
Activation Steering of Video Generation Models via Reduced-Order Linear Optimal Control
Source: arXiv:2606.04775 · Published 2026-06-03 · By Jihoon Hong, Alice Chan, Qiyue Dai, Julian Skifstad, Glen Chou
TL;DR
This paper addresses the problem of safely steering text-to-video (T2V) diffusion transformer models to reduce unsafe content generation without degrading visual quality or prompt fidelity. Current activation steering methods for T2V models apply coarse, non-anticipative interventions that can oversteer, degrade content, or fail to anticipate how perturbations propagate at inference time. To overcome these challenges, the authors propose Latent Activation Linear-Quadratic Regulator (LA-LQR), a reduced-order optimal control framework. LA-LQR models the T2V generation process as a nonlinear dynamical system on internal activations and computes minimally invasive closed-loop feedback interventions to steer latent feature activations toward desired setpoints that correspond to safe or preferred concepts. To make this tractable given the immense dimensionality (tens of millions), they project activations into a low-dimensional latent subspace obtained via randomized SVD on contrastive prompt pairs differing by target features. Local linear approximations of latent dynamics yield a linear time-varying system on which LQR computes efficient timestep- and layer-specific steering signals. The approach preserves video and prompt fidelity while substantially reducing unsafe content on benchmark safety datasets when applied at inference. Theoretical analyses relate latent-space setpoints to raw activations, empirically validating model fidelity. LA-LQR outperforms prior activation steering and defense baselines, striking a balance between safety and content quality.
Key findings
- Activation steering performed in a low-dimensional latent space (D_lat = 64) captures >80% of contrastive feature energy for unsafe content concepts across layers and timesteps (Fig 2a).
- Latent-space Jacobians are consistent across prompts, validating reuse of locally linear dynamics for new inputs (Fig 2b).
- LA-LQR reduces unsafe generation violation rates on T2VSafetyBench from 31.9% (baseline [69]) to 14.6%, cutting violations by over 50% (Table 1).
- On SafeSora dataset, LA-LQR lowers average violation rate from 32.6% ([69]) to 12.2%, outperforming weight update and embedding-based baselines (Table 2).
- Video quality (VBench subject consistency) improves or remains stable with LA-LQR, e.g., 0.971 vs 0.962 average on T2VSafetyBench (Table 1).
- Content Alignment Preservation Score (CAPS) indicating prompt fidelity generally remains competitive compared to baselines, with minor variance (Tables 1 and 2).
- Controlling latent linear feature setpoints via LQR yields steering magnitude proportional to online latent feature error, enabling adaptive, minimal perturbations (Equation 20).
- Theoretical bounds tightly relate latent setpoint tracking errors to raw activation feature control errors, quantifying projection and linearization losses.
Threat model
The adversary crafts text prompts to induce T2V models to generate unsafe or harmful content exploiting latent unsafe concepts learned from large web datasets. They have no access to modify model weights or inference-time activation control inputs. The defender assumes white-box access to model weights and activations to perform inference-time steering via minimal perturbations on internal activations. The adversary cannot directly observe or tamper with the controller nor overcome its closed-loop feedback.
Methodology — deep read
Threat Model & Assumptions: The adversary is assumed to have white-box access to the T2V model weights and activations but cannot alter model weights or training. The adversary can supply prompts that cause unsafe or undesired content, exploiting latent unsafe concepts learned from weakly curated web data. The defense constrains outputs via inference-time activation steering. The adversary cannot directly observe or override internal activation-based controls.
Data: The method leverages paired contrastive prompt sets (D+ and D-) with and without the target unsafe or concept feature. The authors use publicly available safety benchmark datasets T2VSafetyBench and SafeSora containing harmful prompts labeled by categories such as pornography, gore, public figures, etc. They run the Wan 2.1-14B and HunyuanVideo-1.5 T2V models with these prompts to collect activations. For latent space construction, activation differences for pairs in D+ and D- form large contrastive matrices (dimensions up to tens of millions). Randomized SVD aggregates these into a low-rank latent basis.
