
Transferable Self-Harm Surveillance from Emergency Department Triage Notes Using an Evidence-Augmented Machine Learning Approach
Source: arXiv:2606.02545 · Published 2026-06-01 · By Liuliu Chen, Gowri Rajaram, Eleanor Bailey, Katrina Witt, Michelle Lamblin, Jo Robinson et al.
TL;DR
This paper addresses the challenge of scalable, accurate surveillance of self-harm in Emergency Department (ED) triage notes, where reliance on diagnostic codes shows low sensitivity. The authors propose a novel three-stage approach combining a zero-shot large language model (LLM) for high-sensitivity screening, LLM-based structured evidence extraction (capturing indicators like act, injury, method, timing, intent), and a traditional supervised machine learning classifier that integrates extracted evidence with raw text. The method is designed to improve detection of self-harm cases, including precise identification of the primary self-harm method, enabling more granular surveillance beyond binary classification.
Evaluated across three Australian hospitals (including temporal and geographic external validation), the approach achieved high and stable performance, with area under the precision-recall curve (AUPRC) ranging from 0.816 to 0.887, outperforming baselines such as ClinicalBERT and gradient boosting machines. Importantly, the LLM-extracted primary self-harm method matched clinician annotations with 95% accuracy, highlighting the ability to provide interpretable, evidence-augmented outputs suitable for public health surveillance. The approach demonstrated strong cross-hospital transferability, particularly at one external site, and robustness to temporal shifts without retraining or site adaptation.
Key findings
- Stage 1 zero-shot LLM screening achieved recall between 0.967 and 0.984, reducing notes to 4.9%-6.5% while increasing self-harm prevalence from ~1.1%-1.7% to ~21.2%-26.7%.
- Stage 2 zero-shot LLM-based evidence extraction maintained recall of 0.933 to 0.961 but had low precision (~0.39-0.50), necessitating further calibration via Stage 3.
- The final Stage 3 logistic regression classifier, combining triage notes with Stage 2 extracted evidence and reasoning (method + summary), achieved the highest AUPRC of 0.900 and F1 of 0.841 on RMH internal data.
- End-to-end performance across sites: AUPRC of 0.887±0.016 (RMH test), 0.881±0.008 (RMH prospective), 0.884±0.012 (LRH test), 0.879±0.012 (LRH prospective), and 0.816±0.015 (SunH test) with recall 0.800–0.846.
- Cross-hospital transfer performance was close to same-hospital training at LRH (AUPRC 0.884 vs 0.888) and also at SunH (0.816 vs 0.824) though with lower precision at SunH (0.710 vs 0.805).
- The LLM-extracted primary self-harm method matched clinician annotation with 95% exact accuracy and weighted F1=0.95 on 1,016 positive cases.
- Compared with baselines trained on raw triage notes alone, the proposed method outperformed logistic regression (AUPRC 0.816–0.792), ClinicalBERT (AUPRC 0.880–0.737), and gradient boosting (0.844–0.719) across all evaluation sets.
- Computationally, Stage 1 screening runs in ~105ms per note on an NVIDIA A100 GPU, Stage 2 evidence extraction requires ~452ms per note, but screening reduces notes needing Stage 2 to ~6%, keeping the entire pipeline efficient (~2–2.3 GPU-minutes/day at RMH volumes).
Methodology — deep read
Threat Model & Assumptions: The adversary model is implicit; the task focuses on robust self-harm case identification across diverse hospital settings using clinical triage notes. The system assumes the notes are authentic but highly noisy, brief, and use inconsistent terminology. There is no adversarial input or intentional evasion modeled.
Data: Data came from triage notes at three Australian hospitals: Royal Melbourne Hospital (RMH), Latrobe Regional Health (LRH), and Sunshine Hospital (SunH). RMH data spanned 2012-2017 (development/test) and 2018-2022 (prospective test). LRH included 2012-2017 and 2018-2022 respectively, and SunH data covered 2019-2022. Dataset sizes ranged, e.g., RMH development set included ~316k notes with 1.36% self-harm prevalence. Notes were very brief (median 21-47 tokens). Annotations were binary (self-harm positive/negative) by trained researchers with high inter-rater agreement (kappa=0.91).
