
DragOn: A Benchmark and Dataset for Drag-Based GUI Interactions
Source: arXiv:2606.06322 · Published 2026-06-04 · By Nathan Bout, Maxime Langevin, Ronan Riochet
TL;DR
This paper addresses the underexplored problem of drag grounding in vision-language models (VLMs) for GUI interactions, where the task is to localize both source and target drag coordinates for actions like dragging, swiping, highlighting, resizing, and slider manipulation. While prior datasets have focused heavily on click grounding with millions of examples, drag grounding datasets have been an order of magnitude smaller and mostly limited to text highlighting. DragOn introduces a large-scale benchmark and dataset that unifies four distinct drag-based interaction domains—text highlighting, cell selection, element resizing, and slider manipulation—comprising 286K screenshots and 3.5M training tasks, with a held-out evaluation suite of 2000 examples. The key innovation is a "rendering-as-supervision" labeling principle that leverages the native geometry and renderer outputs of source documents (PDF, XLSX, PPTX, HTML) to generate exact pixel-aligned bounding box annotations cheaply and at large scale, avoiding error-prone OCR or detection labeling common in prior work.
The authors benchmark several state-of-the-art proprietary (Claude, GPT) and open source (Qwen, Kimi, Holo) large VLMs on DragOn, showing uniformly low performance below 30% accuracy across tasks with especially poor results on text highlighting and element resizing. Fine-tuning the open Qwen 3.5B model on the DragOn training data yields a substantial improvement (2.3% to 35.3% total accuracy), exceeding all other evaluated models on three of four domains. This demonstrates that targeted drag grounding data can meaningfully enhance vision-language models for this challenging class of interactions, which form a critical part of real-world GUI usage beyond simple clicks. The dataset and benchmark thus provide a much-needed resource to drive future progress on drag-based GUI agent grounding.
Key findings
- DragOn dataset has 286,012 training screenshots and 3,560,142 training drag tasks across four GUI interaction domains.
- Current state-of-the-art proprietary VLMs (Claude Opus 4.7, GPT-5.4) achieve no more than 27.7% overall success on drag grounding; text highlighting and element resizing are especially challenging.
- The best proprietary model scores 57.2% accuracy on slider manipulation but only 7.6%-9.2% on text highlighting.
- Open-weight models lag behind proprietary ones, with Qwen 3.5B at only 2.3% baseline accuracy.
- Fine-tuning Qwen 3.5B on DragOn data improves accuracy from 2.3% to 35.3%, outperforming all tested models on three out of four domains.
- Element resizing accuracy improves substantially under relaxed spatial tolerance: from 32.0% (strict) to 57.2% at 15% pixel tolerance, indicating errors are often small spatial offsets.
- About 14% (50/361) of OSWorld tasks and 83% (96/116) of AndroidWorld tasks require drag actions, showing drag grounding is critical for real-world GUI agent utility.
- The DragOn benchmark test sets include balanced splits of 1,000 examples evenly covering text highlighting, cell selection, element resizing, and slider manipulation.
Threat model
The adversary is the intrinsic modeling challenge in vision-language grounding of drag interactions on GUIs: a learning system must infer precise source and target drag points from a natural language instruction and a single screenshot, without direct API or accessibility tree access. Adversaries include distributional shifts and ambiguities in GUI layouts. The models cannot query the GUI dynamically or receive multi-step interaction feedback in this setup.
Methodology — deep read
The authors start by defining the threat model as developing vision-language agents that must generalize to real-world GUI interactions requiring precise drag grounding—i.e., outputting both source and target pixel coordinates for drag actions given a natural language instruction and a screenshot. The adversary is implicitly the limitations of current VLMs lacking sufficient drag interaction training data.
The DragOn dataset is constructed from four heterogenous domains, each with bespoke data pipelines exploiting a rendering-as-supervision labeling approach:
Text Highlighting: styled DOCX documents sourced from Wikipedia pages in English and French are converted via LibreOffice's headless DOCX-to-PDF renderer. Ground-truth bounding boxes for text spans of varying granularity (character to paragraph) are extracted analytically using PDF geometry via PyMuPDF.
Cell Selection: Fully synthetic XLSX spreadsheets generated with Pandas DataFrames (e.g., calendars, gradebooks) are rendered by LibreOffice Calc inside a Debian Docker container. Pixel-accurate bounding boxes are recovered using probe-based visual detection by assigning distinctive colors to cells one-by-one to find exact pixel regions.
