
Quantifying Faithful Confidence Expression in Large Reasoning Models
Source: arXiv:2606.03969 · Published 2026-06-02 · By Areeb Gani, Asal Meskin, Gabrielle Kaili-May Liu, Arman Cohan
TL;DR
This paper addresses a foundational problem in large language models (LLMs) used for complex reasoning tasks: how well do these models faithfully express their internal confidence through their linguistic outputs? The authors define faithful calibration (FC) as the alignment between a model's intrinsic uncertainty and the confidence it conveys in language. This is critical because reasoning traces with coherent confidence expression help users calibrate trust and decision-making. Existing evaluation approaches for FC focus on short outputs or non-reasoning settings and do not generalize well to large reasoning models (LRMs) that produce long, chain-of-thought (CoT) outputs with complex dependencies and varying step granularities.
The main contribution is a novel framework to quantify FC in LRMs. It leverages three complementary intrinsic confidence estimators—representation-based recurrent confidence chain (RCC), token log-probabilities (DeepConf), and prefix-conditioned sampling-consistency—to capture different uncertainty facets. Linguistic decisiveness is measured by prompting a separate LLM judge to score the certainty conveyed in each reasoning step. The framework aggregates per-step alignment scores into trace- and dataset-level FC metrics. Applying this to 7 LRMs across 5 reasoning datasets (mathematics, science, legal, etc.) and multiple prompt interventions, the authors find that faithful confidence expression remains a significant challenge. Reasoning ability itself does not substantially improve FC compared to non-reasoning models, common prompting strategies that improve FC in simpler LLMs fail in the reasoning setting, and the three confidence estimators yield divergent assessments. Distillation also changes FC profiles in complex ways unrelated to accuracy or model size.
Overall, their results demonstrate that faithfully communicating uncertainty through language is a distinct and under-explored reliability problem for LRMs, which deserves focused attention as such models become widely deployed in high-stakes decision-making domains.
Key findings
- Faithful calibration (FC) scores (cMFG*) for LRMs generally lie between 0.64 and 0.78 across datasets, indicating moderate but imperfect alignment between intrinsic confidence and linguistic decisiveness.
- Model size has limited effect on FC: DeepSeek-R1-8B and QwQ-32B achieve comparable FC scores despite a 4x parameter difference.
- Reasoning training via fine-tuning on chain-of-thought data decreases linguistic decisiveness without reducing intrinsic confidence, resulting in degraded FC (e.g., LM-synthetic checkpoints have lower cMFG* than instruction-tuned bases).
- Prompting interventions (e.g., perception prompts, metacognitive prompts) improve accuracy but do not improve FC metrics consistently in LRMs.
- The three intrinsic confidence estimators (RCC, DeepConf, sampling consistency) disagree substantially on the same traces, with DeepConf yielding the highest FC and sampling consistency the lowest.
- Distilled models exhibit different FC behavior than their teachers; e.g., distilled DeepSeek-R1-Qwen3-8B is more decisive and internally confident leading to higher FC on some datasets, indicating distillation reshapes uncertainty expression policies.
- Later reasoning steps do not uniformly exhibit higher FC; temporal confidence trajectories differ by model and estimator, suggesting complex dynamics in confidence expression over a trace.
- Accuracy and FC are decoupled: FC remains stable even when accuracy varies considerably, showing FC as a distinct reliability dimension.
Threat model
The adversary is not explicitly modeled since this is a reliability and alignment analysis rather than an attack scenario. The setting assumes benign users and models generating reasoning traces; the key issue is the models’ inability to faithfully express intrinsic confidence in language. There is no consideration of malicious or adversarial inputs, but rather focus on intrinsic epistemic uncertainty and linguistic calibration under normal operating conditions.
Methodology — deep read
The authors set out to systematically quantify faithful calibration (FC) in large reasoning models (LRMs) where language output contains long, dynamic chain-of-thought (CoT) reasoning traces. The threat model assumes standard user-facing settings where models generate multi-step reasoning outputs, and the question is how well the expressed uncertainty aligns with internal confidence.
Data: They evaluate 7 models ranging from 7B to 671B parameters including reasoning-tuned and distilled variants, on 5 datasets covering math (AIME), science (SuperGPQA), legal (LegalBench), and open-domain reasoning (HLE, MuSR). Each (model, dataset) pair is evaluated on roughly 1000 examples to ensure robust metrics.
Framework: For each generated reasoning trace—a sequence of steps s1,...,sn ending with an answer—they define intrinsic confidence C(si) per step via three estimators: 1) RCC (Representation-based Confidence Chain) leveraging final-layer hidden states and an inter-step relevance filter computed recurrently to capture propagated confidence; 2) DeepConf uses token-level negative mean log-probabilities capped to [0,1]; 3) Sampling consistency judges confidence by resampling continuations conditioned on the prefix and measuring semantic consistency with the original step.
Linguistic confidence (decisiveness D(si)) is estimated by prompting an external LLM judge model (Gemini-2.5-Flash) trained to score hedging language on a [0,1] scale aligned with human annotations.
