
Asuka-Bench: Benchmarking Code Agents on Underspecified User Intent and Multi-Round Refinement
Source: arXiv:2606.05920 · Published 2026-06-04 · By Xin Wang, Liangtai Sun, Yaoming Zhu, Shuang Zhou, Jiaxing Liu, Fengjiao Chen et al.
TL;DR
Asuka-Bench addresses a critical gap in existing code-generation benchmarks by focusing on iterative, multi-round refinement from underspecified user intents rather than one-shot perfect specification to output mappings. This benchmark simulates real-world web development scenarios where users begin with vague requests and progressively clarify requirements based on seeing intermediate results. It implements a closed evaluation loop involving a Code Agent generating web projects, a UI Agent running automated browser-based tests on the deployed projects, and a User LLM synthesizing natural-language feedback guiding subsequent refinements. The dataset includes 50 diverse web development tasks with 784 evaluation criteria covering presence, functionality, and robustness.
The benchmark evaluates 8 state-of-the-art large language models (LLMs) across two distinct agent frameworks and clearly differentiates their performance, evidencing up to a 38 percentage point spread in weighted Task Pass Rate after three refinement rounds. Iterative refinement delivers substantial gains, especially between rounds 1 and 2, and even the strongest models complete just over half of projects fully within three iterations, indicating substantial room for improvement. A human study confirms the evaluation system’s close alignment with expert judgments (93.35% accuracy). Overall, Asuka-Bench moves beyond static evaluation to measuring how well models incorporate simulation-grounded user feedback and converge toward fully functional web applications in practice.
Key findings
- Asuka-Bench evaluates 50 web tasks spanning 6 categories, with a total of 784 evaluation tasks and 2,402 expected outcomes featuring a DAG dependency structure.
- Weighted Task Pass Rate among 13 model-framework combinations varies by 38 percentage points after three rounds, ranging from 51.8% to 90.1%.
- Project Completion Rate (all tasks passed) peaks at only 52% after 3 rounds, highlighting difficulty of full task coverage.
- Iterative refinement yields large gains: round 2 improves weighted Task Pass Rate by ~25 percentage points on average, round 3 adds 7-13 points, with no saturation by round 3.
- Multi-round runs on underspecified queries outperform single-round attempts on fully clarified PRDs, with net gains of 8.7–26.6 percentage points after 3 rounds.
- The gap between tasks attempted and passed measures repair-from-feedback ability; stronger models close this gap faster across rounds.
- Human evaluator agreement for the automated browser-driven evaluation is 93.35% accuracy and 96.52% F1 score compared to expert labels.
- Extending rounds to 8 with the strongest model achieves 100% weighted Task Pass Rate and Project Completion Rate, confirming task solvability.
Threat model
The adversary model is implicit: the system models typical real-world users who provide initially underspecified, ambiguous requests and iteratively provide feedback based on observed outputs. There is no adversary attempting sabotage or evasion. The Code Agent must interpret natural-language feedback within the bounds of the system to arrive at a correct implementation. The evaluation assumes no direct database or backend manipulation and does not consider malicious inputs or compromised agents.
Methodology — deep read
The core innovation is a closed-loop evaluation framework that captures the iterative nature of real web development from underspecified requests. The threat model assumes a user initiating web app generation with vague high-level goals; the Code Agent produces initial code, which is deployed and tested in-browser by a UI Agent; failures generate natural language feedback via a User LLM, forming a loop that continues until requirements are met or iteration limits reached. This simulates realistic interaction without adversarial intent.
Data provenance includes 50 curated tasks from three sources: real user queries from a production web development platform (de-identified), open-source GitHub projects reformulated into queries, and summarizations of existing feature-rich websites. Each task is paired with a detailed Clarified PRD (human- and LLM-assisted rewrite into hierarchical specs) and a deliberately underspecified query used as the sole input to agents. Simulated frontend-only data supports isolated testing.
Evaluation criteria are hierarchically structured natural-language test cases grouped in a Directed Acyclic Graph (DAG) encoding dependencies between presence, functionality, and robustness tasks. The UI Agent is an autonomous web navigation module that executes criteria as browser interactions (clicks, inputs, inspections), returning binary pass/fail results with explanations. The User LLM synthesizes these results into structured, natural-language feedback sent to the Code Agent.
