
Benchmarking Living-Screen-Native GUI Agents on Short-Video Platforms
Source: arXiv:2606.04701 · Published 2026-06-03 · By Jiashu Yao, Heyan Huang, Daiqing Wu, Wangke Chen, Huaxi Ai, Haoyu Wen et al.
TL;DR
This paper addresses the challenge of building GUI agents that operate on continuously evolving, dynamic screens as found in short-video platforms, where video content plays autonomously and a user must decide what content to watch and for how long. Existing GUI agent benchmarks assume static, frozen screens between discrete agent actions, limiting their applicability to real-world dynamic interfaces. To fill this gap, the authors formalize the concept of Living-Screen-Native GUI agents, which proactively decide both actions and observation durations on continuous-time video-bearing screens.
They introduce LIVINGSCREEN, the first benchmark for this setting, instantiated as a high-fidelity browser-based environment replicating a modern short-video app with a rich GUI and video feed. It includes a three-tier task suite probing elementary GUI actions, multi-source reasoning, and closed-loop applications like content moderation and fact-checking. The benchmark also proposes new metrics jointly measuring task accuracy and information acquisition efficiency. Extensive evaluations across a diverse set of state-of-the-art multimodal large language models (MLLMs) reveal that none match human-level cost-accuracy tradeoffs. The dominant failure mode identified is a fundamental miscalibration of observation control, manifesting as systematic over- or under-observation of videos within the feed. This exposes observation control—the agent's active decision of what and how long to watch—as a critical and understudied capability for future GUI agents.
In sum, the paper makes the conceptual and practical case for expanding GUI agent research to living screens with agent-initiated, cost-aware observation; provides the LivingScreen benchmark to rigorously study this; and delivers empirical insights revealing fundamental limitations of current MLLMs on this frontier.
Key findings
- LIVINGSCREEN benchmark contains 499 tasks over 1,528 unique videos, averaging 5.62 videos per task.
- Human performance achieves 94.0% average success rate (SR) with 9.7 number of steps (NS) and 17.5% watch ratio (WR) on closed-loop tasks, far surpassing all evaluated models.
- Top-performing video-input MLLM Gemini-3.5 achieves 69.3% average SR with 8.0 NS and 11.9% WR overall, still significantly below humans (Table 1).
- MLLMs show divergent observation behaviors: some over-observe (high WR, e.g., Seed-1.8 with 25.1% WR) while others under-observe (low WR but lower SR, e.g., Kimi-K2.5).
- Human users employ a costly but efficient strategy of brief glances (52% of videos glanced) before committing to longer watches; models rarely mimic this, showing only ~26% glanced videos (Fig 3).
- Quantitative annotation finds under-observation occurs on 39–61% of sampled agent trajectories and over-observation on 25–43%, with 9–24% exhibiting both (Table 3).
- Prompting the agent to watch less, more, or mimic human observation patterns shifts watch ratio but does not improve task success, indicating these failures are capability deficits rather than awareness gaps (Table 4).
- Ablation experiments on agent design parameters confirm that agent architecture is not the performance bottleneck; underlying MLLM capabilities dominate (Table 2).
Threat model
The threat model considers an autonomous GUI agent interacting with a living, continuously evolving short-video platform screen through rendered pixels only, without privileged access to video files or internal APIs. The adversary can decide what and how long to observe via pixel-level 'watch' actions and can perform GUI operations including clicks, swipes, and typing. The agent is constrained to operate in real-time continuous state without rewinding or offline access. It cannot manipulate the platform beyond GUI interactions, nor access external knowledge beyond visual feed and metadata on screen. This models realistic users or autonomous assistants, not omniscient adversaries.
Methodology — deep read
Threat Model and Assumptions: The adversary is modeled as a GUI agent operating on a living, continuously-evolving screen of a short-video platform. The environment autonomously advances video playheads and updates the screen state independently of agent actions (Equation 1). The agent does not have privileged access to underlying video files or metadata outside what is rendered on the screen. It decides both what GUI actions to perform (click, swipe, report, etc.) and for how long and at what frame rate to observe video content via a 'watch' action (Equation 3). The task is partially observable and requires cost-aware information gathering.