Faithfulness is computed per step as F(si) = 1 - |D(si) - C(si)|, then aggregated to trace-level via averaging over valid steps. To stabilize dataset-level measurements, they introduce cMFG*, a width-weighted conditional mean faithfulness gap using equal-mass confidence bins, improving over prior fixed-width binning.
They also devise a novel prefix-conditioned sampling approach for the sampling consistency estimator, controlling for step-conditional dependencies when comparing resampled steps.
Prompt interventions adapted from prior work include baseline task prompts, perception prompts to elicit confidence awareness, and MetSens+Hedge meta-cognitive prompts aimed at improving FC.
Training details vary per model, but include supervised finetuning with chain-of-thought data (SYNTHETIC-1), distillation from larger models, and reinforcement learning components in some cases.
For evaluation: FC metrics are reported alongside accuracy and decisiveness, using multiple confidence estimators and prompt variants. Extensive ablations examine the impact of model size, reasoning training, distillation, prompt intervention, and estimator choice.
Reproducibility is supported by released code and detailed experimental setup, but some large-scale models/datasets (e.g., SYNTHETIC-1) remain restricted or internally maintained.
Example end-to-end: For a given math reasoning problem, the model produces a chain-of-thought trace s1 to sn. For each step, the framework extracts internal confidence using RCC/DeepConf/sampling consistency, then prompts Gemini-2.5 to