
Annotation of Positive vs Negative User Interactions for Social Sign Prediction
Source: arXiv:2606.06425 · Published 2026-06-04 · By Biancamaria Bombino, Chiara Boldrini, Andrea Passarella, Marco Conti
TL;DR
This paper addresses the challenge of inferring the sign (positive or negative) of social relationships from user interactions in online settings. Prior work typically applies sentiment analysis to label each interaction's content as positive or negative, then aggregates these to infer relationship sign. However, sentiment focuses on content valence rather than the nature of the relationship itself, causing conflation and potential misclassification. To overcome this, the authors propose a zero-shot approach leveraging Large Language Models (LLMs) to directly identify relational signals at the interaction level, specifically personal praise (positive relational gestures) and personal attacks (negative relational gestures). They evaluate four LLMs of varying accessibility and scale (including open-weight Qwen2.5 and Gemma2, and proprietary GPT-4o and GPT-5.4-mini) with three prompt designs of increasing complexity on two balanced, human-annotated datasets (298 praise comments from GoEmotions and 340 personal attack comments harvested from Wikipedia talk pages and Reddit). Results demonstrate that zero-shot LLMs can effectively separate relational valence from content valence without training data, establishing a practical baseline for relational annotation in sign prediction. Attack detection is robust across prompt designs and models, while praise detection is more sensitive to prompt and model choice, reflecting its greater subjectivity. An ensemble model cascade improves attack detection marginally but not praise detection.
Key findings
- LLMs in zero-shot mode achieve good F1 scores on relational praise and attack classification without any task-specific fine-tuning.
- For praise detection, the intermediate prompt design yields the highest performance across models; structured prompts do not improve and may reduce generalization.
- GPT-5.4-mini attains the best praise classification, but Qwen2.5:7b (7B parameters, open-weight) is competitive under intermediate prompting.
- Attack detection is best with the minimal prompt; increasing prompt complexity reduces performance.
- Proprietary models outperform open-weight ones markedly on attack detection, highlighting model capacity importance for hostile interaction detection.
- Attack detection errors are distributed evenly and less correlated with annotator ambiguity; praise detection errors cluster on low-agreement cases where human annotations disagree.
- Ensemble cascading of GPT-4o, Qwen2.5:7b, and GPT-5.4-mini reduces total attack detection errors from 54 to 49 but offers marginal gains and does not help praise detection.
- In human annotations, 57.35% of attack dataset instances had unanimous agreement, while praise dataset had only 20.8% unanimity, indicating attacks are more explicitly recognizable.
Threat model
The adversary is an observer or analyst attempting to infer the true nature (positive or negative) of social relationships solely from textual interactions between users, without access to explicit relational labels. The challenge comes from the adversary's inability to directly observe relationship valence and only having message content, which may conflate relational and content sentiment. The adversary cannot access private communications or additional metadata beyond text.
Methodology — deep read
The authors formulate the problem as two independent binary classification tasks at the interaction level: determining whether a text constitutes personal praise directed at the interlocutor, and whether it constitutes a personal attack directed at the interlocutor. This explicitly targets relational valence rather than content valence, a departure from typical sentiment analysis approaches. The relationship sign is inferred by aggregating interaction-level labels. They use Large Language Models (LLMs) in a zero-shot setting to classify each textual interaction without task-specific training. Three prompt designs varying in complexity are tested: minimal (task definition only), intermediate (adds directionality clarifications), and structured (includes positive/negative examples). Four LLMs are evaluated: open-weight Qwen2.5:7b & Gemma2:9b and proprietary GPT-4o & GPT-5.4-mini. Temperature is fixed to 0 for deterministic inference, and outputs structured JSON labels parsed post-hoc. To study ensemble effects, a cascading strategy uses error correlation matrices on held-out splits: a primary model labels all data, and uncertain cases are passed sequentially to complementary models to improve recall. Two balanced datasets are constructed: praise dataset based on re-annotated GoEmotions Reddit comments (298 items) labeled by 7 annotators; personal attack dataset (340 items) derived from Reddit 'roastme' and Wikipedia Talk Pages, annotated by 5 annotators. Agreement distributions reveal attacks have higher consensus. Models are evaluated on accuracy, precision, recall, and F1, with confusion matrices analyzed at different annotator-agreement strata to interpret errors. Experiments show praise detection benefits from intermediate prompts and larger models but suffers on ambiguous inputs. Attack detection performs best with minimal prompt, with proprietary models substantially outperforming open-weight ones, and errors more evenly distributed across samples. Ensemble cascading yields minor improvements only for attack detection. The approach decouples relational signals from content sentiment, addressing the problem of conflation in prior sign prediction methods. However, results highlight the inherently subjective nature of positive social signals and the challenges ahead. Detailed prompt engineering and model selection are critical depending on the relational signal targeted.
Technical innovations
- Explicit decoupling of relational valence (praise and attack toward interlocutor) from content valence to better infer social relationship signs.
- Zero-shot application of LLMs with tailored prompt designs to capture interaction-level relational signals without task-specific fine-tuning.
- Systematic evaluation and comparison of open-weight and proprietary LLMs on relational annotation tasks, highlighting tradeoffs in accessibility vs. capacity.
- Cascading ensemble strategy guided by error correlation matrices to combine complementary model predictions for improved detection.
