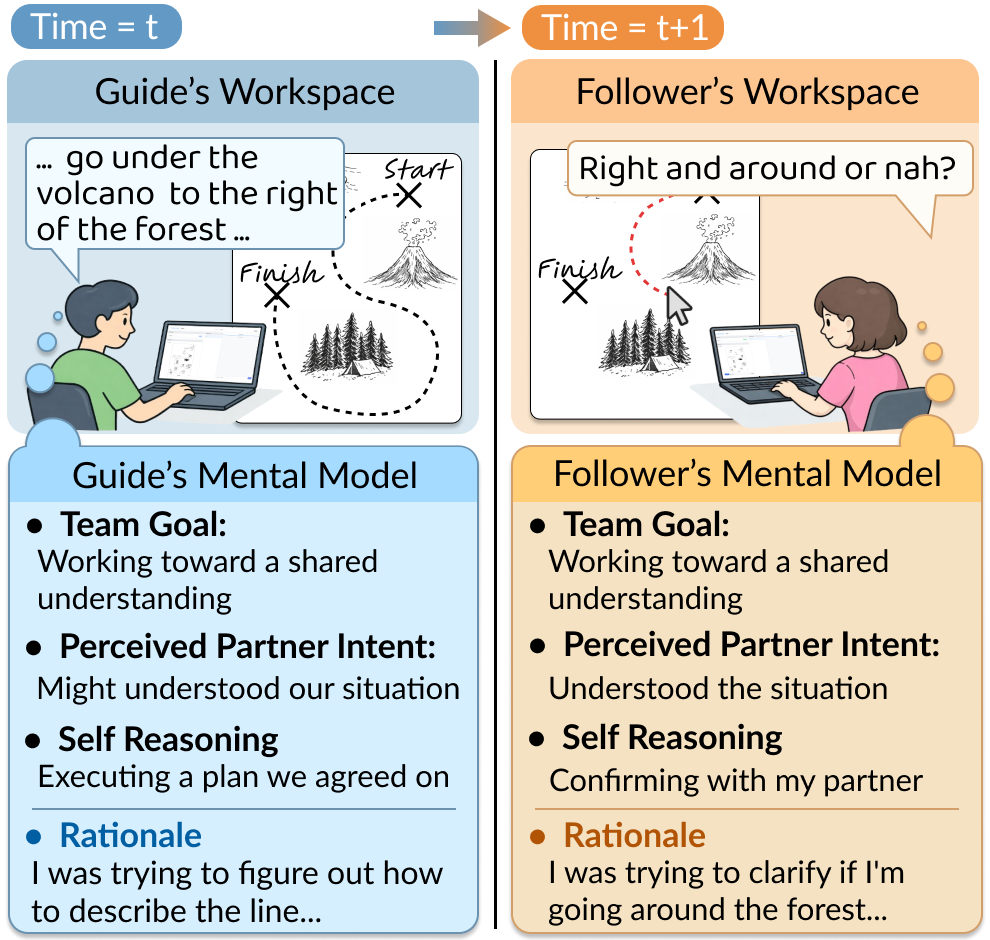
Fig 1: A sample data of ALMANAC, which contains
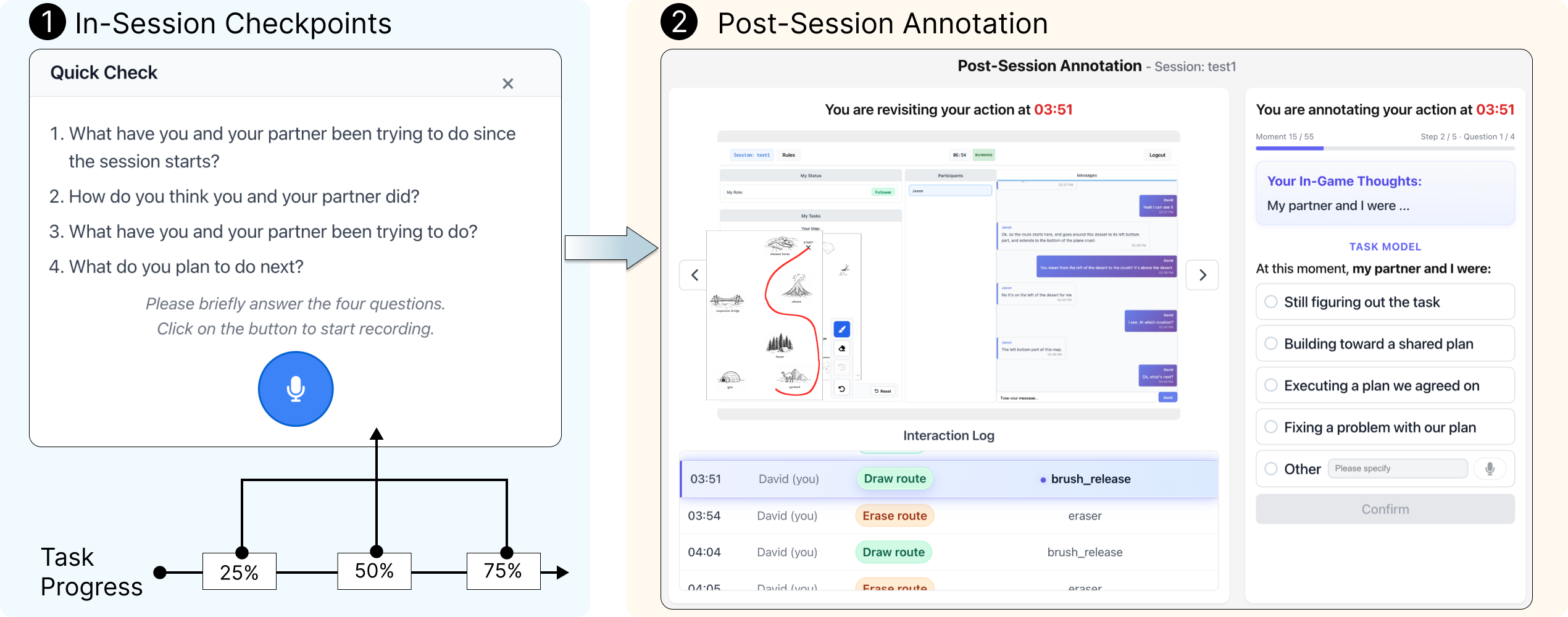
Fig 2: Annotation workflow and interfaces of ALMANAC. Participants first complete the Map Task while
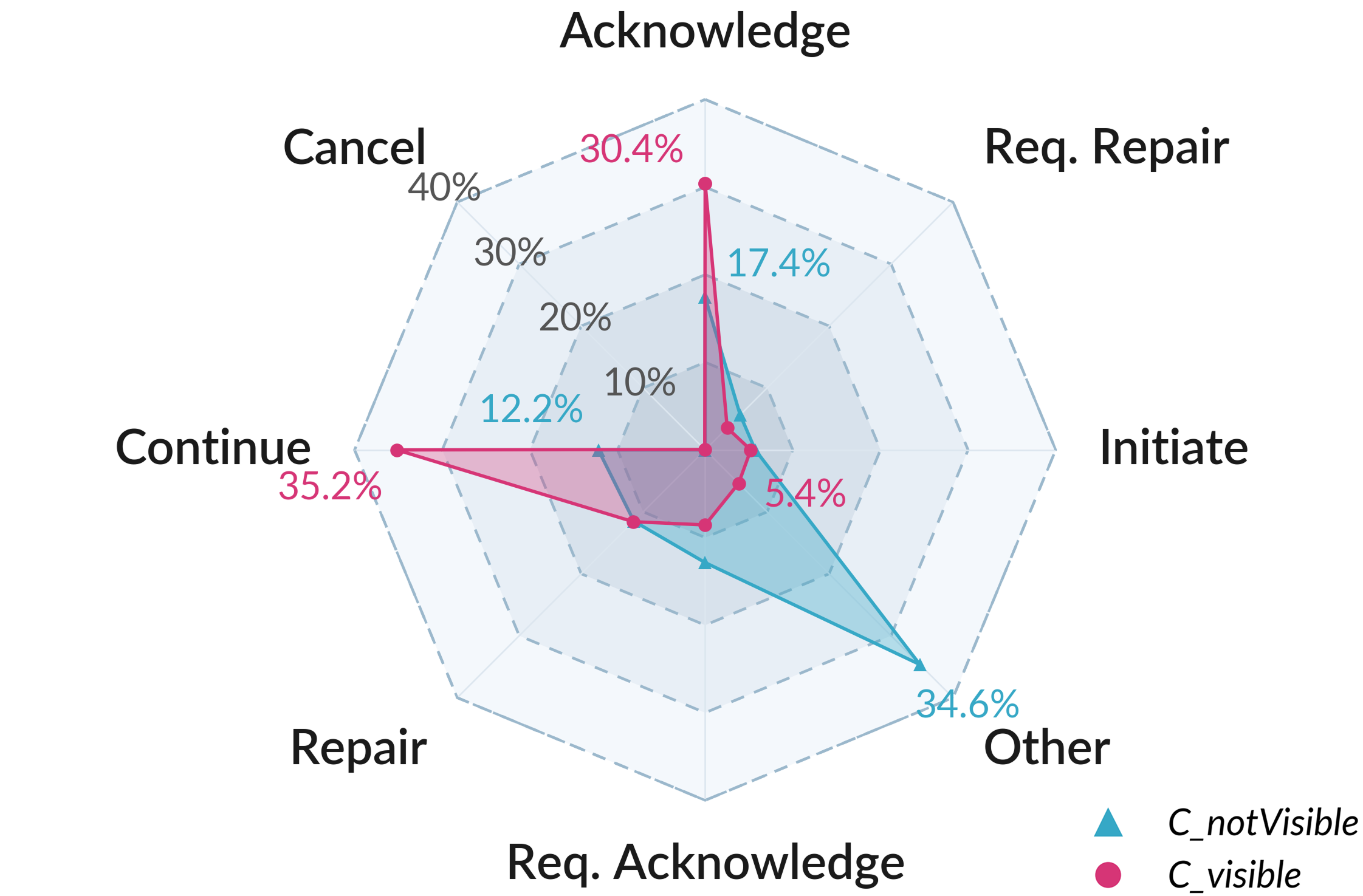
Fig 3: The relative proportion of each grounding act
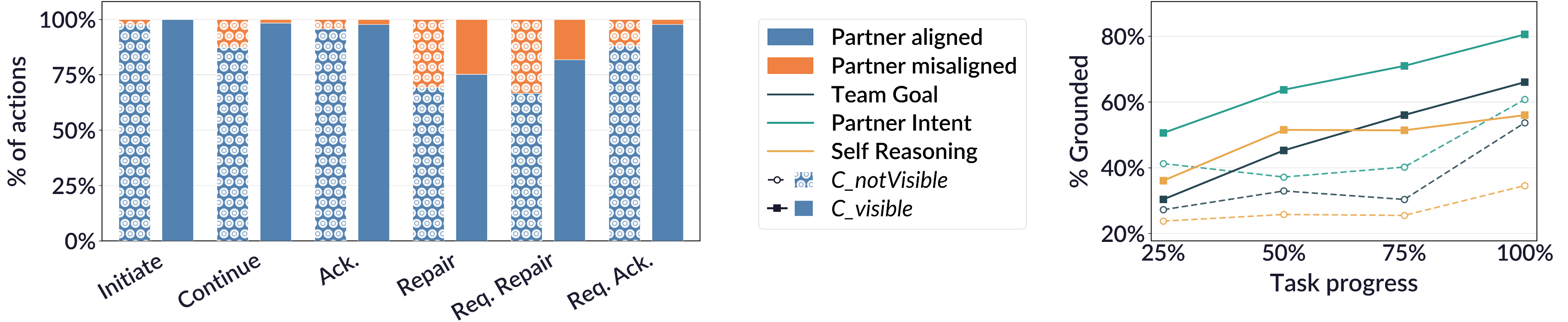
Fig 4: Relationships between grounding acts and mental model alignment. Left: the proportion of perceived
Fig 5: Guide map used in the Map Task. The guide
Fig 6: Follower map used in the Map Task. The
Fig 7: Grid-based map representation used for LLM-
Limitations
- Mental model annotations rely partially on post-session retrospective reports subject to recall bias and post-hoc rationalization.
- The dataset size is modest (25 sessions, 50 participants), limiting generalizability compared to large-scale NLP datasets.
- Participants were recruited via snowball sampling which may affect population representativeness.
- LLMs struggle to infer private, internal self-reasoning compared to externally grounded team goal or partner intent, limiting insight into private cognition.