Architecture/Algorithm: The approach comprises three sequential stages:
- Stage 1: Zero-shot large language model (LLM) screening applied to all triage notes, optimized for high recall to identify candidate self-harm presentations and reduce class imbalance and computational load downstream.
- Stage 2: Zero-shot LLM prompting on screen-positive notes to extract structured, textual evidence for five self-harm indicators: act, injury, method, timing, intent, plus related keywords and summary reasoning. This converts raw text into interpretable features.
- Stage 3: A supervised, evidence-augmented binary classifier combines the original note with Stage 2 extracted evidence and reasoning for final self-harm prediction. The final model used logistic regression with TF-IDF vectorization of notes plus TF-IDF features from extracted evidence and reasoning (method + summary), selected via ablation.
Training Regime: Stage 3 classifier was trained on RMH Chunk 3 (~79k notes), with standard supervised regimen. Evaluations applied fixed models without retraining on external hospitals. Hyperparameters and detailed optimization steps for Stage 3 not fully detailed but used standard ML models including logistic regression and multiple baselines.
Evaluation: Performance evaluated on held-out RMH test set, prospective RMH and LRH sets, external LRH and SunH test/prospective sets. Metrics included area under precision-recall curve (AUPRC), F1-score, precision, recall, and AUROC. Ablations assessed input feature contributions, classifier types, and calibration. Baselines included logistic regression and ClinicalBERT trained on raw notes only, and a prior gradient boosting model. Error analysis included confusion matrices and qualitative review of false positives.
Reproducibility: No explicit code release noted. Datasets are sensitive clinical notes and likely not publicly shareable. Model is based on GPT-OSS-20B LLM for prompting and standard ML classifiers (logistic regression). Some supplementary materials report detailed ablations. No mention of frozen weights or explicit seed strategies.
End-to-End Example: A large corpus of ED triage notes is first filtered by Stage 1 zero-shot LLM screening for high recall. About 5-6% of notes are flagged as possible self-harm. These notes are prompted using fixed LLM templates (Stage 2) to extract textual evidence about method, injury, intent, etc. The resulting structured outputs alongside original note text feed into a logistic regression classifier (Stage 3), which produces a final binary prediction. This multi-stage filtering enables computational efficiency and interpretable, evidence-based predictions that generalize well across hospitals without local retraining.
Technical innovations
- A multi-stage pipeline combining zero-shot large language model screening, zero-shot LLM structured evidence extraction, and traditional supervised classification to detect self-harm in sparse, noisy clinical triage text.
- Use of LLM-extracted structured indicators (act, injury, method, intent, timing) and free-text reasoning to augment raw text features, improving classifier performance and interpretability.
- Demonstration that a simple logistic regression on LLM-augmented features outperforms fine-tuned BERT models and gradient boosting baselines, highlighting the value of explicit evidence features.
- Evaluation of cross-hospital and temporal transferability without requiring site-specific retraining or adaptation, showing robustness in real-world heterogeneous clinical environments.
Datasets
- Royal Melbourne Hospital (RMH) — ~316,895 notes in development (2012-2017), ~369,148 notes in prospective test (2018-2022) — hospital ED triage notes, Australia
- Latrobe Regional Health (LRH) — 34,234 notes in development, 136,932 in test (2012-2017), 163,975 in prospective test (2018-2022) — regional public hospital ED notes, Australia
- Sunshine Hospital (SunH) — 60,907 notes in development, 243,628 in test (2019-2022) — large public hospital ED notes, Australia
Baselines vs proposed
- Logistic Regression (TF-IDF + MiniLM features): RMH test AUPRC=0.816±0.021; Proposed approach: 0.887±0.016
- Gradient Boosting Machine (Rozova et al.): RMH test AUPRC=0.844±0.020; Proposed approach: 0.887±0.016
- ClinicalBERT (fine-tuned): RMH test AUPRC=0.880±0.019; Proposed approach: 0.887±0.016
- Logistic Regression (TF-IDF + MiniLM features): SunH test AUPRC=0.720±0.017; Proposed approach: 0.816±0.015
- ClinicalBERT: SunH test AUPRC=0.737±0.019; Proposed approach: 0.816±0.015
- Gradient Boosting Machine: SunH test AUPRC=0.719±0.019; Proposed approach: 0.816±0.015
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.02545.