Element Resizing: Real-world PPTX slides from the Zenodo 10K corpus are rendered headlessly in LibreOffice to JPEG. Shape geometry is extracted precisely from PPTX XML using EMU units which are converted to pixel coordinates analytically. Actions parameterize dragging of eight standard resize and rotation handles.
Slider Manipulation: Ten HTML slider widgets with diverse visual styles are programmatically generated and rendered in a headless Playwright-Chromium browser. Source and target bounding boxes come from slider geometry computations.
The dataset contains 286K training screenshots and 3.5M training drag tasks, with a held-out evaluation suite of 2,000 examples equally split across the domains and between public validation and private test sets. Each example pairs a screenshot with one natural language intent and associated source/target bounding boxes.
The authors fine-tune a pretrained Qwen3.5-VL-35B-A3B vision-language model on the entire DragOn training set using Adam optimizer (lr=1e-6), global batch size 64 on 32 Nvidia H100 GPUs, for 1000 steps (~2 epochs). Input length is sequence length 20480 tokens. The output is a structured JSON of four drag coordinates in pixel space.
For evaluation, they test multiple baselines including proprietary models (Claude Sonnet 4.5, Claude Opus 4.7, GPT-5.4) queried through APIs with forced JSON output of drag points. Open models tested include Kimi-K2.5, Holo3-35B, Qwen3.5-35B, and larger Qwen variants up to 397B parameters. The fine-tuned Qwen 3.5B model is run locally with chain-of-thought enabled.
Metrics report exact success rates (%) for predicting drag source and target coordinates falling within ground truth bounding boxes. For element resizing, evaluation includes relaxed spatial tolerances at ±10% and ±15% of slide dimensions to account for near-miss predictions. Results show large accuracy improvements from fine-tuning on DragOn data across domains but remaining room for progress especially on text highlighting and element resizing. The training dataset and evaluation code are released publicly to enable reproducibility and leaderboard comparisons.
Concretely, a single example in text highlighting might contain a screenshot of a styled Wikipedia article page, an instruction like “Highlight the second 'Federal' in paragraph 3”, and pixel coordinates for the start and end bounding boxes of the text span derived exactly from PDF geometry. The model must map the natural language to these pixel indices. Without fine-tuning on DragOn, even strong models perform poorly on this task. After fine-tuning, success rate increases significantly, demonstrating DragOn’s value.
Technical innovations
- Rendering-as-supervision: exploiting the native renderer geometry (PDF, XLSX, PPTX, HTML) as an exact labeling source for pixel-aligned drag bounding boxes without noisy OCR or detection.
- Unified drag grounding benchmark spanning four diverse GUI interaction domains—text highlighting, cell selection, element resizing, and slider manipulation—one to two orders of magnitude larger than prior drag-specific datasets.
- Probe-based label maps for pixel-exact cell selection via controlled color-key perturbations and visual localization inside a real LibreOffice Calc renderer container.
- Fine-grained evaluation including ordering sensitivity, continuous degrees of freedom in resizing/rotation, and tolerance-based success metrics to better characterize model performance nuances.
Datasets
- DragOn — 286,012 training screenshots, 3.56M training tasks, 2,000 held-out evaluation examples — constructed from Wikipedia DOCX, synthetic XLSX, Zenodo PPTX slides, and procedurally generated HTML sliders
Baselines vs proposed
- Claude Sonnet 4.5: total accuracy = 10.7% vs fine-tuned Qwen 35B = 35.3%
- Claude Opus 4.7: total accuracy = 27.7% vs fine-tuned Qwen 35B = 35.3%
- GPT-5.4: total accuracy = 25.7% vs fine-tuned Qwen 35B = 35.3%
- Qwen3.5 35B (baseline): total accuracy = 2.3% vs fine-tuned Qwen 35B = 35.3%
- Holo3-35B: total accuracy = 23.2% vs fine-tuned Qwen 35B = 35.3%
- Qwen3.5 397B: total accuracy = 21.5% vs fine-tuned Qwen 35B = 35.3%
- Element resizing accuracy at strict tolerance: fine-tuned Qwen = 32.0%, others < 24%; at 15% tolerance: fine-tuned Qwen = 57.2%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.06322.