Code Agent backbones include eight state-of-the-art LLMs (GPT-5.4, Gemini-3.1-Pro, Claude-4.6-Sonnet, GLM-5, Kimi-K2.6, Seed-2.0-Pro, MiniMax-M2.7, Qwen3.5-Plus) integrated within either the OpenHands or Claude Code agent frameworks, which orchestrate tool calls, file management, and execution workflows. Evaluation runs up to 3 refinement rounds, with round-based feedback and code regeneration. Hardware, hyperparameters, and seeds are detailed in appendices (not fully specified here).
Metrics include Project Completion Rate (fraction of projects with all tasks passed), cumulative weighted Task Pass Rate (task-level weighted pass fraction accounting for difficulty), and weighted Criteria Pass Rate (soft measure of partial criterion success). Evaluation is DAG-aware: only tasks passing prerequisite dependencies run, avoiding cascading failures and focusing feedback on root causes.
Reproducibility is partially supported with an open-source agent (OpenHands); however, dataset details and User LLM implementations use proprietary or closed components (e.g., GPT-5.4). The evaluation framework includes automated tooling for deployment, testing, and feedback generation. The dataset’s full refresh and contamination control are future work.
A concrete example: given an underspecified query like “Build an e-commerce site with product list and cart,” the Code Agent produces an initial site, the UI Agent runs presence checks (elements exist), functionality tests (SKU-price linkage), and robustness tests (handle out of stock), returns binary results to the User LLM, which crafts instructions like “Price display does not update on SKU change, fix this,” guiding the Code Agent’s revised implementation, iterating up to 3 rounds or until criteria are all met.
Technical innovations
- Closed-loop evaluation design involving Code Agent generation, UI Agent browser-grounded test execution, and User LLM feedback synthesis for iterative code refinement.