score the step’s linguistic decisiveness. The absolute gap yields step-level faithfulness; averaging across steps produces a trace FC score. Multiple traces yield dataset-level statistics, facilitating comparisons across models and intervention conditions.
Technical innovations
- A unified framework combining three complementary intrinsic confidence estimators—representation-based (RCC), token log-probability (DeepConf), and sampling consistency—adapted for application to complex, long-form reasoning traces.
- Introduction of prefix-conditioned sampling for stability-based confidence estimation, controlling for the complex conditional dependencies in chain-of-thought outputs.
- Width-weighted conditional mean faithfulness gap metric (cMFG*) leveraging equal-mass confidence bins for robust, stable faithful calibration measurement in narrow confidence ranges encountered in LRMs.
- Systematic empirical study differentiating the impacts of reasoning training and distillation on faithful confidence expression distinct from accuracy or linguistic style.
Datasets
- AIME — ~933 examples — public math olympiad problems dataset
- HLE — 1000 examples — broad-domain expert-level questions, source not explicitly public
- SuperGPQA — 1000 examples — graduate-level scientific questions dataset
- LegalBench — 1000 examples — legal reasoning benchmark dataset
- MuSR — 756 examples — multi-step soft reasoning dataset, source unspecified
Baselines vs proposed
- DeepSeek-R1-8B on AIME: cMFG* (RCC) = 0.788 vs QwQ-32B on AIME: cMFG* (RCC) = 0.777