Fig 1: The four drag grounding action domains covered by the proposed DragOn benchmark. Each example pairs a screenshot with
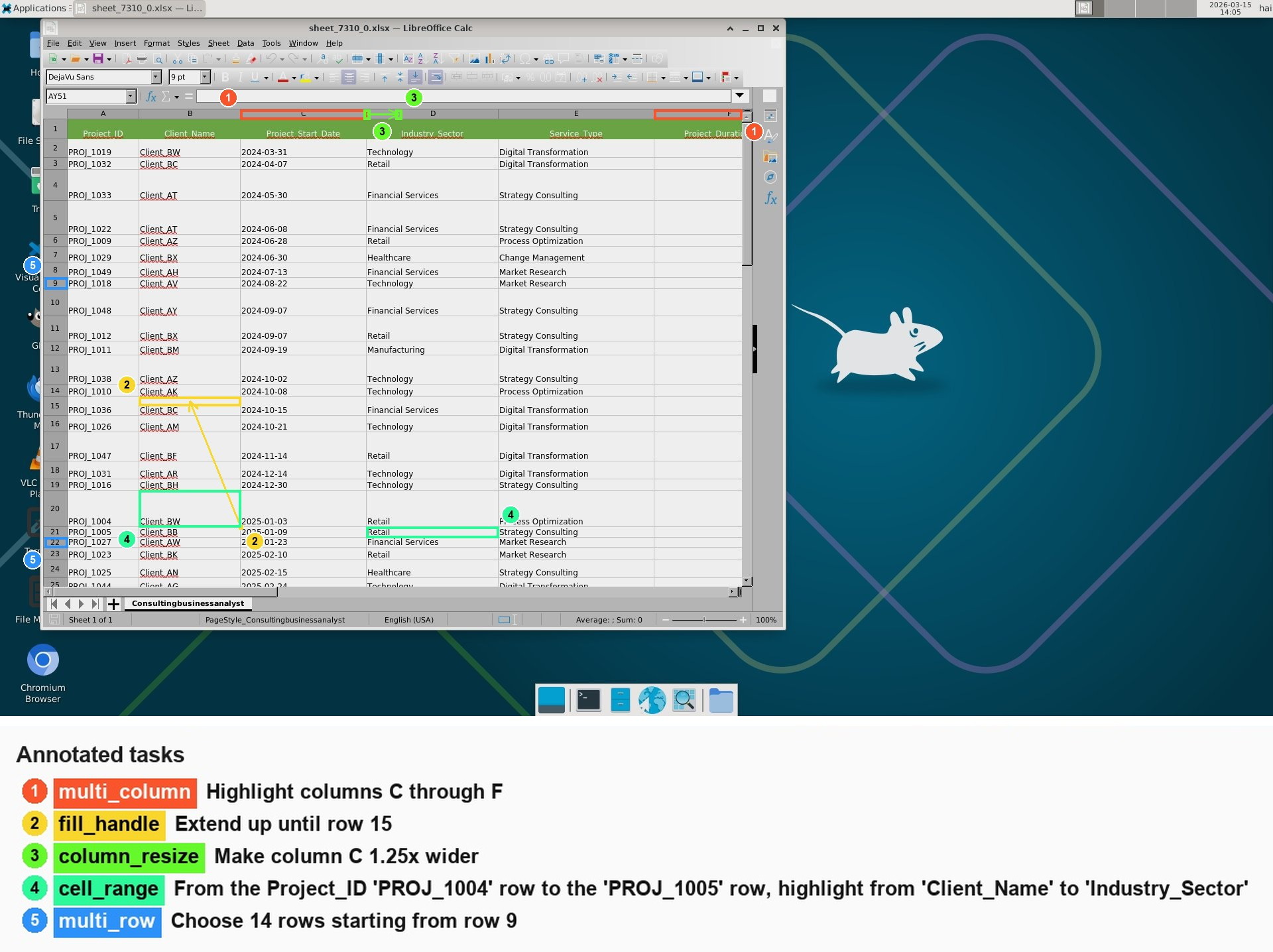
Fig 2: Representative drag actions from end-to-end agent benchmarks. The red arrow shows the executed drag overlaid on the

Fig 3 (page 2).
