
Hedge-Bench: Benchmarking Agents on Hard, Realistic Tasks Pertaining to Financial Reasoning
Source: arXiv:2606.03918 · Published 2026-06-02 · By Eric Cho, Shawn Huang, Alice Lu, Andy Lyu
TL;DR
Hedge-Bench introduces a new benchmarking dataset and evaluation framework designed to test large language models and AI agents on open-ended, real-world financial reasoning tasks performed by professional hedge fund analysts. Unlike prior financial QA benchmarks that focus on closed-form question answering or formulaic numerical reasoning with fixed ground-truth answers, Hedge-Bench captures the multi-step judgment, synthesis, and argumentation skills necessary for expert financial analysis through 102 realistic tasks grounded in actual analyst conversations and reasoning traces. The benchmark provides deterministic grading based on explicitly annotated reasoning moves verified against source documents, enabling objective evaluation beyond model-judged output correctness. Results show that current frontier models, including Anthropic's Claude family, OpenAI's GPT-5, and Google's Gemini, perform poorly, achieving pass rates below 16% and partial rubric coverage averaging under 50%. This illustrates a significant gap between today's LLM capabilities and high-level financial reasoning demands. Hedge-Bench 1.0 therefore highlights the challenges and opportunities for advancing AI reasoning reliability, synthesis, and alignment in complex, high-stakes domains like finance.
Key findings
- Frontier models score below 16% pass@1 (perfect rubric score) on Hedge-Bench tasks, with the leading model Claude-Sonnet-4.6 achieving 15.5% pass@1 overall.
- The best models cover fewer than half the required rubric points, e.g., Claude-Sonnet-4.6 covered 56.4% of themes and 54.9% of valid moves.
- Performance varies widely across financial domains: highest mean dense scores were on Valuation (up to 2.15/4 by Sonnet-4.6) and lowest on Risk (mean 1.23) indicating judgment-heavy topics remain much harder.
- Trajectory length (number of reasoning steps) correlates moderately (Pearson r=0.51) with rubric coverage, with models that explore more deeply scoring better.
- GPT-5.5 achieves a good quality-reliability tradeoff with 1.68 mean dense score at under half the hallucination rate of Sonnet-4.6 (36.6% vs 88.7%), making it most deployable.
- Model scale does not correlate perfectly with performance; e.g. Gemini-3.5-Flash outperforms Gemini-3.1-Pro despite smaller nominal size.
- Open-ended expert reasoning demands synthesis of conflicting data into unified conclusions, not just discrete factual answers, a capability missing in most current agents.
- Agents sometimes exceeded rubric depth, generating novel insights not captured by the evaluation but deemed valuable by human reviewers.
Threat model
Not a security adversarial paper; the implicit 'adversary' is AI agents attempting to simulate expert analyst reasoning without direct access to external undisclosed information and without fabricating unsupported facts. Agents are assumed to only operate on the curated document environment and must not hallucinate ungrounded claims. The benchmark assesses alignment with expert analytical reasoning rather than adversarial robustness or attack resistance.
Methodology — deep read
The paper addresses the challenge of evaluating AI agents on the open-ended, multi-step reasoning tasks that expert financial analysts perform, which are underrepresented in existing benchmarks focused on formulaic or span-based QA.
Threat Model & Assumptions: The adversary is not explicitly defined as an attacker, but the task assumes AI agents have access only to a closed set of relevant documents per company snapshot and must reason like human experts; hallucinating unsupported claims is penalized. Agents cannot access external data beyond the curated corpus per test environment.
Data: The Hedge-Bench 1.0 dataset consists of 102 tasks selected from a larger set of 5,112 tasks created via transcripts of real hedge fund analyst phone conversations discussing public companies. Two experts discuss and reason jointly; transcripts are anonymized and turned into tasks. Each environment includes: (a) an open-ended instruction describing a complex financial topic; (b) a Docker container with a curated corpus of primary documents (e.g., SEC filings, earnings calls, competitor info) timestamped to the conversation date; and (c) an expert-created rubric decomposing the task into multiple themes and explicit lettered reasoning moves.
Architecture / Algorithm: Not a model contribution, but the evaluation harness uses the Harbor task format and an LLM-as-a-judge approach. The judge is a separate LLM (Gemini-3.1-Pro at temperature 0) that grades agent output on three axes: grounding (fact verification of inline citations), analytical coverage (presence of rubric moves derived from expert analysts), and synthesis (explicit reconciliation of conflicting data points).
