
The Ghost Couple: Correlated LLM Name Priors and Their Haunting of the Web and Academic Publishing
Source: arXiv:2606.02184 · Published 2026-06-01 · By Michał Brzozowski, Neo Christopher Chung
TL;DR
This paper investigates a novel and underexplored phenomenon in large language models (LLMs): the generation of correlated fictional character name ensembles, especially recurring ghost author identities, that persistently appear across AI-generated web content and academic publishing metadata. The authors demonstrate that models like Anthropic's Claude, Google's Gemini, and OpenAI's GPT each produce not only high-probability individual fictional names but ensembles of names (pairs and trios) whose co-occurrence rates far exceed chance and are stable across independent generations. These name priors are model-family-specific, version-specific, and actively suppressed at release boundaries, creating identifiable temporal fingerprints across releases.
Critically, this behavioral artifact propagates beyond text generation into the real-world scholarly infrastructure. The authors identify 1,655 ghost-authored records on Zenodo, a CERN-operated repository that mints legitimate DOIs, which list nonexistent journals, falsified publication dates, and author names that trace back directly to these LLM name priors. They trace concentrated bursts of uploads that coincide with LLM deployment windows and uncover synthetic research groups on ResearchGate comprising these ghost names, in some cases combining names derived from multiple model families. This demonstrates a pressing vulnerability: LLM-generated ghost identities can infiltrate and contaminate academic metadata ecosystems at scale, potentially undermining trust and provenance.
The paper provides a systematic forensic methodology to predict these ghost ensembles through API probing of public models, then use these priors as detection signatures for web and academic content mining. The results establish correlated name prior crystallization as a robust, general phenomenon distinct from simple single-name repetition. Suppression patterns across model checkpoints suggest awareness of the issues by developers. This pipeline from LLM behavior to real digital contamination presents new challenges for bot defense, misinformation, and scholarly record integrity.
Key findings
- Elena Vasquez and Marcus Chen co-occur in 23% of Claude-sonnet-4-20250514 pair-prompt responses, dropping to 0% in the latest Claude-sonnet-4-6 checkpoint, evidencing deliberate suppression.
- Gemini’s ghost ensemble (Aris Thorne + Lena Petrova) achieves 93% solo name concentration and 37% pair co-occurrence, indicating near mode collapse on the pair.
- GPT’s most frequent ghost name is Elara Voss, a strong solo prior (23%), but lacking a consistent pairing partner, unlike Claude and Gemini ensembles.
- 1,655 ghost-authored records claiming nonexistent journals with fabricated publication dates were identified on Zenodo, all carrying real DataCite DOIs, making them harvestable by scholarly aggregators.
- Zenodo records show deliberate backdating of publication dates by 2–6 years, with 991 records registered in March 2026 alone, indicating a highly automated burst.
- ResearchGate hosts synthetic research groups combining ghost authors from multiple model families, e.g. papers jointly listing Elena Vasquez (Claude) and Aris Thorne (Gemini).
- The spike in ghost author surname co-occurrence on ResearchGate begins December 2025, about seven months after Claude-sonnet-4 release (May 2025), indicating pipeline latency from model release to content upload and indexing.
- False portraits of ghost authors on websites feature diffusion model artifacts and/or stock photos misattributed as real researchers.
Threat model
The adversary is an entity that uses publicly accessible large language models to generate fictional experts and author names without overriding default or learned name priors. They have no direct model weight access or internal knowledge but may automate large-scale content generation and upload to web/academic platforms. They exploit the LLMs’ correlated name priors as natural defaults to fabricate synthetic author identities that trick metadata aggregators and indexing services. The adversary cannot alter model training or backend but can generate and distribute AI content embedding these ghost identities.
Methodology — deep read
The paper’s core empirical approach involves two main phases: controlled probing of public LLM APIs to identify name priors and correlation structures, followed by large-scale mining of web and academic databases using these priors as forensic signatures.
Threat Model & Assumptions: The adversary is any agent using LLMs (Claude, Gemini, GPT) to generate content with fictional expert names without overriding default name priors. The researcher assumes no internal model access but leverages public APIs and uses output distributions as signal. The goal is to observe recurring fictional names and their co-occurrence patterns that leak model-specific priors into public text.
Data: The authors probed nine Claude checkpoints, ten GPT checkpoints, and one Gemini checkpoint, collected in March 2026, with varied prompts. The prompt sets consisted of 30 single-expert, 30 pair-expert, and 30 trio-expert prompts per checkpoint (with some variations). They extracted proper names from responses using regex capitalized bigram patterns.