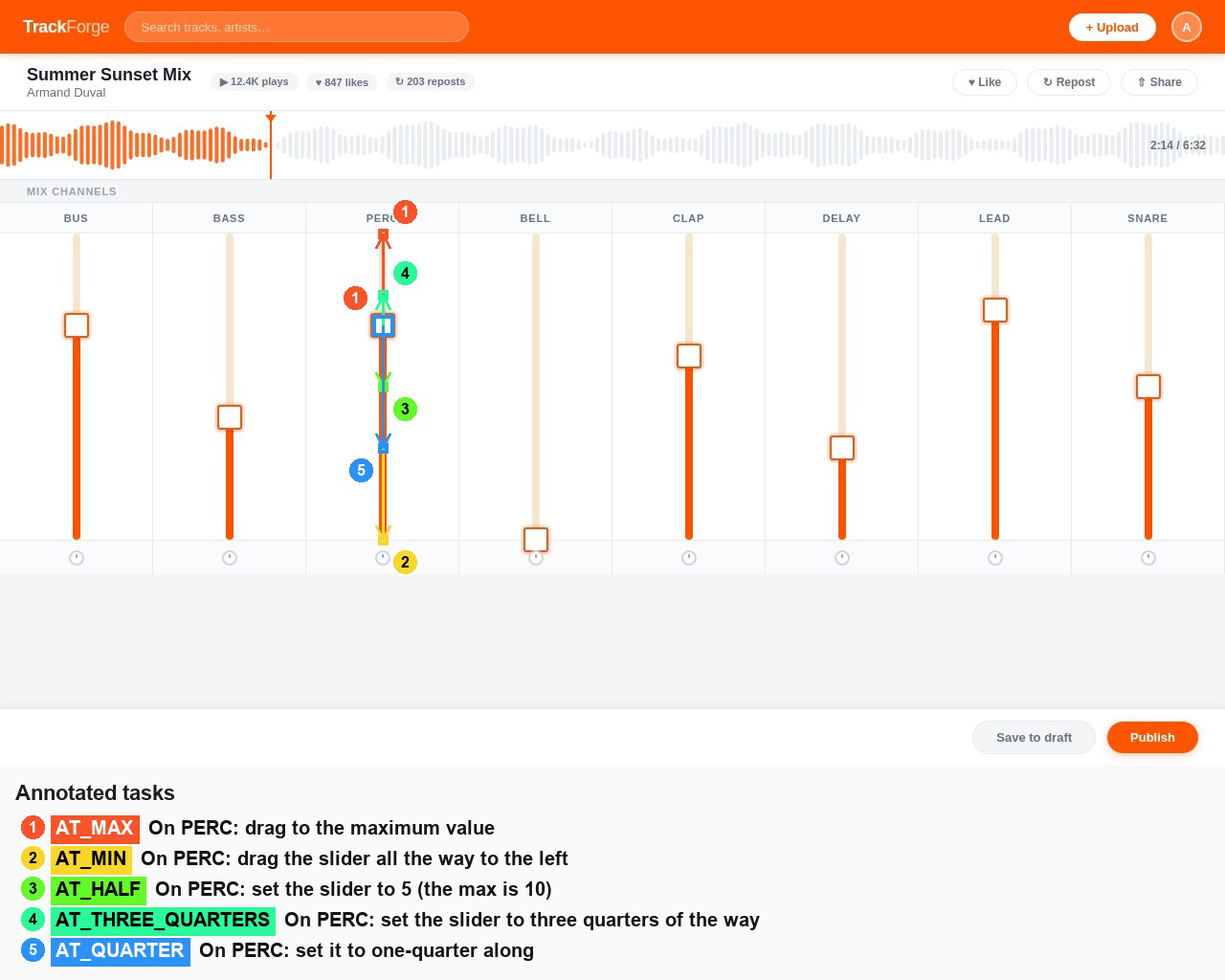
Fig 4 (page 2).
