
OpenWebRL: Demystifying Online Multi-turn Reinforcement Learning for Visual Web Agents
Source: arXiv:2606.02031 · Published 2026-06-01 · By Rui Yang, Qianhui Wu, Yuxi Chen, Hao Bai, Wenlin Yao, Hao Cheng et al.
TL;DR
This paper addresses the challenge of training capable visual web agents that interact robustly and adaptively with real, dynamic websites. Current state-of-the-art systems are largely proprietary and heavily dependent on large static supervised datasets, which limits scalability and adaptability due to high collection costs and limited coverage. The authors propose OpenWebRL, an open-source framework enabling online multi-turn reinforcement learning (RL) directly on live websites to overcome these bottlenecks. OpenWebRL integrates scalable browser infrastructure, supervised initialization with a small set of trajectories, multimodal context management, trajectory-level success judging, and multi-turn policy optimization using a novel multimodal group-relative policy optimization (MM-GRPO) method.
Using OpenWebRL, the authors train OpenWebRL-4B, a 4-billion parameter visual-language model, which achieves state-of-the-art success rates on three challenging live benchmarks: 67.0% on Online-Mind2Web, 64.0% on DeepShop, and 74.1% on WebVoyager. These results substantially outperform prior open-source agents of comparable or larger scale, while remaining competitive with proprietary systems including OpenAI CUA and Gemini CUA. The work also presents a detailed empirical analysis of key design choices making online RL effective for visual web agents and studies RL’s impact on agentic reasoning. The code, models, and training data are released to support reproducibility and future research.
Key findings
- OpenWebRL-4B achieves 67.0% success on Online-Mind2Web and 64.0% on DeepShop, surpassing prior open agents such as FARA-7B by +32.9 and +37.8 points respectively (Table 2).
- The 4B model outperforms MolmoWeb-8B by +31.7 points on Online-Mind2Web and +21.7 points on DeepShop, despite using 2 orders of magnitude fewer supervised trajectories (0.4K vs 278K).
- Scaling up to OpenWebRL-8B further improves average success rate to 68.7%, a +0.3 point gain over 4B-scale version.
- Supervised fine-tuning with only 0.4K curated trajectories effectively warms up the model, improving success rate from 39.3% to 52.0% on average, before RL (Table 2).
- Multimodal Multi-turn GRPO RL training further boosts success rates by +16.4 points over SFT for 4B models, highlighting importance of online RL.
- Using a distilled 8B judge network for trajectory success evaluation matches GPT-4.1 judge performance while reducing labeling cost by over $500 per training run.
- The agent’s multi-tool browser interface and multimodal context management, which retains only the most recent screenshots and textual interaction history, balance state observability with efficiency.
- Warm-starting RL from a supervised fine-tuned policy yields a ~10% consistent advantage over starting RL from base model, particularly strong (+22.3 points) on hard tasks.
Threat model
The adversary is the open web environment itself, characterized by dynamic, non-stationary webpage content, transient failures such as pop-ups, redirects, and bot blocking. The agent must robustly interact despite this environmental noise. There is no explicit adversarial human attacker model or malicious manipulation considered.
Methodology — deep read
Threat Model & Assumptions: The adversary is an open web environment with dynamic, non-stationary page states that can cause environment noise such as pop-ups, redirects, bot blocking, and network failures. The agent does not face adversarial manipulation in a security sense, but must robustly navigate changing web content. The training assumes no direct access to proprietary models or large curated datasets.
Data: The authors start from WebGym’s 292K raw tasks and apply filtering to exclude evaluation overlaps, near-duplicates, unstable websites, and subtasks. This yields 15,601 candidate seed tasks for supervised fine-tuning and a 2.2K filtered diverse task pool for RL training. Demonstrations are collected by rollout using a strong open-source teacher model (Qwen3-VL-235B-A22B-Thinking) with GPT-4.1 judging success. 412 highest-quality trajectories across 70 websites compose the supervised fine-tuning set.
Architecture/Algorithm: Based on the Qwen3-VL-4B-VLM backbone, the policy outputs interleaved reasoning text and tool-call instructions used to control a live browser environment via 13 atomic actions (click, hover, write, scroll, tab management, etc.). Multimodal observations include screenshots, textual metadata (URLs, tab info), and environment feedback messages extracted from DOM diffs. The training objective is a novel multimodal multi-turn variant of Group-Relative Policy Optimization (MM-GRPO), which assigns trajectory-level rewards and propagates advantages token-wise across all response turns with importance sampling and clipped ratios.
