
SentinelBench: A Benchmark for Long-Running Monitoring Agents
Source: arXiv:2606.05342 · Published 2026-06-03 · By Matheus Kunzler Maldaner, Adam Fourney, Amanda Swearngin, Hussein Mozzanar, Gagan Bansal, Maya Murad et al.
TL;DR
SentinelBench addresses a pressing gap in AI agent evaluation: how to benchmark agents on long-running monitoring tasks that unfold over minutes to hours. Traditional agent models assume continuous action to force progress, but many real-world monitoring scenarios require agents to wait efficiently for external events before acting. SentinelBench provides a systematic and open-source benchmark tailored to this class of time-evolving monitoring tasks.
The benchmark consists of 100 tasks over 10 synthetic web environments that realistically simulate apps like email, calendars, finance portals, and social media feeds. Each task involves navigating and reasoning about dynamically changing web pages driven by scripted event sequences. SentinelBench measures task success, reaction time from event occurrence to agent response, and resource consumption such as token usage, revealing the triad tradeoff between responsiveness, cost, and accuracy. Baseline evaluations with several state-of-the-art large language models (GPT-5.4, GPT-4o, Qwen 3.5) paired with different agent wait strategies demonstrate meaningful discriminations in agent ability and highlight how design decisions materially impact these key metrics.
Through detailed environment replication, synthetic persona and content generation, and a multi-dimensional task design including passive/active and absolute/relative criteria, SentinelBench supplies a rigorous, real-world-inspired platform for benchmarking and improving AI monitoring agents.
Key findings
- GPT-5.4 with the wait_for tool achieves the highest overall task success rate of 75%, outperforming GPT-5.4 with sleep (68%) and other models (Qwen 3.5 and GPT-4o around 48%).
- No-operation tasks have very high success rates (95–100%) across all conditions, indicating agents rarely falsely conclude monitoring when no trigger occurs.
- Active tasks are significantly harder than passive tasks; for GPT-5.4 wait_for success is 50% for active versus 92% for passive tasks (Table 4).
- Extending task durations 4x causes GPT-5.4 sleep agents to incur 10x higher estimated monetary cost ($4.65 vs $0.48) while completing fewer tasks (56% vs 69%).
- The wait_for conditional wait strategy generally reduces token consumption and improves reaction time compared to naive sleep-based polling.
- SentinelBench’s 10 synthetic web environments feature realistic UI interactions, backed by REST APIs, populated with 100 user personas and 201 entities generated by LLMs to maintain consistency.
- Agent success depends on accurate detection of environment changes via textual diffs combined with LLM reasoning of page content differences in the wait_for implementation.
- Manual and AI-assisted task validation identified and fixed ambiguities and interface bugs prior to benchmark release, improving task clarity and environment stability.
Threat model
The benchmark assumes a cooperative evaluation setting where the agent operates under natural monitoring constraints and interacts honestly with the environment interface. The adversary is an AI agent attempting to detect task-relevant condition changes from observable UI states without privileged knowledge or oracle access. Agents cannot manipulate or shortcut event timelines; their success depends on timely and accurate monitoring and response to dynamic web page content changes.
Methodology — deep read
Threat Model and Assumptions: SentinelBench assumes a benign evaluation setting; the adversary model is that of an AI agent attempting to monitor time-evolving environments. The agent does not possess privileged knowledge of future events or internal environment state beyond its observations. Agents cannot cheat by peeking at event schedules; success depends on reacting to changes visible via the web UI. The benchmark tests general agent ability to balance action with monitoring delays and resource use, not adversarial robustness.
Data and Environments: The benchmark includes 10 synthetic web applications modeled after popular consumer apps (e.g., email, calendars, social network, finance, entertainment). These are implemented as lightweight React apps with FastAPI backends and SQLite databases, serving a single authenticated user. 100 synthetic user personas and 201 entities are generated via large language models, providing consistent profiles across environments (e.g., user interests, social media followers). Application data (emails, messages, posts, jobs) are populated using scripted generative pipelines to ensure realistic content distributions.
