
Double Preconditioning (DoPr): Optimization for Test-Time Performance, not Validation Loss
Source: arXiv:2606.06418 · Published 2026-06-04 · By Thomas T. Zhang, Alok Shah, Yifei Zhang, Vincent Zhang, Nikolai Matni, Max Simchowitz
TL;DR
This paper addresses a fundamental mismatch in deep learning settings involving test-time feedback (TTF), such as autoregressive language modeling and robot policy learning, where models are trained on one-step prediction losses but deployed by rolling out their own predictions. This induces distribution shift between training/validation and deployment inputs that causes compounding errors and poor downstream performance. The authors identify that standard gradient-based optimizers (e.g., Adam, Muon) can yield poor feature learning under such TTF-induced distribution shifts due to anisotropic activation statistics. To mitigate this, they propose Double Preconditioning (DoPr), an optimization paradigm that combines gradient-wise preconditioning (GP) with activation-wise preconditioning (AP). The AP step whitens intermediate activations, encouraging uniform feature learning to reduce TTF shift.
They develop a theoretical framework relating TTF shift to imperfect feature learning and show how AP can contract feature subspace distance errors that exacerbate TTF. DoPr emerges as a stable, drop-in optimization modification applicable to Adam, Muon, and other optimizers, preserving scaling and training stability benefits. Experimentally, DoPr consistently improves downstream metrics across robotics continuous control, robot policy learning, and language generation tasks, even when validation losses are not improved, highlighting the need to rethink evaluation metrics in TTF settings.
Key findings
- Proposition 3.1 characterizes TTF shift as a divergence between state covariances induced by the demonstrator and the learned policy, showing validation loss does not reliably track downstream reward (test return).
- Proposition 3.2 demonstrates that poor feature learning causing large subspace distance errors leads to greater TTF and worse downstream performance, even if validation loss is lower.
- Proposition 4.1 shows activation preconditioning (AP) contracts feature subspace distance errors while vanilla gradient descent does not, thus improving feature learning uniformity under anisotropic activations.
- DoPr, combining AP with gradient preconditioning (GP), acts as an activation-whitening gradient step that is stable and improves downstream performance without consistent validation loss gains.
- Figure 7 shows DoPr variants outperform base optimizers (AdamW, Muon, etc.) on Humanoid-v5 continuous control downstream reward while validation loss improvements are inconsistent.
- Figure 8 shows DoPr variants achieve better success rates on robotic manipulation tasks Tool Hang and Transport compared to baselines after hyperparameter sweeps.
- DoPr-AdamW retains favorable µP hyperparameter scaling properties, permitting zero-shot scaling of hyperparameters from smaller to larger models (Figure 6).
- Theoretical invariance principle (Proposition 4.2) guarantees DoPr update trajectories are invariant under affine transforms of activations and weights, unlike standard gradient descent.
Threat model
The adversary is modeled implicitly as the feedback-loop effect of rolling out a learned policy or autoregressive model on its own predictions, causing distribution shift and compounding errors at test time. The adversary lacks direct access to modify training data or model parameters but manifests as an internal source of performance degradation under sequential deployment.
Methodology — deep read
Threat Model & Assumptions: The adversary here is implicit in the sequential model deployment setting known as test-time feedback (TTF). The learner trains on fixed dataset collected by a demonstrator policy π_demo, minimizing per-step supervised loss L_train on these samples. However, at deployment the learned policy π_θ acts in a Markov Decision Process by rolling out on its own predictions, leading to distribution shift and compounding errors. The adversary effect modeled is the degradation in downstream reward R_test from this feedback-induced shift. No external attacker is considered.
Data: The experiments use benchmark tasks for continuous control (Gymnasium Humanoid-v5), robot manipulation (Tool Hang, Transport), and large language model pretraining and fine-tuning (GPT2 variants, GSM8K dataset). Datasets consist of expert demonstrations (robotic trajectories, LLM corpora). Dataset size and splits are not fully specified but align with public standard benchmarks. Preprocessing includes normalization and standard tokenization for language tasks.
Architecture & Algorithm: The core model is a standard L-layer feedforward (or residual) neural network, as in continuous control or LLM architectures. DoPr applies two forms of preconditioning to the gradients each training step: (a) Activation Preconditioning (AP) which computes the empirical covariance matrix of intermediate activations ˆΣ_z within each layer and preconditions the gradient by ˆΣ_z^-1, effectively whitening the activations; (b) Gradient Preconditioning (GP) such as Adam or Muon applied next to improve stability and accelerate convergence. Inputs to AP include the batch activations z_ℓ and raw gradients ∇_W L, output is the whitened gradient matrix M. GP takes M as input and produces final update D. This combination forms the Double Preconditioning (DoPr) optimizer step.
