
The Structural Influence of Low-Credibility Narratives During the COVID-19 Vaccine Rollout
Source: arXiv:2606.01630 · Published 2026-06-01 · By Lynnette Hui Xian Ng, Wenqi Zhou, Kathleen M. Carley
TL;DR
This study tackles the challenge of accurately quantifying the structural influence of low-credibility narratives spreading on social media during the COVID-19 vaccine rollout. It introduces two novel network-aware metrics, Appeal and Scope, that blend message popularity with the structural connectivity of the message author in the communication network. Using a large-scale dataset of 5.8 million Twitter (X) messages related to COVID-19 vaccine misinformation, the authors compare the disseminative efficacy of human versus automated (bot) accounts across three temporally distinct phases: Pre-Vaccine, Vaccine Launch, and Post-Vaccine. The key finding is that although bots distribute a significant volume of misinformation, human users achieve substantially higher structural influence, especially during the critical Vaccine Launch phase. Bots maximize their influence during the uncertain Pre-Vaccine period when authoritative information is lacking, while human-driven narratives dominate during the focal rollout week. This temporal differentiation underscores distinct operational strategies of bots and humans in information diffusion and calls for time-sensitive moderation strategies.
Key findings
- Human-distributed low-credibility narratives generated 22x greater Appeal than bot-distributed equivalents, whereas non-low-credibility content from humans produced 449x greater Appeal than bots.
- Bots produced 41.2% of total messages but only 23.1% of accounts, indicating higher volume per bot.
- Low-credibility narratives accounted for 69.9% and 70.7% of messages in Pre-Vaccine and Vaccine Launch periods, versus 63.4% Post-Vaccine.
- During the Vaccine Launch week, human low-credibility narratives showed a 14.11% increase in Appeal and 85.52% increase in Scope (statistically significant, p<0.001).
- Bots had highest Appeal and Scope during Pre-Vaccine period and lowest during Vaccine Launch (interaction effect coefficients significant, p<0.001).
- Regression shows automated accounts exhibit 91.11% lower Appeal and 89.56% lower Scope than humans after controlling for covariates.
- Mann-Whitney U tests show statistically significant, stable separation between bots and humans in Appeal (r=0.100) and Scope (r=0.071) across time periods.
- Bots distribute relatively more low-credibility than non-low-credibility content; bot-distributed low-credibility narratives were 34% more widespread by Scope than bot non-low-credibility narratives.
Threat model
The adversary consists of automated bot accounts programmed to amplify low-credibility COVID-19 vaccine narratives by exploiting social media platform distribution mechanisms. These bots operate at high volume and frequency without human attention limits, aiming to maximize message spread especially during high uncertainty periods. The study assumes bots cannot fully mimic human network influence structurally and that the platform’s network interactions (retweets, mentions) can be observed. The model excludes scenarios involving direct platform intervention or bots that evade detection at rates beyond the BotHunter classifier.
Methodology — deep read
Threat Model & Assumptions: The adversary consists of automated bot accounts designed to rapidly propagate low-credibility COVID-19 vaccine narratives on social media, contrasted against organic human users. The study assumes distinct operational behaviors and temporal deployment strategies between bots and humans but does not model adversarial evasion tactics or coordinated campaigns explicitly.
Data: The dataset, CovidInfo, comprises approximately 8.6 million Twitter messages spanning December 1, 2020, to January 31, 2021, covering three phases: Pre-Vaccine (Dec 1-7), Vaccine Launch (Dec 8-10), and Post-Vaccine (Jan 25-31). Messages were filtered for those containing low-credibility narratives related to COVID-19 vaccines, identified through a comparison to a curated reference dataset of narrative categories using TwHIN-BERT semantic embeddings and cosine similarity thresholding at 0.7, producing about 5.89 million low-credibility messages.
Account Classification: BotHunter, a hierarchical random forest machine learning model, was used to assign bot likelihood scores to accounts, labeling those with probability ≥ 0.70 as bots and <0.70 as human users. This differentiated 519,337 bot accounts (23.1%) responsible for 41.2% of messages, from 1,738,645 human accounts.
Structural Influence Metrics: The authors define two novel metrics. Appeal weights a message's retweet count by the total degree percentile of its author in the constructed all-communication network (based on retweets and mentions) for the relevant time period, capturing message popularity moderated by author connectivity. Scope weights the author's total degree centrality by the percentile rank of the message's retweet count, quantifying the author's potential network reach amplified by message popularity.