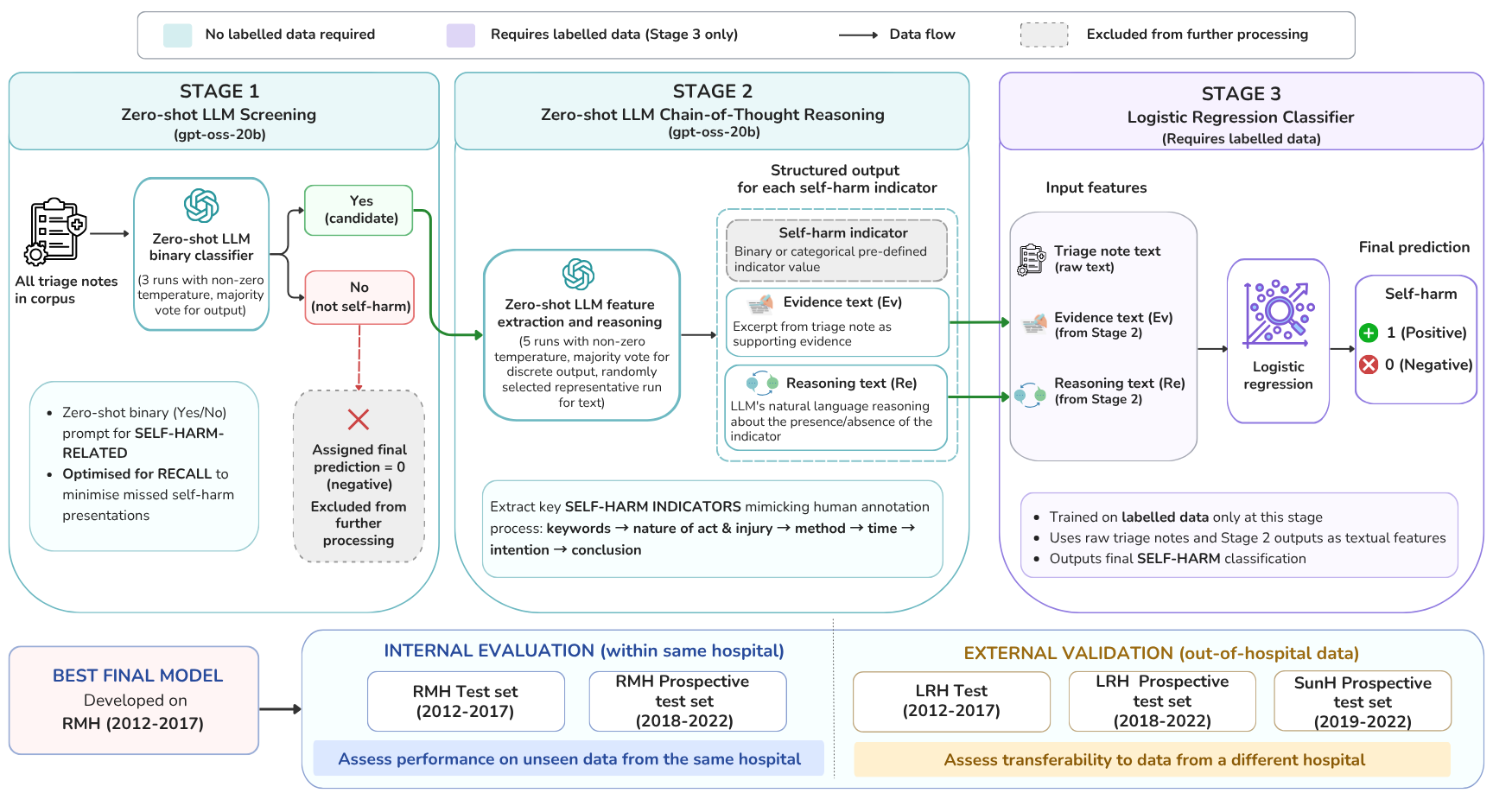
Fig 1: Flowchart of proposed three-stage approach for self-harm surveillance.
