
TeleHunt: A Framework and Tool for Efficient Cybercriminal Community Discovery on Telegram
Source: arXiv:2606.04657 · Published 2026-06-03 · By Roy Ricaldi, Victor Asanache, Luca Allodi
TL;DR
This paper addresses the challenge of systematically discovering cybercriminal communities on Telegram, a popular encrypted messaging platform increasingly used for illicit activities. Existing efforts primarily focus on content classification or static ecosystem snapshots, lacking a framework to evaluate exploration strategies and their bias. TeleHunt is introduced as a modular, configurable pipeline leveraging large language model (LLM)-assisted classification, pointer extraction, and iterative snowballing to discover cybercriminal communities with fine-grained market segment labels. Through a comprehensive empirical evaluation across over 6,000 communities and 172 million messages, the authors compare seed sources (dark web vs open web), pointer types (handles, invite links, forwards), and contextual filtering impact on discovery efficiency, accessibility, and rediscovery. Their results demonstrate link-based pointers vastly outperform other types, open-web seeds produce higher discovery volumes, and most discovered communities are public or lightly gated. Low rediscovery rates suggest limited saturation within three expansion iterations, highlighting the fragmented and dynamic nature of the Telegram underground ecosystem. They also release a large labeled dataset to the research community. Overall, TeleHunt enables systematic, scalable cybercriminal community discovery with quantifiable performance metrics to guide threat intelligence workflows.
Key findings
- Link-containing pointer strategies (L, HL) significantly increase yield: O-L-C-N achieves 0.40 yield vs 0.34 for O-HF-C-N (handle+forward), plus +70% more valuable communities discovered than dark-web seed counterparts.
- Open web seeds outperform dark web seeds in discovery rate by 3–24%, e.g., discovery rate 0.52 vs 0.42 for link-only configurations (O-L-C-N vs D-L-C-N).
- Precision remains consistently high (70–82%) across configurations, with link-based strategies achieving up to 82% precision in detecting valuable communities.
- Noise (invalid pointers) grows with iteration and pointer age, often exceeding 40% for link-based methods; dark web seeds have higher noise rates than open web seeds.
- Most discovered communities are public (73–97%), with private communities around 20–22% and vetted under 4%, indicating largely accessible ecosystems.
- Market segments Fraud Tools and Cyberattacks dominate discovery graphs and act as hubs enabling transitions to less accessible segments (Digital Infrastructure, Tutorials, Personal Data).
- Rediscovery rates (revisiting known communities) remain low overall (<3%), especially for open-web seeds, indicating incomplete saturation after three iterations.
- Criminal-contextual filtering moderately reduces noise (≈14% fewer pointer failures per week age) and increases yield, though effects are smaller than pointer type.
Threat model
The adversary is a cyber threat intelligence analyst who can access Telegram's public API and initial seed communities from open web or dark web sources but cannot directly access private or vetted groups without explicit invitation beyond discovered pointers. Their goal is to discover and map cybercriminal communities effectively accounting for link decay, community churn, and incomplete coverage. They do not have insider privileges or continuous real-time monitoring capabilities beyond iterative snowball expansion.
Methodology — deep read
Threat model and assumptions: The adversary is an analyst or CTI practitioner aiming to discover cybercriminal communities on Telegram using snowball sampling of message pointers. The adversary has access to Telegram's public API and initial seed communities from both dark web and open web sources. They cannot access fully private or invitation-only groups without invites beyond extracted pointers, and the ecosystem is assumed dynamic with community churn and pointer decay.
Data: Two sets of seed communities: 41 from dark web forums and 45 from open web indexing (TGstat). These seeds are expanded through iterative snowballing up to three iterations, scraping all messages in a 30-day window from discovered communities. The dataset contains 6,022 Telegram communities with 172 million messages from over 2 million users.
Architecture / Algorithm: TeleHunt is a modular pipeline integrating data collection (Telegram API scraping), message classification, pointer extraction, context filtering, iterative expansion, and labeling. Message classification uses two fine-tuned RoBERTa-Large models: a binary cybercriminal classifier and a six-class market segment classifier, both validated with F1 scores above 0.95. Pointer extraction targets three types: handles (@username), invite links (t.me/+hash), and forwards. Context windows around pointers (up to 11 messages) are classified to filter for pointers in cybercriminal contexts (≥50% context messages labeled criminal). Communities with ≥70% cybercriminal messages are labeled valuable.