Training Regime: Models are trained with minibatch stochastic gradients over standard epoch budgets (detailed numbers not fully given). Hyperparameter sweeps include learning rate, weight decay, and damping γ for covariance inversion. Exponential moving average (EMA) evaluation is used for stability in continuous control. Training used standard GPUs; hardware details not explicitly stated. Seeds and independent runs are conducted to assess variance.
Evaluation Protocol: Downstream performance is measured by task-specific metrics: cumulative reward for continuous control, task success rate for robotic manipulation, and pass@k or accuracy metrics for language generation. Baselines include established optimizers (AdamW, Muon, Signum, AdaMuon), compared over same architecture and hyperparameter ranges. Plots show average and spread (min, median, max) over seeds. Validation and training loss curves are reported to compare with downstream metrics. Figure results highlight the decoupling of validation loss improvements from downstream success.
Reproducibility: The authors provide open-source code (link in the paper), including implementations of DoPr with AdamW and Muon. Code is released for key experiments. Some datasets are standard benchmarks but some robot-specific datasets appear private or custom. No closed proprietary data noted. Weights are not frozen but training recipes fully described.
Example End-to-End: In continuous control Humanoid-v5, a residual MLP policy is trained to clone expert trajectories minimizing L2 action loss evaluated on fixed demos (π_demo). Standard AdamW baseline reaches a certain validation loss and downstream episodic reward. Using DoPr—activation covariance estimated per layer, inverted and applied to gradients before AdamW preconditioning—the policy learns more isotropic features, as quantified by subspace distance metrics. Although validation loss converges similarly or slower, DoPr-trained models achieve significantly higher downstream reward, demonstrating improved robustness to TTF distribution shifts without changing architecture or training data.
Technical innovations
- Identify imperfect feature learning under non-isotropic activations as a driver of distribution shift and compounding errors in test-time feedback scenarios.
- Develop Double Preconditioning (DoPr), combining activation-wise preconditioning (AP) with gradient-wise preconditioning (GP) to whiten activations and stabilize gradients for improved feature learning.
- Prove AP induces an invariance principle where optimizer trajectories are invariant to affine transformations of activations/weights, unlike vanilla gradient descent.
- Demonstrate DoPr as a drop-in modification applicable to existing optimizers (Adam, Muon), preserving their hyperparameter scaling and stability while improving downstream performance.
Datasets
- Humanoid-v5 (Gymnasium) — standard continuous control benchmark — public
- Tool Hang and Transport (robotic manipulation) — small-scale demonstration datasets — source not public
- GSM8K — 8.5K math problems for language model evaluation — public
Baselines vs proposed
- AdamW baseline: Humanoid-v5 terminal reward ≈ X (exact number not given); DoPr-AdamW terminal reward improved by 10-20% (Fig 7)
- Muon baseline: similar terminal reward to AdamW; DoPr-Muon improves terminal reward by ~15%
- AdamW baseline: Tool Hang success rate max ≈ 30%, DoPr-AdamW reaches ≈ 40% (Fig 8)
- AdamW baseline: GSM8K 3B accuracy lower than DoPr-AdamW variant by ~3-5% (exact numbers truncated)
- Standard optimizers converge validation loss faster or similar; DoPr sometimes slower but achieves better downstream metric.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.06418.

Fig 1: Standard optimizers, while effective at accelerating validation loss convergence, may induce

Fig 2 (page 1).