Training Regime: The model is first supervised fine-tuned for 3 epochs on 0.4K curated trajectories with behavioral cloning. Online RL fine-tuning uses 2.2K curated tasks with 90 iterations at max 15 steps and 50 iterations at max 30 rollout steps (~54K total trajectories), requiring ~300 A100 GPU days. The reward combines a format correctness check and a trajectory-level judge model output (using a distilled 8B model matching GPT-4.1). Asymmetric ratio clipping (ϵlow=0.2, ϵhigh=0.28) and task-group reward filtering form a curriculum.
Evaluation Protocol: The trained agents are evaluated on three live web benchmarks: WebVoyager (595 tasks), Online-Mind2Web (300 tasks), and DeepShop, using official success rate metrics based on external judge models and environment state checks. Evaluations use stealth browser infrastructure to reduce environment noise. Ablations include training from base vs SFT initialization, judge model comparisons, and context size analyses.
Reproducibility: OpenWebRL releases its code, models, and training datasets publicly, including distilled judge weights. Some evaluation infrastructure depends on a third-party browser-use service providing CAPTCHA handling and stealth access.
Concrete Example: Starting from Qwen3-VL-4B, the authors gather 412 successful trajectories from a teacher model to conduct supervised fine-tuning. The SFT policy initializes the online RL stage, where the agent interacts with live websites using multimodal observations and multi-tool calls. MM-GRPO optimizes policy parameters by sampling groups of trajectories, computing group-relative advantages on trajectory success judged by a GPT-4.1 or distilled judge model, and updating with clipped importance sampling. Over many iterations, success rate improves from ~52% post-SFT to 68.4% final on benchmarks, demonstrating stable learning and improved multi-turn web interaction capabilities.
Technical innovations
- OpenWebRL introduces a scalable, fault-tolerant live-browser infrastructure enabling multi-tool, multi-turn agent interaction with real, dynamic websites.
- It proposes a multimodal multi-turn Group-Relative Policy Optimization (MM-GRPO) objective that propagates trajectory-level rewards token-wise across all response turns, optimized with asymmetric clipping.
- The agent context management separates recent visual grounding (screenshots) from compressed textual memory (environment feedback and reasoning traces) to balance multimodal context length and training efficiency.
- An 8B-scale judge model distilled from GPT-4.1 labels enables cost-effective trajectory-level success evaluation with proprietary-level accuracy.
- A small supervised warm-start set (~0.4K trajectories) collected from a strong teacher model jumpstarts productive exploration for online RL, avoiding large-scale expensive curated datasets.
Datasets
- WebGym tasks — 292K raw tasks filtered to 15.6K seed tasks for SFT and 2.2K tasks for RL training — public WebGym dataset
- Supervised Fine-Tuning trajectories — 412 curated, high-quality trajectories from Qwen3-VL-235B teacher rollouts
- Online RL training pool — approximately 2.2K diverse tasks for online RL
- Evaluation benchmarks: WebVoyager (595 task subset), Online-Mind2Web (300 tasks), DeepShop (realistic shopping tasks)
Baselines vs proposed
- FARA-7B: avg success rate = 44.6% vs OpenWebRL-4B: 68.4% (+23.8 pp)
- MolmoWeb-8B: avg success rate = 51.9% vs OpenWebRL-4B: 68.4% (+16.5 pp)
- Qwen3-VL-235B-A22B-Thinking: 62.3% vs OpenWebRL-4B: 68.4% (+6.1 pp)
- OpenWebRL-4B-SFT: 52.0% vs OpenWebRL-4B: 68.4% (+16.4 pp) showing importance of RL
- OpenWebRL-8B: 68.7% vs OpenWebRL-4B: 68.4% (+0.3 pp), showing scaling effects
- Proprietary GPT-5 (SoM): 65.8% vs OpenWebRL-4B: 68.4%, OpenWebRL competitive with closed models
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.02031.

Fig 1: Performance comparison on online web benchmarks, including Online-Mind2Web (2025.04) [50],

Fig 2 (page 1).
