
Boosting Brain-to-Image Decoding with TRIBE v2 Data Augmentation
Source: arXiv:2606.06345 · Published 2026-06-04 · By Yohann Benchetrit, Marlène Careil, Simon Dahan, Hubert Banville, Stéphane d'Ascoli, Jean-Rémi King
TL;DR
This paper addresses the critical limitation in brain-to-image decoding imposed by the scarcity of labeled fMRI data. Existing decoding methods need large subject-specific datasets, which are expensive and time-consuming to collect, hindering practical applications. The authors propose a model-based, stimulus-conditioned data augmentation approach leveraging TRIBE v2, a large-scale pretrained fMRI encoding model trained on over 1000 hours of naturalistic multimodal stimuli. TRIBE v2 predicts synthetic fMRI responses to novel images, which are then used as additional training data for decoders learning to map fMRI signals back to image embeddings. The method systematically explores how varying the fraction of real fMRI data and the amount of augmentation affect decoding accuracy.
Experiments on two benchmark datasets, the Natural Scenes Dataset (NSD, 7T) and BOLD5000 (3T), show up to 68% improvement in Top-10 image retrieval accuracy when augmenting low- and medium-data regimes with TRIBE-generated synthetic fMRI. Notably, decoders trained solely on synthetic fMRI achieve above-chance retrieval in some settings, indicating TRIBE’s ability to support zero-shot brain-to-image decoding. Gains depend critically on real-to-synthetic data ratios and decoder model choice, with excessive synthetic augmentation causing performance saturation or degradation. The augmentation pipeline also improves image reconstruction quality with generative models. These results demonstrate that large-scale multimodal fMRI encoding models like TRIBE v2 can substantially improve data efficiency for brain decoding while highlighting the need for calibration of synthetic data use.
Key findings
- TRIBE v2 synthetic augmentation improves Top-10 image retrieval by up to 68% in low-data regimes compared to real-only training (NSD and BOLD5000 datasets).
- On NSD, 90% of full-data accuracy can be reached with only 50% of real data when augmented with 4x synthetic data, cutting scan time roughly in half.
- On BOLD5000, 90% of full-data accuracy is reached with 10-30% of real data plus synthetic, representing ~9 hours saved per subject.
- Augmentation benefits saturate and decline if synthetic data fraction is too high (typically above 8x for Ridge and 4x for Deep decoders).
- Decoders trained exclusively on synthetic fMRI achieve above-chance image retrieval on BOLD5000 and with deep decoders on NSD.
- TRIBE synthetic fMRI outperforms noise controls, confirming gains come from stimulus-dependent signal rather than increased training data volume alone.
- Deep decoders benefit less uniformly and require smaller synthetic augmentation ratios than linear Ridge models.
- TRIBE augmentation also improves image reconstruction metrics (PixCorr increased ~2.5x) using the DynaDiff generative model on NSD.
Threat model
n/a — This paper does not address adversarial threat models or security scenarios but rather proposes a data augmentation method for brain decoding models.
Methodology — deep read
Threat Model & Assumptions: The adversary is not explicitly defined as this is a model augmentation study for brain decoding, but key assumptions include: access to small labeled real fMRI datasets per subject, and ability to generate synthetic fMRI responses from an average-subject pretrained encoding model (TRIBE v2) with no subject-specific adaptation. Decoding is performed on held-out real fMRI.
Data: The authors use two open fMRI datasets: (a) NSD (7T, high-res, 4 fully-scanned subjects, ~9000 training images each, ~1000 test images), and (b) BOLD5000 (3T, 4 subjects, ~4900 unique training images, 112 test images). Real fMRI is preprocessed to cortical surface fsaverage5 space. One trial per image is retained to avoid repetition imbalance. Synthetic fMRI is generated by running TRIBE v2 on a pool of COCO images unseen by target subjects.
