
Formalizing the Binding Problem
Source: arXiv:2606.03976 · Published 2026-06-02 · By Lianghuan Huang, Yihao Li, Saeed Salehi, Yingshan Chang, Ansh Soni, Konrad P. Kording
TL;DR
This paper addresses the long-standing binding problem in vision: how to represent not only features but also the correct combinations of features that make up distinct objects in multi-object scenes. While Vision Transformers (ViTs) have shown some capacity to separate patches, it was unclear whether they encode binding information about feature conjunctions that define objects. The authors formalize binding using an information-theoretic framework, defining binding information as the mutual information between the scene representation and the object code (which encodes presence or absence of each object defined by feature subsets). They introduce a probing methodology to estimate how much binding information is present in learned model representations, separating binding from mere feature encoding. Applying this framework, they find that the image summary token ([CLS]) in ViTs encodes less than half of the binding information, whereas spatial tokens collectively encode binding almost perfectly. Probes employing an attention mechanism over spatial tokens can decode over 90% of the binding information on synthetic and natural datasets. Binding is shown to be a necessary but under-encoded component in current vision models for accurate multi-object understanding, especially under occlusion and feature sharing. The work provides a rigorous quantitative theory and practical probing tools for evaluating binding in visual representations.
Key findings
- The [CLS] summary token of a DINOv2-Large ViT encodes only about 48.5% of the total binding information (mutual information with object code) on a synthetic 6-object ColorShape dataset (Table 3).
- Conditional on feature information, the [CLS] token encodes only 42.4% of binding information that cannot be explained by features alone (Table 3).
- Using an attention-based probe over the full set of spatial tokens, binding information decoded rises to 92.2% of total binding, and 94.1% conditional binding (Table 5).
- Quadratic probes nearly match deep neural network probes in estimating binding, indicating the binding information structure is largely quadratic in the representation.
- Parameter sharing among object probes that share features causes only a small 2.4-bit loss in binding decoding accuracy, supporting a conjunctive feature encoding structure (Table 2).
- Increasing feature space complexity reduces binding performance for CLIP ViT-L/14 on ColorShape (Fig 4).
- Binding information declines with increasing occlusion on CLEVR dataset, indicating occlusions challenge binding (Fig 5).
- Natural datasets like Visual Genome with complex semantic features present unique binding challenges but the probing method can measure binding there as well.
Methodology — deep read
The authors first define the binding problem formally in an information-theoretic framework. They consider scenes with a finite set of discrete features F and objects O, where each object corresponds to a unique subset of features. The feature code F is a binary vector indicating which features are present in a scene; the object code O is a binary vector indicating which objects are present. Binding information in a learned representation Z is then defined as the mutual information I(O; Z), i.e., how much information the representation contains about which objects are present. They further define conditional binding information I(O; Z | F), which captures binding beyond what is explained by features alone.
To estimate binding information from actual model representations, the authors train autoregressive probes q_θ(o_k | o_<k, z) to approximate the conditional distribution p(o | z), where o_k is the presence indicator for the k-th object and o_<k denotes all prior objects, conditioned on representation z. This allows factorization of the exponentially large object code space into tractable training tasks predicting each object sequentially. The cross-entropy loss of these probes approximates the entropy H(O | Z). Similar probes are trained for the feature code F to estimate H(F | Z). Overall binding information is computed using entropy decomposition with dataset prior entropies H(O) and H(F) obtained empirically.
The framework is applied primarily to pre-trained Vision Transformer models, focusing on probing different components of the final-layer representation: the image summary token [CLS] and the full spatial tokens. For the [CLS] token, various probe architectures are compared including linear, quadratic, and deep neural networks (4-layer GELU MLPs). For the spatial tokens, a novel lightweight attention probe is introduced whereby learned queries conditioned on previously decoded object predictions compute weighted sums over spatial tokens, followed by quadratic readouts.
Experiments use a synthetic ColorShape dataset with 8 colors and 8 shapes forming 64 objects, constructing scenes with multiple objects sharing features randomly placed without overlap. The dataset is split so training, validation, and test sets have disjoint feature and object sets, testing probe generalization. Dataset priors H(O) = 39.9 bits and H(F) = 7.0 bits are computed combinatorially. Probes are trained until convergence, with train/val/test losses tracked to ensure generalization.