Tasks: 100 total tasks (10 per environment) are generated using an AI coding agent prompting event timelines of approximately 10 minutes duration. Tasks are categorized along two axes — action requirement (active vs passive) and criterion type (absolute vs relative). Passive tasks involve waiting for monitoring conditions followed by minimal action; active tasks require periodic interaction (e.g., opening pages). Absolute criteria involve fixed thresholds; relative criteria require comparing increments (e.g., '3 more likes'). 20 are no-op tasks where conditions never occur, providing a test for false positives. Tasks are finalized by SQL queries validating environment states post-interaction.
Agent Architectures and Configurations: Evaluations involve three large language models (GPT-5.4 low-reasoning variant, GPT-4o, and Qwen 3.5 9B) paired with a browser-agent harness. The harness receives screenshots and UI descriptions, then chooses from browser tools (click, type, scroll, visit URL). Two tool configurations are tested: one with a sleep(time) tool performing fixed delays (naive polling), and a novel wait_for(condition, timeout) tool which monitors page diffs and invokes a unified diff combined with LLM reasoning to detect environment changes relevant to a natural language condition.
Training Regime: As a benchmark paper, SentinelBench does not train models but evaluates pretrained LLMs in zero/few-shot interactive settings. The wait_for tool integrates a loop capturing page snapshots once per second, computing diffs, and prompting the model to determine if the monitored condition is met, otherwise continuing or timing out after the specified maximum.
Evaluation Protocol: Each task runs a simulated event timeline on the synthetic web environment backend, advancing events at rates scaled by a speed_factor parameter to test various duration regimes. The evaluation harness runs the agent until it terminates or times out, capturing metrics including success (task completion meeting SQL-defined condition), reaction time (delta between event condition timestamp and agent completion), and resource use (token counts, cost if self-reported). Task success criteria differ by task type (e.g., for passive tasks, agent must contact user only after condition occurs; for active tasks, database must be in correct final state).
Reproducibility: SentinelBench is open source with public code, environments, scenario generators, and synthetic catalogs at https://github.com/microsoft/sentinel_environments. Tasks and environment states are reproducible via provided event timelines and seedable synthetic data. Agent evaluation toolchains are flexible and scriptable, though pretrained model weights come externally. All task prompts, environment UIs, and evaluation scripts are included. Synthetic datasets and task generation pipelines are documented.
Example Walkthrough: A passive absolute MicroFy task requires the agent to watch a music feed for a new song with 'subway' in the lyrics and 'like' it. The environment preloads 24 tracks and plays events adding new tracks at scheduled times over 10 minutes. The agent monitors the feed UI via repeated screenshots, using wait_for to detect the targeted track appearance by interpreting diffs and content changes. Upon detecting the condition at 329 seconds, the agent must like the new track and contact the user within the simulation. Success is validated by SQL queries checking 'liked' flags on the track. Reaction time measures delay from track arrival to agent action, while token cost aggregates all model inference tokens consumed during the process.
Technical innovations
- SentinelBench introduces a versatile public benchmark specifically for long-running monitoring AI agents that operate over evolving web environments, filling a gap not targeted by prior transient task benchmarks.
- A novel wait_for(condition, timeout) tool is implemented using page textual diffs combined with LLM reasoning to detect relevant page changes and efficiently block until meaningful updates occur, reducing naive polling costs.
- The benchmark’s synthetic web environments are realistically constructed with multi-screen React apps, REST APIs, and dynamically generated personas and content catalogues coherently spanning 10 distinct application domains.
- Task design incorporates nuanced axes—active vs passive monitoring and absolute vs relative conditions—allowing assessment of different real-world monitoring challenges and capturing agent memory and reasoning capabilities.