Architecture/Algorithm: The main analytic technique was frequency and co-occurrence analysis of extracted names from model completions, focusing on recurring names that appear disproportionately and as correlated pairs or trios. They defined ghost pairs/trios precisely based on regex matching (e.g., Elena Vasquez + Marcus Chen) and measured presence rates per prompt set per checkpoint.
Training Regime: Not applicable as models probed were black-box APIs without re-training. However, for each checkpoint, 30 prompts were run per condition (single, pair, trio), temperature=1.0, max_tokens=800 (Claude/GPT) or 500 (Gemini).
Evaluation Protocol: Frequencies of individual and paired names were tabulated per model checkpoint, tracing name prevalence and pair/trio co-occurrences across nine Claude checkpoints to identify suppression signatures. Web crawling utilized Google Search via Serper.dev API with queries seeded by identified ghost names. ResearchGate and Zenodo repositories were queried for ghost author content and metadata. Temporal analysis compared upload dates to model release dates for pipeline latency.
Reproducibility: Code and full dataset release status is not stated explicitly and likely unavailable for scraped web and academic data. Methods rely on public API access to LLMs and public database queries.
Example: For Claude-sonnet-4-20250514, the authors ran 30 pair prompts requesting fictional co-authors. Name extraction found Elena Vasquez and Marcus Chen co-occurred in 23% of completions, a strong signal of correlated name prior. Searching the web with these names revealed sites hosting fictitious expert profiles bearing these names. Querying Zenodo for certain journal titles revealed 1,655 records backdating to 2020–2023 but actually minted in 2026, with many ghost authors including Elena Vasquez, confirming real-world propagation of the ghost ensemble.
Technical innovations
- Identification and quantification of correlated ghost name ensembles (pairs and trios) in LLM outputs, rather than independent single-name priors.
- Forensic predict-then-confirm methodology: probing model APIs to predict model-specific name priors, then using these priors as signatures to detect AI-generated content on web and academic infrastructures.
- Demonstration of model-version-specific suppression of problematic ghost name priors across successive checkpoints, providing evidence of mitigation efforts visible in output statistics.
- Discovery of a real-world impact pipeline whereby LLM-generated ghost names contaminate scholarly metadata repositories with fabricated publication and journal data carrying legitimate DOIs.
Datasets
- Claude checkpoints (9 versions) — 30 prompts per single/pair/trio prompt set — proprietary Anthropic models
- GPT checkpoints (10 versions) — 30 prompts per single/pair prompt set — proprietary OpenAI models
- Gemini checkpoint (gemini-2.5-flash) — 30 prompts per single/pair/trio prompt set — proprietary Google model
- Zenodo ghost-authored records — 1,655 records dated 2026-03 and 2026-04 — public CERN-operated repository metadata
- ResearchGate fake author publications — 436 records identified via search — public academic social network
- Google Search results via Serper.dev API — various URLs for ghost name co-occurrences
Baselines vs proposed
- Claude-sonnet-4-20250514: Elena Vasquez single-name frequency = 66% vs Claude-sonnet-4-6: 7%
- Claude-sonnet-4-20250514 pair-prompt co-occurrence of Elena Vasquez + Marcus Chen = 23% vs claude-sonnet-4-6 = 0%
- Gemini gemini-2.5-flash: Aris Thorne solo frequency = 93%, pair co-occurrence with Lena Petrova = 37%
- GPT-4-turbo-...: Elara Voss solo frequency = 23%, no fixed partner detected
- Zenodo ghost-authored records: 1,655 records with fabricated venues and backdated dates vs zero such records in legitimate journal query
- Ghost records upload burst on Zenodo: 1–2 records/month in 2025 vs 991 in March 2026
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.02184.