Additional experiments probe binding on CLEVR with varied occlusion and Visual Genome natural images to test binding under harder real-world feature conjunctions and scene complexities. Various ablations test probe architectures and conditioning on past object labels. Binding decoding accuracy is measured via error reduction over baselines and mutual information estimates.
Code is publicly released, but some datasets are controlled synthetic scenes constructed for the study.
Technical innovations
- An information-theoretic formalization of binding as mutual information between learned representations and object presence indicators in multi-object scenes.
- A scalable autoregressive probing method that decomposes the exponential object code space to sequentially decode object presence from model representations with validity guarantees.
- Introduction of a simplified attention probe that queries spatial tokens conditioned on previously decoded objects for near-perfect binding decoding.
- Normalization and conditional definitions of binding information to separate binding beyond feature information in representation analysis.
Datasets
- ColorShape — ~59,000 images (39,200 train, 9,800 val, 9,800 test) — synthetic, constructed by authors
- CLEVR with varied occlusion levels — standard benchmark (Johnson et al., 2016) — publicly available
- Visual Genome — natural images with dense feature/object annotations — publicly available
Baselines vs proposed
- Linear probe on [CLS]: object code probe error reduction = 37.4% vs DNN probe = 64.4% (Table 1)
- Quadratic probe on [CLS]: object code error reduction = 63.0% vs DNN probe = 64.4%
- Attention probe on full spatial tokens: object code error reduction = 96.8% vs DNN probe on [CLS]=64.4% (Table 4)
- [CLS] token encodes 48.5% of binding info; full spatial tokens encode 92.2% binding info (Table 3 vs 5)