- DAG-aware evaluation protocol enforcing prerequisite dependencies among test tasks, focusing feedback on root causes and reducing wasteful or misleading error signals.
- Benchmarking from underspecified user queries rather than fully specified PRDs, modeling realistic web development workflows with incremental clarification.
- Automatic generation of hierarchical, weighted evaluation criteria covering presence, functionality, and robustness grounded in browser-rendered behaviors.
Datasets
- Asuka-Bench — 50 web development tasks, 784 evaluation tasks, 2,402 expected outcomes — collected from production user data, GitHub repos, and existing websites, with simulated frontend-only data
Baselines vs proposed
- Seed-2.0-Pro on OpenHands: weighted Task Pass Rate after 3 rounds = 53.7% vs GPT-5.4 on OpenHands = 90.1%
- Claude-4.6-Sonnet on OpenHands: Project Completion Rate = 46% vs GPT-5.4 on OpenHands = 52%
- GLM-5 on Claude Code: weighted Task Pass Rate R3 = 76.6% vs Qwen3.5-Plus = 70.1%
- Iterative refinement on underspecified queries improves weighted Task Pass Rate by 8.7–26.6 pp vs single-round on full PRD across models
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.05920.
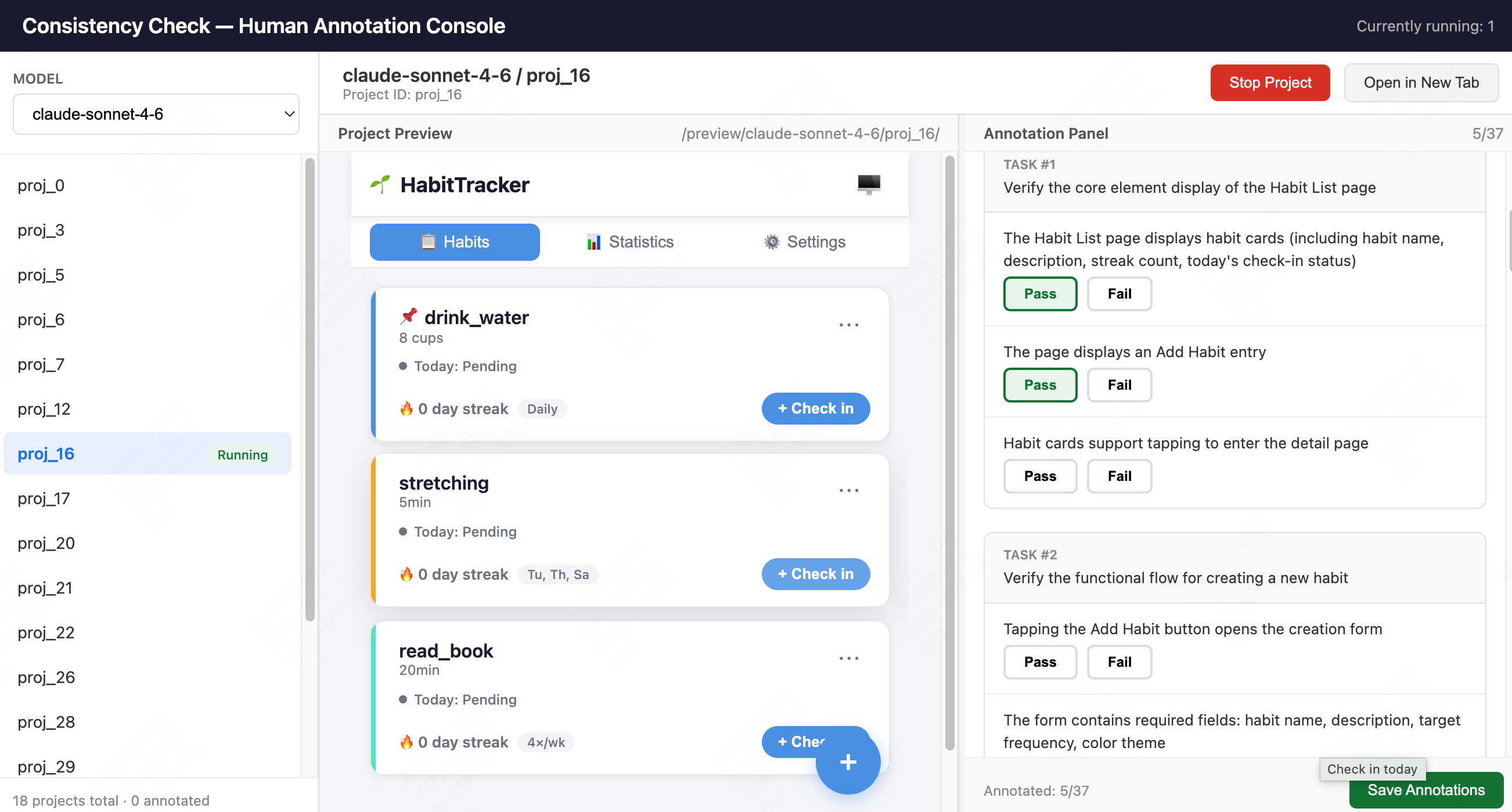
Fig 7: The web-based annotation console used by human annotators. The deployed project under evaluation is
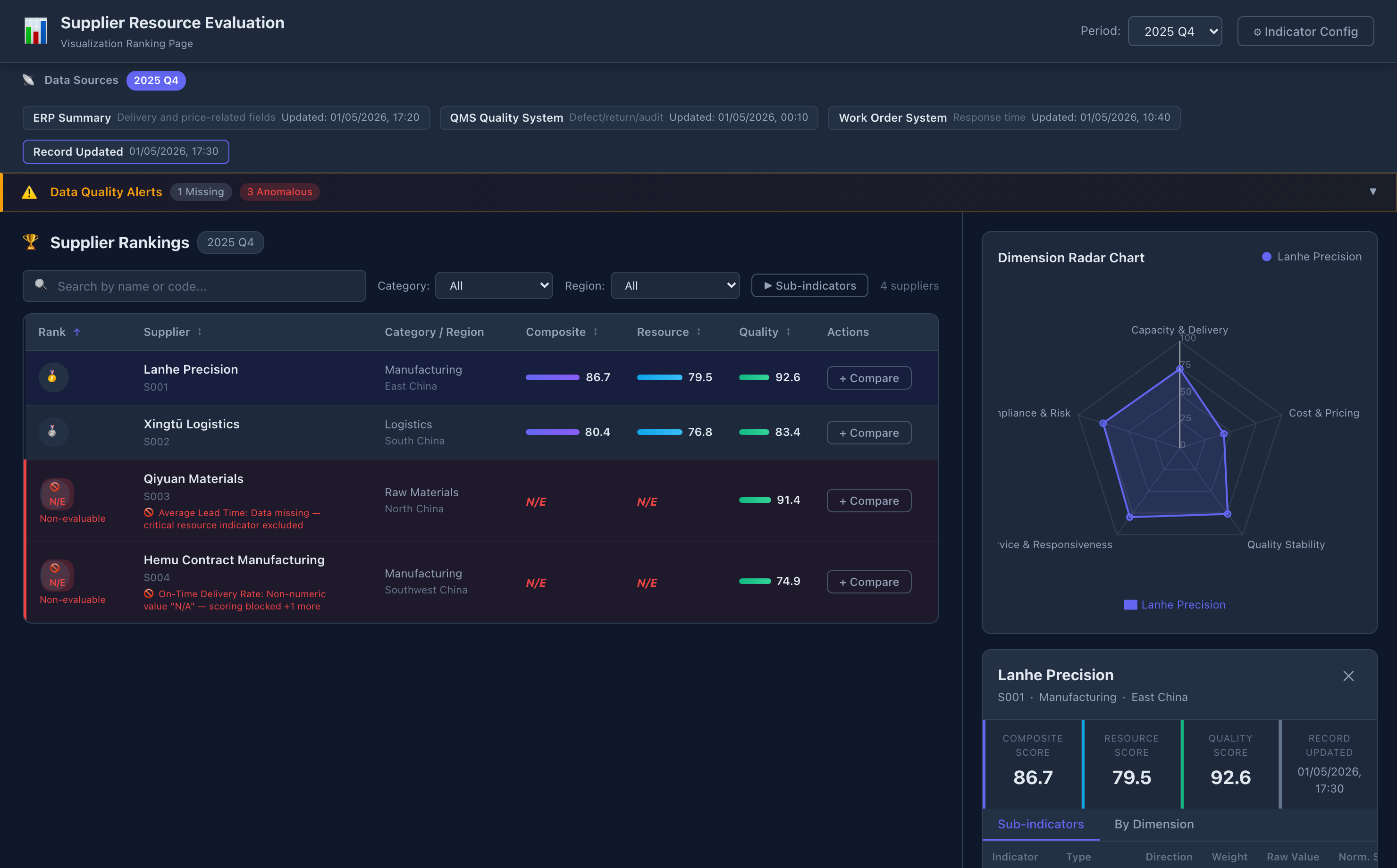
Fig 13: Successful implementation of the case-study PRD by Claude-4.6-Sonnet after three rounds of feedback.
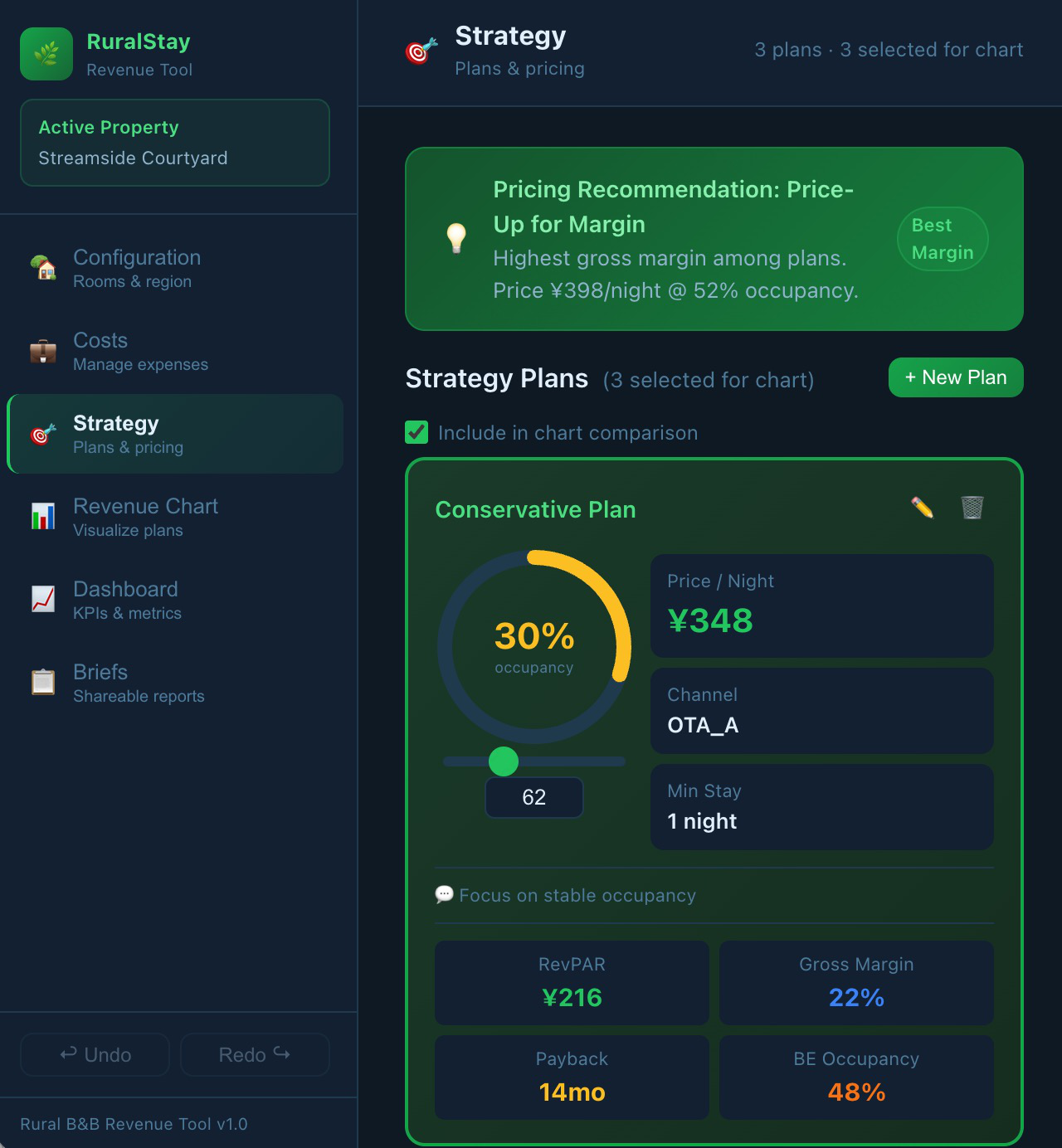
Fig 14: Progressive repair on the Rural-Stay Revenue Strategy Tool (Claude-4.6-Sonnet). v1 (left) shows four
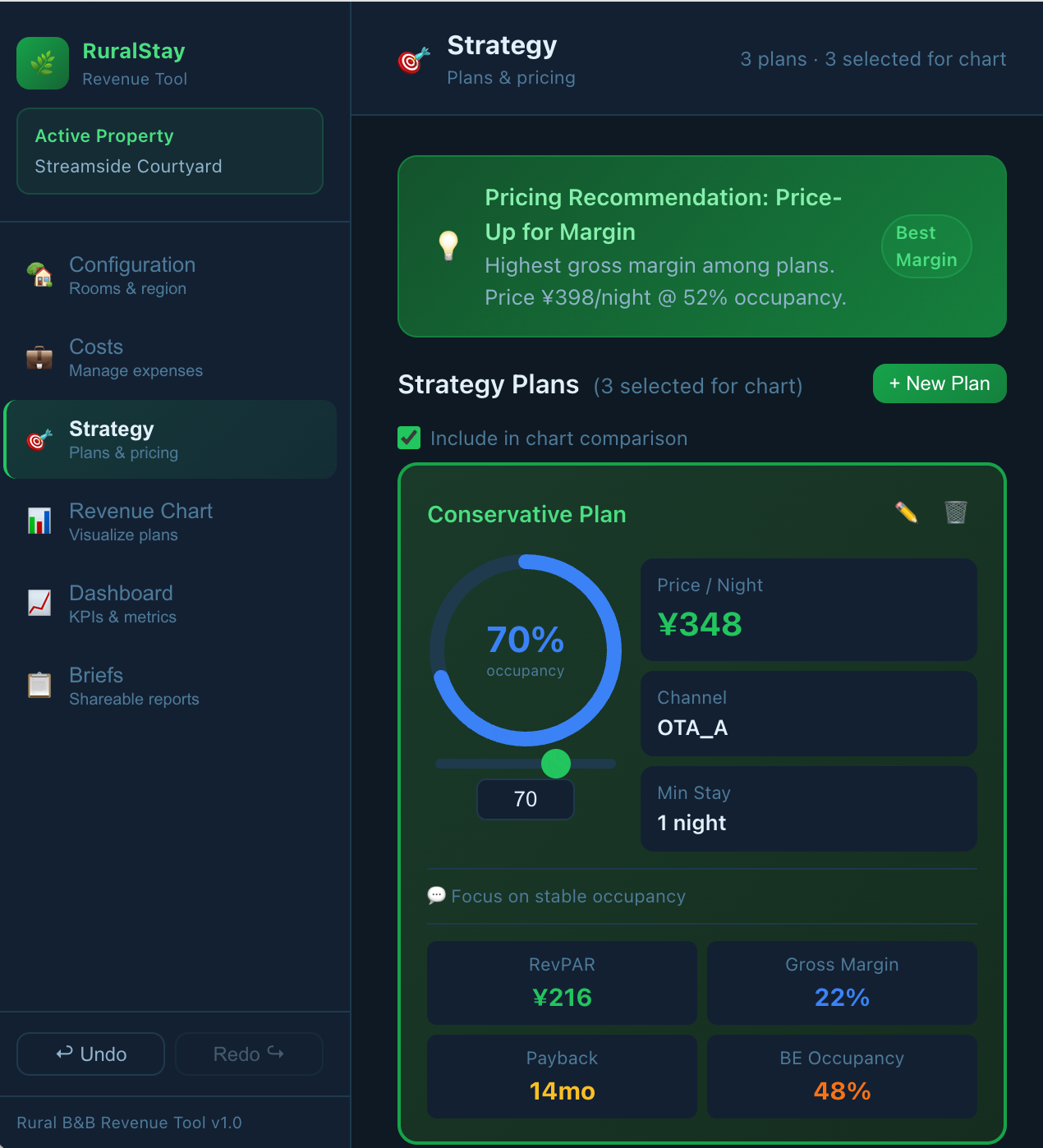
Fig 15: Progressive repair on the Visual Social Media Platform (Claude-4.6-Sonnet). v1 (left) shows four
Fig 5 (page 21).