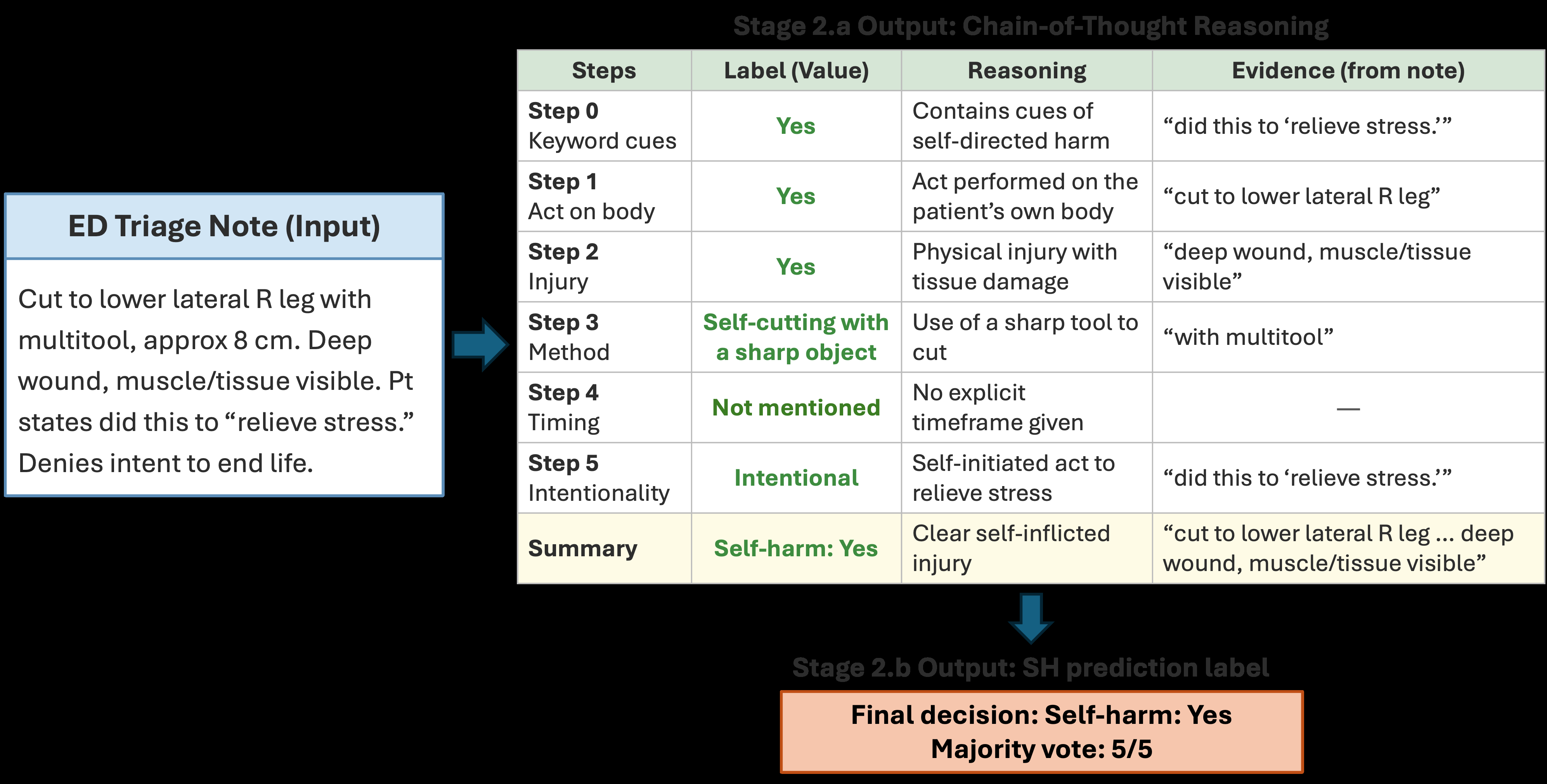
Fig 2: Example output of Stage 2. The presented triage note was synthesised for publication pur-
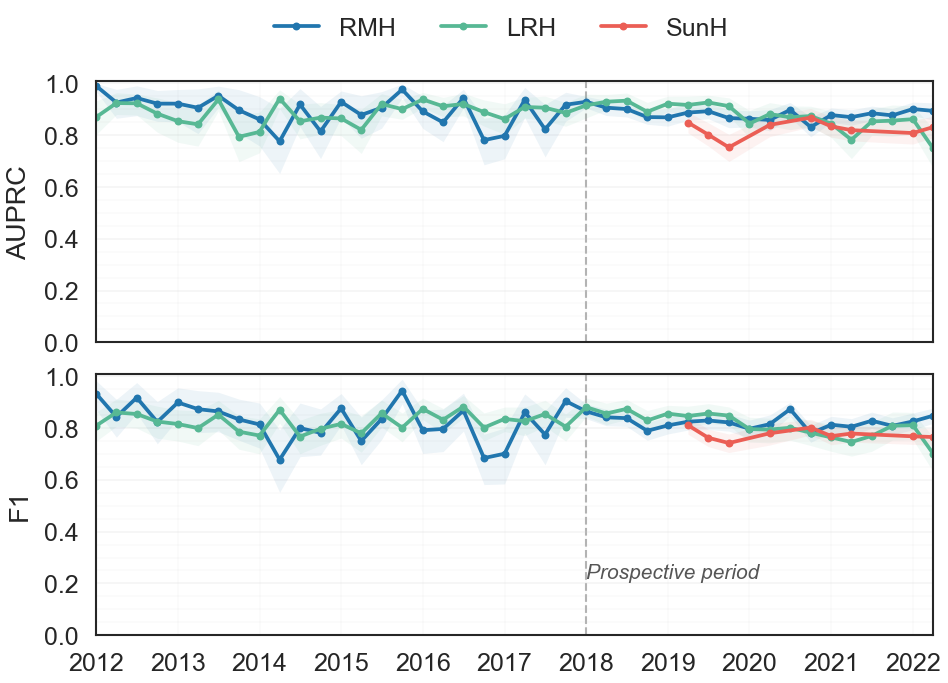
Fig 3: Quarterly AUPRC and F1 