- Conditional binding info beyond features: 42.4% for [CLS], 94.1% for spatial tokens (Table 3 vs 5)
- Parameter sharing among objects reduces binding decoding by ~2.4 bits (5.3 percentage points ER) compared to no sharing (Table 2)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.03976.
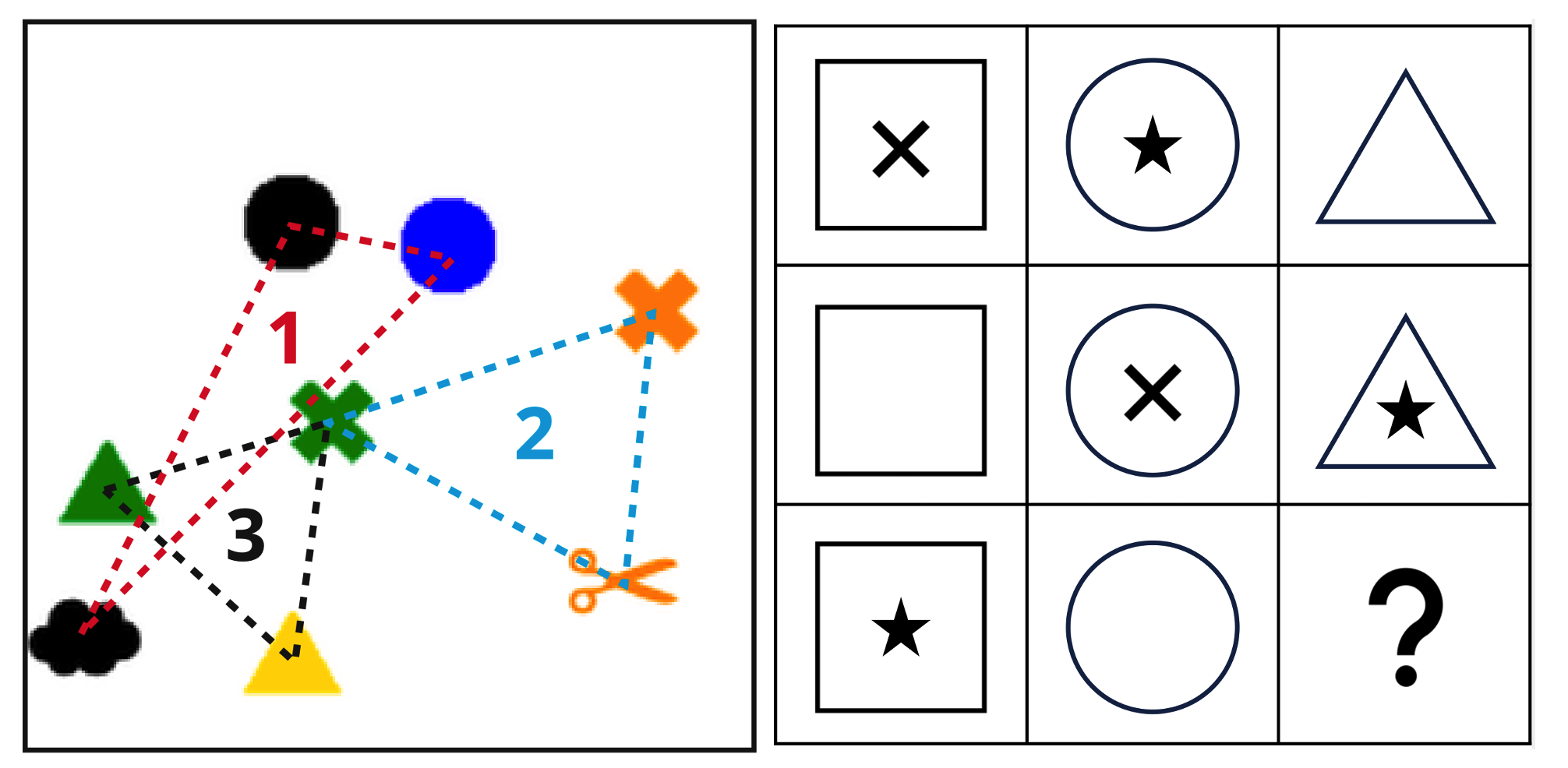
Fig 1: Binding failures. Left: (Campbell et al., 2025) shows
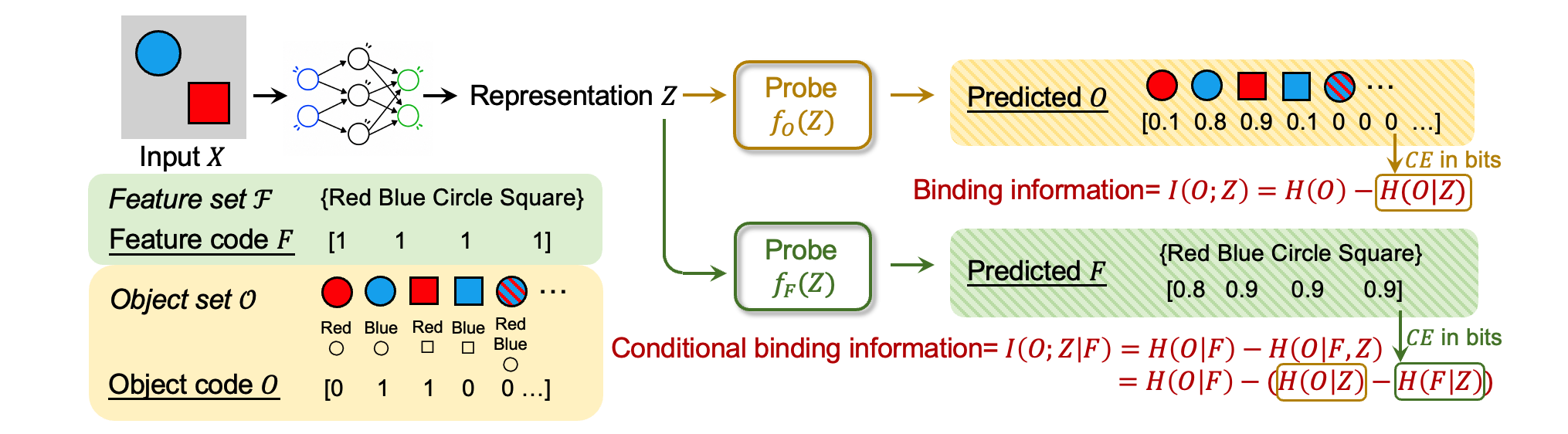
Fig 2: Binding theory and probing framework. We first define the space of features and objects of interest, as shown in features set

Fig 3: Binding degrades with increasing feature space complexity in ColorShape. Middle: We run the CLIP ViT-L/14 (224px)
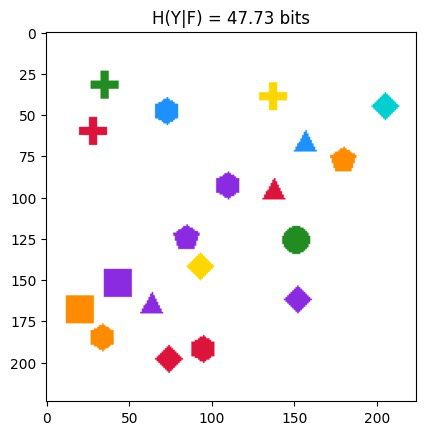
Fig 4: CLEVR examples of object-code uncertainty revealed by binding probes. Blue bars (H(O | Z)) indicate uncertainty in

Fig 5 (page 9).

Fig 6 (page 9).

Fig 7 (page 9).
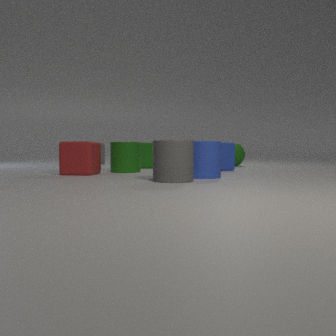
Fig 5: The different occlusion levels of the CLEVR dataset, controlled by camera elevation and pitch angle. In left-to-right,
Limitations
- The study is limited to Vision Transformers and may not generalize to all architectures (CNNs, other attention models).
- Autoregressive probes assume a certain factorization and require sequential conditioning which may not capture all dependencies in object code perfectly.
- Synthetic datasets like ColorShape may not fully represent the complexity of real-world object binding challenges.
- No explicit adversarial evaluation to test robustness of binding under deliberate perturbations.
- CLEVR occlusion and Visual Genome natural images tested, but generalization to more complex scenes and modalities remains to be explored.
- The probes are trained post-hoc and may not reflect what the original model internally uses for binding.
Open questions / follow-ons
- How can architectures be modified or trained to improve binding information in summary tokens, reducing reliance on full spatial tokens?