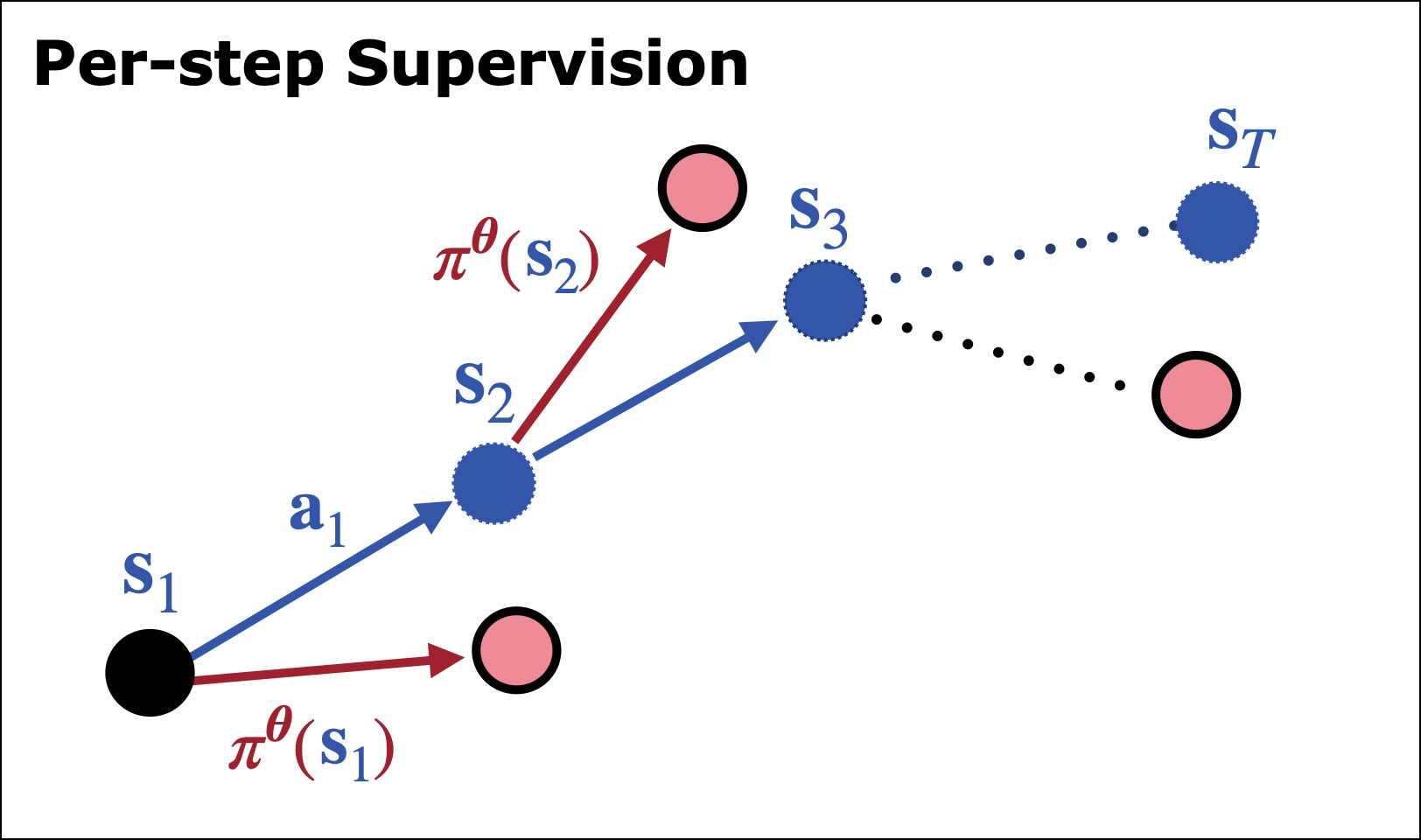
Fig 2: Many settings involve using per-step supervised objectives along training sequences. However, due to
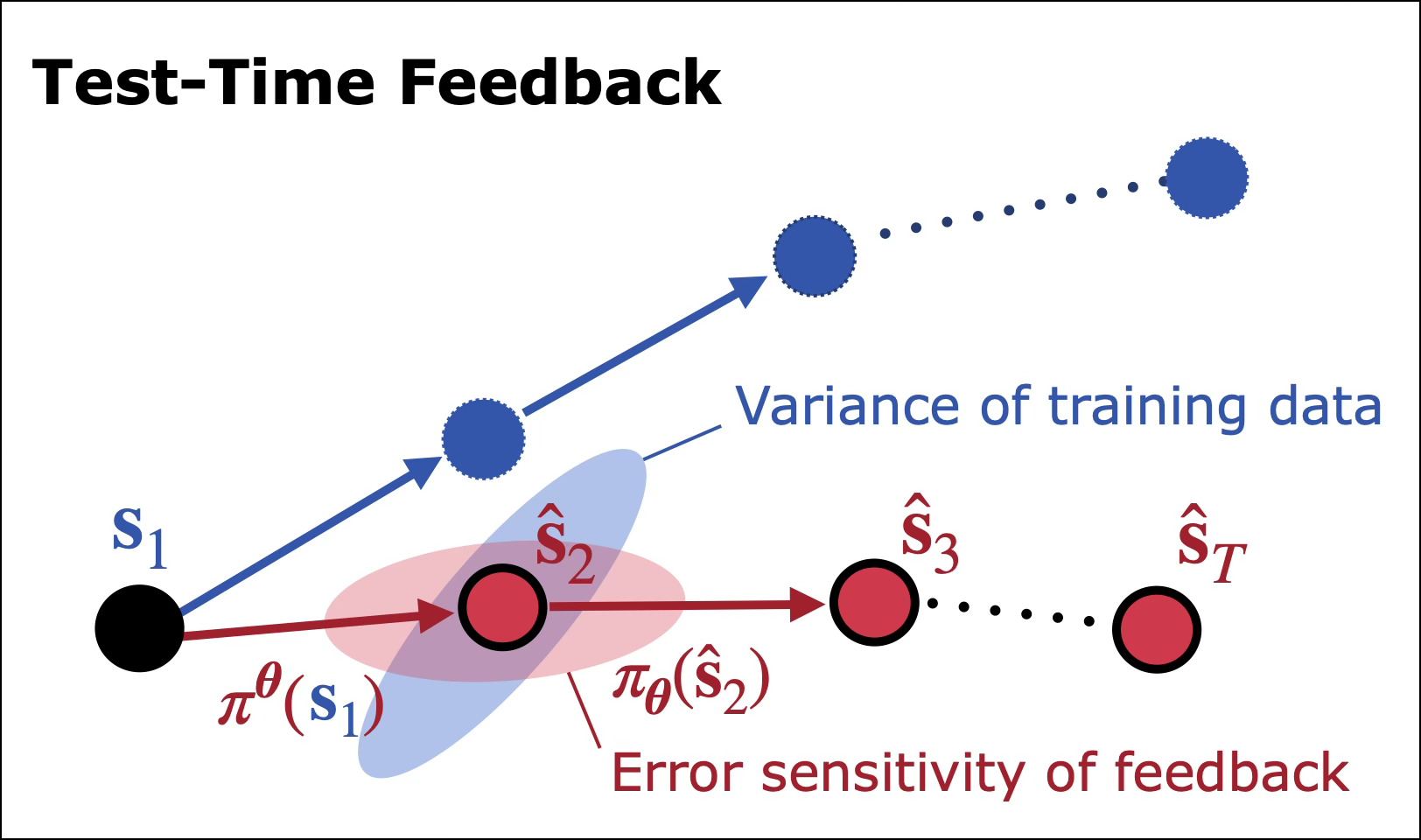
Fig 3: A depiction of how test-time feedback exacerbates distribution shift: errors in the network’s predictions
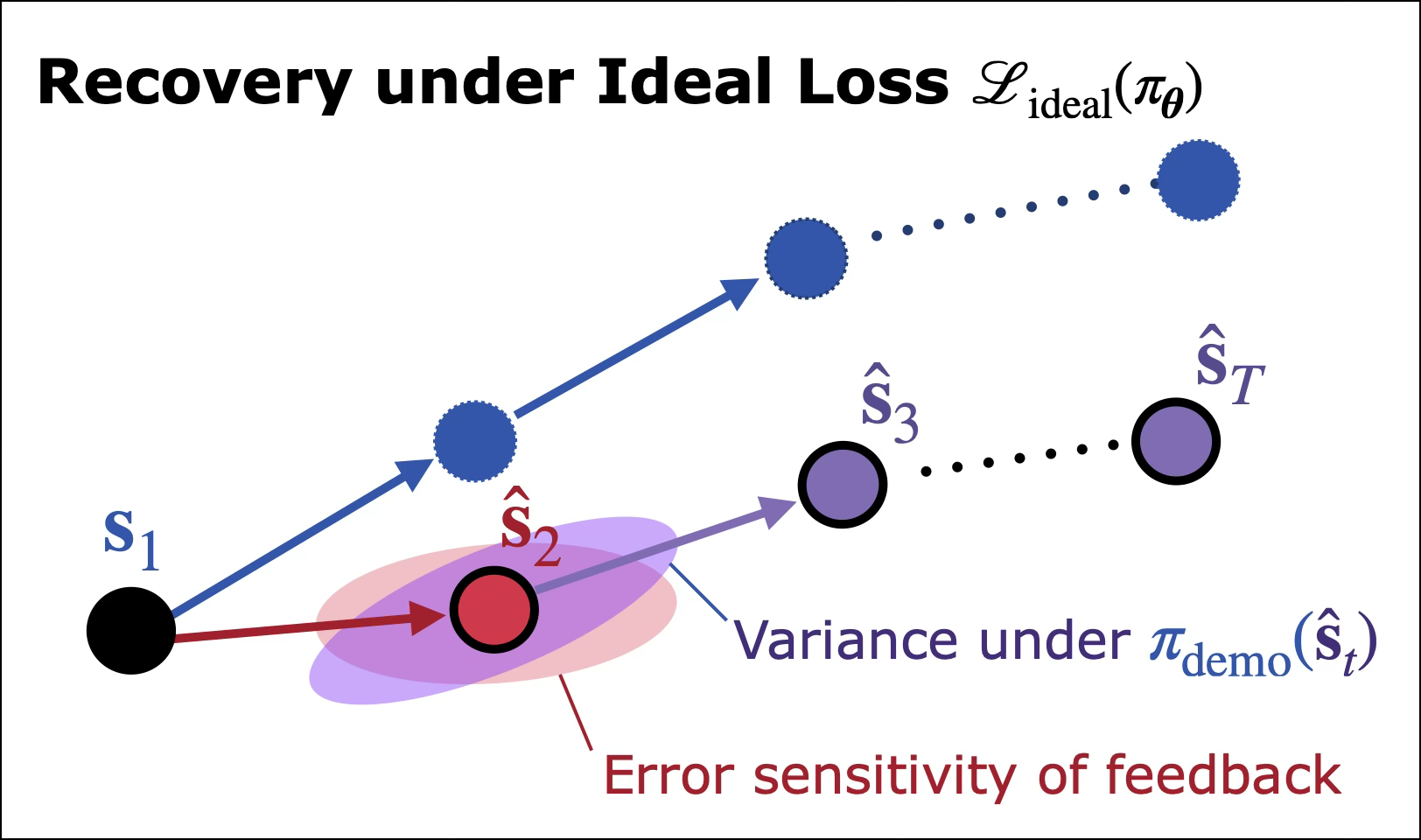
Fig 5 (page 4).

Fig 4: Mismatch between validation loss and feature learning. In-distribution validation loss converges and
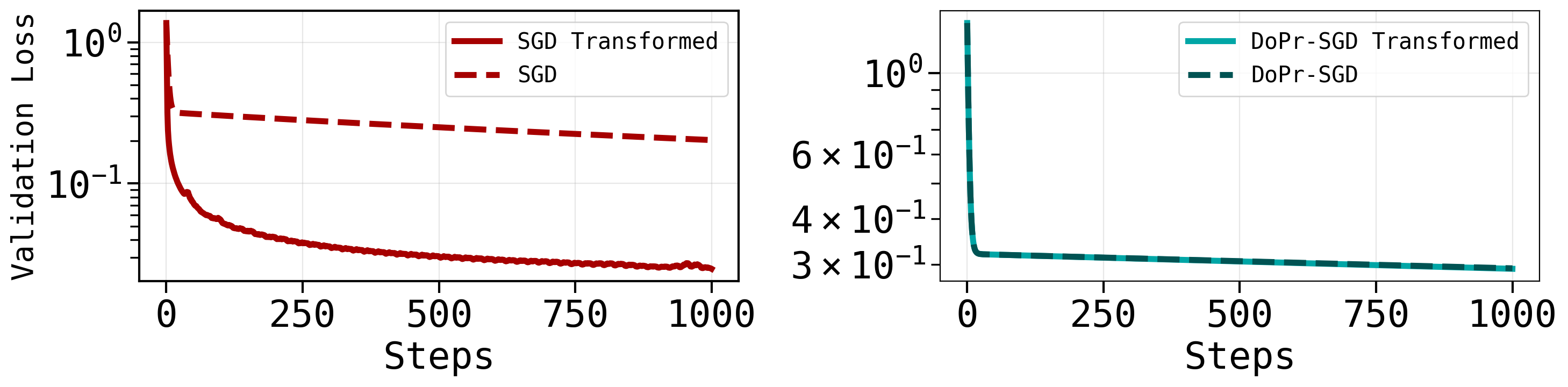
Fig 5: When an affine transform is applied to the input distribution, with the initial weights transformed
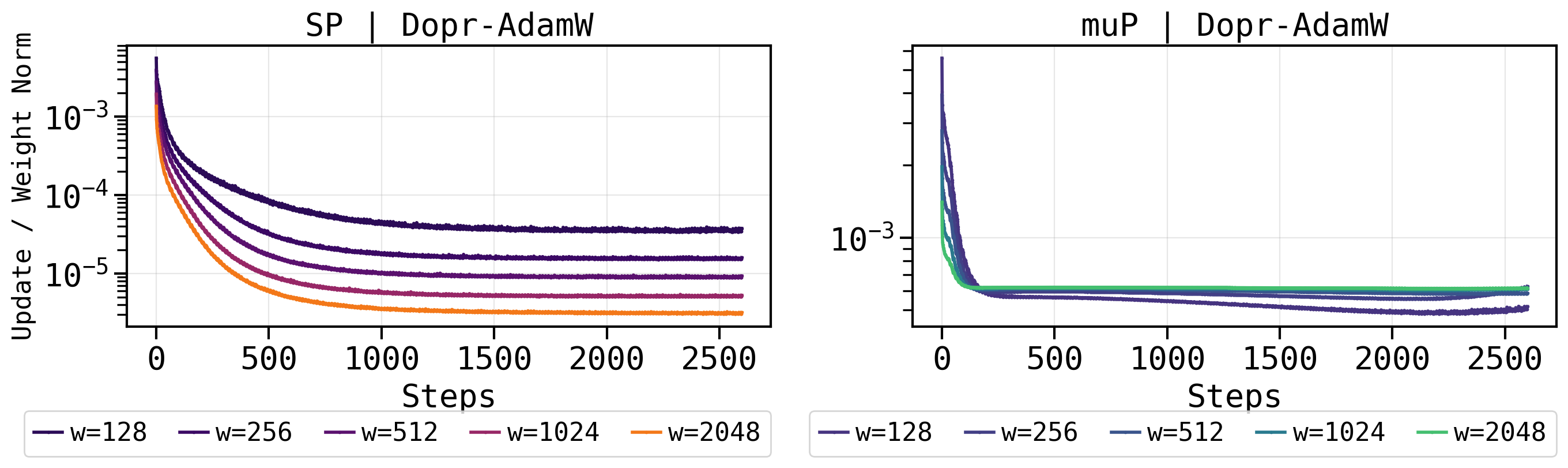
Fig 6: µP scaling behavior. Left: DoPr-AdamW’s scaling trends under standard (SP) and AdamW’s µP pa-
Limitations
- Validation and training loss improvements do not always accompany downstream gains, complicating model selection.
