
Forecasting Political News Engagement on Social Media
Source: arXiv:2606.04293 · Published 2026-06-02 · By Karthik Shivaram, Mustafa Bilgic, Matthew Shapiro, Aron Culotta
TL;DR
This paper addresses the problem of forecasting political news engagement on Twitter over long time horizons, which is crucial for understanding dynamics such as hyperpartisanship, filter bubbles, and misinformation spread. The authors curate a novel longitudinal dataset consisting of over 60 million tweets from politically engaged users spanning seven years (2015-2021), annotating about 10% of tweets with news source handles and their political leanings. They develop neural network models, primarily Bi-LSTM architectures, to forecast users' future news engagements across a seven-category partisan spectrum, using both historical engagement counts and tweet content as inputs. Their best performing model achieves a mean absolute error (MAE) of 3.7 engagements per three-month window, outperforming baseline and alternative approaches.
By leveraging the learned user representations from their forecast model, the authors cluster users to reveal salient long-term engagement patterns. Key findings include that hyperpartisan users are more engaged overall, right-leaning users engage more than left-leaning users with contra-partisan sources, and particular topics such as immigration, COVID-19, Islamophobia, and gun control strongly predict engagement with low-reliability news sources. The work builds a foundation for detailed modeling and understanding of user-level political news consumption evolution over multiyear time frames on social media.
Key findings
- The curated dataset includes 63.4 million tweets from 5,838 users, with 4.6 million annotated news engagement tweets spanning 2015-2021.
- The best forecasting model (SFN+C, Bi-LSTM with only news engagement counts) achieves MAE=3.73 and MSE=207.89 over test sets, improving over baseline MAE=3.89.
- Models incorporating tweet text embeddings alone (SFN+T) perform worse (MAE=4.22) than engagement count-based models.
- Forecast errors increase in 2020 coinciding with large political events (COVID-19, Trump impeachment).
- The SFN+C model better captures sudden shifts in user engagement than baseline, illustrated by lower MAE on transition samples (e.g. engagement-to-no engagement shifts).
- Users with hyperpartisan leanings (-3 / +3) represent minority portions of data and have higher forecast errors.
- Text analysis reveals terms like "COVID-19", "impeachment" for unreliable liberal sources and terms like "globalists", "marxists", and "cartels" for unreliable conservative sources as predictive indicators.
- Clustering of learned user representations uncovers twenty salient long-term engagement groups aligned by partisan lean and topical focus.
Threat model
The adversary is a typical politically engaged Twitter user whose activity patterns and tweet content evolve over time. There is no explicit consideration of malicious manipulation, coordinated campaigns, or bot interference in forecasting. The threat model assumes historical engagement data and user-generated tweet text are available inputs but does not consider attackers designing adversarial inputs or goal-directed misinformation campaigns.
Methodology — deep read
The study focuses on forecasting future political news engagement on Twitter for individual users based on their historic behavior and tweet content. The threat model assumes adversaries are regular platform users engaged politically, without explicit adversarial manipulations considered.
The authors curate a large dataset by collecting tweets from 1.67 million users mentioning or linking to 522 political news sources annotated on a partisan scale from -3 (extreme liberal, unreliable) to +3 (extreme conservative, unreliable). After filtering, 5,838 users with at least 50 news engagements spanning 3+ years remained, totaling 44.2 million tweets, including 4.6 million news engagement tweets spanning 2015-2021. News sources include 419 mainstream outlets rated by allsides.com and 103 low-reliability sources from prior misinformation work.
Data is segmented into overlapping three-year folds (D1-D4), with train, validation (20% holdout users), and test splits organized by time. Each prediction task uses 8 input quarterly time steps (each with 3 months) to forecast the next quarter’s news engagement distribution across 7 partisan categories.
Input features include (1) time series of z-score normalized news engagement counts per partisan stance, (2) aggregated transformer-based (TwHIN-Bert) embeddings of users' 25 most recent engagement and non-engagement tweets per quarter, (3) transformer embeddings of top 100 hashtags in the last quarter, and (4) one-hot encoded quarter identifiers for input and forecast windows.