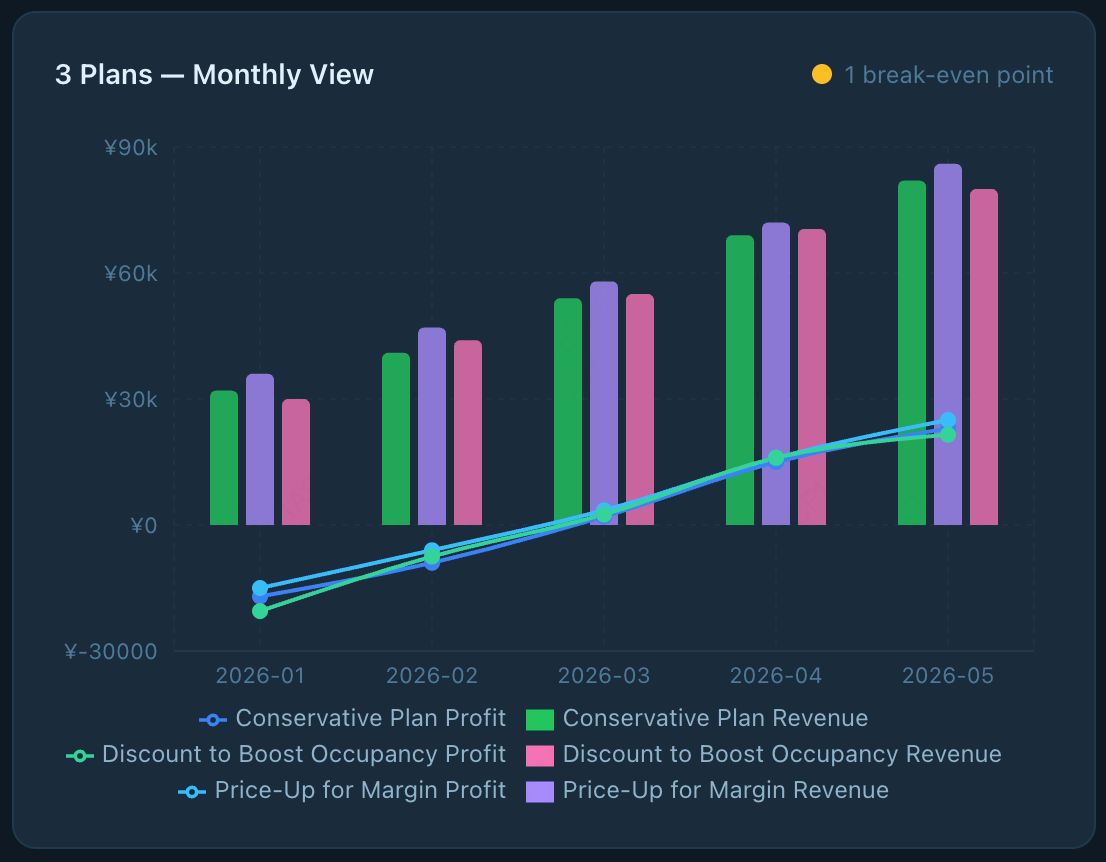
Fig 6 (page 21).