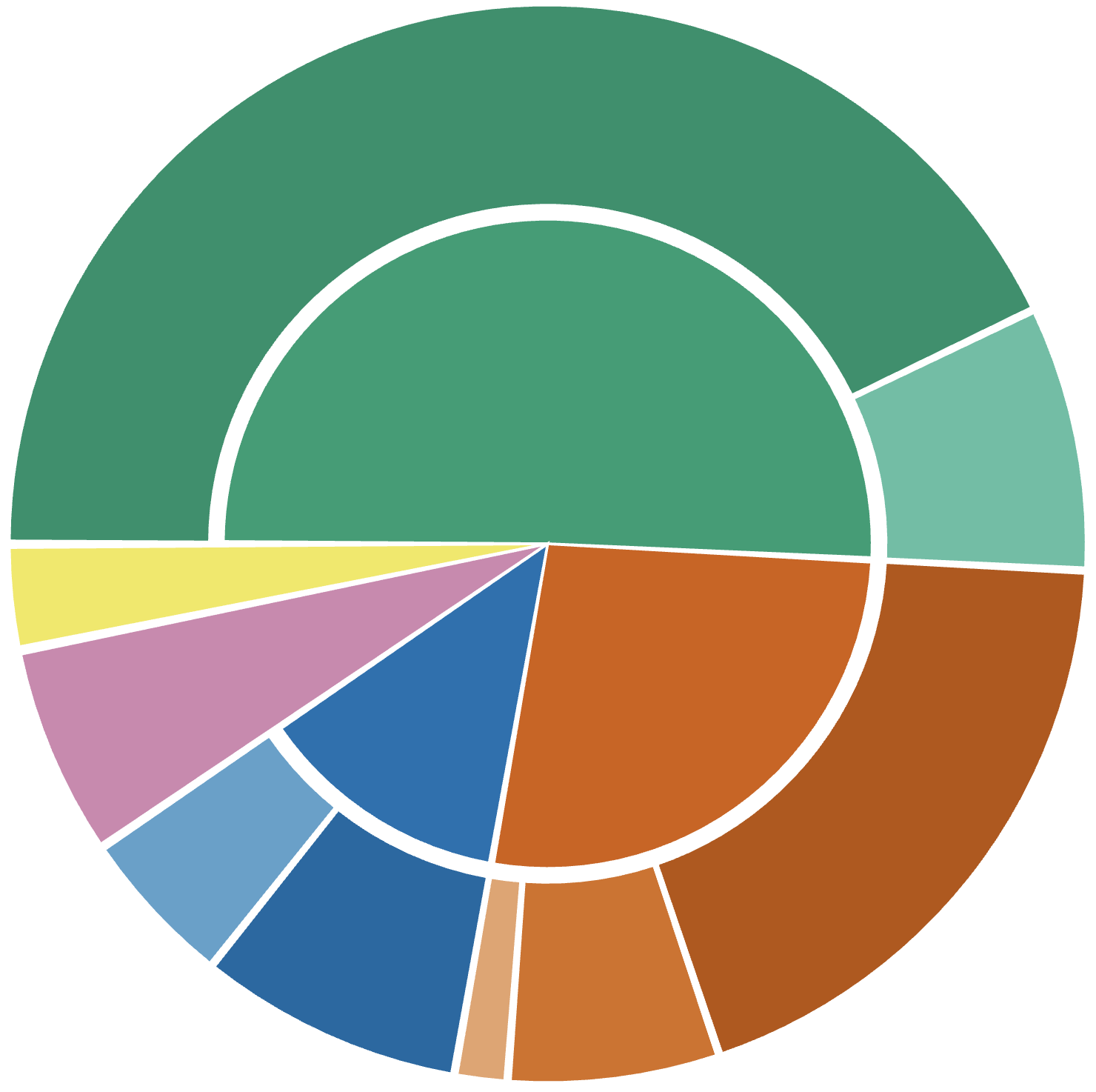
Fig 9: Distribution of failure modes based on a manual inspection of 100 failed trajectories.