Architecture / Algorithm: The T2V model is a diffusion transformer (DiT) with L transformer blocks and a reverse diffusion scheduler over T timesteps. Activations are indexed by layer l and timestep t (flattened as s). The generation is formulated as a nonlinear time-varying dynamical system x_{s+1} = f_s(x_s,u_s), where x_s are activations and u_s are control perturbations applied to text embeddings or video tokens at layer l and timestep t. To reduce dimensionality, activations x_s (dimension D_act ~ 10^7) are projected via Ps (constructed by top D_lat=64 right singular vectors of contrastive activation matrices) into latent states z_s = Ps x_s. Local linearizations give approximate linear dynamics z_{s+1} ≈ A_s z_s + B_s u_s in the latent space, with A_s, B_s computed using Jacobian-vector products without materializing full Jacobians.
Latent Linear Feature Setpoints (LLFS) β^_s define desired feature strength along the normalized latent feature direction v_s. The control objective is to minimize deviations from β^_s while applying minimal perturbations u_s. An LQR optimal controller synthesizes feedback gains K_s that produce timestep- and layer-specific steering signals u_s = K_s (β^*_s - v_s^T z_s) v_s adaptively based on current latent activation errors.
Training Regime: The controller uses a nominal latent activation trajectory computed from a representative prompt, linearizes around it, and solves discrete Riccati equations for feedback gains K_s. Since the latent dynamics and gains generalize well across prompts, online Jacobian recomputation is not required for new inputs. Hyperparameters like the latent subspace rank (D_lat=64), LQR cost matrices Q and R are tuned for steering strength vs perturbation minimization.
Evaluation Protocol: They evaluate LA-LQR against baselines [9], SAFREE [10], and [69] on T2VSafetyBench and SafeSora datasets with harmful prompts. Metrics include Violation Rate (% unsafe videos detected by GPT-4o evaluator), VBench video quality metrics (subject consistency reported), and Content Alignment Preservation Score (CAPS) measuring semantic similarity between steered and unsteered videos. Tests run on real T2V models (Wan2.1 and HunyuanVideo-1.5) over 41-frame videos. Ablations vary LQR parameters controlling steering strength. Statistical variance is reported as std deviations over samples.
Reproducibility: The paper mentions using publicly known model architectures and datasets but does not explicitly note released code or frozen weights (unclear). The randomized SVD and Jacobian computations rely on GPU streaming approximations. Implementation details are sufficiently described for reproduction using white-box DiT models and prompt contrastive pairs.
Concrete example: For steering the "color red" concept in Wan2.1, they construct contrastive prompts with and without "red," collect activation differences, compute the top 64 latent components, extract latent feature directions, and solve the LQR for optimal control gains. At inference, latent activations are projected, feature strength error computed, and corrective steering signals applied at each transformer layer and timestep, gradually increasing the presence of red in generated frames as LQR state cost parameter Q is increased (Fig 3). This demonstrates end-to-end latent LQR steering affecting video semantic content with minimal raw perturbation.
Technical innovations
- Formulation of T2V diffusion transformer inference as a nonlinear time-varying dynamical system amenable to control-theoretic steering.
- Construction of a reduced-order latent feature subspace by randomized SVD on contrastive activation vectors from paired prompts, enabling tractable low-dimensional control of very high-dimensional activations.
- Design of a latent linear-quadratic regulator (LA-LQR) feedback controller that adaptively steers latent activations toward feature setpoints with minimal perturbations, leveraging online error feedback.
- Theoretical bound relating latent feature setpoint tracking to raw activation-space feature control, quantifying projection fidelity and error propagation.
Datasets
- T2VSafetyBench — thousands of harmful prompts in categories such as pornography, gore, public figures — used for evaluation.
- SafeSora — harmful prompt dataset with categories like violence, terrorism, racism, sexual content, animal abuse — used for evaluation.
Baselines vs proposed
- Wan model baseline [69]: Violation Rate average = 31.9% vs LA-LQR: 14.6% (over 50% reduction) on T2VSafetyBench (Table 1).
- Wan model baseline [10] SAFREE: 26.1% violation rate vs LA-LQR: 14.6% on T2VSafetyBench.
- [9] baseline: 36.9% violation rate vs LA-LQR: 14.6% on T2VSafetyBench.
- HunyuanVideo-1.5 baseline [69]: 32.6% violation rate vs LA-LQR: 12.2% on SafeSora (Table 2).
- [10] baseline SAFREE: 28.6% vs LA-LQR: 12.2% on SafeSora.
- [9] baseline: 31.5% vs LA-LQR: 12.2% on SafeSora.
- VBench subject consistency average: Baselines ~0.93–0.96 vs LA-LQR 0.97–0.97 (Tables 1 and 2).
- CAPS (content alignment): Baselines range 0.62-0.82 vs LA-LQR ~0.58-0.67 with some variance (Tables 1 and 2).
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.04775.