- Despite improvements, gains from including mental model signals in behavior prediction are inconsistent across models and conditions.
- The study environment is a simplified dyadic routing task, limiting extrapolation to more complex or multi-agent real-world collaborations.
Open questions / follow-ons
- How can real-time, continuous mental model inference be improved for private self-reasoning components beyond retrospective annotations?
- Can ALMANAC-scale annotated datasets be expanded to more complex, multi-agent, or multi-modal collaboration scenarios to better generalize agent capabilities?
- What novel training paradigms or architectural innovations can enable LLM agents to effectively leverage mental model signals for maintaining shared situation awareness in collaboration?
- How do mental model alignment dynamics evolve over longer time horizons and across culturally or demographically diverse populations?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, ALMANAC offers a rare window into the cognitive processes underpinning authentic human collaboration at a granular, action-by-action level. Understanding how humans maintain and align mental models—reasoning about their own actions, interpreting partner intentions, and tracking team goals—provides a conceptual framework to differentiate sophisticated human-like coordination from automated or scripted agent behavior.
Although the specific Map Task domain is specialized, the annotated mental model signals and behavioral patterns can inform design of advanced bot-detection heuristics or behavioral CAPTCHAs that gauge a claimant’s ability to perform multi-turn, theory-grounded collaboration rather than simply executing instructions. Incorporating mental model features into evaluation—such as reasoning consistency, intent alignment, or progress-aware adjustments—could improve the robustness and interpretability of bot-defense mechanisms when interacting with increasingly capable LLM-driven agents.
Cite
@article{arxiv2606_06388,
title={ Humans' ALMANAC: A Human Collaboration Dataset of Action-Level Mental Model Annotations for Agent Collaboration },
author={ Jiaju Chen and Yuxuan Lu and Jiayi Su and Chaoran Chen and Songlin Xiao and Zheng Zhang and Yun Wang and Yunyao Li and Jian Zhao and Tongshuang Wu and Toby Jia-Jun Li and Dakuo Wang and Bingsheng Yao },
journal={arXiv preprint arXiv:2606.06388},
year={ 2026 },
url={https://arxiv.org/abs/2606.06388}
}