- DeepSeek-R1-8B on LegalBench: cMFG* (DeepConf) = 0.674 vs QwQ-32B on LegalBench: cMFG* (DeepConf) = 0.737
- Llama-3.1-8B-Instruct (instruction-tuned) on AIME: cMFG* (DeepConf) = 0.775 vs Llama-3.1-Synthetic-1 (reasoning-tuned) on AIME: cMFG* (DeepConf) = 0.842 but decisiveness sharply drops
- DeepSeek-R1 teacher on HLE: cMFG* (DeepConf) = 0.736 vs distilled DeepSeek-R1-Qwen3-8B on HLE: cMFG* (DeepConf) = 0.785
- Prompt baseline vs perception and MetSens+Hedge prompts: accuracy improved up to ~0.06 but mean cMFG* changed by ~0.00, i.e., no faithful calibration gains
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.03969.
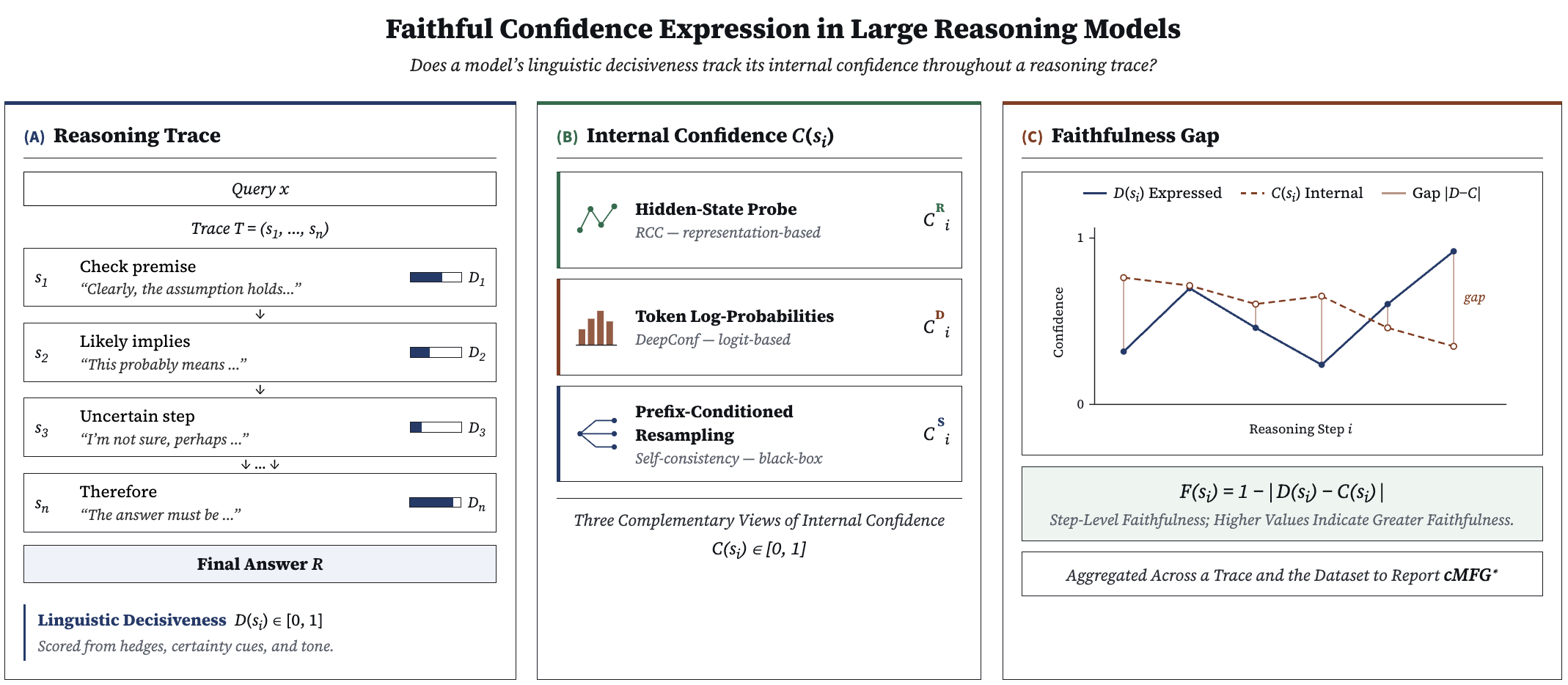
Fig 1: Overview of our framework to measure and analyze faithful calibration of reasoning models.
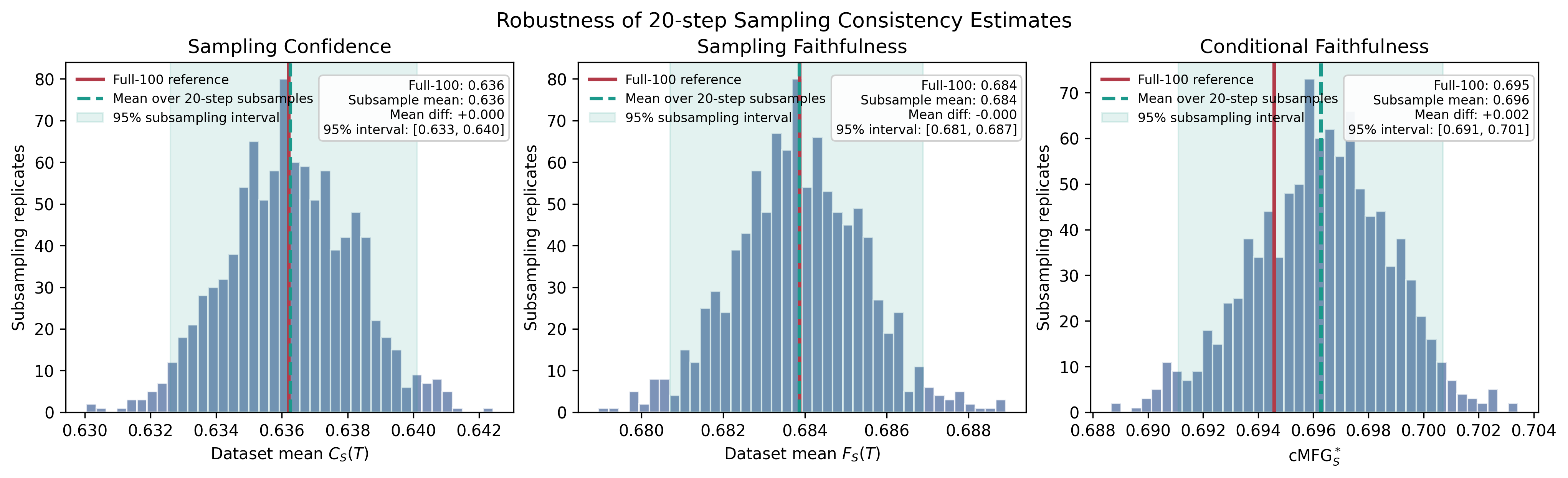