Fig 1: Overview. Our method, LA-LQR, steers T2V
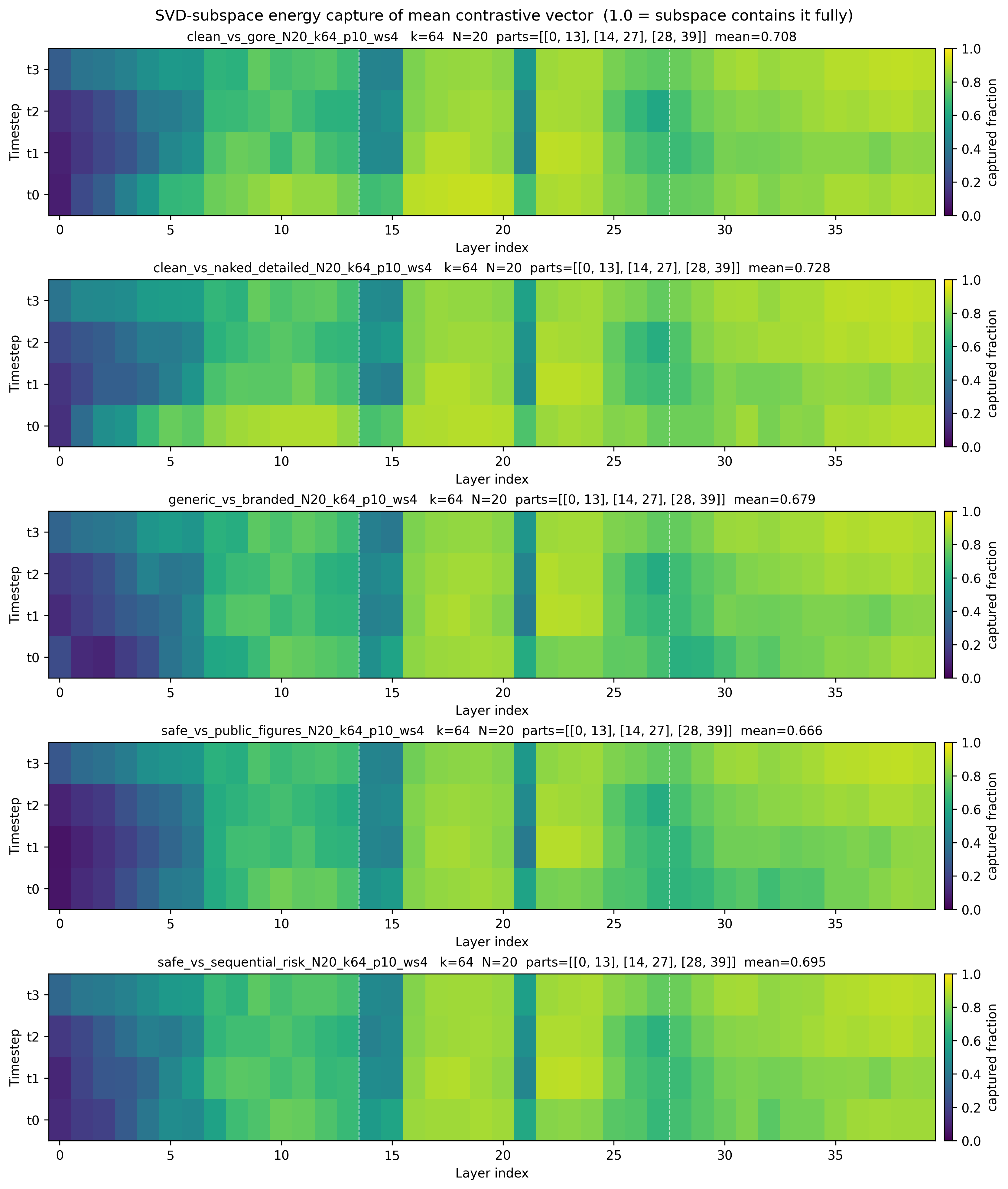
Fig 2: (a) Proportion of energy of Cr matrices captured in the subspace spanned by the top-