The rubric treats coverage at the theme level, requiring a threshold number of grounded moves per theme for credit, with a final synthesis step required for full score. Scoring is dense [0–4], with pass@1 the probability of scoring perfect 4/4.
Training Regime: Not applicable; research evaluates pre-existing models including Anthropic’s Claude versions (Haiku-4.5 to Opus-4.8, Sonnet-4.6), OpenAI’s GPT-5 variants, and Google Gemini 3.1-Pro and 3.5-Flash.
Evaluation Protocol: Eight trials (independent attempts) per model per task (total 6,528 trials across 102 tasks). Metrics: pass@1 (perfect score), mean dense rubric score, coverage of rubric moves, hallucination rates (unsupported factual claims), trajectory length (steps), and tool usage. Comparisons include multiple models across families. Ablations include analysis by financial topic categories (Valuation, M&A, Risk, etc.).
Reproducibility: Dataset and evaluation harness published at the project GitHub (github.com/Trata-Inc/trata-hedge-bench). Original conversations and proprietary document snapshots may be restricted. All environment containers fix document dates to avoid lookahead.
End-to-end example: A task on Iridium Communications’ use of L-band spectrum requires the agent to identify specific technical moats. The rubric enumerates moves such as citing L-band resilience to interference, contrasting mission critical reliability vs broadband, and valuing fleet mobility. The agent must produce reasoning inline-citing supporting SEC filings and earnings calls. The judge verifies that cited facts match documents, counts coverage of reasoning moves, and checks whether the agent synthesizes counterevidence into a unified conclusion. The final score depends on grounded coverage and synthesis presence.
Technical innovations
- First benchmark to derive open-ended, multi-step financial reasoning tasks from actual hedge fund analyst conversation transcripts rather than synthetic question-answer pairs.
- Use of explicit reasoning traces by expert analysts to create deterministic rubrics that decompose tasks into semantically meaningful reasoning moves enabling granular scoring.
- Implementation of an LLM-as-a-judge grading framework that separately validates factual grounding (via inline citations), analytical coverage, and synthesis of opposing data points to evaluate agent outputs.
- Quantitative analysis correlating trajectory length and number of tool calls with reasoning coverage and hallucination rate, providing insight into agent effort vs reliability tradeoffs.
Datasets
- Hedge-Bench 1.0 — 102 tasks — proprietary dataset derived from real hedge fund analyst discussion transcripts and curated document pools
Baselines vs proposed
- Claude-Sonnet-4.6: pass@1 = 15.5%, mean dense score = 1.92 vs GPT-5.5: pass@1 = 10.1%, mean dense score = 1.68
- Claude-Opus-4.7: pass@1 = 11.2%, mean dense score = 1.84 vs Gemini-3.5-Flash: pass@1 = 7.5%, mean dense score = 1.68
- GPT-5.4-Mini: pass@1 < 1%, mean dense score = 0.75 vs Claude-Haiku-4.5: pass@1 ≈ 1.4%, mean dense score = 1.24
- Sonnet-4.6 achieves 56.4% theme coverage vs GPT-5.5 achieves 48.1% theme coverage
- Hallucination rates: Sonnet-4.6 at 88.7%, GPT-5.5 at 36.6%; better precision-recall tradeoff by GPT-5.5
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.03918.