Data: The video corpus consists of 1,528 unique short videos aggregated primarily from publicly available Chinese short-video datasets, with less than 1% synthesized videos for rare edge cases. Each video includes metadata such as titles, hashtags, comments, and user profiles. Tasks are crafted by graduate-level annotators who curate feeds from keyword clusterings, inject distractors, and author multi-level task queries with ground-truth answers. A three-stage quality control process (annotator calibration, shortcut filtering via DeepSeek-V4, and cross-review) ensures high-quality and non-trivial tasks. The final benchmark includes 499 tasks, split into three tiers (L1 atomic GUI actions, L2 cross-source understanding, and L3 closed-loop applications) with various question formats (multiple-choice, declarative state).
Architecture / Algorithm: The backbone agent architecture is held constant for all experiments, wrapping various pre-existing frontier multimodal large language models (MLLMs) as the reasoning core. Models evaluated include Gemini-3.5-Flash, Gemini-3.1-Pro, Doubao-Seed family, Qwen-3.x, GLM-5V-Turbo, Kimi-K2.5, Claude-Opus, Claude-Sonnet, GPT-5.5, and GPT-5.4. The agent inputs are screenshots or short screen recordings under its watch control, and outputs are discrete GUI primitive actions or observation commands. Key innovation is elevating watch actions as first-class with time window and frame rate parameters, allowing endogenous, cost-bearing observation control. The agent retains all past history but keeps only the most recent observation media in context to limit memory.
Training Regime: Models are evaluated zero-shot as publicly released MLLMs, with no additional fine-tuning performed. Temperature is fixed at 0.6 and prompt engineering uses a uniform think-then-tool-call format. Agent episodes are capped at 30 steps to control complexity. Ablation experiments vary maximum steps (20-40), observation retention length (1-5), and explicit reasoning prompts to confirm that agent design choices are not bottlenecks. All experiments run on suitable GPU hardware but exact details are not specified.
Evaluation Protocol: Metrics include Success Rate (SR) measuring task accuracy per tier; Number of Steps (NS) counting agent action invocations; and Watch Ratio (WR) quantifying fraction of video feed watched. SR is measured by comparing final environment state against ground truth or model multiple-choice answers. Evaluations cover all three task tiers L1-L3. Efficiency metrics punish agents that oversample observations or perform unnecessary steps. Human annotators provide baseline performance. Failure modes are qualitatively and quantitatively explored by detailed annotation of 100 agent trajectories per model, flagging over- vs under-observation issues. Prompt variants are tested to verify causal influences on observation behavior.
Reproducibility: The entire LIVINGSCREEN environment, tasks, videos, and evaluation pipeline are publicly released on GitHub. The video collection is drawn from public datasets under their existing licenses. The benchmark code and annotated task sets are available for independent benchmarking. The model weights used are standard publicly available MLLMs, and no closed proprietary data is used. However, the main experiments use Chinese-language short-video content, which may limit applicability.
Example Walkthrough: For one closed-loop content moderation application (L3 task), the agent is presented with a feed of 4-6 short videos plus metadata. At each step, it decides whether to watch a video clip for some duration frame-by-frame, skip it, or perform GUI actions like reporting content or liking. The agent's observation window and frame rate determine the temporal slice it receives as input. After collecting sufficient information, the agent issues a final labeled action (e.g., report videos violating policy). Success depends on observing relevant evidence efficiently without wasting steps, balancing SR with NS and WR. Human users approximate this by glancing briefly then deciding which videos to fully watch, while models either watch too much irrelevant content or too little relevant content, hurting efficiency and accuracy.
Technical innovations
- Formalization of Living-Screen-Native GUI agents operating on continuous-time evolving screens with agent-controlled observation windows, differing from standard discrete-time frozen GUI benchmarks.
- Development of LIVINGSCREEN benchmark including a high-fidelity browser-based environment faithfully replicating a short-video platform's dynamic feed with pixel-level GUI actions and observations.
- Introduction of watch primitive as a first-class agent action controlling spatiotemporal observation granularity (duration, frame rate) instead of fixed passive video input.