Fig 5: Subsampling robustness analysis for max_sample_steps = 20. Using a higher-budget
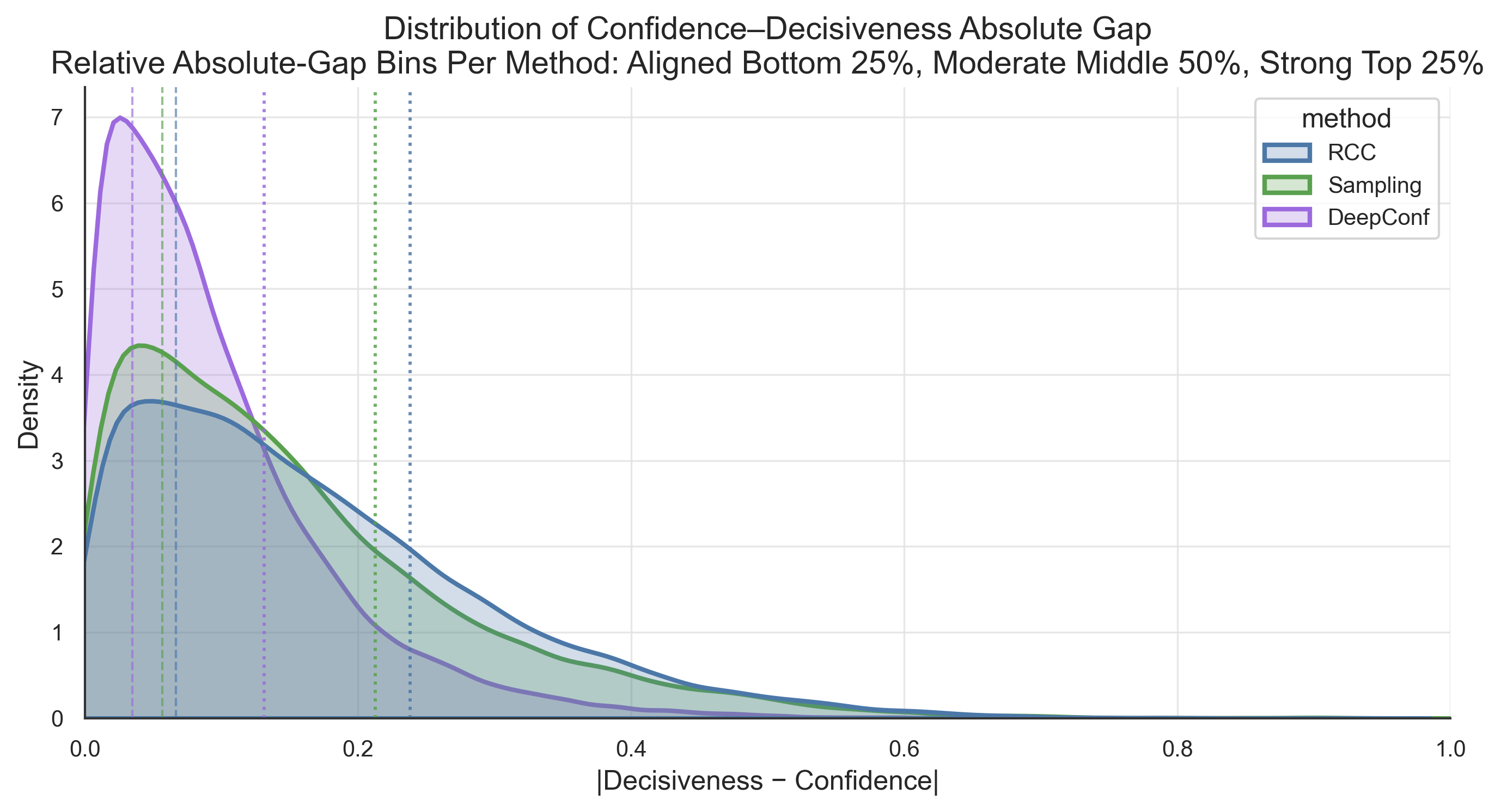
Fig 8: Distribution of confidence–decisiveness absolute gaps |D −C| across intrinsic-confidence
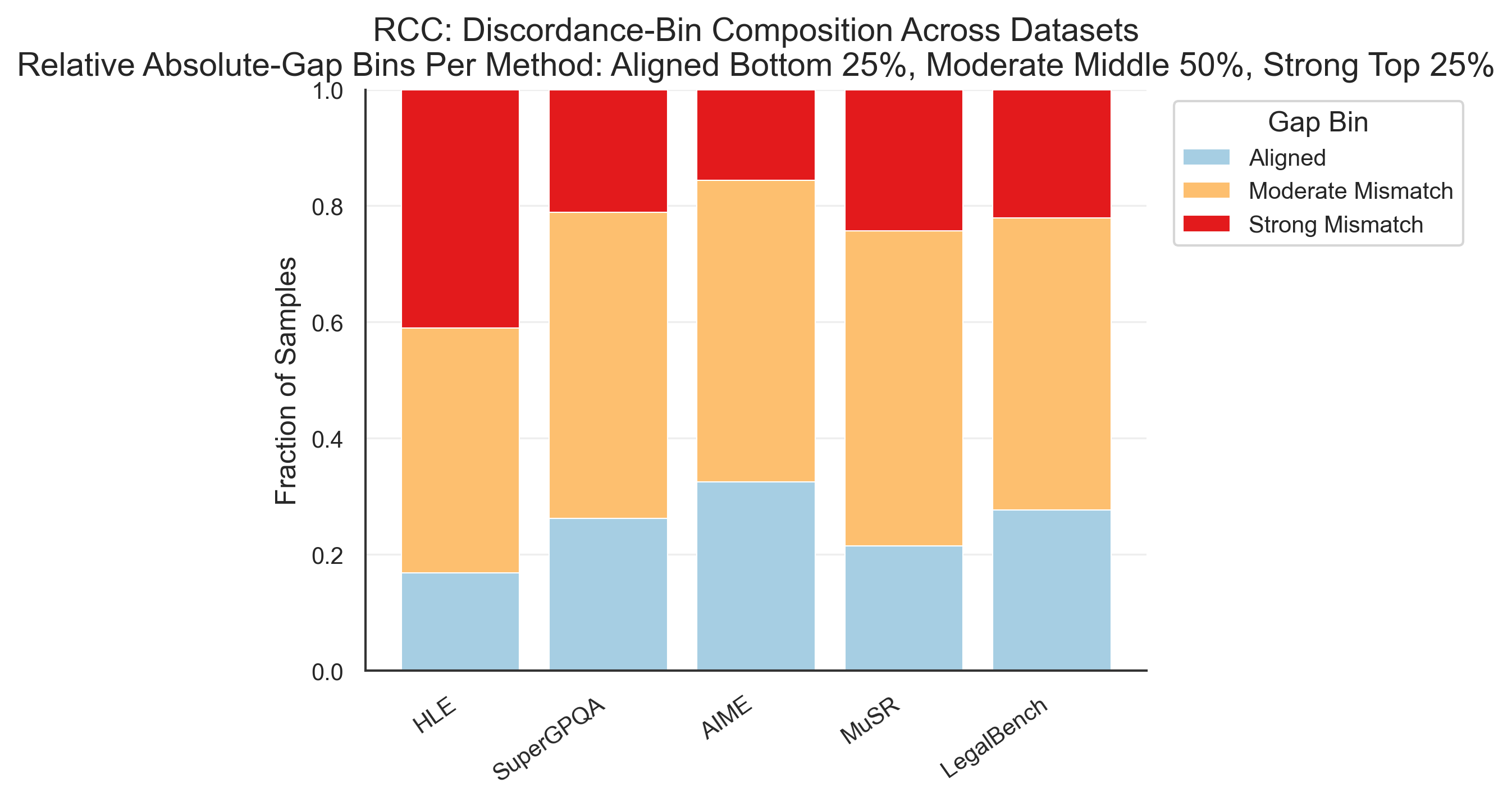
Fig 9: Dataset-level composition of confidence–decisiveness gap bins for the three intrinsic-
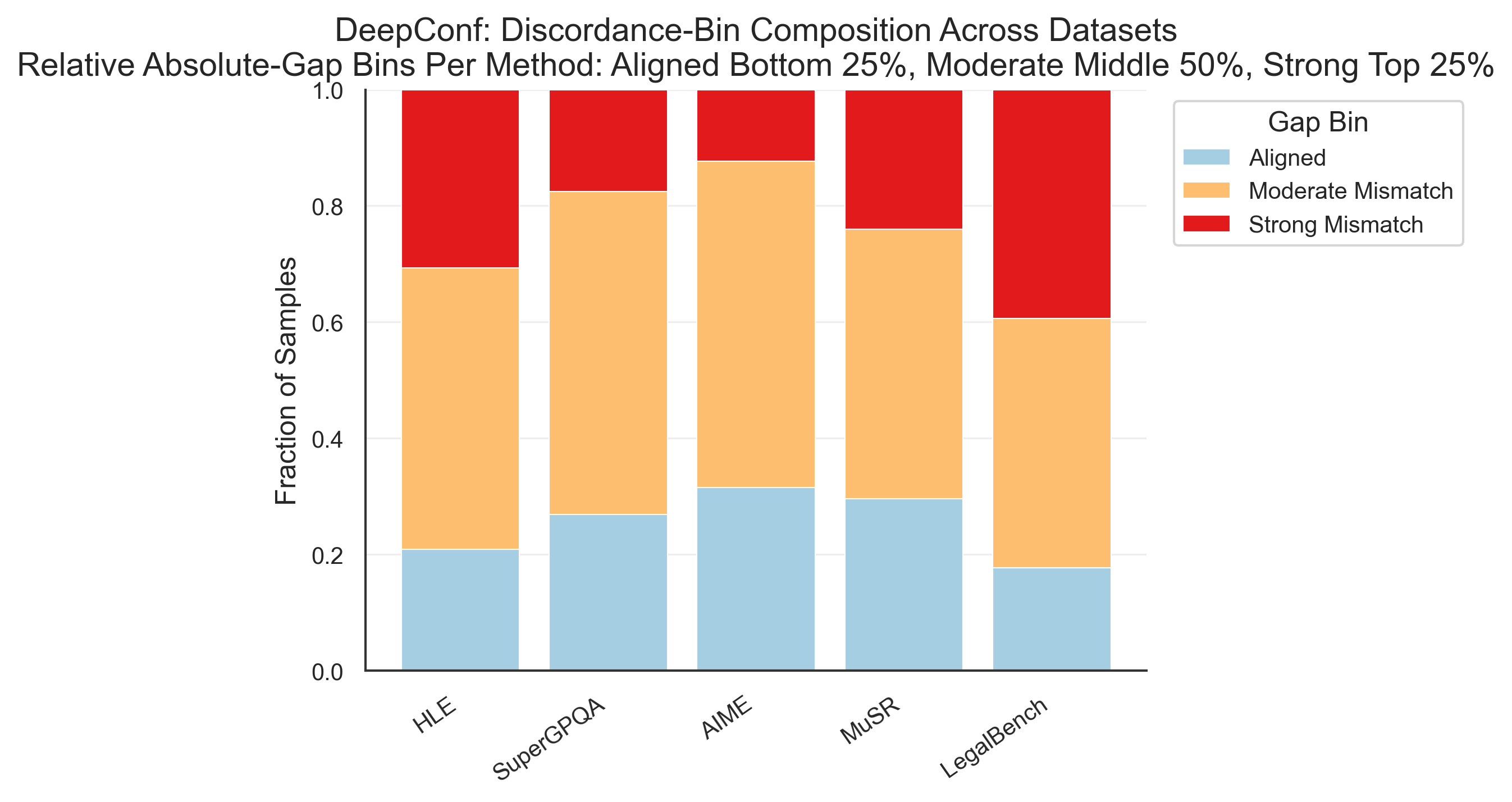
Fig 10: Relationship between the fraction of strong confidence–decisiveness mismatches and
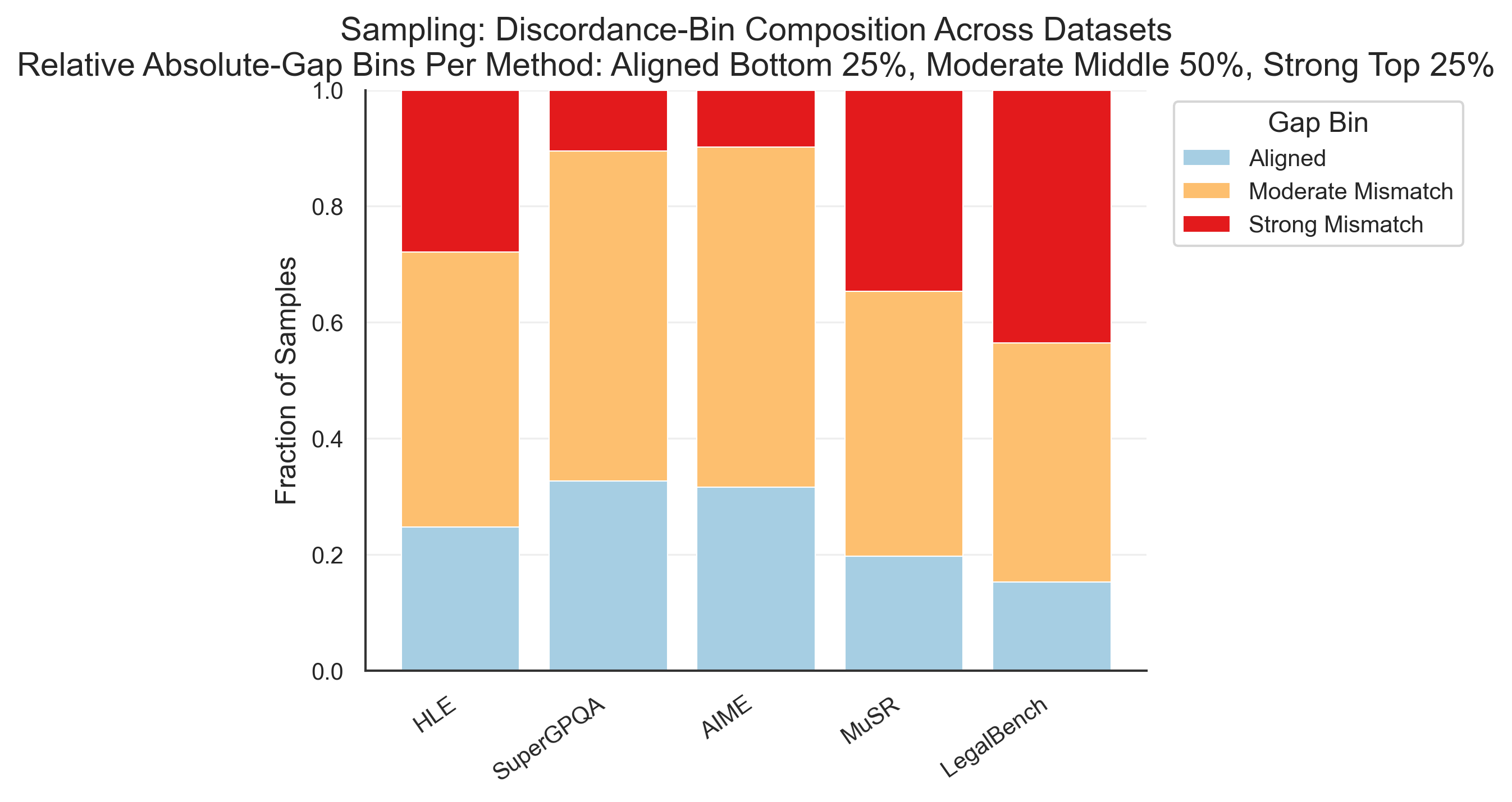
Fig 11: Confidence distribution on wrong answers across intrinsic-confidence estimators. The
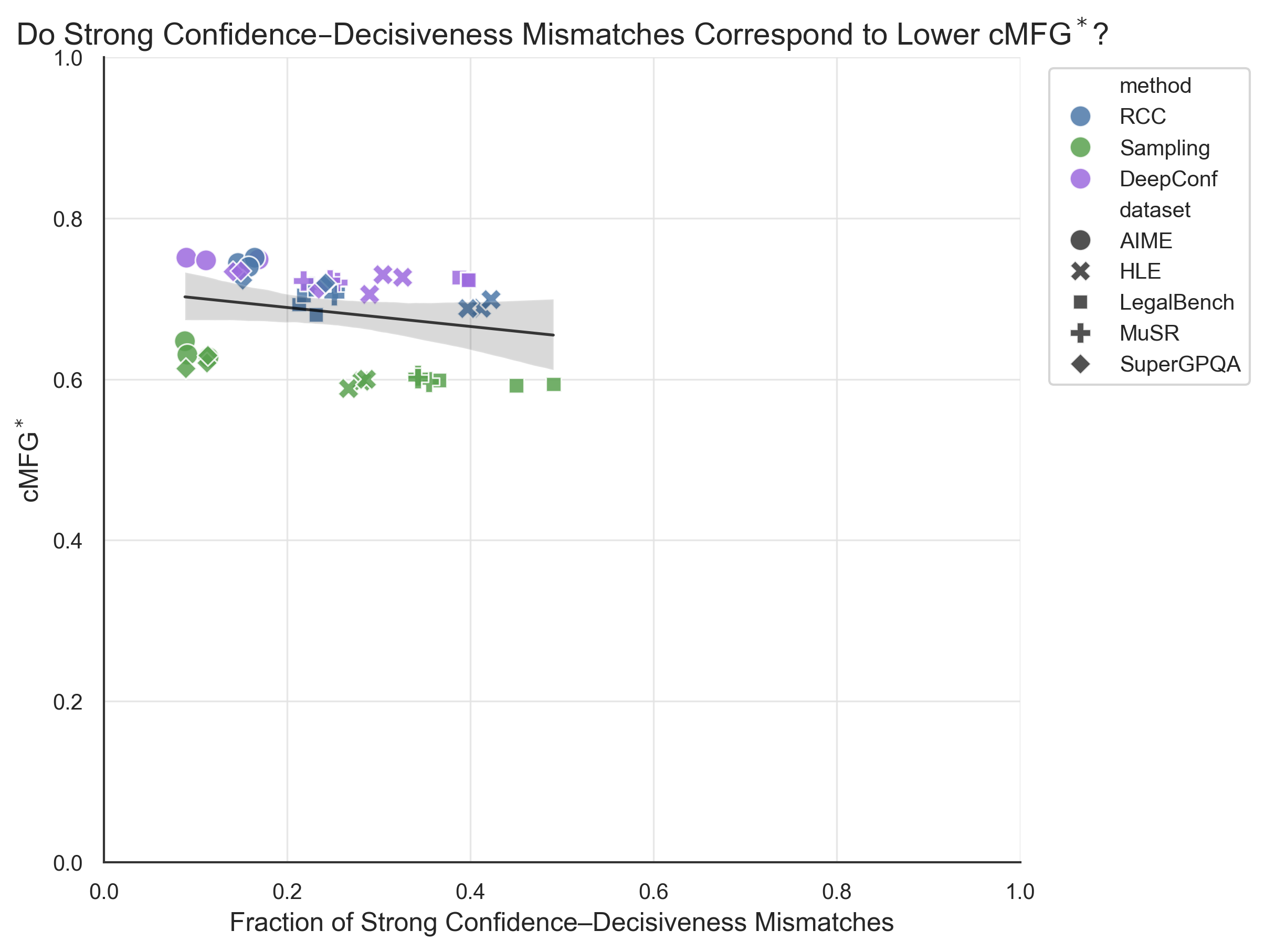
Fig 12: Fraction of wrong answers falling in the very-high-confidence bin by dataset and estimator.