across RMH, LRH, and SunH evaluation periods. RMH represents
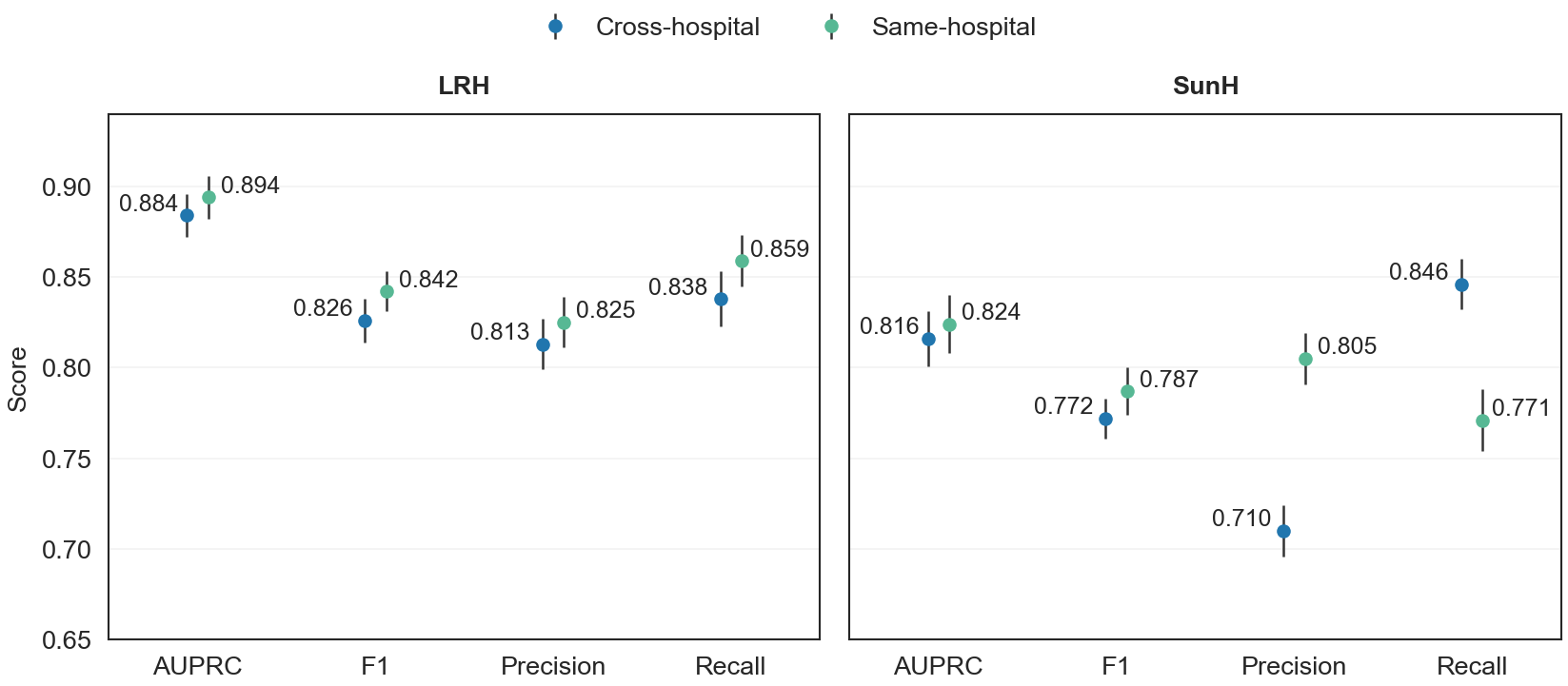
Fig 4: Performance comparison between cross-hospital transfer and same-hospital training. Cross-