- Joint evaluation metrics combining task success rate (accuracy) with information efficiency components (number of steps and watch ratio), capturing the new tradeoff for living-screen agents.
- Systematic empirical study revealing over- and under-observation as dominant and co-occurring failure modes of current MLLMs in this setting, highlighting observation control as a critical dimension for GUI agent research.
Datasets
- LIVINGSCREEN Video Corpus — 1,528 unique short videos — curated from public Chinese short-video datasets (Ma et al., 2019; Qi et al., 2023), plus <1% synthesized videos (Liu et al., 2025)
- LIVINGSCREEN Task Set — 499 tasks annotated and quality-controlled by domain-expert annotators — created specifically for this benchmark
Baselines vs proposed
- Human Baseline: Average Success Rate (SR) = 94.0%, Number of Steps (NS) = 9.7, Watch Ratio (WR) = 17.5%
- Gemini-3.5-Flash: SR = 69.3%, NS = 8.0, WR = 11.9% vs Human SR 94.0%
- Doubao-Seed-1.8: SR = 65.6%, NS = 9.5, WR = 25.1% vs Human WR 17.5%
- Kimi-K2.5: SR = 36.8%, NS = 11.7, WR = 20.2% vs Human SR 94.0%
- Qwen-3.6-Plus: SR = 44.9%, NS = 10.5, WR = 10.9% vs Human SR 94.0%
- Prompting seed-1.8 watch less: SR 56.3%, WR 19.3% vs default SR 65.6%, WR 25.1%, showing efficiency gains but accuracy drops
- Prompting seed-1.8 mimic-human: SR 59.4%, WR 23.6% vs default SR 65.6%, WR 25.1%, no improvement in success rate
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.04701.
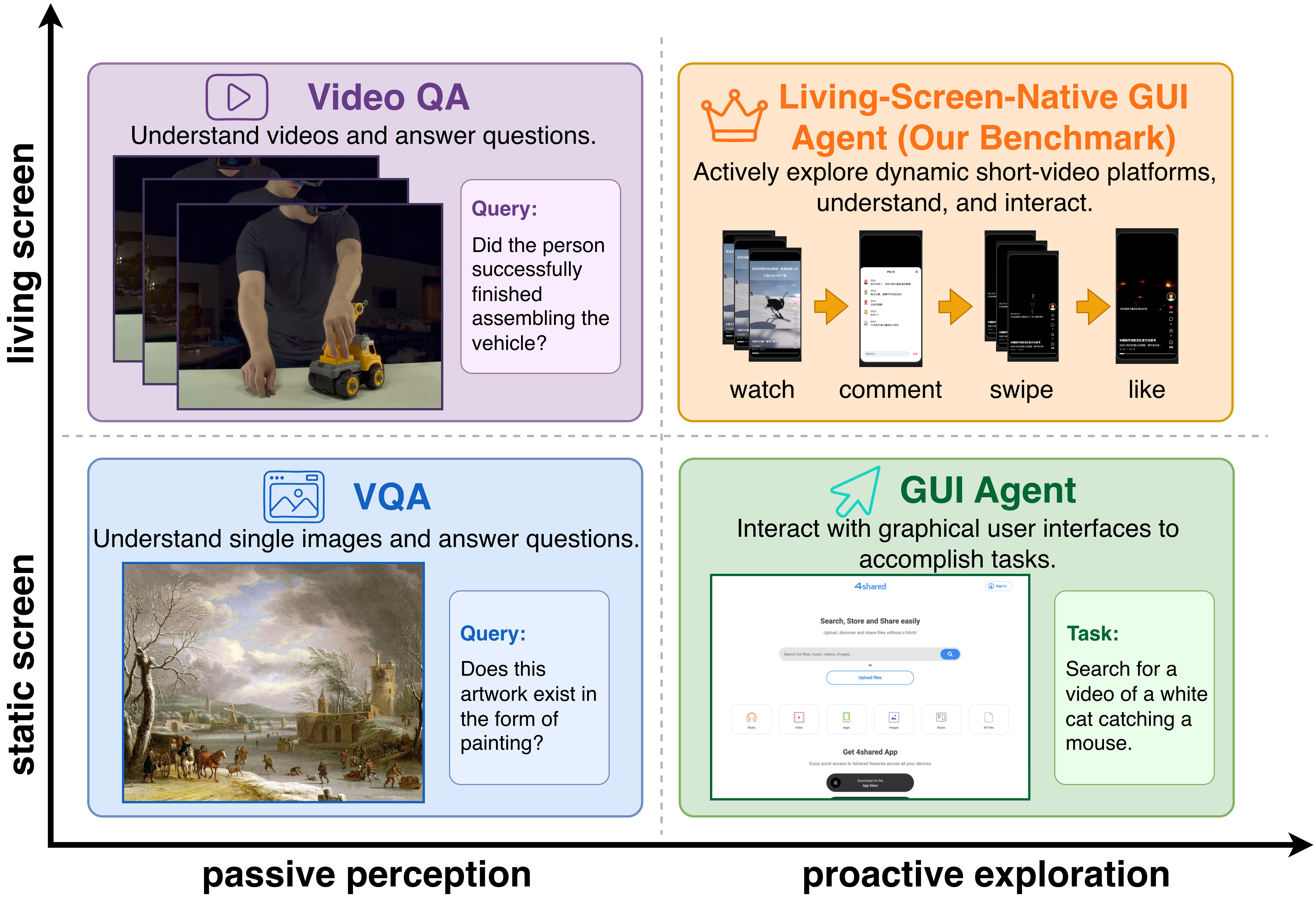
Fig 1: Positioning living-screen-native GUI agents.
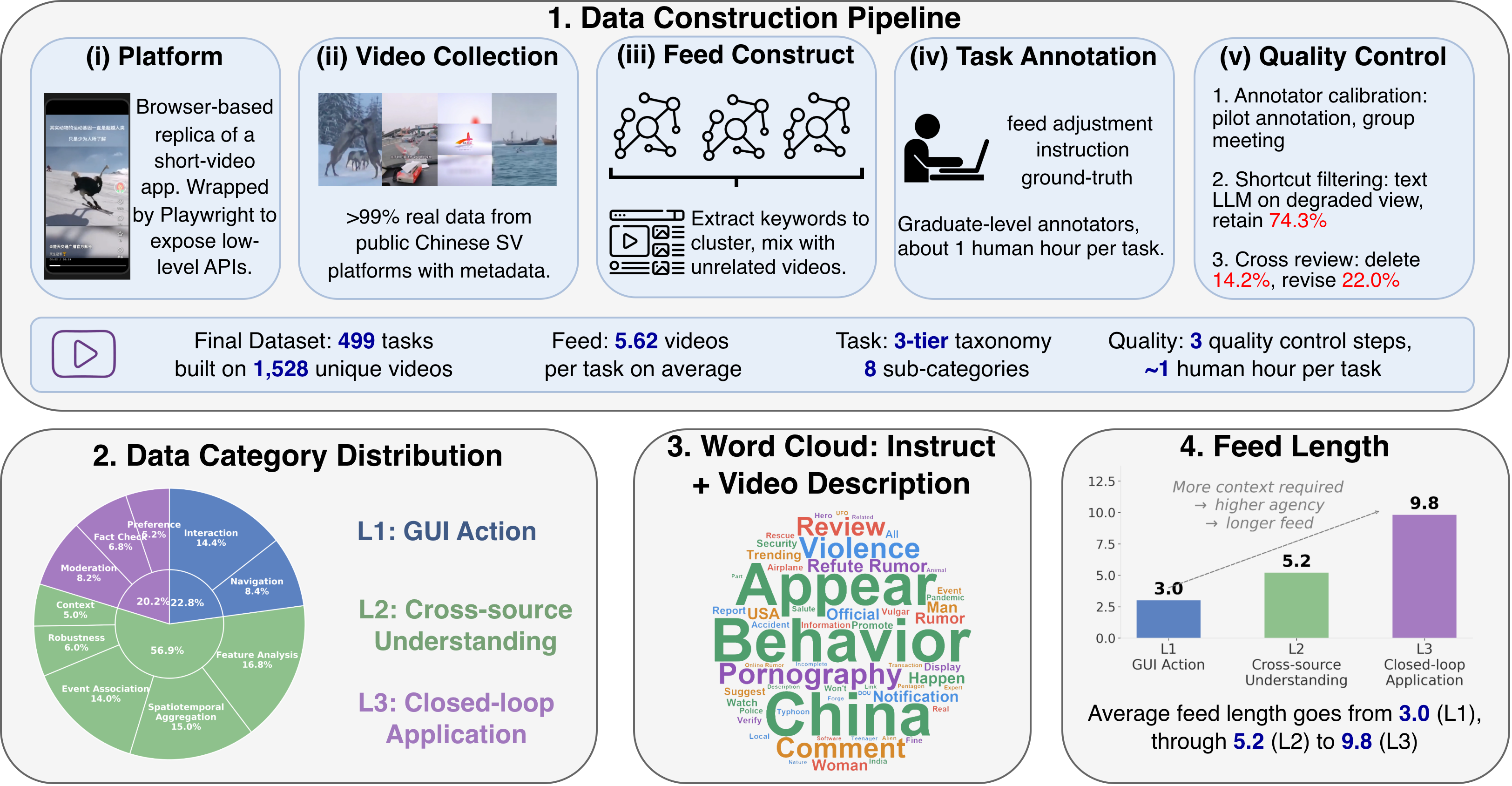
Fig 2: Illustration of LIVINGSCREEN.
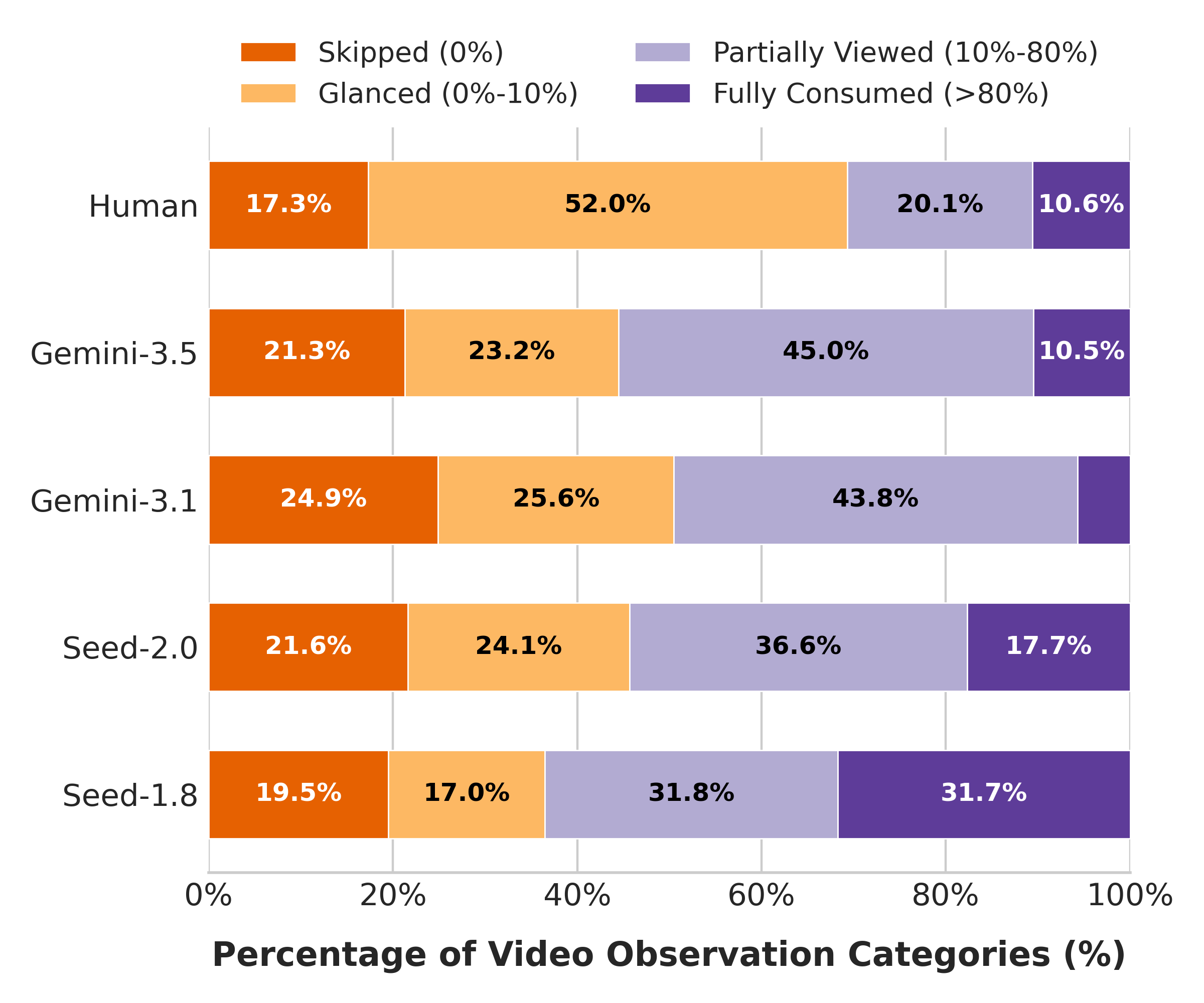
Fig 3: (Gemini-3.5, Gemini-3.1, Seed-2.0, Seed-
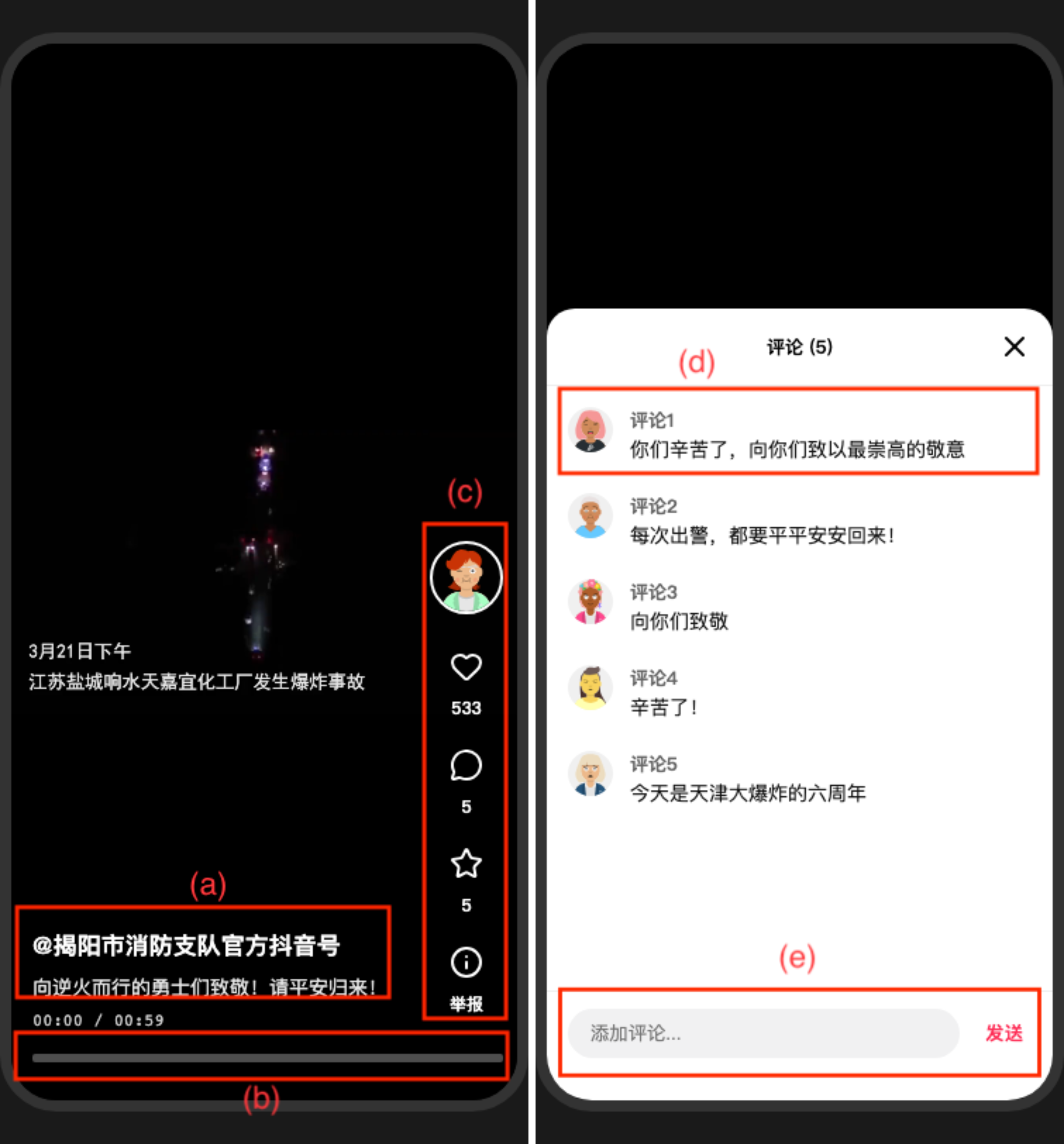
Fig 4: shows the full LIVINGSCREEN interface
Limitations
- Environment is a high-fidelity browser replica and does not model live recommendation engines, personalization, social graphs, or deployed platform dynamics, limiting ecological validity.
- All videos, comments, and tasks are in Chinese from a single platform ecosystem, which may limit generalizability to other languages or short-video apps with different interfaces and user behaviors.