Datasets
- SentinelBench Synthetic Personas and Entities — 100 user personas, 201 entities — generated with large language models (specific code and catalogs at https://github.com/microsoft/sentinel_environments)
- SentinelBench Task Event Traces — 100 tasks with scripted event sequences spanning 10 environments — publicly available alongside benchmark code
Baselines vs proposed
- GPT-5.4 + wait_for: success rate = 0.75 vs GPT-5.4 + sleep: 0.68
- GPT-4o + wait_for: 0.48 vs GPT-4o + sleep: 0.46
- Qwen 3.5:9b + wait_for: 0.48 vs Qwen 3.5:9b + sleep: 0.49 (comparable)
- No-operation task success (GPT-5.4 wait_for): 0.95 vs active task success: 0.50 (large gap)
- Extended tasks (40 minutes) with GPT-5.4 sleep tool consume 10x more estimated cost ($4.65 vs $0.48) and complete fewer tasks (56% vs 69%) compared to wait_for tool
- Token usage per task ranges from 70,000 to over 500,000 tokens depending on model and configuration
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.05342.
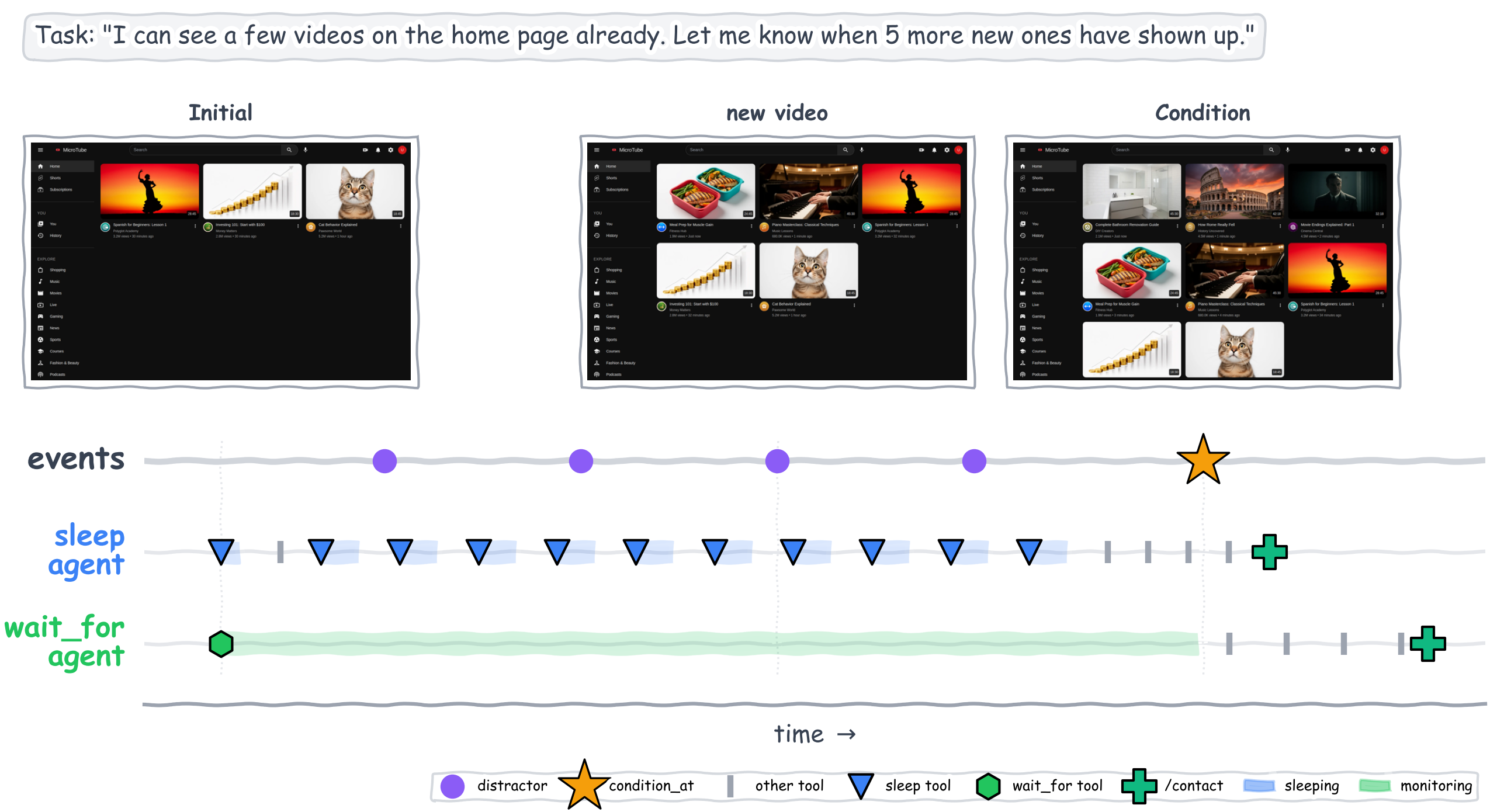
Fig 1: Agent execution timelines in SentinelBench for a representative scenario. Each row visualizes
Fig 2: Four SentinelBench environments. Each consists of a synthetic environment with a live web
Fig 3: Anatomy of a SentinelBench monitoring task: prompt, environment UI at the trigger moment,
Fig 4 (page 2).