Fig 3: Steering the concept of “the color red" in Wan, with increasing steering strength. (a)

Fig 4: Safeguarding Wan against harmful prompts from T2VSafetyBench [63]. For each example,

Fig 13: Filtering- and embedding-based methods such as SAFREE [10] and [69] also struggle on

Fig 6 (page 9).

Fig 7 (page 9).

Fig 8 (page 9).
Limitations
- The approach assumes white-box access to T2V model weights and activations, limiting applicability to closed models or black-box APIs.
- Linear time-varying approximations may break down under highly nonlinear activation dynamics or out-of-distribution prompts.
- The latent subspace constructed relies on paired prompts with contrastive features, requiring curation and limiting generalization to unseen concepts.
- Evaluations focus on reducing explicit unsafe content categories; other subtle biases or harms remain unexamined.
- CAPS semantic similarity scores for some categories showed variance or degradation compared to baselines, indicating occasional prompt fidelity loss.
- No explicit adversarial robustness analysis presented; adaptive prompt attacks could potentially bypass steering.
Open questions / follow-ons
- Can the LA-LQR approach generalize to unseen or open-world unsafe concepts without curated contrastive prompt pairs?
- How robust is LA-LQR steering to adversarial prompt attacks optimized to evade latent feature detection and control?
- Can latent linear-quadratic control be extended with nonlinear or deep models for improved fidelity and dynamic adaptation over longer horizons?
- What are the tradeoffs between steering strength, prompt fidelity, and video quality under different LQR cost formulations across diverse model architectures?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners focused on bot detection and prevention of malicious content in automated video generation, this work presents a novel inference-time mechanism to suppress unsafe or harmful content emanating from T2V models without retraining or modifying model weights. Such minimally invasive activation steering via reduced-order optimal control can be integrated into deployment pipelines to dynamically modulate video generations when suspicious or harmful prompts are detected. The closed-loop feedback controller allows adaptive interventions that balance content safety against fidelity, avoiding overly aggressive filtering that harms user experience. This method provides a mechanistic alternative to brittle prompt filtering or costly fine-tuning, with the theoretical rigor and empirical validation demonstrating practical efficacy. However, practitioners should note that this requires white-box access and carefully curated concept representations, which may limit applicability to proprietary models. Further research on adversarial robustness and scalability to open-concept spaces would be necessary to deploy such control architectures reliably at scale.
Cite
@article{arxiv2606_04775,
title={ Activation Steering of Video Generation Models via Reduced-Order Linear Optimal Control },
author={ Jihoon Hong and Alice Chan and Qiyue Dai and Julian Skifstad and Glen Chou },
journal={arXiv preprint arXiv:2606.04775},
year={ 2026 },
url={https://arxiv.org/abs/2606.04775}
}