Datasets
- Praise dataset — 298 texts (149 praise, 149 non-praise) — subset re-annotated from GoEmotions Reddit comments, 7 human annotators.
- Personal attacks dataset — 340 texts (170 attack, 170 non-attack) — collected from Wikipedia Talk Pages and Reddit (e.g., roastme), 5 human annotators.
Baselines vs proposed
- Qwen2.5:7b praise classification F1 ~ competitive with larger models under intermediate prompt; GPT-5.4-mini best overall for praise.
- GPT-5.4-mini attack detection accuracy and F1 (minimal prompt) outperform Qwen2.5:7b and Gemma2 by significant margins (exact numbers in figures not specified).
- Cascade ensemble on attack detection reduces total errors from 54 (GPT-5.4-mini single model) to 49, improving recall without increasing false positives.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.06425.

Fig 1: Confusion matrices for the praise classification task across four differ-

Fig 2: Confusion matrices for the attack classification task across four differ-
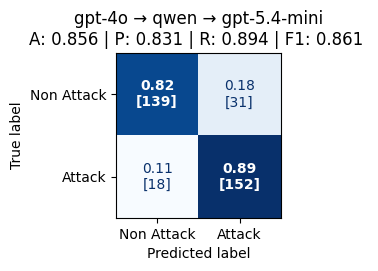
Fig 3: Confusion matrix of the cascaded ensemble (GPT-4o, Qwen2.5:7b, GPT-
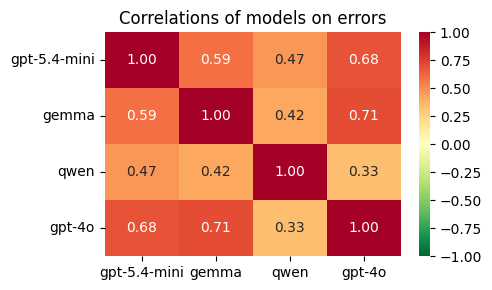
Fig 4: Error correlation matrices calculated to guide LLM choice in the pipeline.
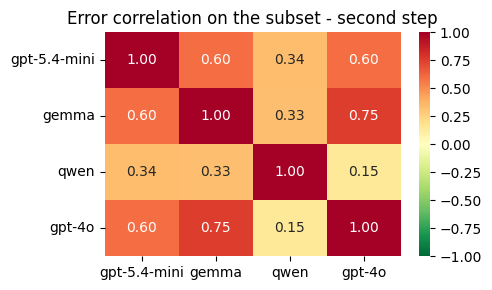
Fig 5 (page 12).
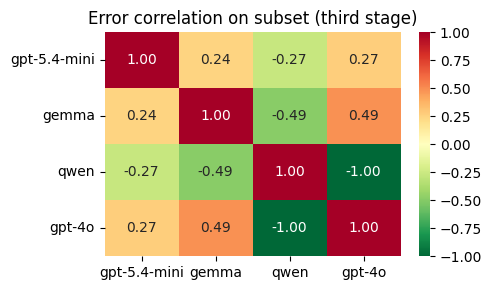
Fig 6 (page 12).
Limitations
- Datasets are relatively small and specialized, limiting generalization to other social platforms and interaction types.
- Praise detection remains highly subjective, sensitive to prompt design and model capacity; likely to produce noisier labels in ambiguous cases.
- Ensemble gains are marginal and rely on oracle access to error correlations, limiting practical deployment viability.
- Evaluation limited to binary classification tasks; aggregation to actual relationship-level sign prediction pipelines is left implicit.
- Potential overlap between GoEmotions corpus and LLM pre-training (though labels differ), which could bias praise detection results.
- No explicit adversarial robustness or temporal/dynamic evaluation of social relationships; static snapshots only.
Open questions / follow-ons
- How well do LLM-based relational annotations generalize to other domains, languages, and platforms outside Reddit and Wikipedia talk pages?
- Can few-shot prompting, chain-of-thought reasoning, or lightweight fine-tuning improve praise detection given its subjectivity?
- What approaches can better leverage ensembles or model combinations without requiring oracle knowledge of error correlations?
- How to effectively aggregate interaction-level relational annotations to produce robust and stable relationship sign predictions, especially over evolving conversations?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this work offers a novel paradigm to distinguish relational intent in user interactions beyond surface sentiment analysis. Integrating LLM-based annotation to detect personal attacks and praise could enhance detection of hostile, manipulative, or trust-building bot behavior. Since attack detection is robust even to prompt changes and model selection, deploying such classifiers may strengthen monitoring of negative or suspicious user interactions indicative of bot-driven abuse or social engineering. However, the higher complexity and subjectivity of positive relational signal detection caution against naive aggregation of positive interaction labels for trust verification without careful prompt design. Overall, the clear methodological separation of content sentiment vs relational valence highlights a promising direction to refine social engagement metrics and trust signals used in defense systems, especially where labeled data is scarce.
Cite
@article{arxiv2606_06425,
title={ Annotation of Positive vs Negative User Interactions for Social Sign Prediction },
author={ Biancamaria Bombino and Chiara Boldrini and Andrea Passarella and Marco Conti },
journal={arXiv preprint arXiv:2606.06425},
year={ 2026 },
url={https://arxiv.org/abs/2606.06425}
}