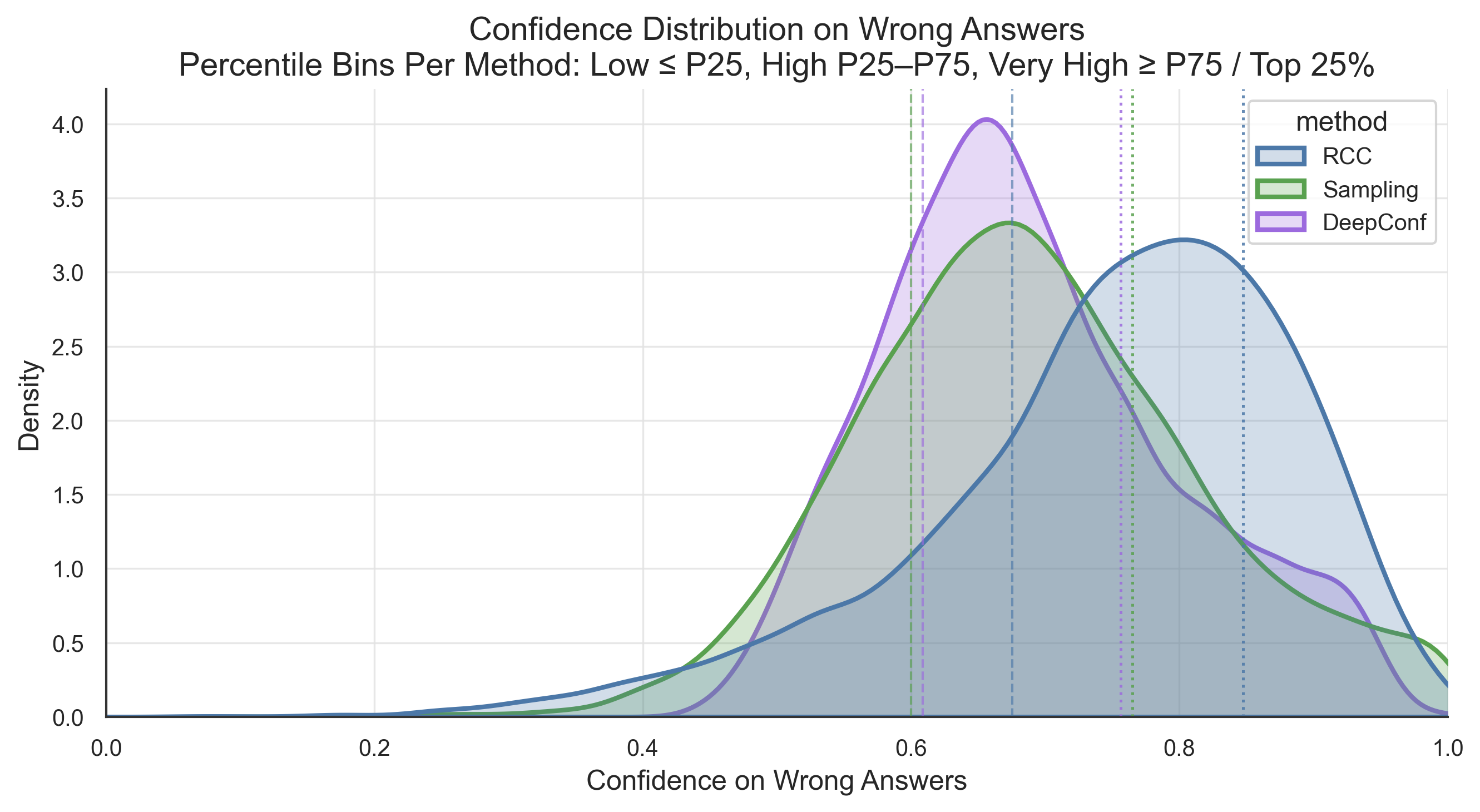
Fig 13: Relative confidence-bin composition among wrong answers, broken down by dataset and
Limitations
- Faithful calibration estimations depend heavily on choice of intrinsic confidence estimator, with substantial disagreement observed, complicating interpretation.
- Datasets and tasks, while diverse, may not cover the full range of reasoning or domain complexity encountered in practice.
- Prompting interventions tested are limited to a few representative strategies from prior work; other or more sophisticated methods might yield different results.
- The framework assumes access to internal hidden states or token log-probabilities limiting applicability to models without such access for some estimators.
- Evaluation focuses on step-level averaging ignoring potential correlations or nonlinear dynamics within traces beyond what RCC partially captures.
- The judging LLM for linguistic decisiveness was validated but remains a proxy for human perception and may inherit biases.
Open questions / follow-ons
- Can more sophisticated prompt engineering or interactive clarification improve faithful calibration in reasoning models beyond the tested methods?
- How do different architectures or training objectives explicitly designed to model uncertainty affect FC in LRMs?
- To what extent do human evaluations of expressed confidence align with LLM-judge metrics, especially in multi-modal or real-world scenarios?
- Can confidence estimators be unified or combined to yield a more robust, estimator-agnostic measure of faithful calibration?
Why it matters for bot defense
For bot-defense and CAPTCHA engineering, this work highlights that large reasoning models can articulate confidence in ways that diverge significantly from their internal uncertainty. In security contexts where automated reasoning outputs might inform adaptive challenges or trust decisions, relying on superficially confident language could be misleading. Understanding that models' linguistic decisiveness does not faithfully track their actual certainty implies that detection or defense mechanisms cannot rely solely on expressed confidence modalities.
Furthermore, the finding that FC is not improved by reasoning training or typical prompting suggests that surface-level behavior might not reveal model reliability. Developers should consider multi-faceted confidence estimators and embrace uncertainty quantification frameworks that account for internal model states and output variability. This research underlines the necessity to evaluate not only correctness but also the faithful expression of uncertainty to better gauge when automated reasoning outputs can be trusted.
Cite
@article{arxiv2606_03969,
title={ Quantifying Faithful Confidence Expression in Large Reasoning Models },
author={ Areeb Gani and Asal Meskin and Gabrielle Kaili-May Liu and Arman Cohan },
journal={arXiv preprint arXiv:2606.03969},
year={ 2026 },
url={https://arxiv.org/abs/2606.03969}
}