Architecture/Algorithm: TRIBE v2 is a large-scale multimodal fMRI encoding model predicting 1 Hz cortical BOLD responses to video, audio and language. Static images are converted to 3s static video clips to input to TRIBE’s visual pathway. Synthetic fMRI responses are truncated to a single time point and aligned to real data resolution. Decoders map fMRI inputs to DINOv2-small image embeddings. Two decoder types are used: (a) linear Ridge regression with cross-validation and regularization, and (b) a residual MLP deep decoder trained with a CLIP-style contrastive retrieval loss. A DynaDiff diffusion generative model reconstructs images from decoded embeddings for a subset of experiments.
Training Regime: Decoders are trained separately for each subject. Real training data fraction p ranges from 10% to 100%, and synthetic augmentation factor a ranges from 0 to 16 times the size of real data. Models are trained with up to 40 epochs, AdamW optimizer (LR 5e-4 deep, tuned alphas ridge), early stopping, 20% validation split. Multiple random seeds average results.
Evaluation Protocol: Decoders are evaluated on held-out real fMRI test sets. Primary metric is Top-K image retrieval accuracy (Top-10) using cosine similarity between predicted and actual image embeddings. Median retrieval rank also reported. Reconstruction quality evaluated by PixCorr and semantic similarity metrics (SwAV, EfficientNet). Controls with noise-augmented synthetic data verify gains come from actual stimulus-dependent synthetic fMRI not random noise.
Reproducibility: TRIBE v2 and datasets used are public or established; code and training details are described but code availability not explicitly stated. Experiments are repeated over multiple subjects and seeds. Operating grids systematically explore a range of real & synthetic data proportions.
Example end-to-end: For NSD subject 5, the authors select 50% of real training pairs and augment with 4x synthetic pairs generated from COCO images via TRIBE v2. The ridge decoder maps these 50% + synthetic fMRI to DINOv2 embeddings trained for retrieval. Evaluated on held-out real fMRI test set, the augmented decoder achieves near 90% accuracy of full 100% real-only baseline, demonstrating substantial scan time reduction.
Technical innovations
- Use of TRIBE v2, a large-scale pretrained multimodal fMRI encoding model, as a stimulus-conditioned synthetic fMRI data generator for data augmentation in brain decoding.
- Systematic operating grids exploring decoder performance as a function of real data fraction and synthetic-to-real data augmentation ratio to identify regimes of performance gain and saturation.
- Application of out-of-distribution TRIBE v2 predictions (trained on dynamic videos) to static image stimuli by short static video conversion.
- Empirical demonstration that synthetic fMRI-based augmentation can enable zero-shot brain-to-image decoding above chance without real training data.
- Integration of TRIBE synthetic augmentation with both simple linear Ridge and more complex deep contrastive retriever decoders, and extension to image reconstruction tasks.
Datasets
- Natural Scenes Dataset (NSD) — ~9000 training + 1000 test images per subject (4 subjects) — 7T fMRI whole-brain data
- BOLD5000 — ~4900 training + 112 test images per subject (4 subjects) — 3T fMRI
- COCO images — large pool used to generate synthetic fMRI via TRIBE v2 (excluded overlap with subject stimuli)
Baselines vs proposed
- NSD Ridge decoder: 100% real-only Top-10 retrieval baseline ~100%, augmented with 50% real + 4x synthetic achieves ~90% baseline accuracy (∼68% relative gain over 50% real-only).
- BOLD5000 Ridge decoder: 100% real-only baseline ~100%, augmented with 10% real + 8x synthetic achieves ~90% baseline, 9 hours scan time saved per subject.
- Noise-augmented control at 10% real + 8x synthetic yields lower retrieval accuracy than TRIBE synthetic augmentation, showing augmentation signal is stimulus-dependent.
- Deep decoders show smaller but consistent gains; TRIBE augmentation at 30% real + 4x synthetic produces largest relative improvements (~up to 40%).
- 100% synthetic-only Ridge decoder retrieval remains at chance for NSD but above chance for BOLD5000; Deep decoder retrieval above chance for both datasets.
- Image reconstruction with DynaDiff on NSD improves PixCorr from 0.06 to 0.16 at augmentation factor a=1.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.06345.
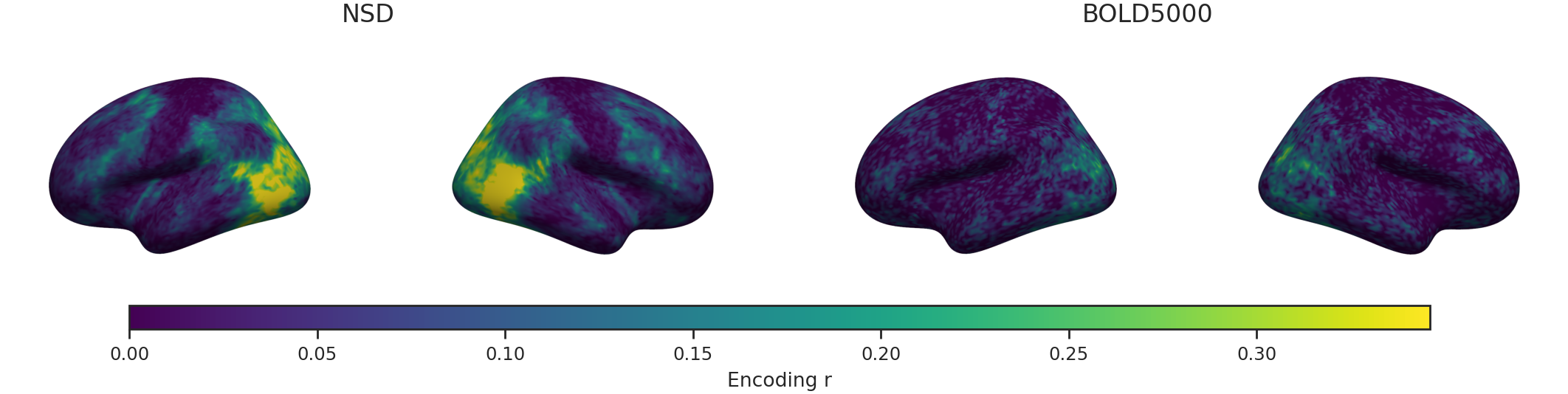
Fig 1: TRIBE v2 image-conditioned fMRI augmentation and target-embedding neural signal. (a) For each subject and