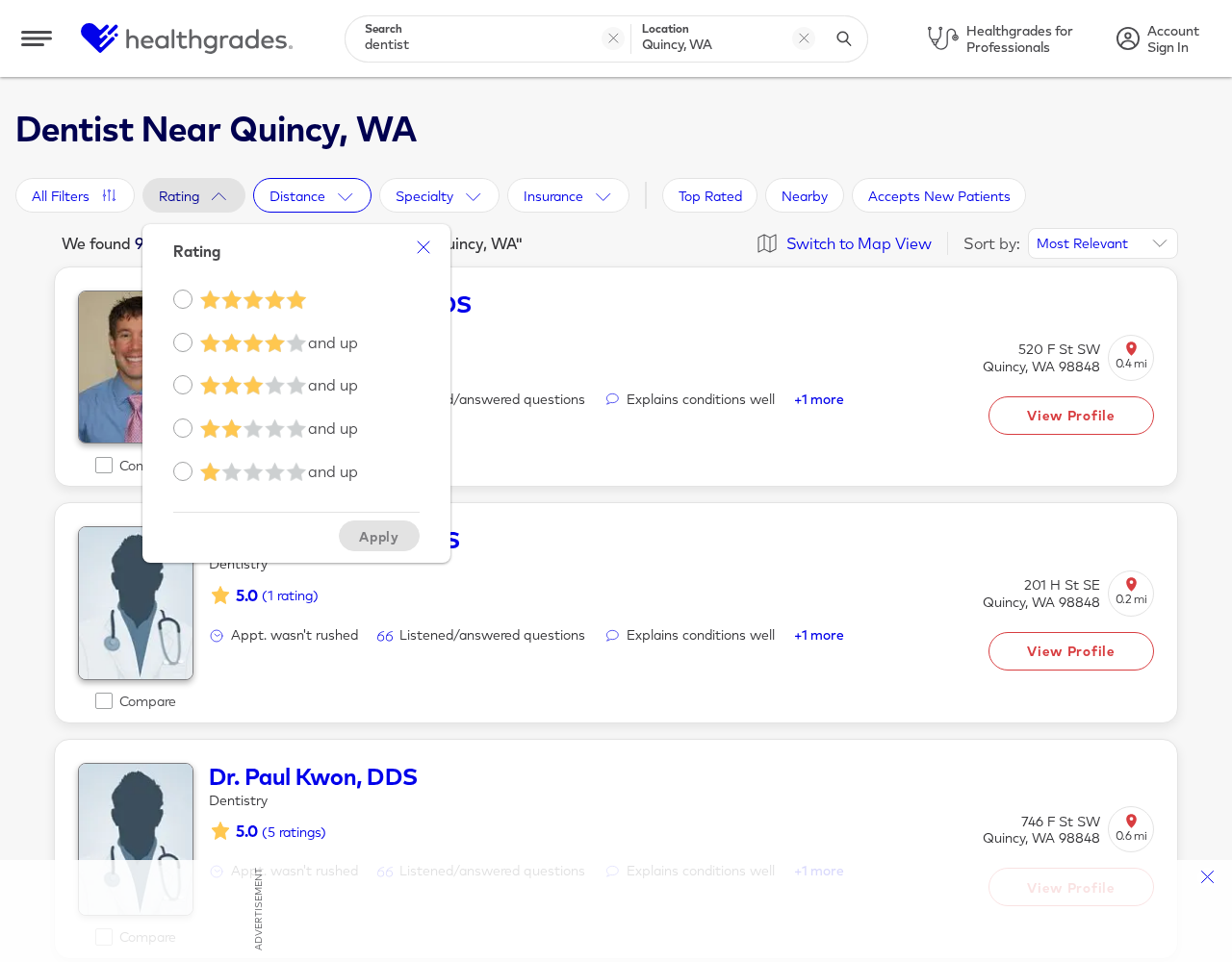
Fig 4 (page 30).

Fig 10: and Figure 11 show two representative long-horizon shopping tasks in which the agent must
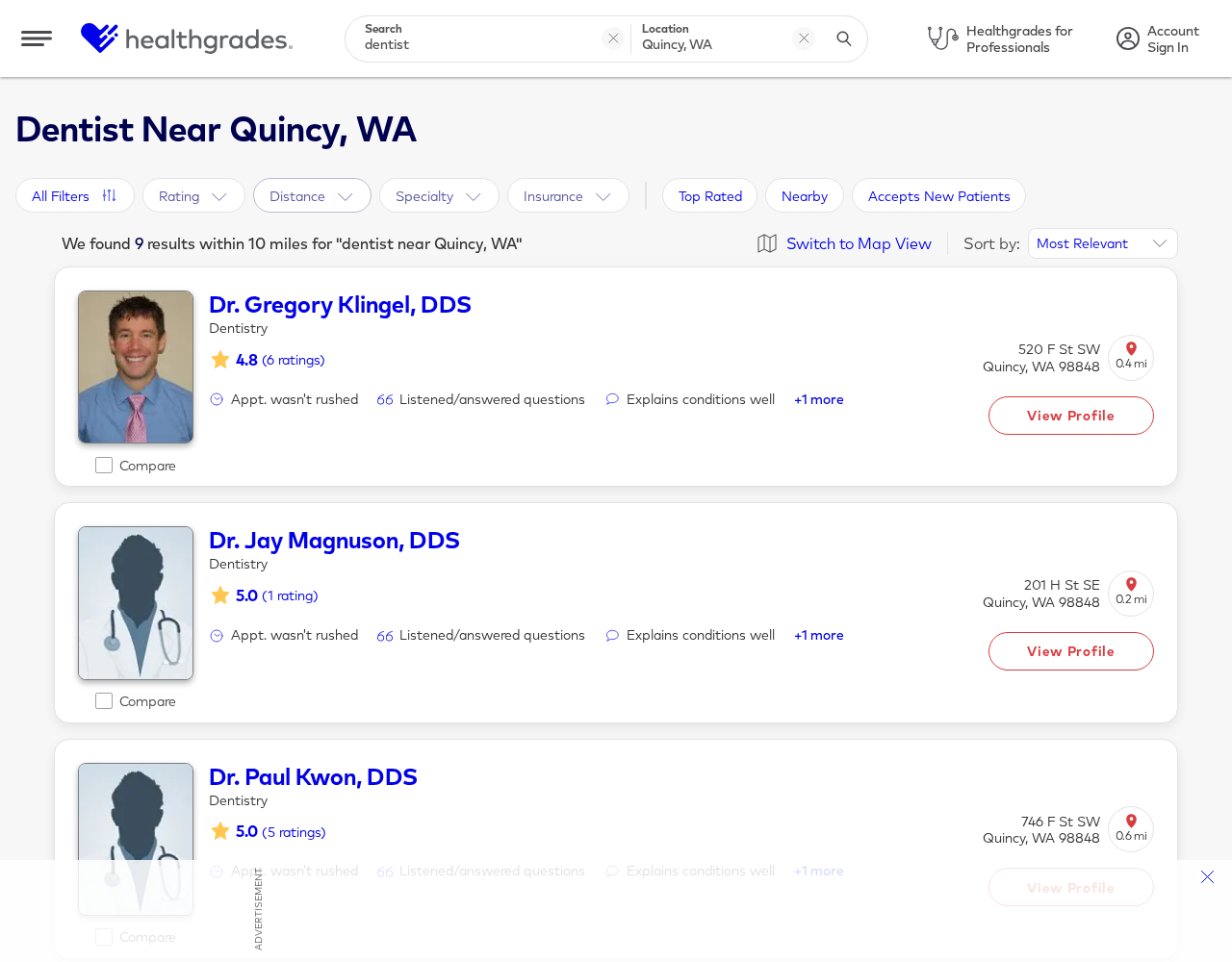
Fig 6 (page 33).
Fig 11: Trajectory Example: Add the cheapest black sofa with at least three seats, a leather finish, and at
Fig 8 (page 35).
Limitations
- Evaluation depends on third-party stealth browser infrastructure with CAPTCHA solving, limiting full reproducibility and carrying additional cost.
- The framework does not explicitly address adversarial manipulation or security threats on the web.
- Online RL training is computationally expensive (~300 A100 GPU days), which may be inaccessible for smaller teams.
- The approach focuses on relatively small (~4B-8B) VLMs and may not easily scale to much larger models without further engineering.
- Task diversity in the RL training pool is limited to 2.2K filtered tasks, which may not fully represent all real-world web scenarios.
- Analysis is primarily on success rate metrics; other behavioral or robustness metrics under diverse live-web conditions remain unreported.
Open questions / follow-ons
- How to further scale online RL training to larger VLMs and more diverse web tasks efficiently?
- Can agent robustness be improved against adversarial or purposely obfuscated web content beyond current environment noise?
- What methods can more effectively compress multimodal long-term memory to allow deeper multi-turn interactions?