Fig 1: Pass@1 and mean dense score per model. Pass@1: the probability a single model attempt scores a perfect
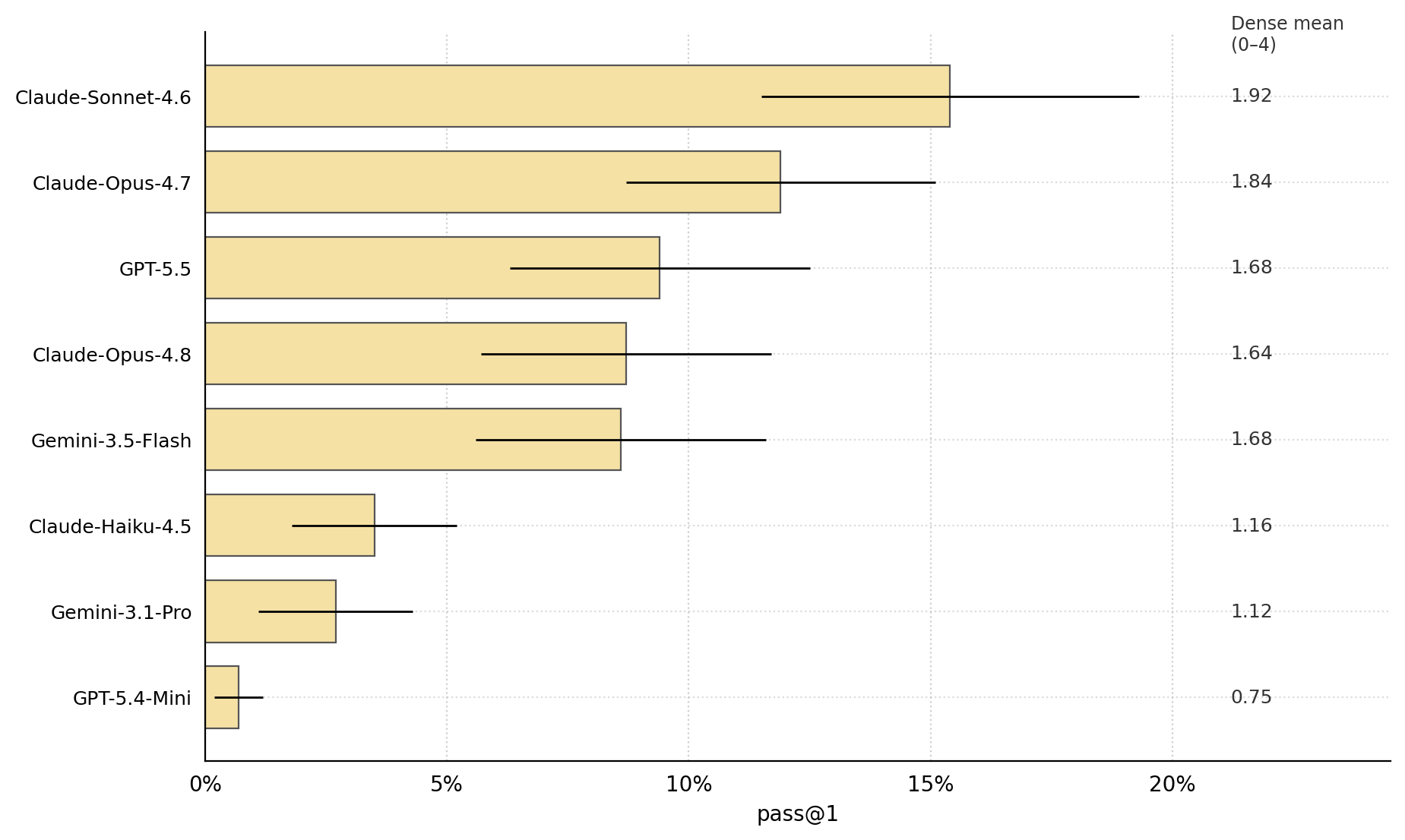
Fig 2: Overview of our pipeline. Top: how we collected transcripts and formulated test environments. Bottom: our
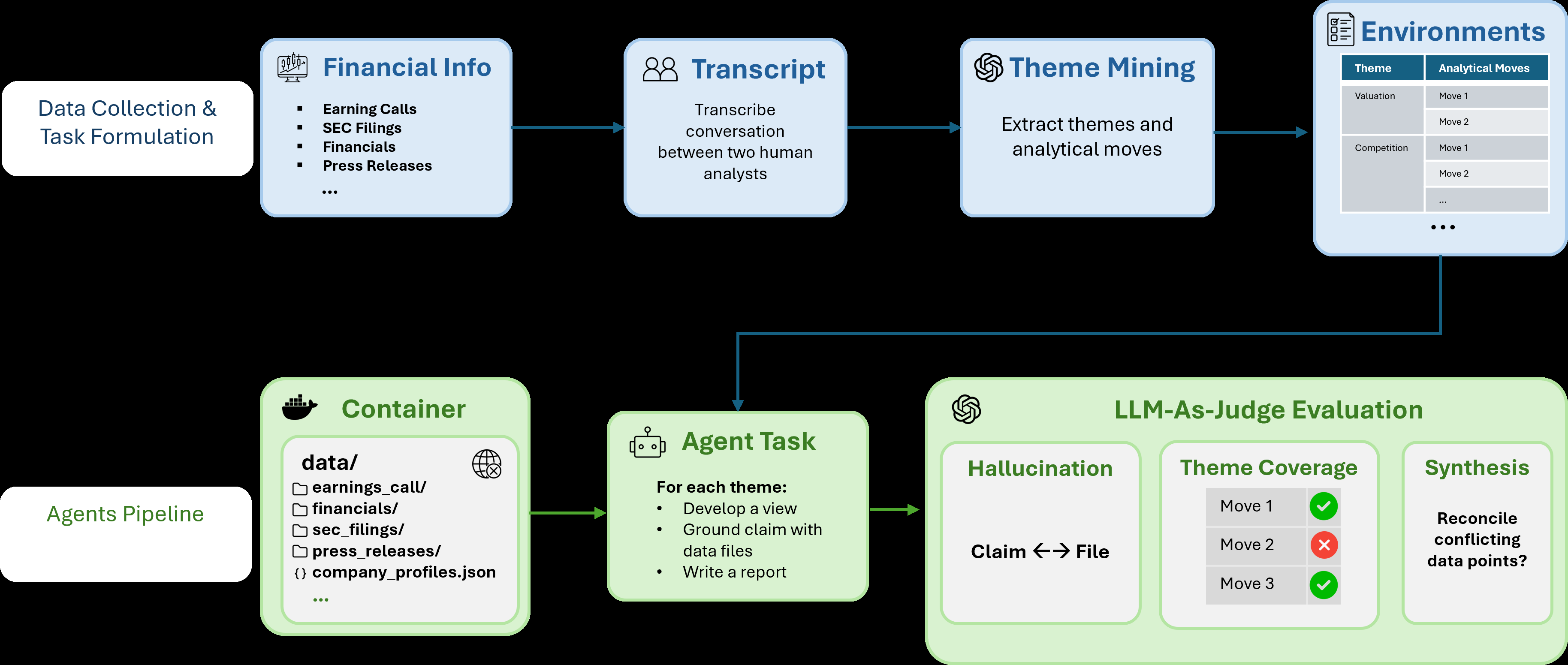
Fig 3: An example theme from a Hedge-Bench rubric. A theme is a distinct line of inquiry an analyst would pursue
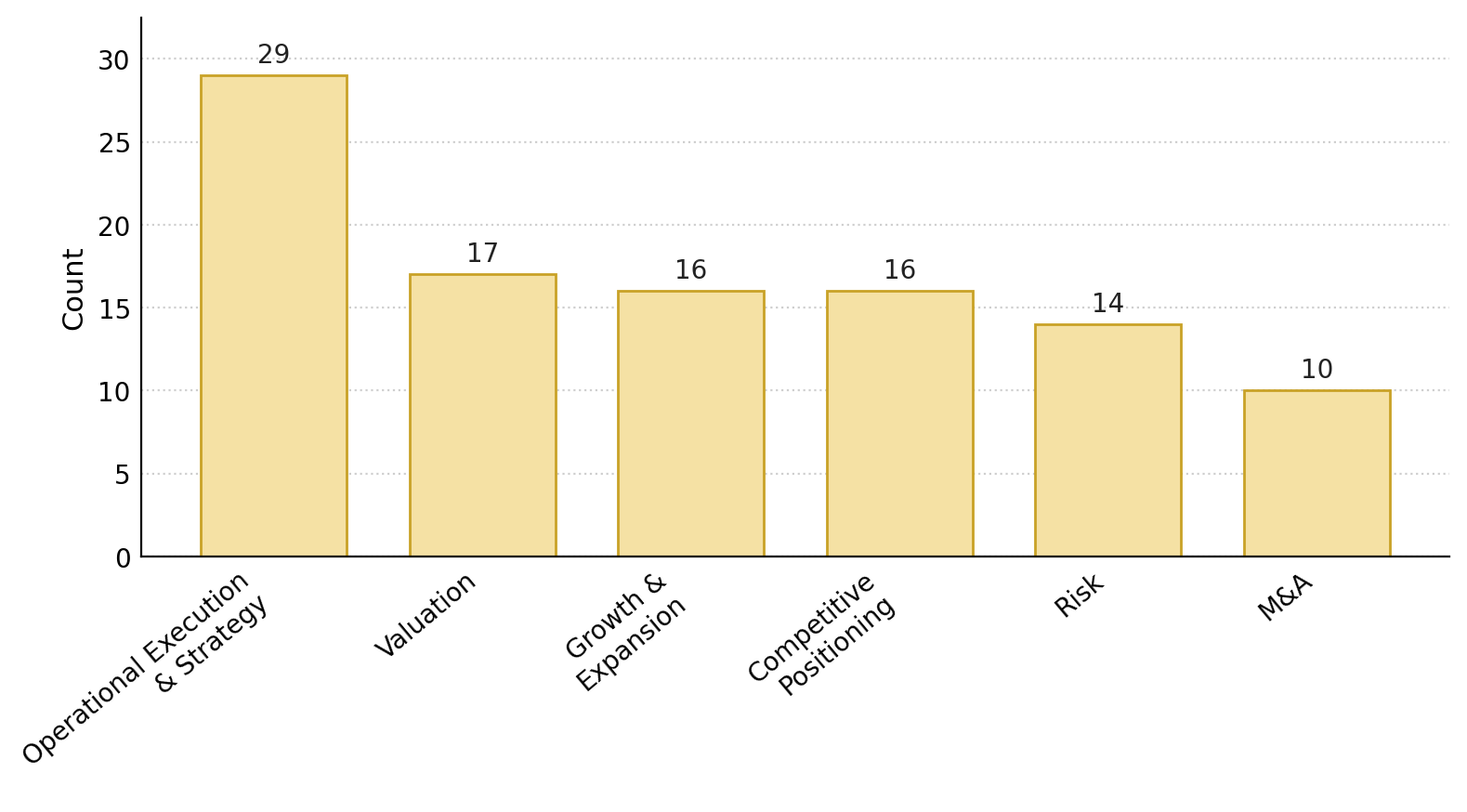
Fig 4: Number of environments per category.

Fig 5: We provide the agents with various types of
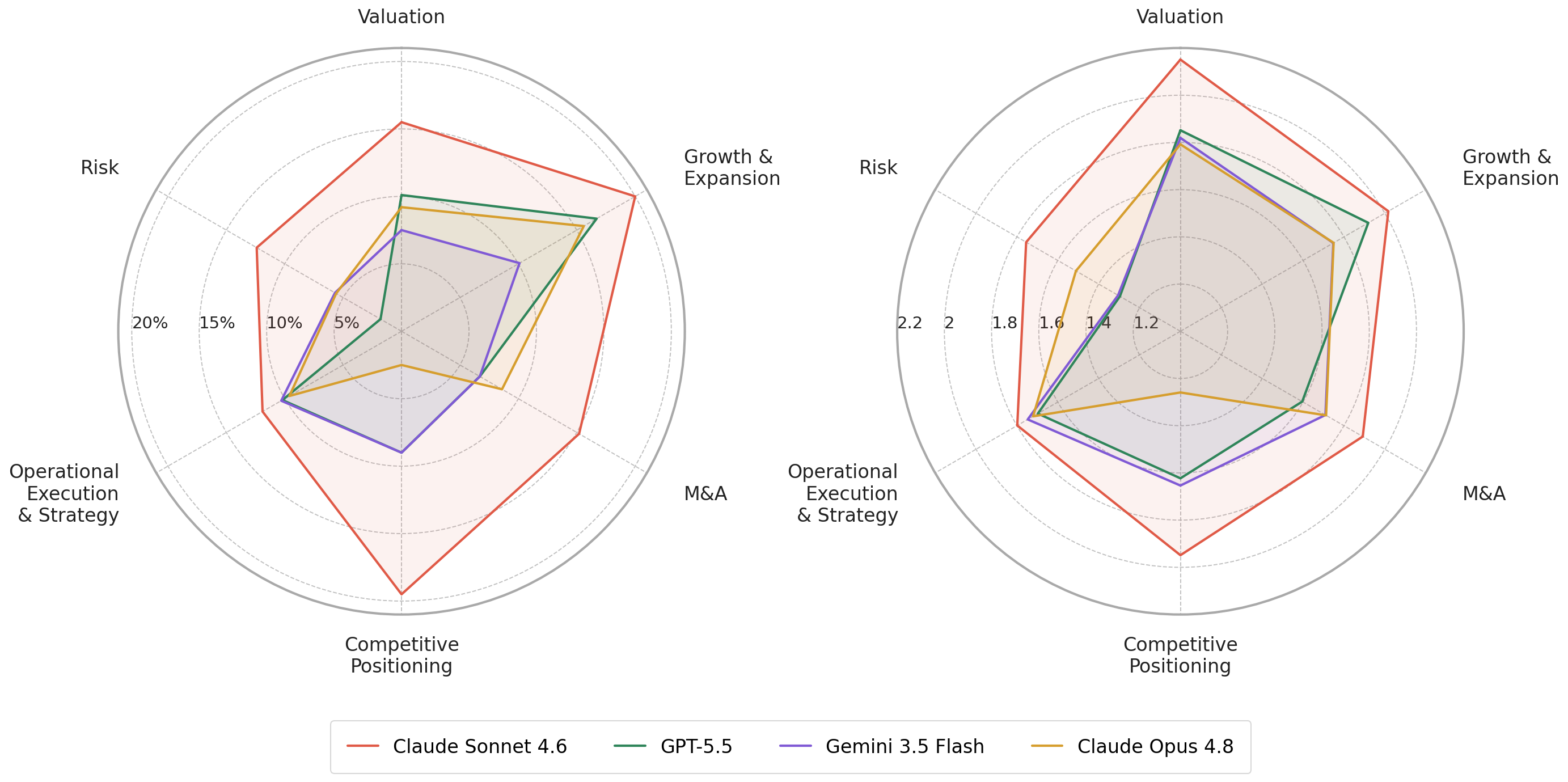
Fig 6: Selected model performance by category. Left: Pass@1 rates. Right: Mean dense scores.
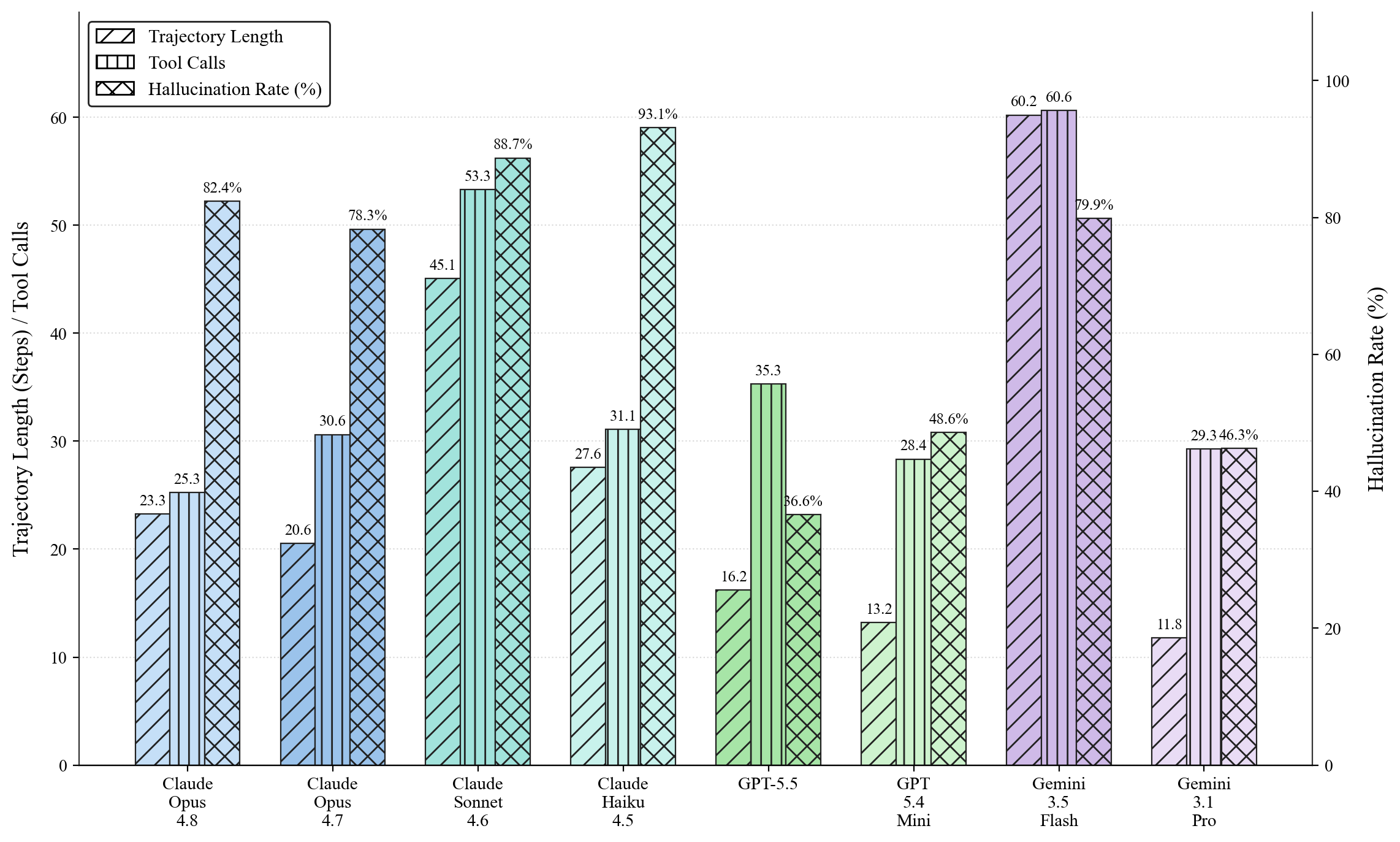
Fig 7: The trajectory length, tool-call counts, and hallucination rate for each model.