Statistical Models: Due to zero-inflated and heavy-tailed distributions of engagement and degree measures, Tweedie compound Poisson-Gamma regression models were fitted for Appeal and Scope as dependent variables. Models incorporated bot status, time period, narrative category, retweet status, and account age as covariates. An interaction term between bot status and time period modeled their conditional temporal effects.
Evaluation: Descriptive statistics characterized bot/human participation and low-credibility narrative prevalence over time. Statistical tests including Mann-Whitney U and Kruskal-Wallis H tested between-group differences and temporal stability. Regression coefficient magnitude and significance assessed differential effects, with all models controlling for potential confounds and multicollinearity verified by VIF scores below 5.
Reproducibility: The study builds on a public CovidInfo dataset and published reference datasets for low-credibility classification. BotHunter is publicly documented though proprietary Twitter embeddings (TwHIN-BERT) were used, limiting full replication of semantic filtering. The paper does not indicate code or model weight release, so direct replication of the classification pipeline is limited but statistical analysis is fully detailed.
End-to-end example: For a tweet posted during the Vaccine Launch phase, the author’s network degree percentile and the tweet’s retweet count yield an Appeal score measuring its influence weighted by author connectivity. Simultaneously, the author’s degree centrality combined with the tweet’s retweet percentile yields Scope, reflecting broader network reach. These influence metrics are regressed on bot status and time period indicators to isolate how automated vs human authorship affects diffusion patterns across vaccine event stages.
Technical innovations
- Introduction of two composite structural influence metrics—Appeal and Scope—that integrate message popularity with author network connectivity to quantify narrative diffusion beyond simple engagement counts.
- Application of Tweedie compound Poisson-Gamma regression modeling to handle zero-inflated, heavy-tailed distributions of social media diffusion metrics.
- Temporal segmentation of information diffusion into Pre-Vaccine, Vaccine Launch, and Post-Vaccine phases allowing nuanced analysis of dynamic actor influence across event lifecycle.
- Use of domain-specialized TwHIN-BERT embeddings combined with cosine similarity thresholding for semantic classification of low-credibility COVID-19 vaccine narratives.
Datasets
- CovidInfo — 8.6 million tweets — public dataset of COVID-19 vaccine discussions on Twitter (X)
- Reference low-credibility narrative dataset — size unspecified — expert-annotated for COVID-19 misinformation narratives
Baselines vs proposed
- Human accounts Appeal: baseline normalized to 1; Bot accounts Appeal = 0.089 (91.11% lower), p<0.001
- Human accounts Scope: baseline normalized to 1; Bot accounts Scope = 0.104 (89.56% lower), p<0.001
- Low-credibility narratives during Vaccine Launch phase Appeal: +6.92% vs other periods, p<0.001
- Low-credibility narratives during Vaccine Launch phase Scope: +52.04% vs other periods, p<0.001
- Bot × Vaccine Launch interaction Appeal: -30.2% relative to human baseline, p<0.001
- Bot × Vaccine Launch interaction Scope: -62.3% relative to human baseline, p<0.001
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.01630.