Fig 5 (page 2).
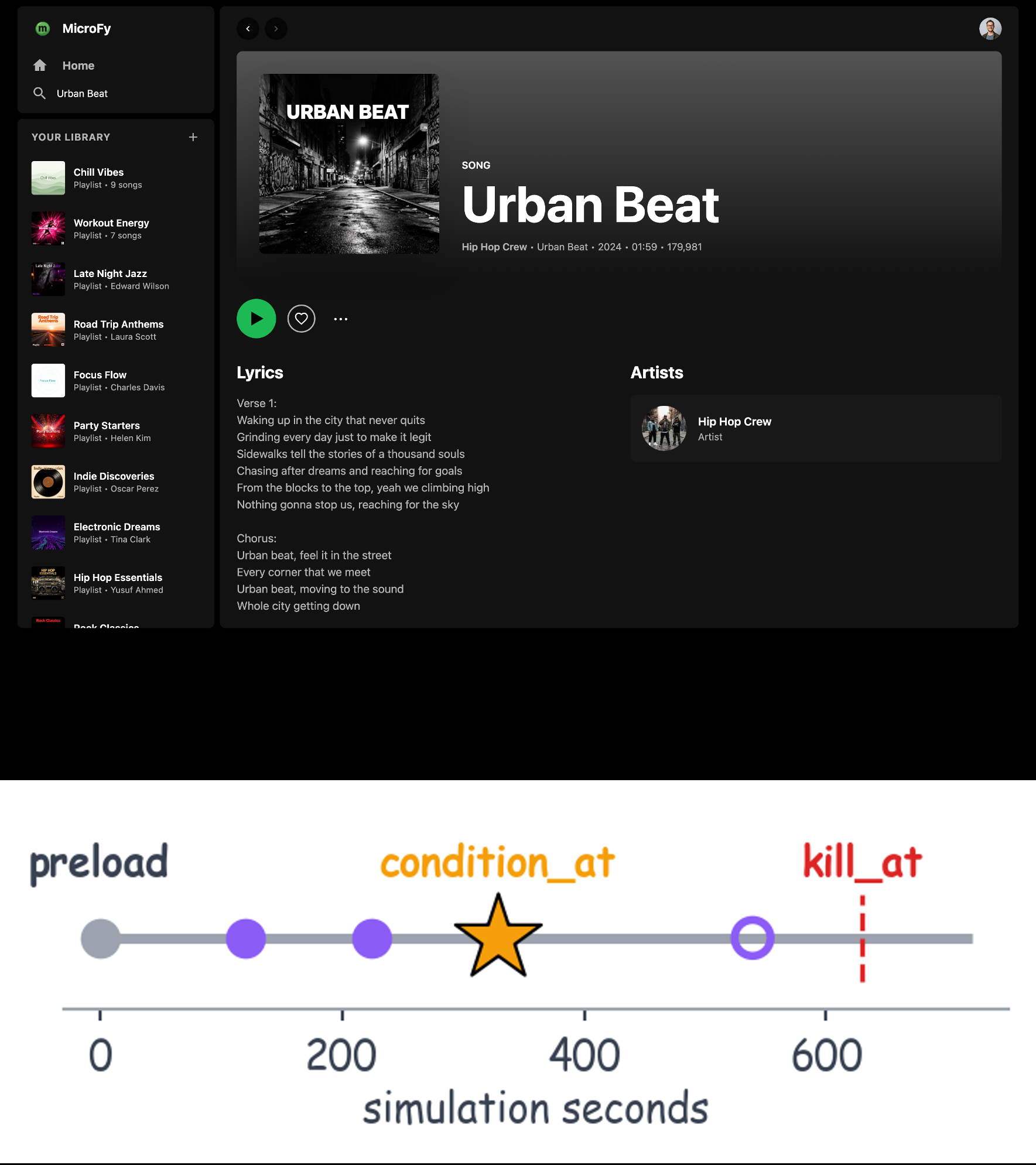
Fig 4: SentinelBench includes 100 synthetic user personas. Each persona consists of core demographic

Fig 7 (page 5).

Fig 5: The simulation life cycle for SentinelBench environments. The evaluation harness interacts with
Limitations
- Benchmark uses synthetic web applications and generated personas; while realistic, they do not represent production systems, so results may not fully transfer.
- Environment complexity is moderate; some real-world variability (e.g., noise, concurrency) is not modeled.
- Agent evaluations rely on pretrained LLMs with fixed inference prompting; no agent training or fine-tuning was performed specifically for these tasks.
- Reaction time and cost metrics assume agents self-report token usage; agents lacking instrumentation may have incomplete cost accounting.
- The wait_for tool implementation is heuristic and lightweight; more sophisticated monitoring or event subscription strategies are unexplored.
- No adversarial or robustness evaluation against manipulative environments or malicious agents is included.
Open questions / follow-ons
- How can wait_for style conditional monitoring strategies be extended or optimized using specialized event-driven web scraping or visual understanding frameworks?
- What are the tradeoffs between passive and active monitoring strategies in real user-facing applications with real network delays and intermittent updates?
- How do agent architectures that include memory or stateful episodic recall perform compared to stateless snapshot-based monitoring within SentinelBench’s relative task conditions?