- Can the probing framework be extended to other modalities or multi-modal binding problems (e.g., vision-language binding)?
- What are the causal mechanisms within ViTs that enable encoding of binding in spatial tokens but not summary tokens?
- How does binding information correlate with downstream task performance in more complex visual reasoning benchmarks?
Why it matters for bot defense
The paper's formalization and probing method provide a rigorous toolset for bot-defense and CAPTCHA engineers to quantify how well vision models encode object-feature bindings. Binding failures often manifest as misattributed features which can inform adversary behaviors or model weaknesses. For CAPTCHA systems that rely on challenging multi-object scene understanding, such as verifying that objects are correctly recognized with their attributes, understanding whether and where the binding information is encoded in visual representations is critical. This work suggests that systems relying solely on summary representations may miss critical conjunction information, increasing vulnerability to feature-sharing attacks or spoofing. The attention-based probing approach could be adapted to audit deep models used in CAPTCHA pipelines to identify whether binding information—and by extension, resistance to misbinding adversarial examples—is sufficiently encoded or needs architectural/ training modifications. Lastly, understanding binding degradation under occlusion and clutter can guide CAPTCHA image design for robust human verification versus automated attacks.
Cite
@article{arxiv2606_03976,
title={ Formalizing the Binding Problem },
author={ Lianghuan Huang and Yihao Li and Saeed Salehi and Yingshan Chang and Ansh Soni and Konrad P. Kording },
journal={arXiv preprint arXiv:2606.03976},
year={ 2026 },
url={https://arxiv.org/abs/2606.03976}
}