Training regime: Classifiers are fine-tuned on prior established datasets from previous work (citation [18]), specifics of epochs, batch size, or hardware used are not provided in detail but reported validation is high. Thresholds (70% community criminal messages, 50% context criminal messages, 30-day windows) are empirically chosen.
Evaluation protocol: The pipeline is run for each configuration combining seed source (dark/open web), pointer types (handles, links, forwards, and combinations), contextual filtering setting, and extra-shot expansion over three iterations. Efficiency metrics include discovery rate (new communities per pointer), yield (valuable communities per pointer), precision (valuable per new), and noise (invalid pointers). Accessibility is assessed by community access type distribution (public/private/vetted) and market segment coverage. Rediscovery measures rate of revisits to known communities to assess exploration saturation. Beta regression and logistic regression model significant factors affecting yield and noise. Human validation on samples (100 communities per seed origin) audited classification quality (Cohen's kappa showing substantial agreement).
Reproducibility: Code, database schema, and anonymized samples are publicly available at https://github.com/royricaldi/telehunt. Due to Telegram limits and community volatility, results reflect a snapshot over a two-week collection.
Example: Starting from an open-web seed community, the tool scrapes all messages from the last 30 days, classifies them to detect cybercriminal posts, extracts pointers (e.g., invite links) from criminal-context messages, filters pointers by context, then queries Telegram for newly pointed communities. Newly discovered communities with ≥70% cybercriminal messages become seeds for the next iteration. Across three iterations, metrics like yield and noise are logged to evaluate the effectiveness of link-based versus handle-based discovery and seed provenance effects.