Fig 1: Elena Vasquez and Marcus Chen co-appearing across seven independently produced AI-generated pages

Fig 2: The Claude ghost trio co-occurring across three independent websites (rows), grouped by surname
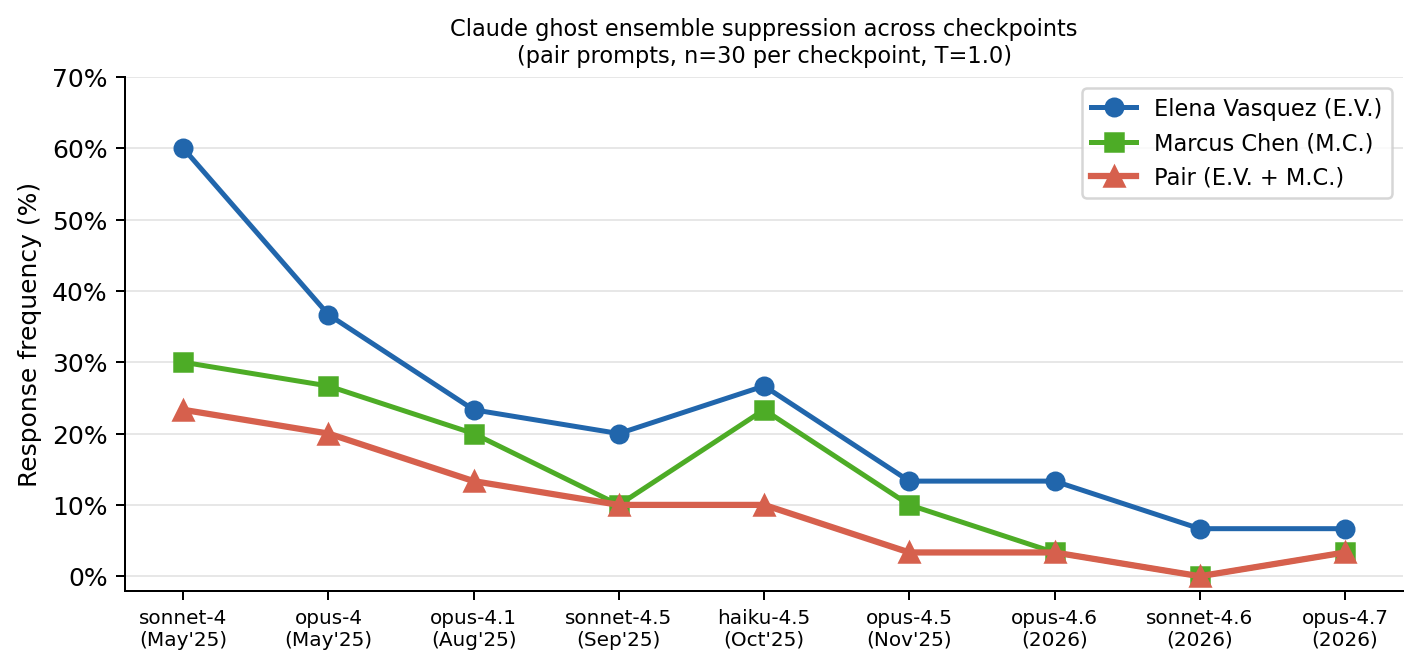
Fig 3: Elena Vasquez, Marcus Chen, and their pair
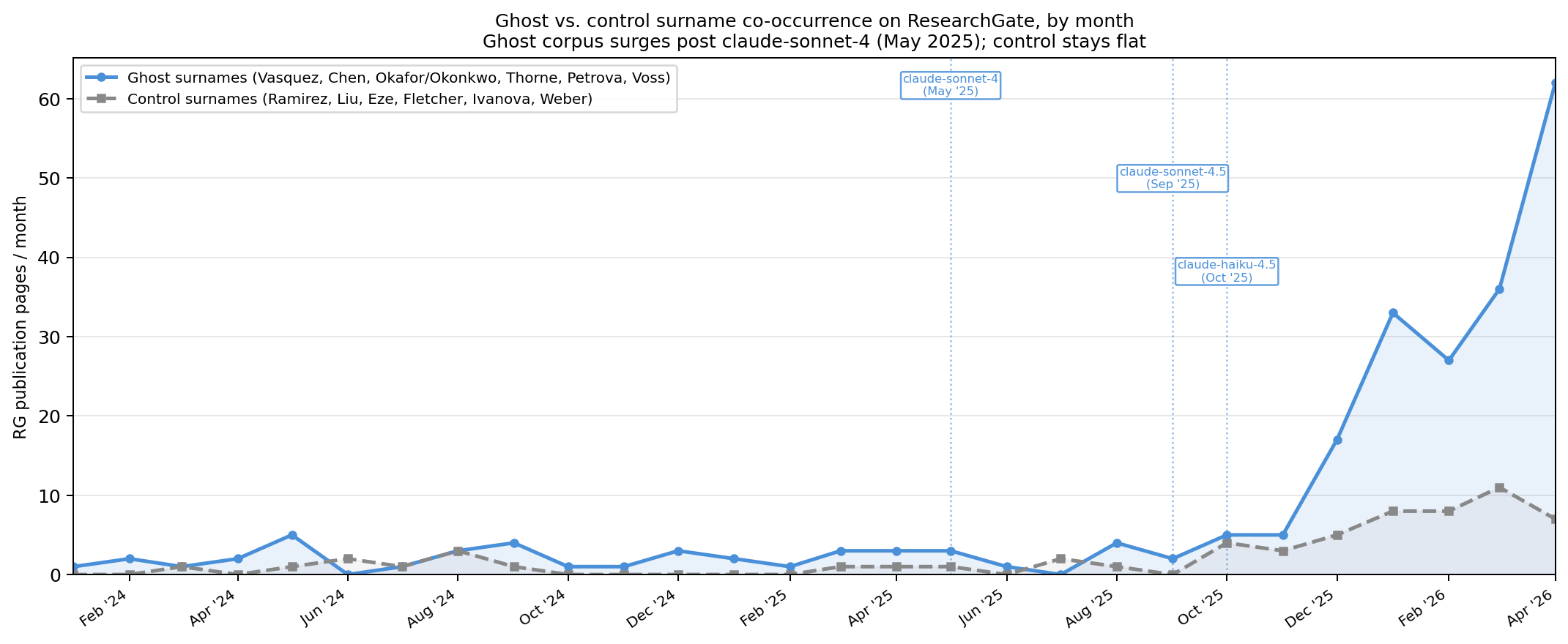
Fig 4: Monthly ghost vs. control surname co-occurrence on ResearchGate. Control surnames (demographically
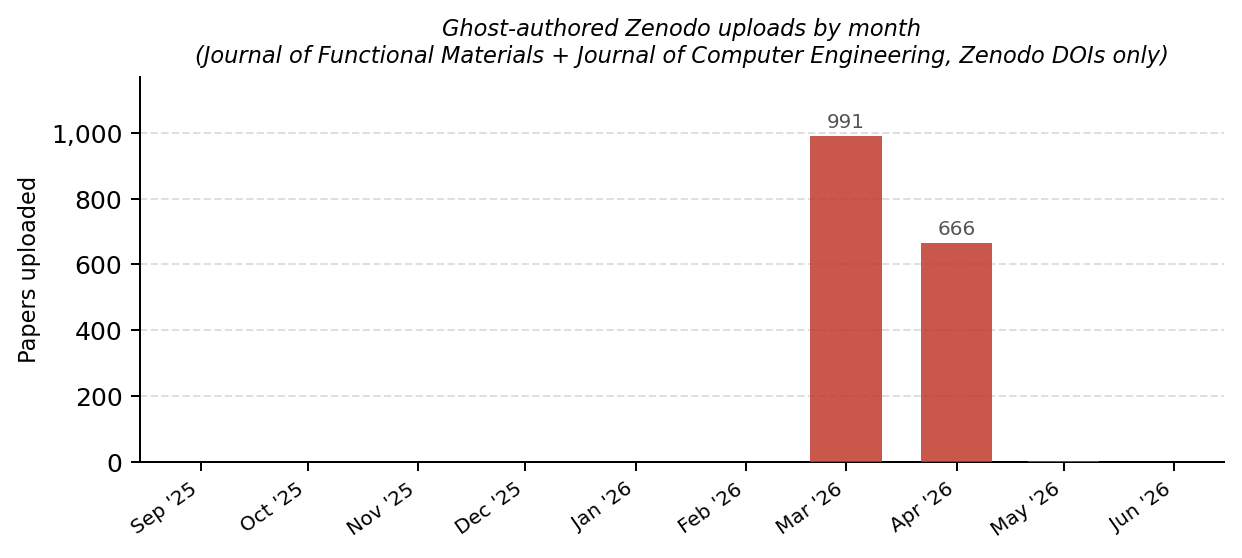
Fig 5: Monthly Zenodo upload counts for ghost-authored records (Journal of Functional Materials and Journal
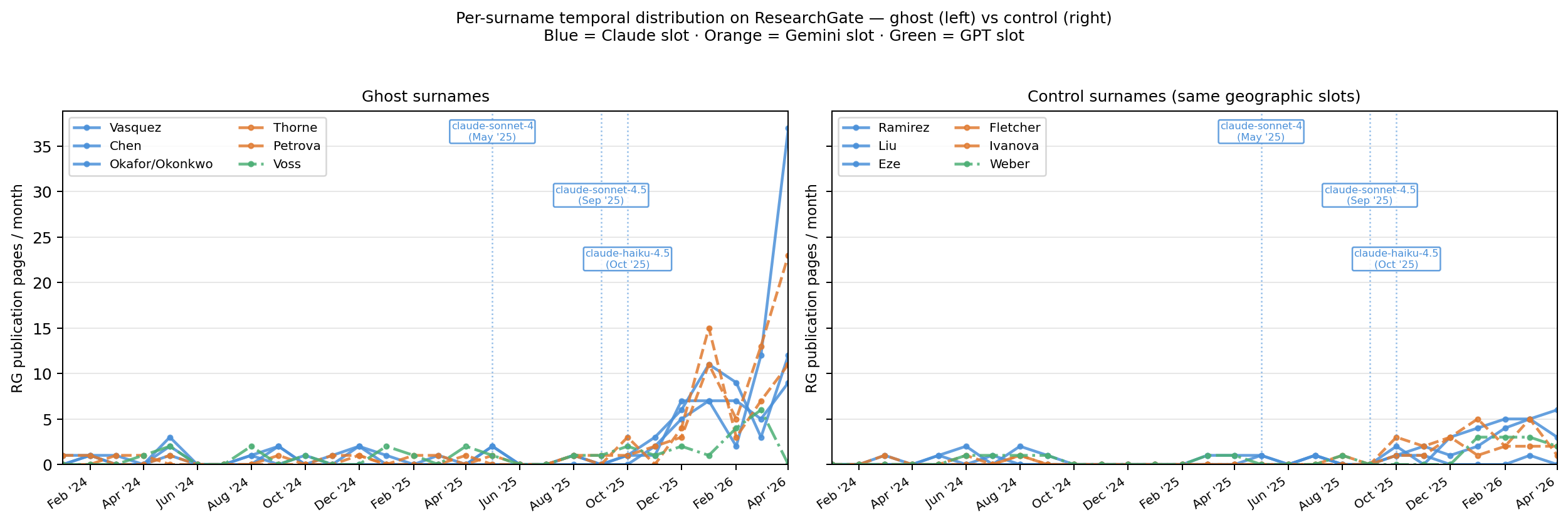
Fig 6: Per-surname temporal distribution, ghost (left) vs. control (right), shared y-axis. Control lines are flat
Limitations
- Only publicly accessible API checkpoints were probed; non-public or fine-tuned internal models were not evaluated.
- Prompt set size (30 prompts per condition) may miss lower-frequency name priors or rare ensemble structures.
- Web corpus collection via Google Search API is subject to indexing delays and recency bias; some content may be missed.
- True real-world individuals with the same names may exist, complicating definitive attribution of ghost authorship.