The primary forecasting models are Bi-directional LSTMs: the Single Feature Network (SFN) uses either text embeddings (SFN+T) or engagement counts (SFN+C) as input sequences; the Multiple Feature Network (MFN) combines LSTM outputs with hashtag and forecast quarter embeddings through an intermediate layer before predicting the future engagement vector.
Models are trained using Mean Absolute Error loss summed over the seven partisan stances, using mini-batches, five random seeds for averaging, and hyperparameters tuned on validation data. Baseline predictions assume the future engagement matches the last observed quarter.
Model evaluation reports MAE and MSE over test periods, disaggregated by partisan category and time. Additional analyses include error distributions over time, user-level error visualization, transition event evaluation for sudden engagement shifts, and linguistic analysis of text predictive of unreliable news engagement.
For interpretability, the authors extract the intermediate MFN representations per time window and concatenate them over 2018-2021 to construct user vectors, which are clustered via k-means (K=20). Cluster heatmaps visualize partisan engagement timelines and top distinctive terms by year, revealing nuanced group-level behavior shifts.
Code and anonymized data records (user IDs, mention records, partisan labels) are made available for reproducibility, although the full historical tweets remain proprietary. The transformers used were off-the-shelf fine-tuned Twitter BERT models.
An example workflow is predicting user i's next quarter news engagement distribution given their last 2 years of quarterly engagement counts and tweet embeddings: the input engagement vectors and tweet embeddings are fed into the Bi-LSTM, whose concatenated final hidden states are combined with hashtags and forecast quarter embeddings in MFN, producing a 7-dimensional predicted partisan engagement count vector, which is compared to true values for loss calculation.
Technical innovations
- Curation of a uniquely large, longitudinal Twitter dataset of political news engagement over seven years with fine-grained partisan annotations.
- Use of multi-timescale Bi-LSTM models combining historic partisan engagement counts with transformer-based tweet and hashtag embeddings to forecast future user news consumption distributions over partisan stances.
- Extraction and clustering of latent neural representations across multiple temporal windows to reveal long-term user-level patterns of political news engagement evolution.
- Identification of linguistic features predictive of engagement with unreliable political news sources by integrating chi-square feature selection on model-ranked engagement subsets.
Datasets
- Twitter political news engagement dataset — 63.4M tweets — collected via Twitter Streaming API with 5,838 anonymized users (filtered from 1.67M) spanning 2015-2021, with 4.6M news engagement tweets annotated with partisan leanings of 522 news sources.
- AllSides news source bias ratings — 419 sources — public media bias rating site allsides.com
- Low-reliability news sources — 103 sources — derived from Osmundsen et al. (2021b) / Guess et al. (2019)
Baselines vs proposed
- Baseline (last observed quarter engagement): MAE = 3.89, MSE = 216.33
- SFN+C (BiLSTM with engagement counts): MAE = 3.73, MSE = 207.89 (best performing)
- MFN (combined features): MAE = 3.85, MSE = 220.55
- SFN+T (BiLSTM with text embeddings only): MAE = 4.22, MSE = 258.08
- SFN+C outperforms baseline with statistically significant improvements (p < 0.01), except vs MFN where difference is smaller.
- SFN+C has lower error than baseline across most partisan stances except lowest frequency stances (-3/+3) where errors are similarly high.
- For sudden engagement transitions (engagement to no engagement and vice versa), SFN+C improves over baseline by up to ~20% MAE reduction.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.04293.