Technical innovations
- Integration of LLM-driven message-level classification with pointer extraction and contextual filtering to automate iterative snowball discovery on Telegram.
- Systematic empirical evaluation framework measuring discovery efficiency, ecosystem accessibility, and rediscovery saturation across multiple strategy configurations.
- Use of a multi-dimensional labeled dataset of 6,000+ Telegram communities with market segment and access-type annotations to characterize cybercrime ecosystem structure.
- Application of beta regression and logistic models to quantify the impact of pointer types, seed sources, and context filtering on discovery yield and noise.
Datasets
- TeleHunt Telegram Dataset — 172,385,463 messages, 6,022 communities, 2,392,741 users — collected from Telegram public and dark web seeded communities (not publicly released but available on request)
Baselines vs proposed
- Handle + Forward (HF) baseline: discovery rate 0.17 (dark web), yield 0.19 vs Proposed Link-only (L): discovery rate 0.42, yield 0.36 (dark web)
- Open Web seed + Link (O-L-C-N): discovery rate 0.52, yield 0.40 vs Dark Web seed + Link (D-L-C-N): discovery rate 0.42, yield 0.36
- HF-only precision ~0.71 vs Link-only precision ~0.82 across configurations
- Noise rates for dark web seeds exceed 0.34, while open web seed noise rates are lower (down to 0.24).
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.04657.
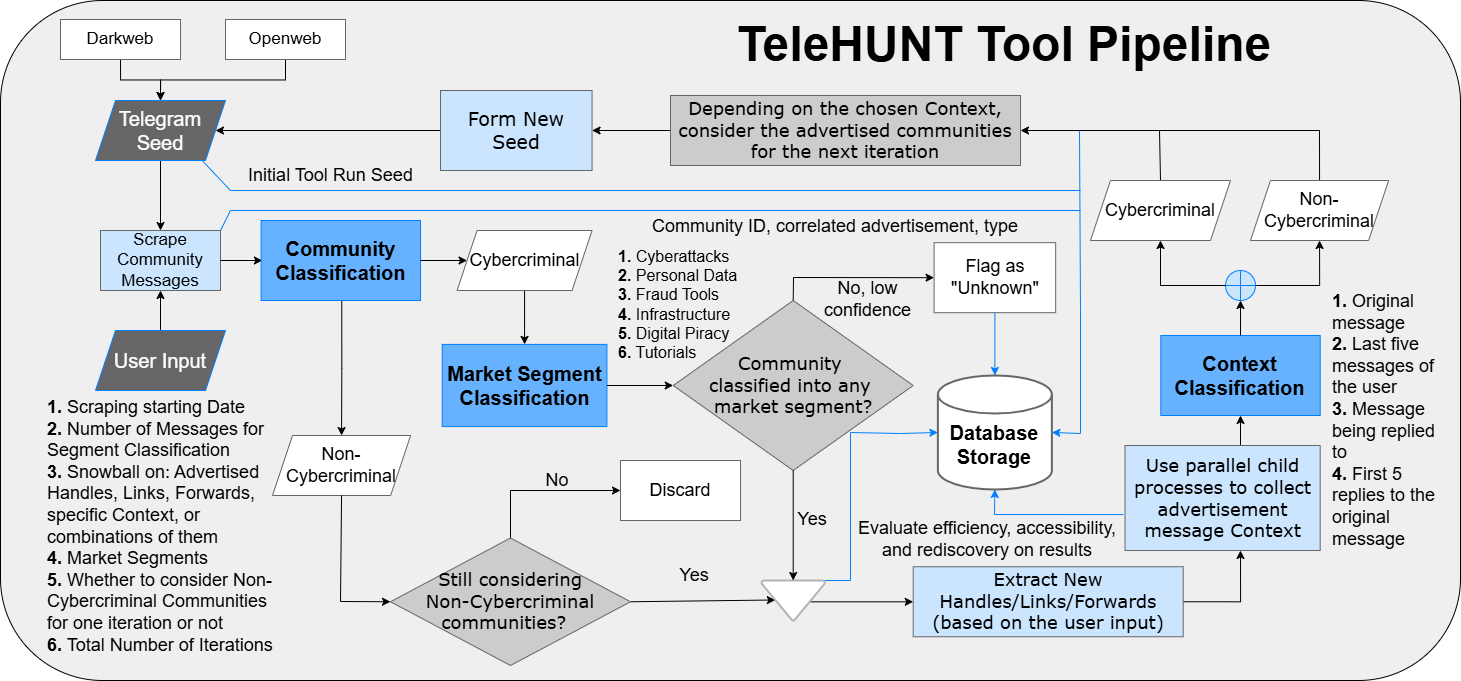
Fig 2: TeleHunt pipeline.
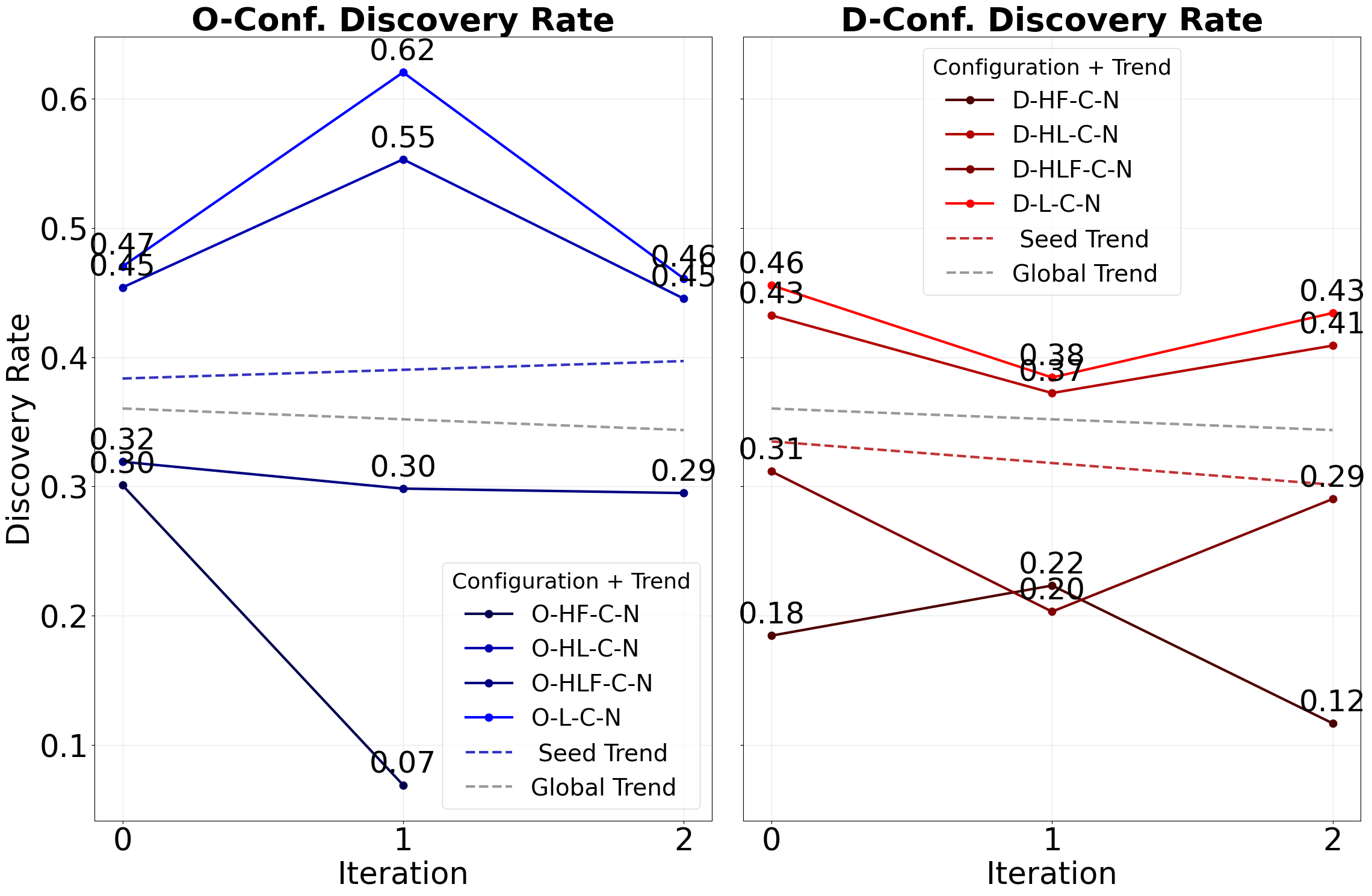
Fig 3: Discovery rate per iteration.