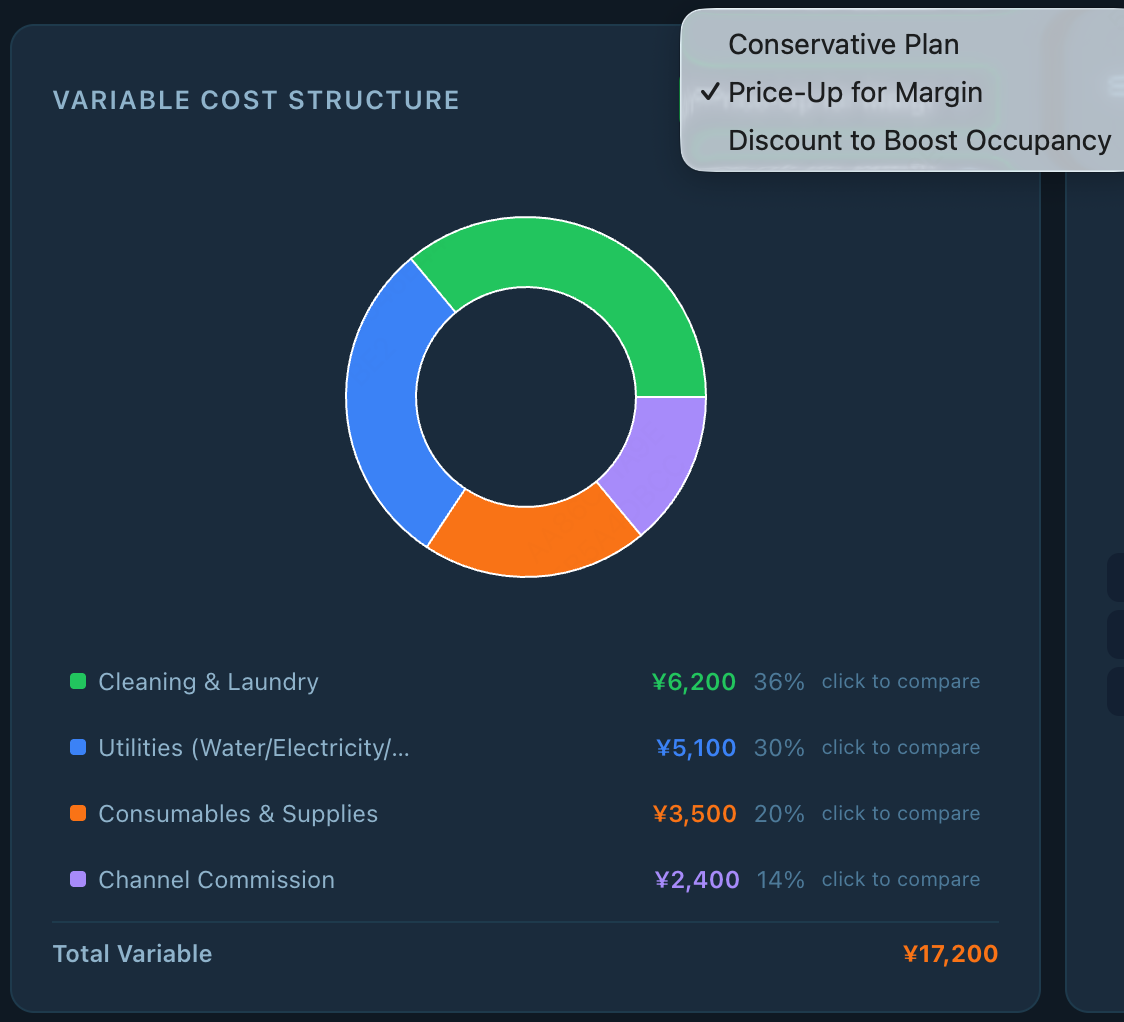
Fig 7 (page 21).
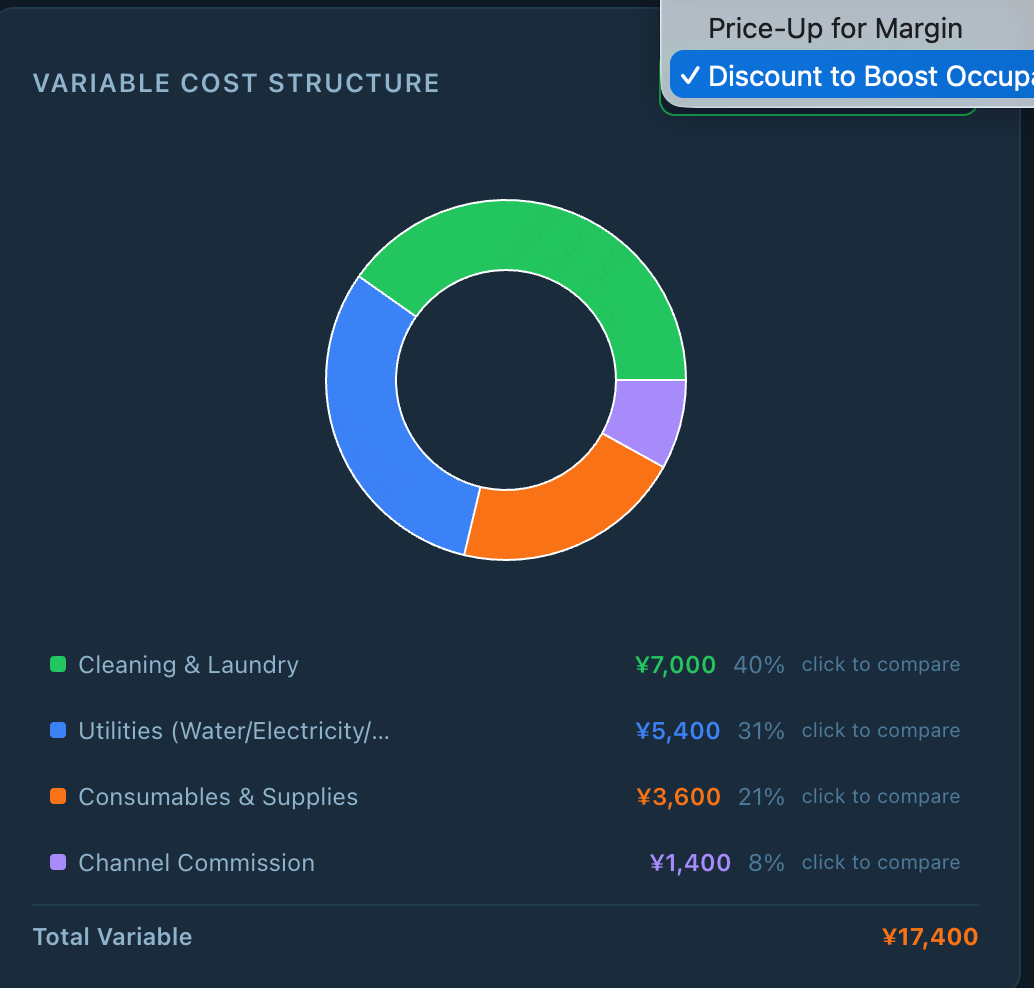
Fig 8 (page 21).
Limitations
- Domain restricted to self-contained frontend web applications with simulated data; lacks backend integration, real-time collaboration, or 3D/complex interactive scenarios.
- Evaluator components (UI Agent and User LLM) based on GPT-5.4 may bias or limit evaluation; results may shift with different evaluator models.
- Human agreement validation used single annotator labels, limiting full reliability estimates; multi-annotator studies could strengthen confidence.
- Potential risk of benchmark contamination through memorization as tasks and DAG criteria remain static; requires periodic task set refresh which is future work.
- No adversarial evaluation to test robustness against misleading or hostile feedback loops.
- Limited hardware and hyperparameter diversity information, leaving some reproducibility details underspecified.
Open questions / follow-ons
- How do these iterative refinement approaches generalize to backend-integrated or full-stack web applications?
- Can the evaluation framework incorporate adversarial feedback or noisy user inputs to test model resilience?
- What are the effects of alternative User LLM or UI Agent configurations on evaluation reliability and bias?
- How can the benchmark be extended to support multi-user collaborative development scenarios?
Why it matters for bot defense