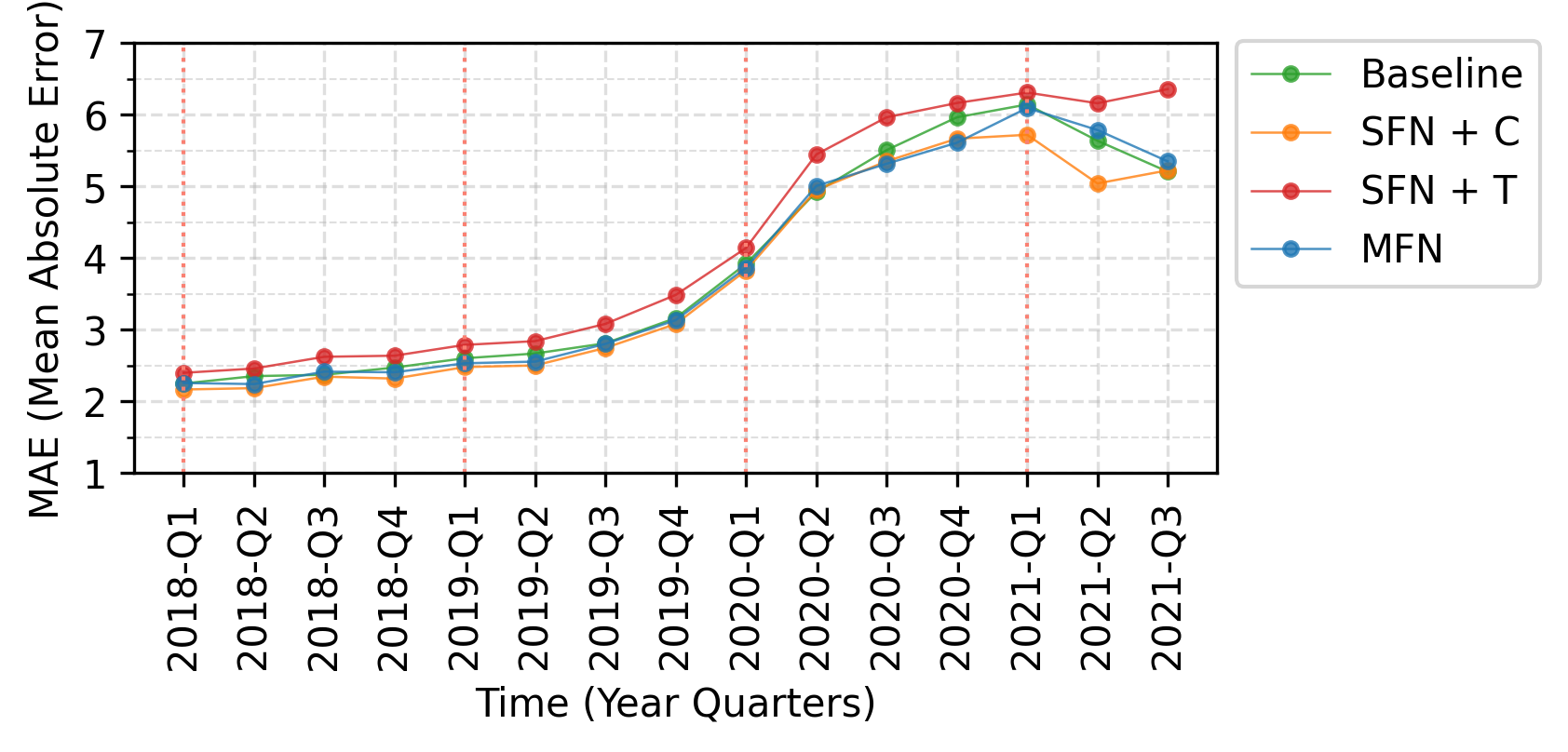
Fig 2: plots test error by quarter. We observe that er-
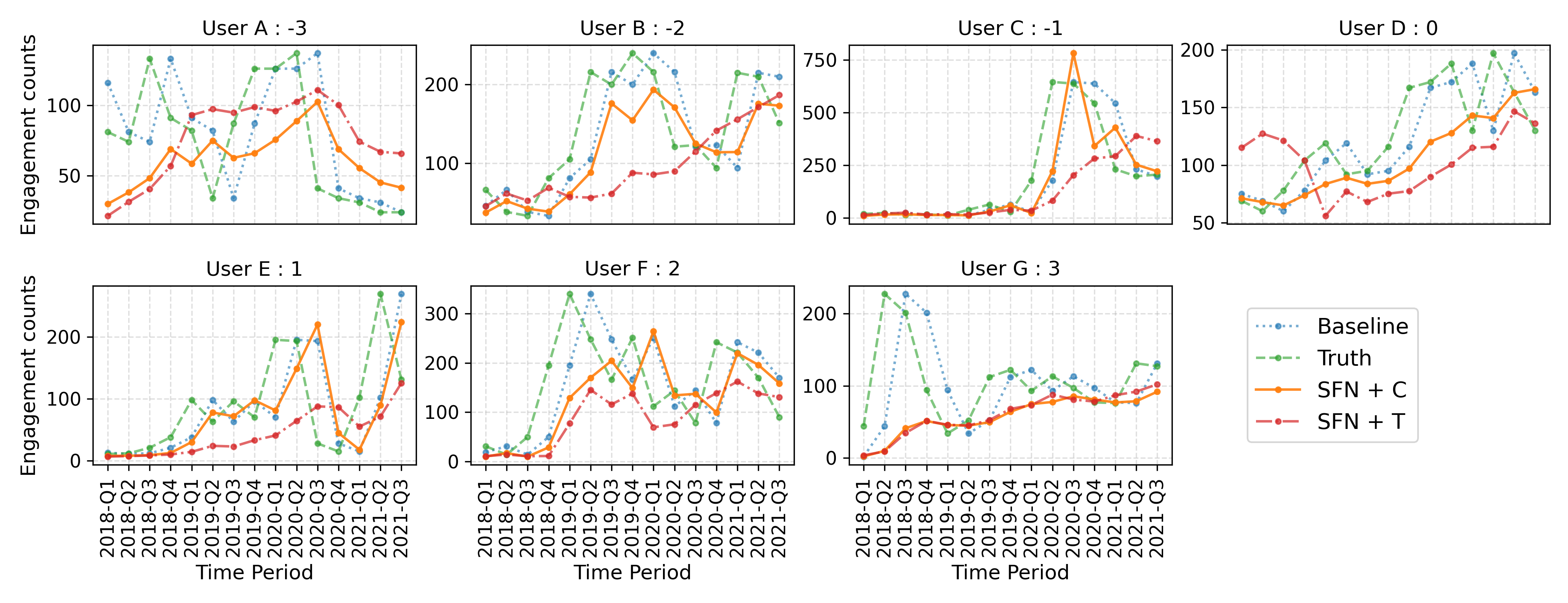
Fig 3: True vs. predictied values for users with the highest errors, according to the SFN+C model.
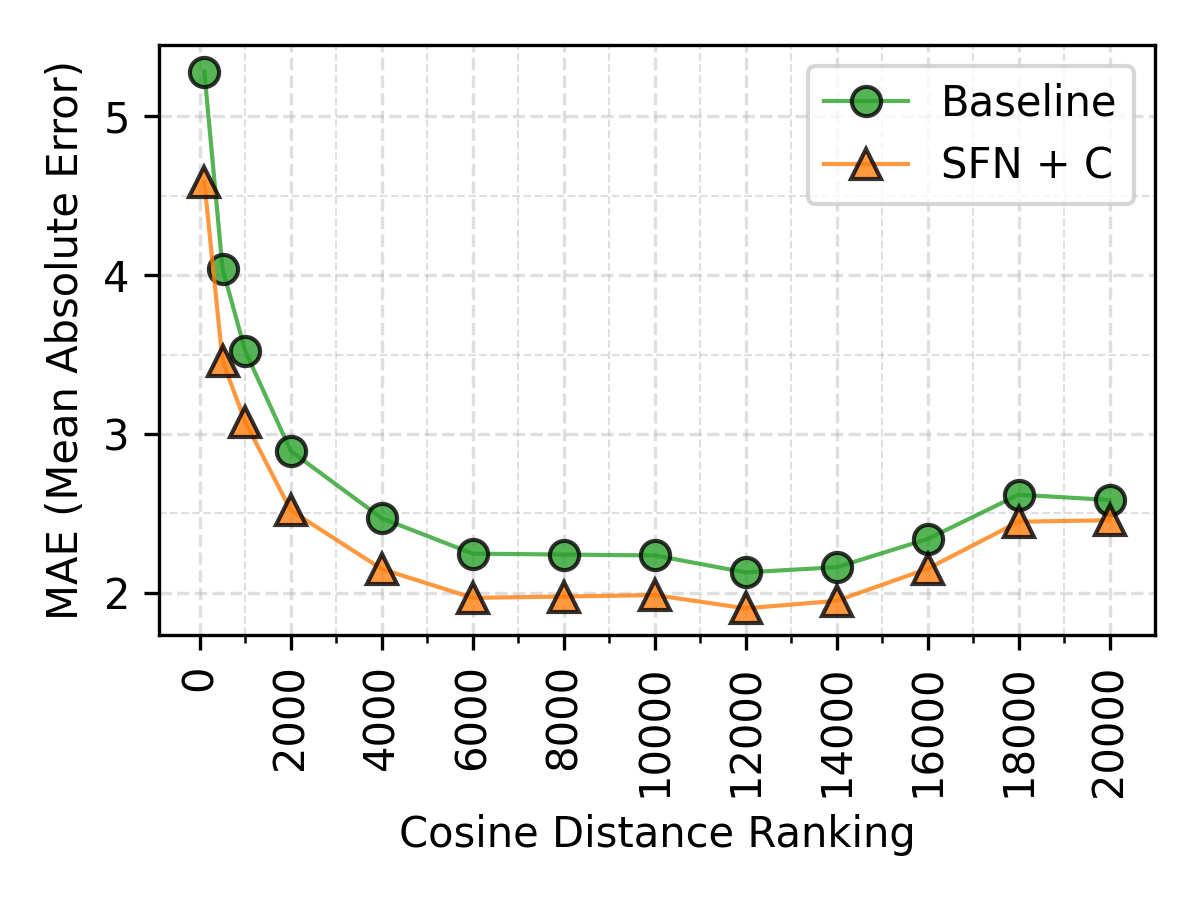
Fig 4: Error by transition points based on cosine distance
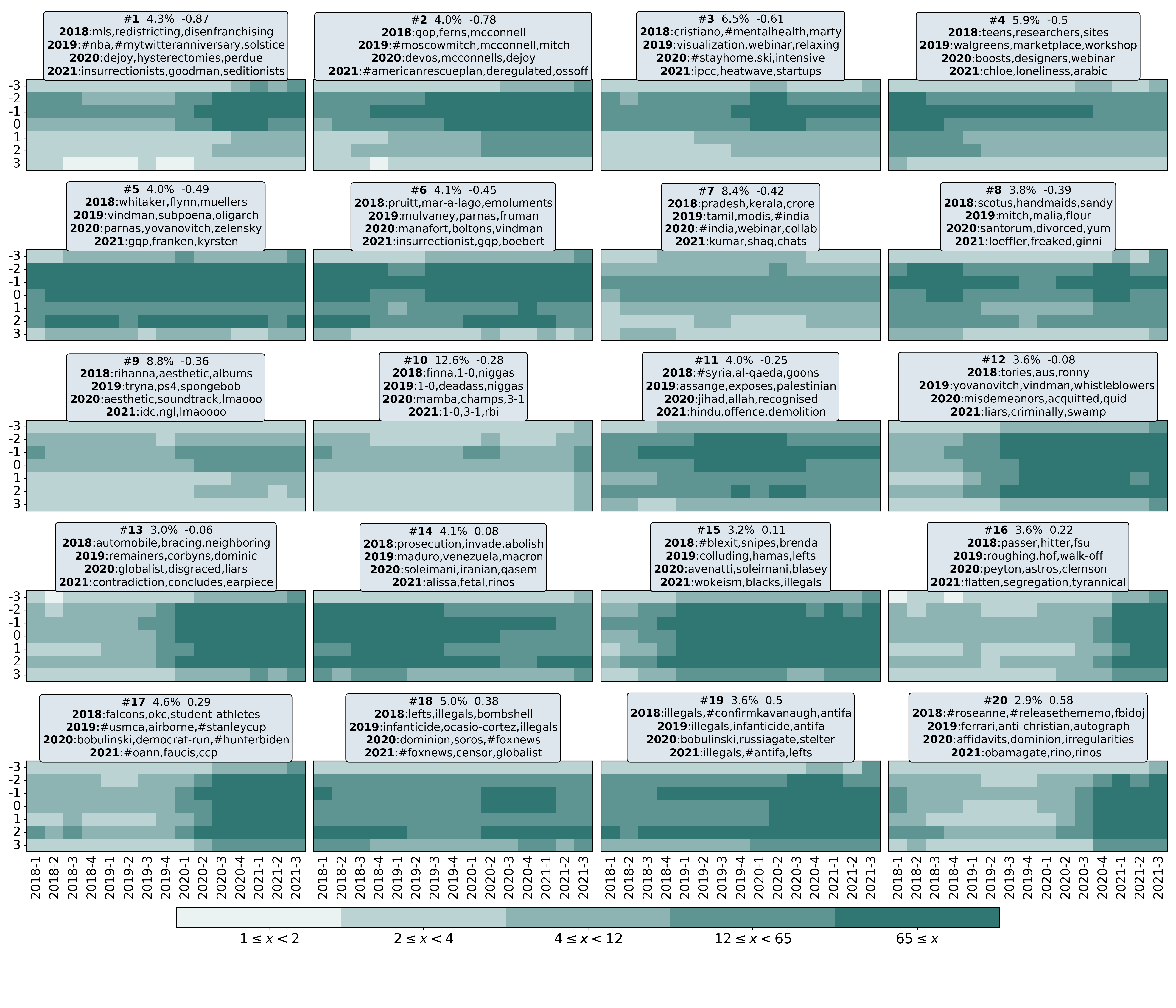
Fig 5: Visualization of 20 discovered clusters of users based on the learned representation of the forecasting model. Over
Limitations
- The study excludes users with fewer than 50 news engagements or insufficient longitudinal data, limiting generalizability to less active or newer users.
- Engagement is measured only by mentions and links to identified news sources, potentially missing other forms of news consumption or sharing.