Limitations
- Rubrics and ground truth are based on the reasoning moves of one specific pair of expert analysts per task, so evaluations reflect alignment with their analytical style; alternative expert rubrics might differ.
- The rubric creation process currently uses a single LLM pass without multi-step human verification; moves are tested against static data folder rather than direct transcript spans, risking some rubric drift from original expert discussion.
- Evaluation penalizes hallucinated facts only insofar as they taint supported moves; off-rubric reasoning is not penalized but may not be credited either.
- Tasks are confined to curated, time-stamped document sets per environment with finite context windows; real-world analyst work may incorporate broader or updated information.
- The grading LLM judge is susceptible to rare parsing failures which zero out entire runs; no extensive analysis of judge robustness to adversarial outputs is reported.
- No adversarial model or stress testing under shifted data distributions was performed to assess robustness or generalization beyond the controlled task documents.
Open questions / follow-ons
- Can future models improve synthesis capabilities to reconcile conflicting evidence at scale and achieve pass rates significantly above 16% on Hedge-Bench?
- How can rubric quality and ground truth be enhanced through iterative multi-stage human–LLM collaboration to reduce rubric drift and increase fidelity to analyst expert consensus?
- What training or prompting techniques best reduce hallucination rates without sacrificing depth of reasoning and coverage across diverse financial topics?
- How do these models generalize when exposed to out-of-distribution or newer financial events beyond historic curated documents?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners focusing on AI agent detection or behavioral modeling, Hedge-Bench provides a clear example of benchmarking the reasoning depth and factual grounding abilities of state-of-the-art LLMs in a narrowly defined, expert-heavy domain. Its rigorous multi-stage rubric and grounding checks illustrate how fine-grained evaluation metrics beyond accuracy—such as reasoning trace coverage and hallucination rate—are critical when assessing complex open-ended outputs. Captchas or bot-defense mechanisms aimed at identifying sophisticated AI agents could draw insights on measuring semantic alignment to expert reasoning routines or testing an agent's ability to produce stepwise grounded arguments. Moreover, the observed tradeoff between exploration effort and hallucination highlights a general challenge in detecting advanced reasoning agents that produce plausible but unverifiable outputs, an important consideration for trust and security in AI-powered interactions.
Cite
@article{arxiv2606_03918,
title={ Hedge-Bench: Benchmarking Agents on Hard, Realistic Tasks Pertaining to Financial Reasoning },
author={ Eric Cho and Shawn Huang and Alice Lu and Andy Lyu },
journal={arXiv preprint arXiv:2606.03918},
year={ 2026 },
url={https://arxiv.org/abs/2606.03918}
}