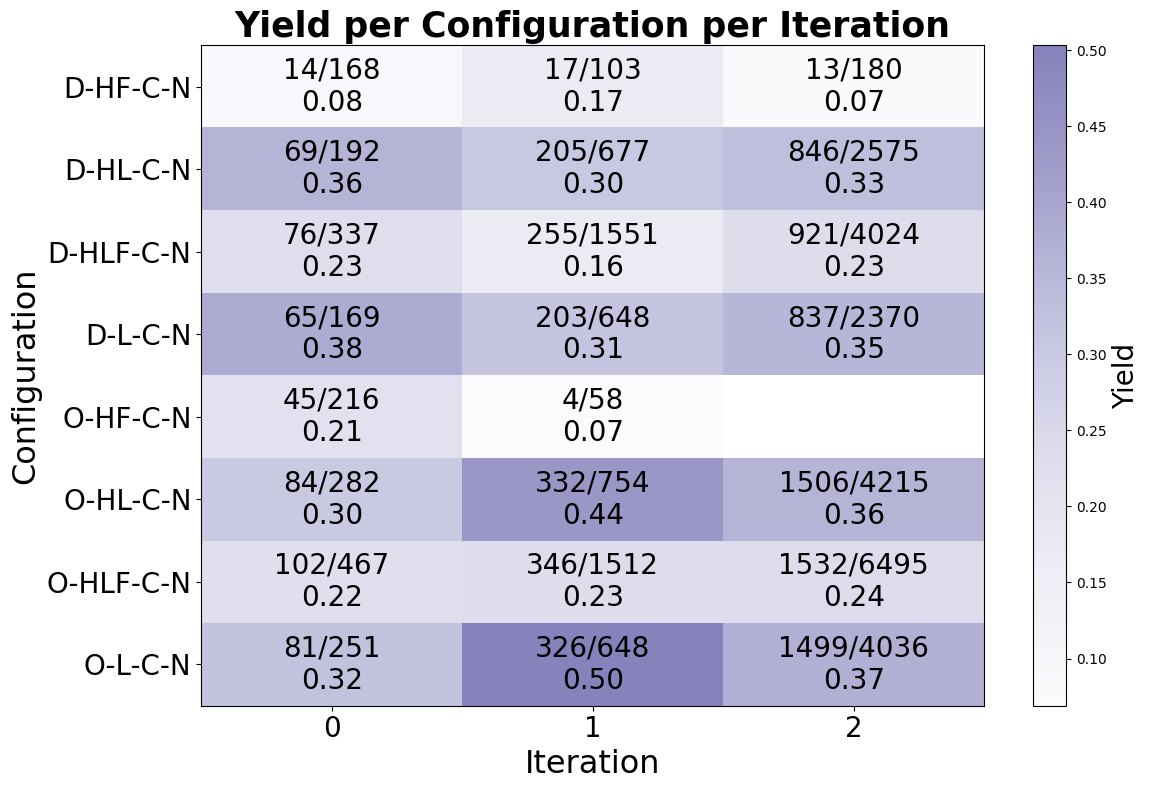
Fig 4: Yield per iteration.