Asuka-Bench introduces a rigorous framework to benchmark code generation agents under iterative, underspecified user intent, a scenario analogous to bot interactions that evolve with partial or ambiguous goals. For bot-defense or CAPTCHA practitioners, this benchmark illustrates the importance of designing evaluation protocols that consider multi-turn dialogues and continuous refinement, rather than one-shot correctness. The DAG-based dependency evaluation and closed-loop feedback approach can inspire more nuanced automated detection mechanisms that distinguish bots capable of learning and repairing based on interaction history versus those limited to one-shot behaviors. Moreover, the browser-grounded test execution suggests ways to tie security evaluations to rendered frontend behaviors, potentially enabling dynamic challenge adaptations in CAPTCHA systems. However, Asuka-Bench is not directly focused on adversarial robustness or evasion, so additional layers would be needed for CAPTCHAs targeting malicious bots, but its structural insights on iterative intent clarification remain valuable.
Cite
@article{arxiv2606_05920,
title={ Asuka-Bench: Benchmarking Code Agents on Underspecified User Intent and Multi-Round Refinement },
author={ Xin Wang and Liangtai Sun and Yaoming Zhu and Shuang Zhou and Jiaxing Liu and Fengjiao Chen and Lin Qiu and Xuezhi Cao and Xunliang Cai and Licheng Zhang and Zhendong Mao },
journal={arXiv preprint arXiv:2606.05920},
year={ 2026 },
url={https://arxiv.org/abs/2606.05920}
}