- Can reinforcement learning or fine-tuning on SentinelBench tasks improve agent cost-efficiency and reaction time beyond zero-shot LLM prompting?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, SentinelBench is relevant because monitoring agents that respond to long-duration, low-signal events require balancing responsiveness with cost — a critical consideration for detecting and filtering suspicious automated behavior over extended interactions. The benchmark’s synthetic but realistic web environments model tasks that agents need to monitor stateful services and respond to changes, paralleling scenarios where bot detectors must continuously watch user behavior or session state.
Applying insights from SentinelBench, bot-defense engineers might design agents or CAPTCHAs that exploit the reaction-cost tradeoffs for long-running tasks, e.g., forcing bots to waste resources via polling inefficiencies or delayed event reaction. The wait_for conditional monitoring concept could inspire more nuanced challenge-response mechanisms that detect bots relying on continuous, costly polling versus more human-like event-driven interaction patterns. The multi-metric evaluations combining success, reaction time, and cost are a helpful framework to assess bot detection mechanisms in realistic long-duration user workflows.
Cite
@article{arxiv2606_05342,
title={ SentinelBench: A Benchmark for Long-Running Monitoring Agents },
author={ Matheus Kunzler Maldaner and Adam Fourney and Amanda Swearngin and Hussein Mozzanar and Gagan Bansal and Maya Murad and Rafah Hosn and Saleema Amershi },
journal={arXiv preprint arXiv:2606.05342},
year={ 2026 },
url={https://arxiv.org/abs/2606.05342}
}