- Annotation scale of 499 tasks and 100 agent trajectory samples per model is moderately sized but smaller than some large-scale video QA benchmarks due to high annotation effort, potentially limiting statistical power for some analyses.
- Evaluations rely on publicly released MLLMs without adaptation or fine-tuning to the benchmark, which could underrepresent potential performance improvements from task-specific training.
- No adversarial or manipulated content stress tests were performed, so robustness against intentional evasion or adversarial manipulation remains untested.
- Observation control failures are characterized but no novel agent architecture or training method to close the gap is presented here.
Open questions / follow-ons
- How can observation control be integrated into agent architectures and training to mitigate over- and under-observation failure modes?
- What are effective policies or reinforcement learning approaches to jointly optimize cost-aware observation and accurate video content understanding in living-screen settings?
- How do observation control strategies and benchmark performance generalize across other languages, cultural contexts, and distinct short-video platforms with different UI affordances?
- Can integrating privileged access (e.g., video content indexing) or multimodal side information about videos improve living-screen-native agent performance while preserving realistic deployment constraints?
Why it matters for bot defense
The paper's insights into observation control and cost-aware information gathering have direct relevance for bot defense and CAPTCHA practitioners aiming to detect or thwart automated agents on dynamic multimedia platforms. Specifically, the characterization of over- and under-observation behaviors in autonomous agents offers a novel axis for behavioral analysis that CAPTCHA systems could exploit. For instance, monitoring whether an entity performs rational glance-and-commit viewing or excessive, inefficient consumption could help differentiate bots from genuine human users. Additionally, benchmarks like LIVINGSCREEN provide realistic testing grounds for evaluating agent robustness and adaptability to continuously evolving GUI environments common in modern web and mobile apps.
Furthermore, the formal notion of agent-initiated, cost-bearing observation actions expands the landscape of possible bot behaviors beyond traditional static or passive interaction schemes. Bot-defense strategies must consider that advanced agents may adaptively control how much and how long they observe UI content before acting, complicating detection based solely on action timing or click patterns. Hence, incorporating multimodal and temporal metrics related to observation control into CAPTCHA challenge design could enhance resilience against sophisticated GUI agents. Overall, this work motivates a deeper understanding and measurement of observation strategies as part of comprehensive bot detection and defense.
Cite
@article{arxiv2606_04701,
title={ Benchmarking Living-Screen-Native GUI Agents on Short-Video Platforms },
author={ Jiashu Yao and Heyan Huang and Daiqing Wu and Wangke Chen and Huaxi Ai and Haoyu Wen and Zeming Liu and Yuhang Guo },
journal={arXiv preprint arXiv:2606.04701},
year={ 2026 },
url={https://arxiv.org/abs/2606.04701}
}