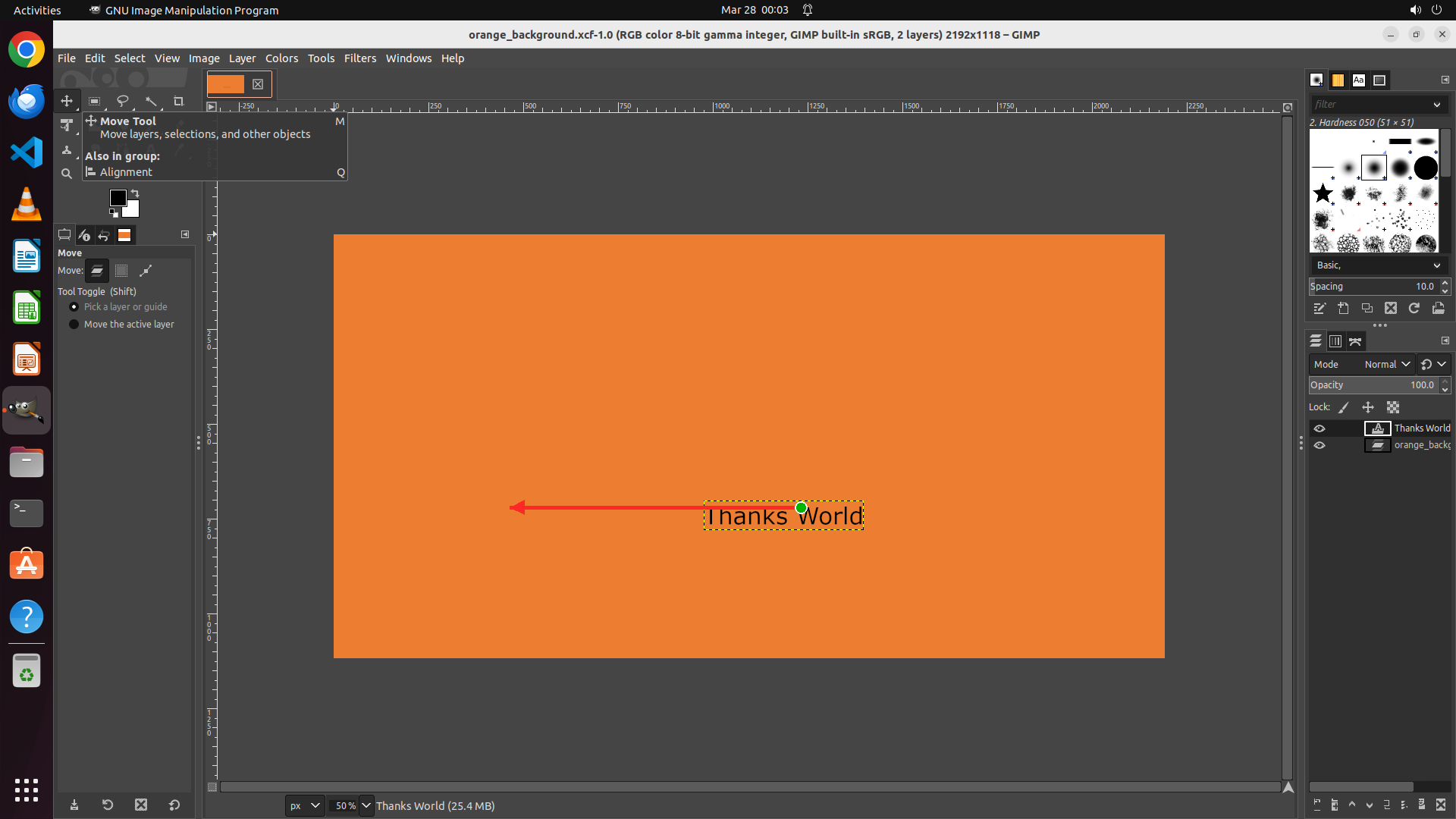
Fig 5 (page 4).
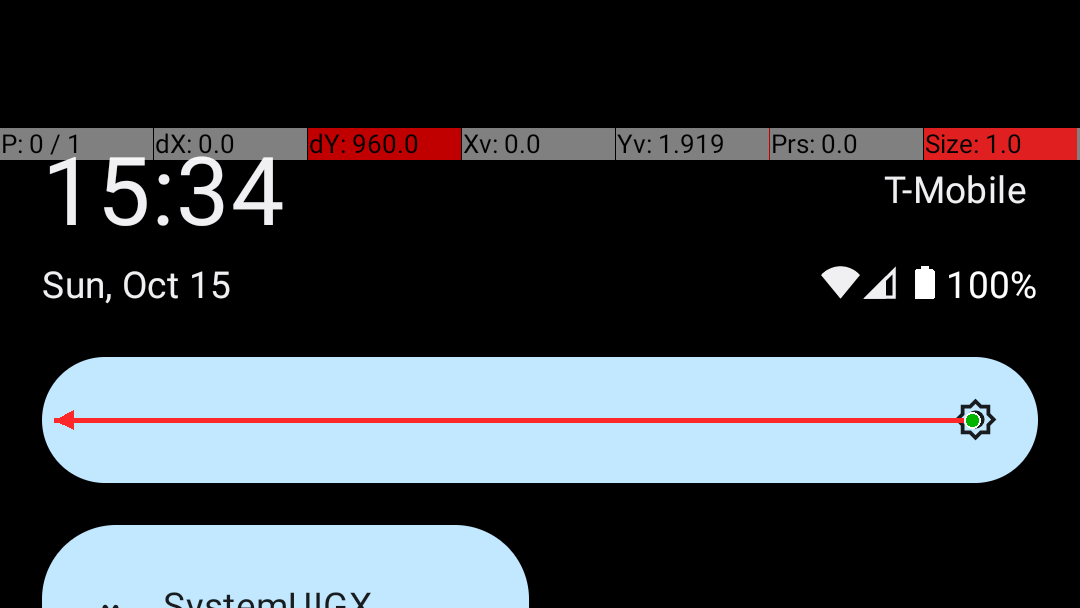
Fig 6 (page 4).