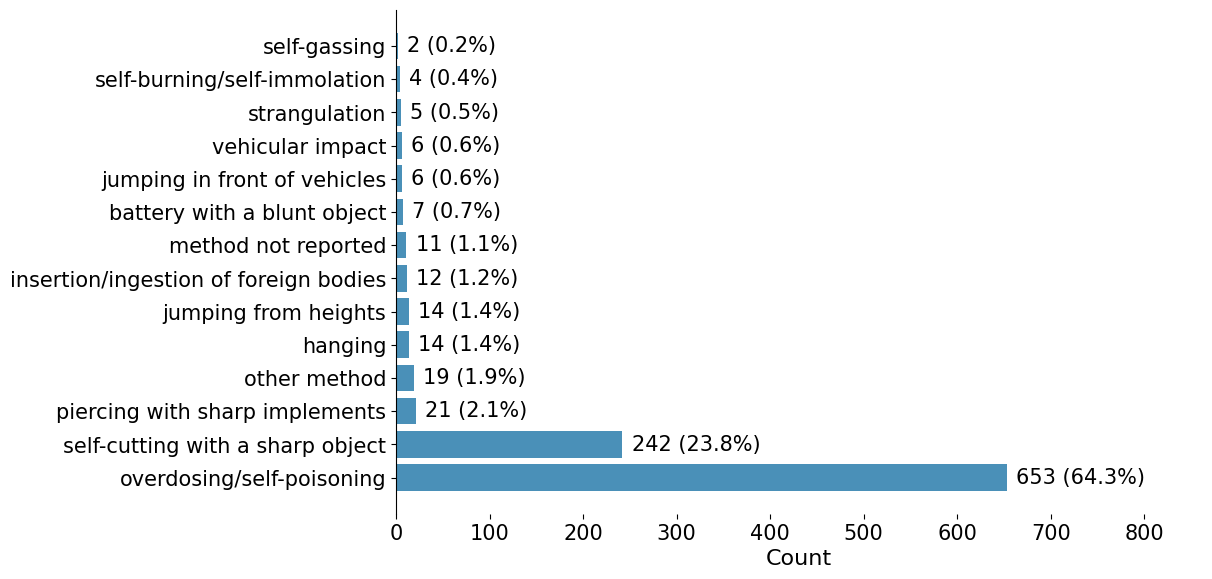
Fig 5: Clinician-annotated distribution of primary self-harm methods in RMH Chunk 3.

Fig 6: Confusion matrices at the classification threshold of 0.614 for all notes in the test set.