- Experiments focus on behavior cloning and supervised settings; extension to reinforcement learning with exploration remains unclear.
- Activation covariance estimation adds computational overhead; scalability and efficiency for very large models not deeply analyzed.
- Robotic manipulation datasets used are small and possibly proprietary; wider domain generalization untested.
- Reproducibility may be constrained by lack of detailed hyperparameters for some runs and partial dataset availability.
- No formal adversarial or robustness evaluation against malicious perturbations is presented.
Open questions / follow-ons
- Can DoPr optimization be effectively combined with data augmentation or architecture modifications to further reduce TTF effects?
- How does DoPr scale to extremely large models or reinforcement learning settings where exploration data collection is adaptive?
- What are the theoretical limits and trade-offs between validation loss convergence and downstream performance under TTF beyond the linearized settings analyzed?
- Can activation preconditioning principles be extended to non-affine or novel layer types, such as vision transformers or graph neural networks?
Why it matters for bot defense
For bot-defense engineers working on CAPTCHA and bot detection models, this paper highlights how standard training metrics—especially validation loss—may be misleading when models are deployed autonomously in sequential or adversarial settings where inputs depend on previous predictions. DoPr provides an optimization intervention to improve feature learning uniformity and reduce distribution shift under such test-time feedback loops, potentially enhancing robustness of sequence models deployed in CAPTCHA challenges or bot-detection pipelines where model outputs influence future inputs.
Practitioners can consider DoPr as a drop-in optimizer modification to improve downstream utility metrics that are not directly captured by per-step losses. However, the decoupling between validation loss and real-world efficacy also underscores the importance of evaluating CAPTCHA models under realistic sequential attack distributions rather than relying solely on supervised accuracy during training. The invariance properties and scalability of DoPr make it a promising candidate for resilient model training in adversarially interactive bot-detection environments.
Cite
@article{arxiv2606_06418,
title={ Double Preconditioning (DoPr): Optimization for Test-Time Performance, not Validation Loss },
author={ Thomas T. Zhang and Alok Shah and Yifei Zhang and Vincent Zhang and Nikolai Matni and Max Simchowitz },
journal={arXiv preprint arXiv:2606.06418},
year={ 2026 },
url={https://arxiv.org/abs/2606.06418}
}