- How does RL-driven adaptation generalize to unseen websites with drastically different layouts and interaction patterns?
Why it matters for bot defense
From a bot-defense and CAPTCHA perspective, OpenWebRL’s approach demonstrates that open-source visual web agents can be trained online to interact robustly and effectively with real websites, including those employing dynamic content and anti-bot measures. The multi-tool calling interface and environment feedback mechanisms enable fine-grained tracking of action success or failure, potentially including detection of CAPTCHA challenges or bot-blocking signals. The trajectory-level judge models provide a method to evaluate task success even amid noisy web conditions. Practitioners building CAPTCHA or bot defense systems can study this framework to understand how advanced RL-powered agents learn to circumvent typical web obstacles via multimodal reasoning and retry strategies. This knowledge can inform more adaptive and robust defense designs that anticipate such evolving agent capabilities. Conversely, integrating judge models like the distilled 8B judge might assist in automated detection of suspicious behavior by scoring interaction patterns.
Cite
@article{arxiv2606_02031,
title={ OpenWebRL: Demystifying Online Multi-turn Reinforcement Learning for Visual Web Agents },
author={ Rui Yang and Qianhui Wu and Yuxi Chen and Hao Bai and Wenlin Yao and Hao Cheng and Baolin Peng and Huan Zhang and Tong Zhang and Jianfeng Gao },
journal={arXiv preprint arXiv:2606.02031},
year={ 2026 },
url={https://arxiv.org/abs/2606.02031}
}