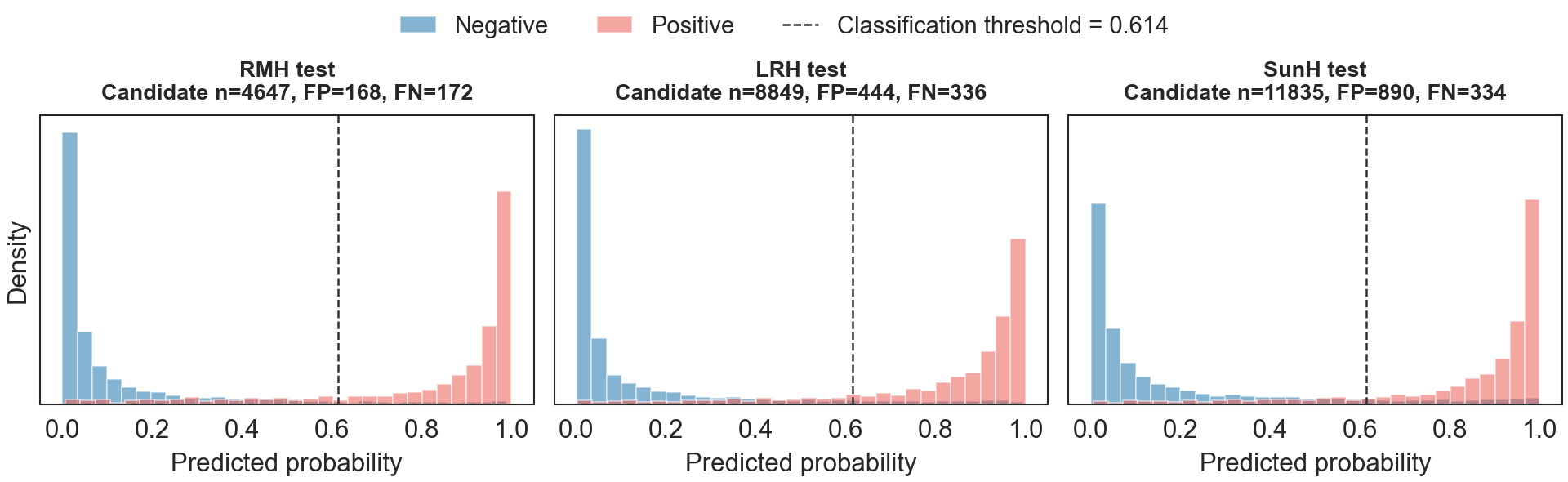
Fig 7: Predicted probability distributions for screen-positive cases at each test site.
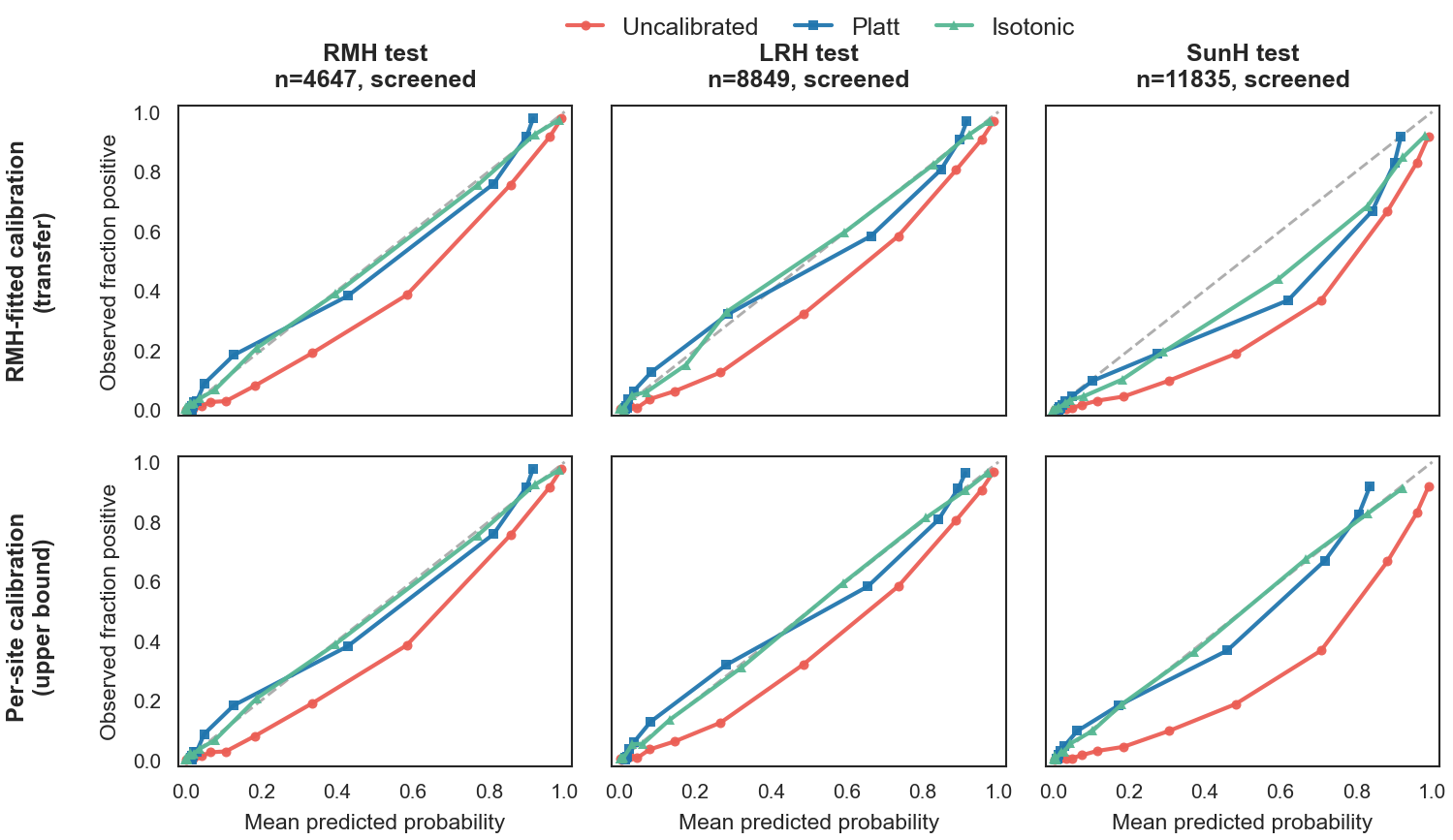
Fig 8: Calibration curves for the final model on screened cases across the held-out test sets. Top row:
Limitations
- Evaluation limited to three Australian hospital ED datasets; generalization to other countries, healthcare systems, or languages untested.
- Only the primary self-harm method was clinically validated; other extracted evidence and indicators lacked independent clinician review.
- The LLM-based evidence extraction relied on zero-shot prompting without local fine-tuning; potential further gains from prompt engineering or few-shot tuning remain unexplored.
- Lower precision and shifted precision-recall balance observed particularly at the SunH external site, likely due to local documentation or population differences.
- Calibration of predicted probabilities was imperfect and site-dependent; only post-hoc calibration was explored without integration into the main pipeline.
- The approach remains computationally nontrivial due to extensive LLM inference despite screening, which may limit real-time deployment without further optimization.
Open questions / follow-ons
- Can the structured evidence extraction step be fine-tuned or few-shot adapted per hospital to improve precision without sacrificing recall?
- How does the approach generalize to other clinical settings, languages, or data sources beyond Australian ED triage notes?
- Can real-time deployment be optimized by replacing the large LLM with smaller specialized models or serverless architectures?