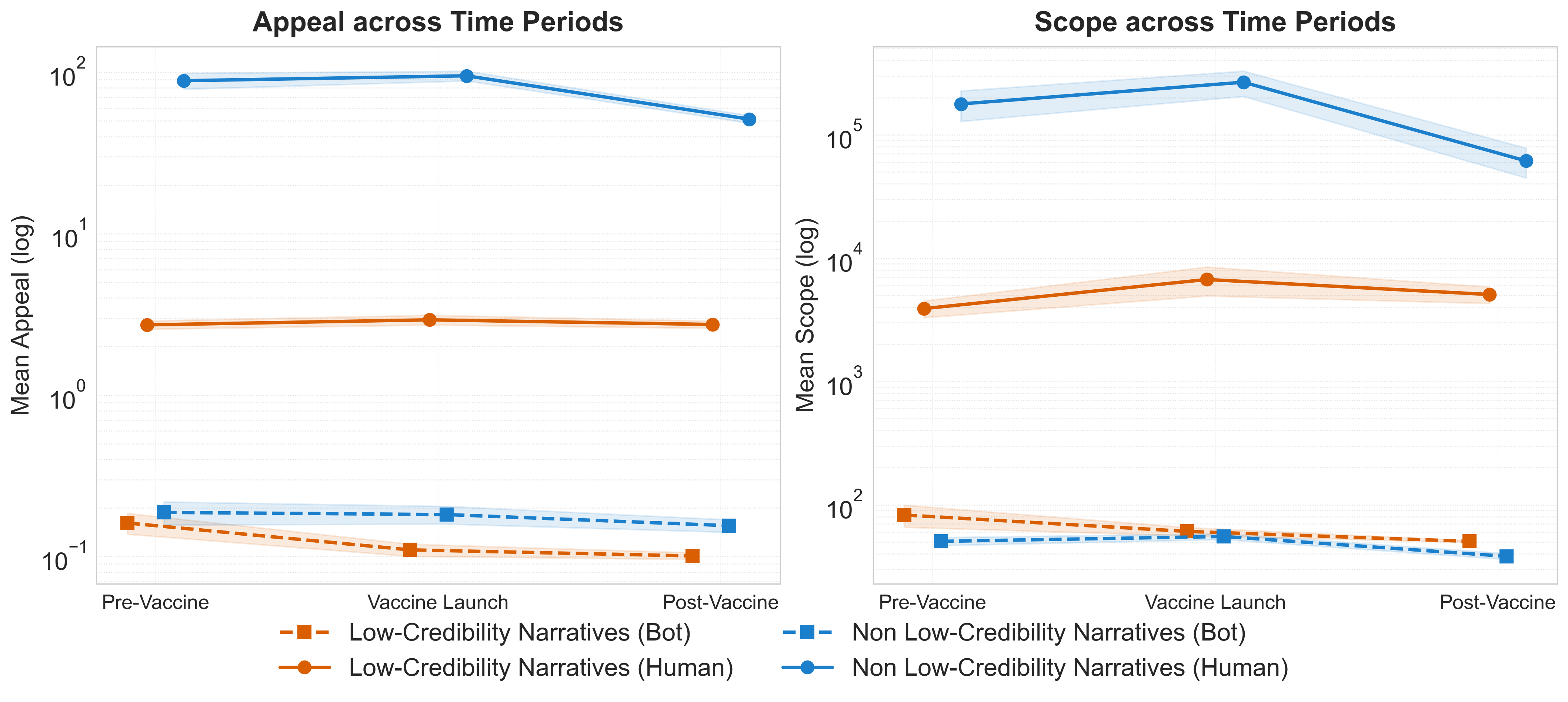
Fig 1: Average Appeal and Scope of Tweets across the three Time Periods.
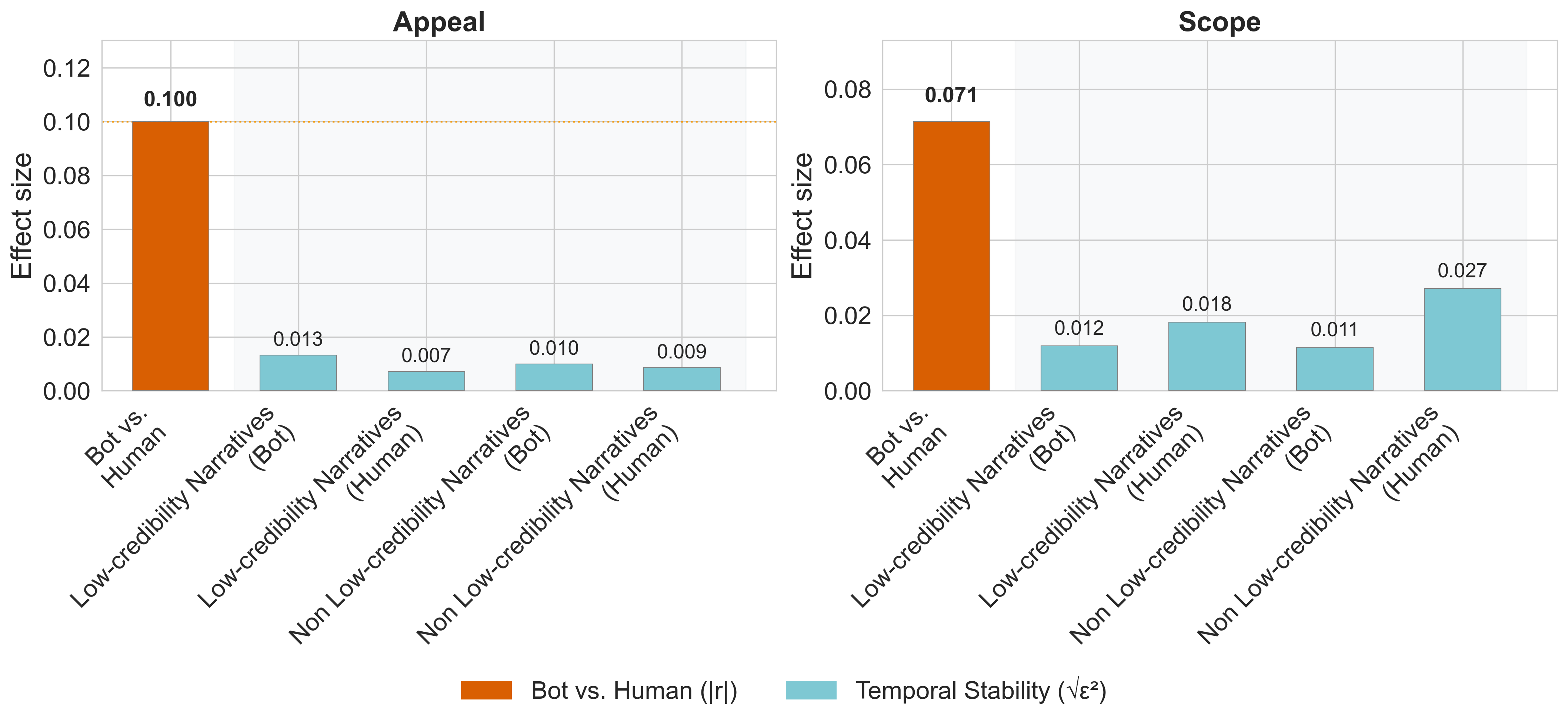
Fig 2: Effect size contrast between between-group (bot-human) separation (orange)
Limitations
- Use of proprietary Twitter-trained TwHIN-BERT embeddings limits replicability of narrative classification pipeline.
- Bot detection threshold (P(bot)≥0.7) may misclassify borderline accounts, affecting bot vs human comparisons.
- Analysis focuses on retweet and mention networks but does not consider other interaction types or platform dynamics.
- Temporal segmentation uses fixed discrete windows which may smooth over finer-grained dynamics.
- No adversarial or coordinated campaign detection to differentiate different bot strategies or network manipulations.
- Causal claims about influence potential are inferred from observational network data, not experimentally validated.
Open questions / follow-ons
- How do coordinated bot campaigns versus isolated automated accounts differ in structural influence patterns?
- Can dynamic real-time detection of influence shifts during unfolding crises improve platform moderation strategies?
- How generalizable are the Appeal and Scope metrics to other types of misinformation or social media platforms?
- What causal impact do bot-driven diffusion patterns have on offline public health behaviors and attitudes?
Why it matters for bot defense
For bot-defense practitioners, this study underscores the importance of incorporating network structural metrics beyond raw volume or engagement counts when evaluating the influence of automated accounts spreading misinformation. The defined Appeal and Scope metrics provide concrete tools to quantify the diffusion capacity of bot versus human actors, helping to identify when automated campaigns are structurally optimized to amplify narratives.
Furthermore, the detected temporal shifts suggest that bot detection and mitigation efforts must be adaptable to event lifecycle stages—in early ambiguous phases bots dominate, whereas later phases see human-driven amplification. This insight advises CAPTCHA and bot-detection systems to prioritize intervention timing and tailor strategies to the specific operational strengths of bots during different event stages, rather than static or volume-based heuristics. Overall, the paper provides actionable analytics to better calibrate defenses against bot-influenced low-credibility narratives in critical real-world events.
Cite
@article{arxiv2606_01630,
title={ The Structural Influence of Low-Credibility Narratives During the COVID-19 Vaccine Rollout },
author={ Lynnette Hui Xian Ng and Wenqi Zhou and Kathleen M. Carley },
journal={arXiv preprint arXiv:2606.01630},
year={ 2026 },
url={https://arxiv.org/abs/2606.01630}
}