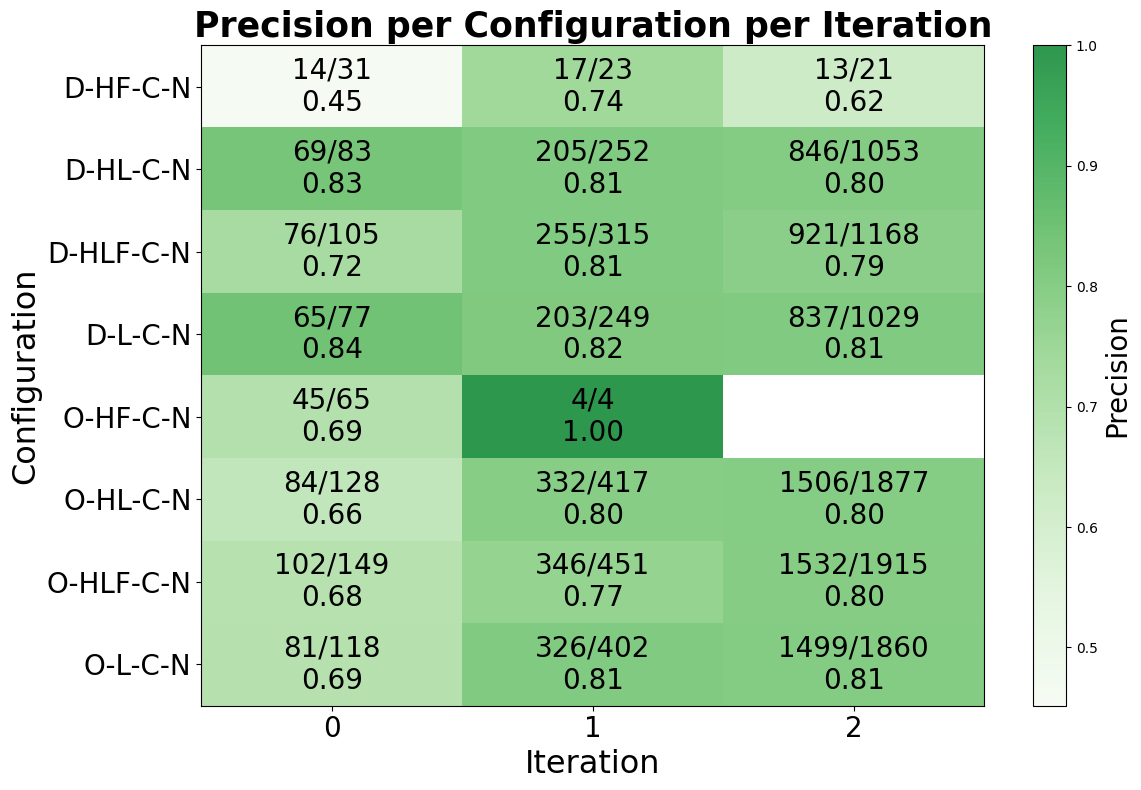
Fig 5: Precision per iteration.
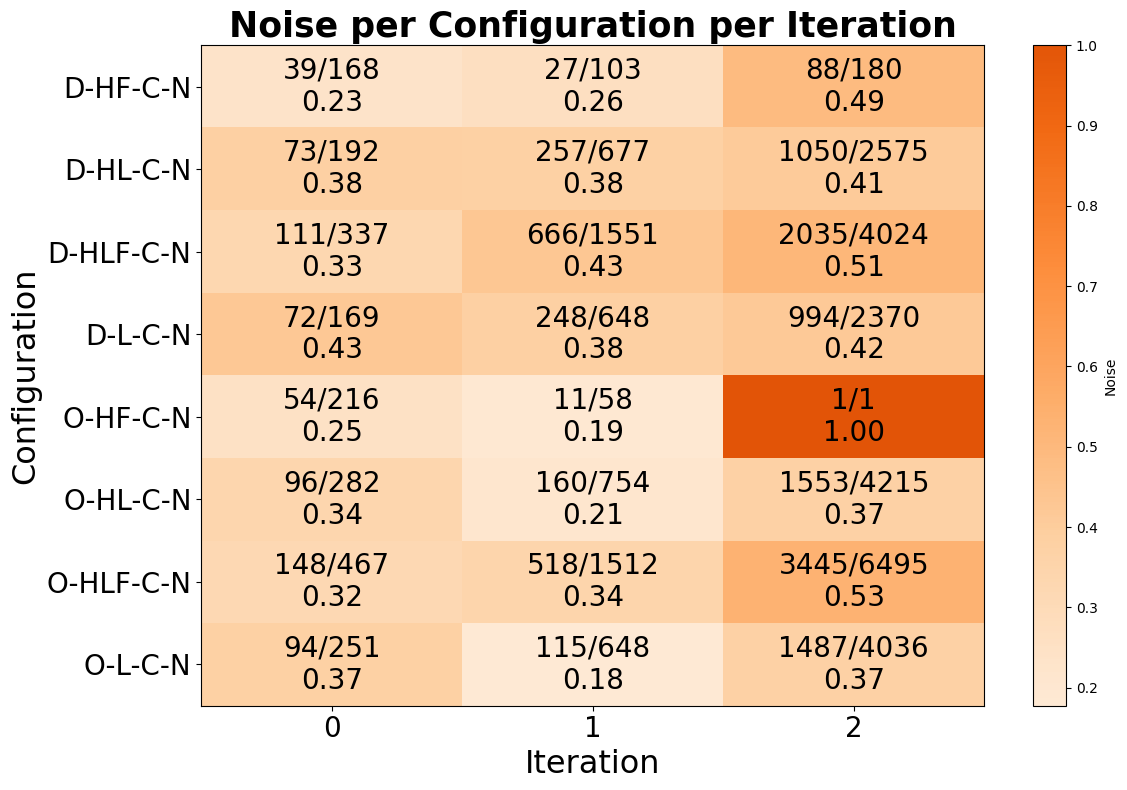
Fig 6: Noise per iteration.
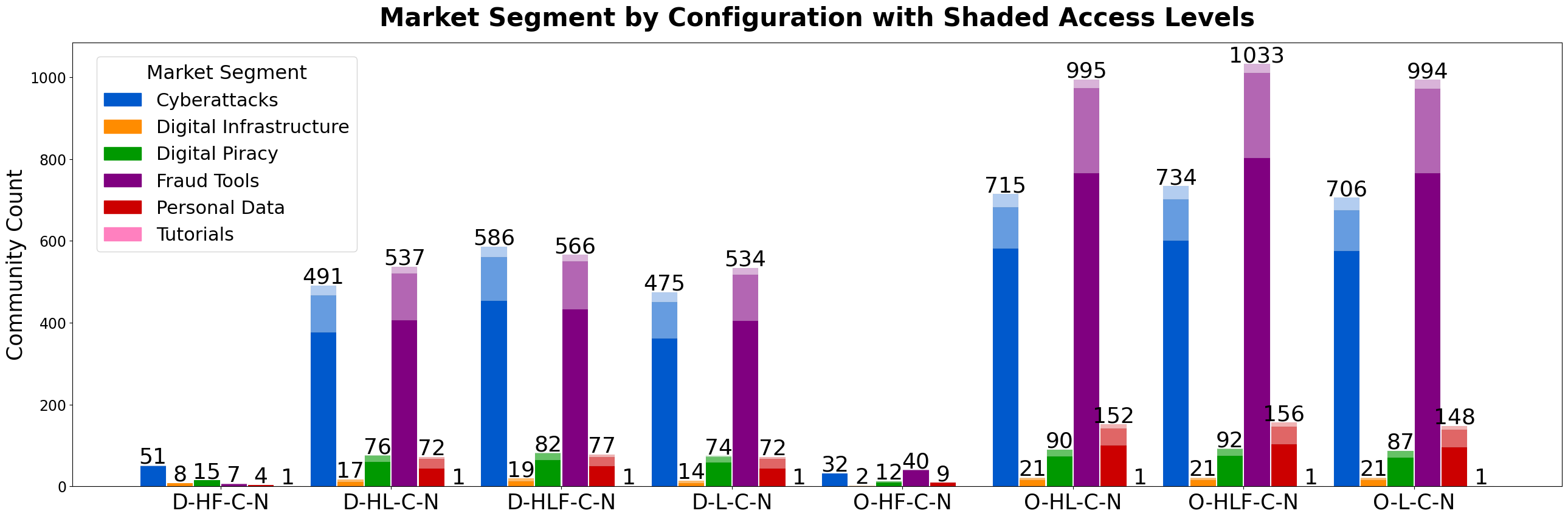
Fig 7: Market segment accessibility characteristics. Shading depicts public, private,
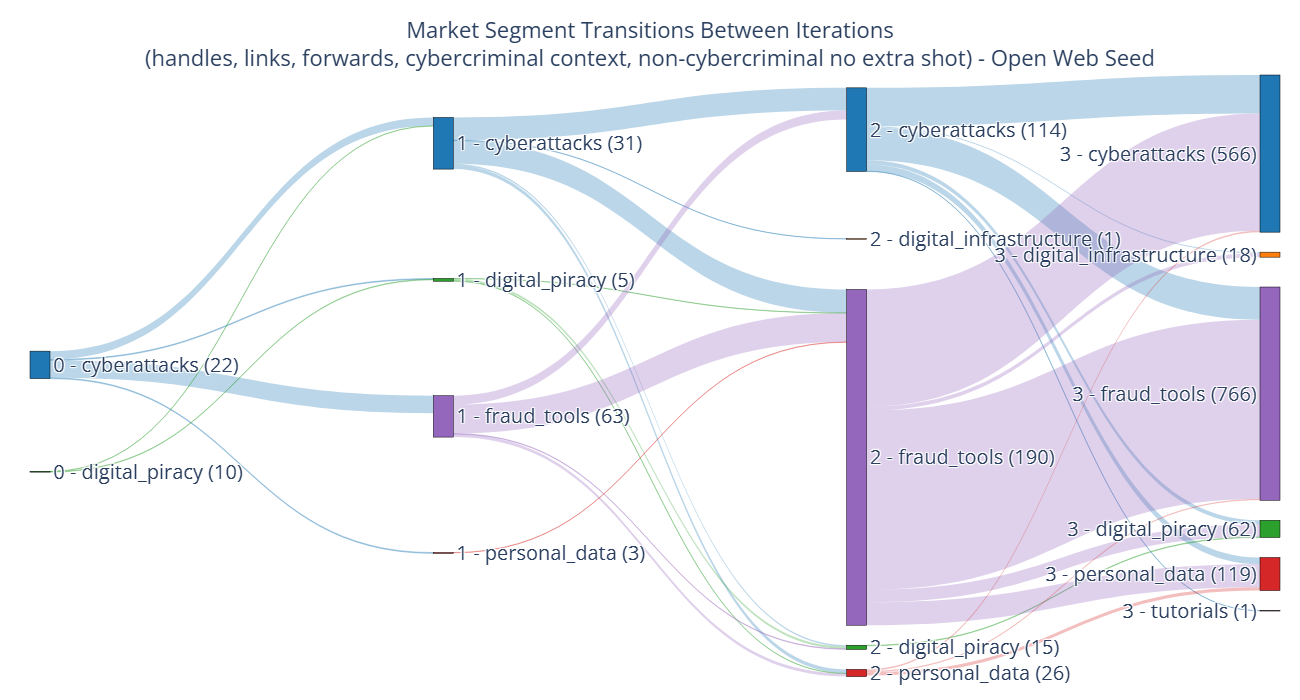
Fig 8: O-HLF-C-N access paths across segments.
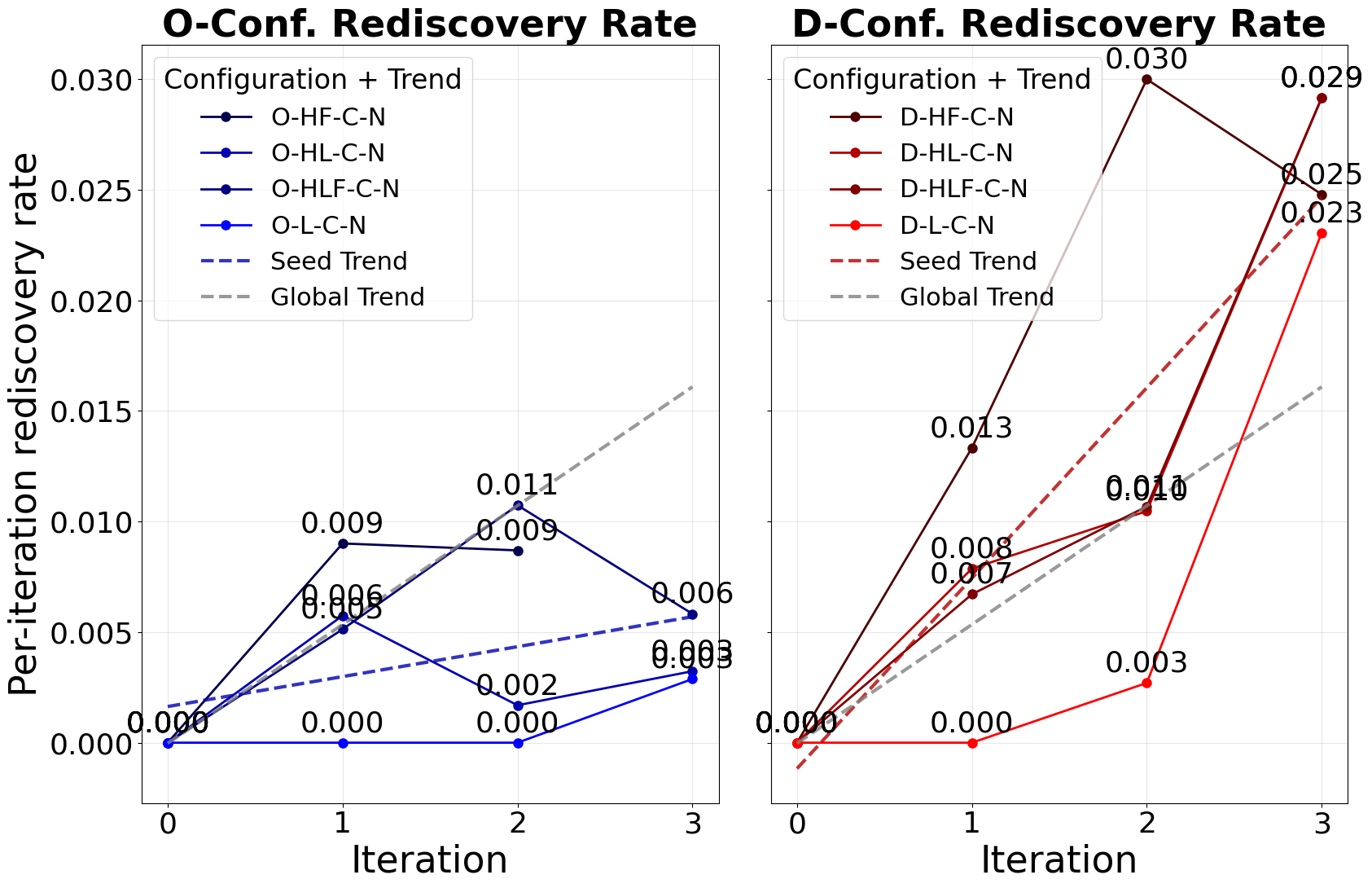
Fig 9: Per-visit redundancy across configurations.
Limitations
- Ecosystem coverage is limited by initial seed selection bias; the framework does not guarantee exhaustive discovery.
- Temporal snapshot of two weeks may miss dynamic behaviors like enforcement-driven migration or long-term trends.