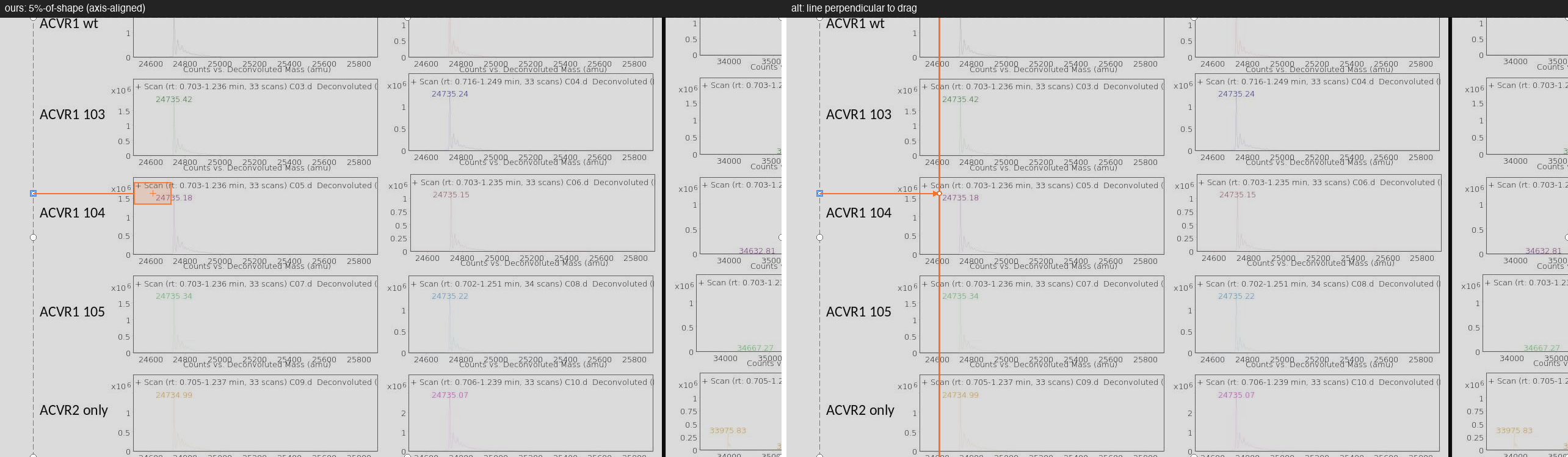
Fig 3: Canonical vs. alternative ground-truth target regions for actions with a continuum of valid drop points. We adopt the canonical
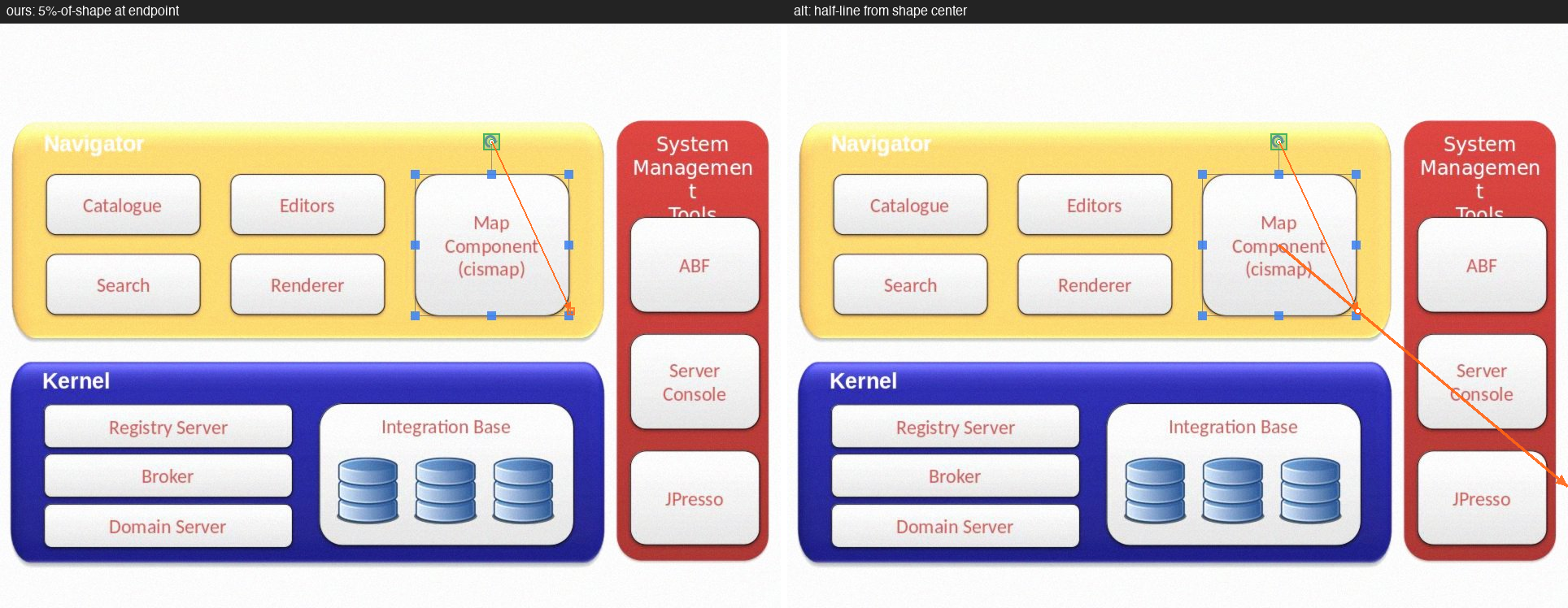
Fig 4: Qualitative end-to-end comparison on the OSWorld task libreoffice calc 19: the computer-use-specialized policy
Limitations
- Evaluation focuses on static two-point drag grounding, not continuous full drag trajectory prediction or closed-loop interaction.
- Performance on text highlighting and element resizing remains low (<35%) even after fine-tuning, indicating task difficulty.
- No thorough adversarial robustness or distribution shift evaluation, e.g. out-of-domain GUIs or noisy renderings.
- Dataset mainly covers four drag types, excluding other prevalent drag gestures like freehand drawing or multi-touch interactions.
- Element resizing evaluation uses a canonical target convention ignoring degrees of freedom which might limit interpreting near-misses.
- Open-source training relies on license-limited source data (Wikipedia, Zenodo PPTX); web and spreadsheet domains use synthetic or programmatic generation.
Open questions / follow-ons
- How can drag grounding be extended to continuous trajectory or closed-loop interactive scenarios beyond static two-point localization?
- Can drag grounding models generalize robustly to unseen applications, complex GUI themes, or noisy environments?
- What is the impact of incorporating temporal context or multi-modal signals (e.g., cursor dynamics, user history) on drag grounding accuracy?
- How to best represent degrees of freedom and inherent spatial tolerances in drag tasks for evaluation and training?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, DragOn highlights that drag-based GUI interactions remain a challenging frontier for current vision-language models, especially on complex tasks like text highlighting and element resizing. Since drag grounding performance is far from saturated, CAPTCHA or bot-detection systems leveraging drag gestures can exploit these weaknesses to design more robust bot-challenges. Moreover, the rendering-as-supervision data generation approach exemplifies how to efficiently create precise ground truth for subtle GUI manipulations, which can inspire improved training or evaluation pipelines for multi-step or continuous interaction bots. Lastly, the observed improvement from targeted fine-tuning on large, high-quality drag grounding datasets underscores the continuing importance of domain-specific data in advancing agent capabilities relevant to automated GUI control and detection.
Cite
@article{arxiv2606_06322,
title={ DragOn: A Benchmark and Dataset for Drag-Based GUI Interactions },
author={ Nathan Bout and Maxime Langevin and Ronan Riochet },
journal={arXiv preprint arXiv:2606.06322},
year={ 2026 },
url={https://arxiv.org/abs/2606.06322}
}