- No direct adversarial evaluation or simulation of malicious fake-paper generation pipelines was conducted beyond observational mining.
- No automatic detection model or algorithm was proposed—paper focuses on forensic characterization.
Open questions / follow-ons
- How do different model training diets and narrative fine-tuning regimes drive the formation or suppression of correlated name ensembles?
- Can robust automated detection algorithms use correlated ensemble signatures as reliable markers for AI-generated content?
- What mitigation strategies beyond suppression at release boundaries can prevent ghost author hallucination and propagation?
- How widespread is contamination of scholarly records beyond Zenodo and ResearchGate, e.g. in CrossRef, Scopus, or library catalogues?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this work highlights a distinctive signal—correlated ghost name ensembles—that can serve as indirect fingerprints of AI-generated synthetic personas embedded in text. Unlike stylometric or token-watermarking methods requiring model access, these name priors exist in public outputs and persist in web and academic metadata, opening new avenues for detecting and mitigating AI-driven identity fabrication attacks. Understanding the temporal dynamics of ensemble suppression and proliferation can inform monitoring strategies for emerging synthetic content threats.
The large-scale contamination of academic metadata repositories via real DOIs minted on platforms like Zenodo illustrates a non-traditional attack vector where the infrastructure trusted for content authenticity is subverted by AI-generated ghost authorships. Defense systems should consider name-ensemble signatures as a complementary detection layer to token-level classifiers or behavior analysis, especially for verifying user-submitted academic papers, profiles, or expert testimonials. The demonstration that these priors vary by model family and version suggests that provenance-aware defenses can leverage model-specific profiles in risk scoring.
Cite
@article{arxiv2606_02184,
title={ The Ghost Couple: Correlated LLM Name Priors and Their Haunting of the Web and Academic Publishing },
author={ Michał Brzozowski and Neo Christopher Chung },
journal={arXiv preprint arXiv:2606.02184},
year={ 2026 },
url={https://arxiv.org/abs/2606.02184}
}