- Threshold values for community and context classification (70%, 50%, 30 days) are empirically chosen without sensitivity analyses.
- Classification errors from multilingual content, slang, and class imbalance may affect the labeling accuracy of communities and market segments.
- Telegram API rate limits and intermittent downtime constrain large-scale continuous crawling and exploration depth.
- High noise rates from pointer decay and stale invite links increase resource cost and reduce exploration efficiency.
Open questions / follow-ons
- How stable are exploration outcomes and ecosystem structures over longer time horizons exceeding the two-week snapshot?
- What is the sensitivity of discovery metrics to different threshold choices for context filtering, message labeling, and community dormancy?
- Can further expanding iteration depth beyond three reveal meaningful saturation or more tightly connected ecosystem cores?
- How might dynamic factors like law enforcement takedowns or platform policy changes affect community discoverability longitudinally?
Why it matters for bot defense
TeleHunt provides a rigorous, reproducible methodology for systematically mapping cybercriminal communities on Telegram, which uses various access controls and dynamic evasion tactics. Bot-defense and CAPTCHA practitioners can adapt the insights to optimize data gathering by focusing on pointer types, seed source selection, and contextual filtering that maximize discovery efficiency while minimizing noise. Specifically, the dominance of invite links as discovery vectors indicates that monitoring referral paths and pointer freshness is key in environments with restricted or ephemeral access modalities. Understanding rediscovery saturation helps calibrate exploration depth to avoid diminished returns and resource wastage. The modular design with LLM-assisted classification could also inspire approaches combining language understanding with pointer extraction in detecting malicious collective behavior on messaging platforms.
Cite
@article{arxiv2606_04657,
title={ TeleHunt: A Framework and Tool for Efficient Cybercriminal Community Discovery on Telegram },
author={ Roy Ricaldi and Victor Asanache and Luca Allodi },
journal={arXiv preprint arXiv:2606.04657},
year={ 2026 },
url={https://arxiv.org/abs/2606.04657}
}