- The dataset and models focus on English-language tweets and US-centric news outlets, limiting cross-lingual and international applicability.
- The approach does not model adversarial manipulation or explicitly detect bots, beyond simple filtering heuristics.
- Errors increase notably in periods of intense political events (e.g., 2020), indicating challenges handling rare but impactful outlier phenomena.
- Interpretability of neural latent features and the direct causality of linguistic indicators remains heuristic and exploratory.
Open questions / follow-ons
- How well do these forecasting models generalize to new users or emerging news sources outside the trained partisan categories?
- Can incorporating network structure and friend/follower relationships improve prediction accuracy and identify echo chamber effects?
- How resilient are these models and user cluster characterizations to coordinated manipulation or bot-driven amplification attacks?
- What interventions could be designed based on forecasted user shifts toward unreliable sources to mitigate misinformation spread?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this paper offers insights into the longitudinal behavior of politically engaged social media users, including how their news consumption evolves and shifts, often unpredictably around major events. While the work does not focus on adversarial bot detection, the detailed engagement forecasting and latent user representation clustering techniques could inform behavioral analysis to distinguish authentic long-term user patterns from bot or troll activity that may lack such complexity or show sudden anomalous spikes. The text-based indicators of unreliable source engagement and partisan shifts also suggest feature sets that might aid in nuanced user authenticity assessments or risk scoring in bot defense. Overall, this study provides a valuable data-driven framework for understanding persistent user behavior evolution in politically sensitive contexts that can be complementary to technical bot detection and CAPTCHA challenge design.
Cite
@article{arxiv2606_04293,
title={ Forecasting Political News Engagement on Social Media },
author={ Karthik Shivaram and Mustafa Bilgic and Matthew Shapiro and Aron Culotta },
journal={arXiv preprint arXiv:2606.04293},
year={ 2026 },
url={https://arxiv.org/abs/2606.04293}
}