Fig 2: Operating grids for TRIBE augmentation using Ridge decoders. A. Top-10 retrieval accuracy normalized to the

Fig 3: Operating grids for TRIBE augmentation using Deep decoders. The operating grids as in Figure 2 are computed

Fig 4: Image reconstruction metrics on NSD with Dynadiff. Similar to image decoding, TRIBE boosts results up to a

Fig 5 (page 6).

Fig 6 (page 7).
Fig 7 (page 7).

Fig 8 (page 7).
Limitations
- TRIBE synthetic fMRI represents an average-subject brain response without subject-specific adaptation, limiting augmentation effectiveness.
- Synthesizing static image fMRI from a model trained on naturalistic videos is out-of-distribution, possibly explaining augmentation benefit saturation.
- Datasets used have few subjects (4 per dataset), limiting generalizability and requiring validation on larger or more diverse cohorts.
- Decoding evaluated only on within-subject held-out test data; cross-subject or adversarial robustness not addressed.
- Benefits depend strongly on decoder architecture and dataset, making calibration essential but non-trivial.
- Code release and pretrained decoder weights availability unclear, making reproduction and extension more challenging.
Open questions / follow-ons
- Can subject-specific TRIBE adaptation or fine-tuning further improve augmentation effectiveness by capturing idiosyncratic neural responses?
- How well does TRIBE-based augmentation generalize to other neural decoding modalities beyond visual image stimuli, such as language or audio decoding?
- Can joint multi-subject decoder pretraining with synthetic augmentation improve robustness and reduce reliance on large real datasets?
- What are the limits of zero-shot decoding with synthetic-only fMRI data generated by encoding models trained on naturalistic inputs?
Why it matters for bot defense
This work highlights how synthetic data generated by large pretrained models can address data scarcity in complex neural decoding tasks. For bot-defense and CAPTCHA practitioners, it underscores the promise and challenges of leveraging synthetic biometric or neural signals for training attacks or defenses in low-data regimes. The demonstrated critical dependence on data quality, composition ratios, and decoder architecture provides a cautionary note on blindly applying synthetic augmentation. While fMRI decoding is far from real-time CAPTCHA verification, principles of model-conditioned synthetic data generation and calibration may inform future designs of neuro-inspired or behavioral challenge-response tests. Importantly, the paper shows that synthetic signals trained on average populations have limitations due to lack of individual heterogeneity, which resonates with challenges in distinguishing authentic human users from bots based on neurological or physiological signals. Overall, the approach advocates for carefully calibrated synthetic augmentation and operating regime analysis to effectively boost model performance under data constraints.
Cite
@article{arxiv2606_06345,
title={ Boosting Brain-to-Image Decoding with TRIBE v2 Data Augmentation },
author={ Yohann Benchetrit and Marlène Careil and Simon Dahan and Hubert Banville and Stéphane d'Ascoli and Jean-Rémi King },
journal={arXiv preprint arXiv:2606.06345},
year={ 2026 },
url={https://arxiv.org/abs/2606.06345}
}