- What is the utility and validity of the other extracted self-harm indicators (injury, intent, timing) for epidemiological surveillance and clinical intervention?
Why it matters for bot defense
Although this work does not directly target bot defense or CAPTCHA, it exemplifies the potential of evidence-augmented machine learning combining LLM zero-shot prompting with traditional classifiers to improve classification accuracy and interpretability on noisy short text data. Bot-defense practitioners may consider similar staged pipelines where an initial high-recall LLM filter reduces candidate inputs for downstream more precise classification. The explicit extraction of structured supporting evidence from unstructured text also suggests avenues for richer feature design that improves robustness and transferability across domains or data sources. Moreover, the study's demonstration of cross-site transfer without retraining is relevant for systems that must operate over heterogeneous environments without frequent retraining. However, computational expense considerations highlighted here remain important when deploying large LLMs at scale.
Cite
@article{arxiv2606_02545,
title={ Transferable Self-Harm Surveillance from Emergency Department Triage Notes Using an Evidence-Augmented Machine Learning Approach },
author={ Liuliu Chen and Gowri Rajaram and Eleanor Bailey and Katrina Witt and Michelle Lamblin and Jo Robinson and Mike Conway and Vlada Rozova },
journal={arXiv preprint arXiv:2606.02545},
year={ 2026 },
url={https://arxiv.org/abs/2606.02545}
}