
Multi-Agent Computer Use
Source: arXiv:2606.01533 · Published 2026-06-01 · By Jing Yu Koh, Ruslan Salakhutdinov, Daniel Fried
TL;DR
This paper addresses the limitations of current computer use agents (CUAs), which typically operate as single serial agents executing tasks step-by-step. Such serial execution struggles with complex, long-horizon computer use tasks that benefit from task decomposition, parallel execution, and dynamic replanning. The authors introduce Multi-Agent Computer Use (MACU), a novel framework where a manager agent decomposes tasks into subtasks arranged in a directed acyclic graph (DAG). Parallel subagents execute subtasks on the ready frontier of the DAG, while the manager continually revises the DAG structure and subtask instructions based on new observations from subagents. This design explicitly handles the partial observability of computer environments by passing along preserved information between subtasks.
Empirically, MACU improves success rates by 3.4% to 25.5% across four diverse computer use benchmarks including OSWorld, Online-Mind2Web, WebTailBench, and Odysseys. Notably, on the Odysseys benchmark of long-horizon web navigation tasks, MACU also reduces wall-clock task time by about 1.5x through parallelism. The framework exhibits superior scaling with increased inference budget and solves complex tasks that stall single-agent CUAs. Ablations underline the critical importance of continuous replanning and parallel subagent execution. These results advocate for shifting beyond single-agent CUAs toward multi-agent coordination to enhance reliability, efficiency, and scalability on complex interactive tasks.
Key findings
- MACU improves success rate over single-agent CUAs by 4.7% on OSWorld, 3.4% on Online-Mind2Web, 8.7% on WebTailBench-v2, and 25.5% on Odysseys benchmarks (Tab. 1).
- MACU reduces median wall-clock time on Odysseys tasks from 162.4 to 110.3 minutes (~1.47x speedup) due to parallel subagent execution (Tab. 1).
- Increasing manager's replanning budget from 0 to 10 increases average success rate on OSWorld from 25.0% to 58.3%, showing the importance of continuous replanning (Tab. 2).
- MACU outperforms pass@8 single-agent baselines even though pass@8 has access to groundtruth evaluation, demonstrating more efficient use of inference budget (Fig. 4).
- Stronger CUA subagent models improve baseline and MACU performance, e.g., Qwen3.6-27B achieves 47.2% single-agent vs 66.7% MACU success rate (Tab. 3).
- Stronger manager models substantially improve MACU, with Opus 4.6 manager achieving 58.3% success vs 25.0% single-agent baseline using Qwen3.5-4B subagents (Tab. 4).
- Increasing maximum number of parallel subagents (N) from 1 to 4 on Odysseys reduces wall clock from 25.4 to 7.9 minutes and increases success rate from 53.3% to 60.4% (Fig. 5).
- MACU gains are largest on decomposable tasks needing parallel exploration, e.g. price_comparison tasks in WebTailBench improve from 3.7% to 33.9%, and improved success rates on easy & medium Odysseys tasks (Fig. 6, Tab. 5).
Threat model
Not applicable. The paper studies multi-agent coordination and planning for computer use agents rather than adversarial threat scenarios. The environment is partially observable, and the challenge is from incomplete information and task complexity rather than a hostile attacker.
Methodology — deep read
Threat Model & Assumptions: The adversary is not explicitly modeled since this is primarily about multi-agent systems in partially observable computer-use environments. The key challenge addressed is the partial observability of the system's state (filesystem, dynamic browser content, etc.) which downstream subagents cannot re-observe once a subtask completes. The manager must maintain and revise task decomposition continuously in this uncertain environment.
Data: Evaluations are conducted on four public benchmarks of computer use tasks - OSWorld (369 desktop Ubuntu tasks), Online-Mind2Web (300 web navigation tasks across 136 websites), WebTailBench-v2 (609 web navigation tasks emphasizing multi-step depth), and Odysseys (200 long-horizon web navigation tasks based on real human browsing). Success rate is measured either by execution-based scripts (OSWorld) or large language model (LLM) judges validating task completion (others). The datasets cover varied domains of computer use and span increasing task complexity.
Architecture / Algorithm: MACU consists of a single manager agent and multiple homogeneous CUA subagents sharing the same underlying model. The manager: a large language model (LLM) that takes in the task instruction, current DAG of subtasks, and observations from subagents to produce DAG edits and manage workflows. Subagents: automated computer use agents operating isolated virtual machines, executing ReAct-style loops (reasoning and action cycles) on assigned subtasks. The manager decomposes an overall task into a DAG where nodes represent subtasks with dependency edges. At each iteration, subagents are dispatched to ready nodes in parallel. After subtask completion, the manager updates the DAG based on new observations by adding, modifying, canceling subtasks, with a limited replanning budget B.
Training Regime: The paper focuses on LLM inference setups - subagent and manager models are off-the-shelf models called via APIs or locally hosted (Qwen3.6-27B as subagent, Opus 4.6 as manager). There is no finetuning or reinforcement learning reported. Hyperparameters such as max parallel subagents N=4, replanning budget B=10 are empirically chosen. Multiple manager and subagent LLMs of various sizes were evaluated in ablations.
Evaluation Protocol: Measured success rates and rubric scores computed by evaluators specific to each benchmark. Wall-clock task completion times are recorded to assess efficiency. Baselines include single-agent CUAs with repeated inference calls (pass@k) for performance comparisons. Ablations performed on manager model, subagent model size, replanning budget, and max parallelism N. Stratification by task difficulty and task type was analyzed. Statistical confidence procedures are not detailed.
Reproducibility: The authors release code and interactive visualizations online at https://jykoh.com/multi-agent-computer-use. The datasets are public benchmarks (OSWorld, Online-Mind2Web, WebTailBench, Odysseys). Exact models like Qwen3.6-27B and Opus 4.6 may be proprietary or API-based, likely limiting exact reproduction without access. Prompts and detailed experiment settings are in appendices.
One Example Run: On an Odysseys travel planning task, the manager decomposes the task into parallel subtasks such as hotel review and flight search, dispatching subagents to each. If a subtask is blocked or fails, the manager replans by retrying with alternate accommodations or flight queries. Successful subtasks are aggregated to produce a final itinerary recommendation. This multi-agent, iterative replanning approach contrasts with the single-agent baseline that executes serially and struggles with task branches or failures.
The methodology rigorously integrates planning, execution, observation, and dynamic replanning under partial observability via a flexible DAG structure to manage complex workflows efficiently.
Technical innovations
- Introducing a general multi-agent computer use framework that coordinates multiple CUA subagents via a dynamically evolving directed acyclic graph (DAG) for task decomposition and execution.
- Treating partial observability of computer use environments as a core challenge by explicitly retaining and propagating observations and states between subtasks through the manager’s DAG structure.
- Use of a single homogeneous subagent model running on isolated virtual machines with a separate manager LLM responsible for planning, decomposition, and dynamic replanning without specialized submodules.
- Continuous on-the-fly DAG mutation (adding, cancelling, rewriting subtasks) guided by observations from subagents, controlled by a replanning budget to balance exploration and stability.
- Demonstration that multi-agent coordination unlocks better test-time scaling and performance on complex, long-horizon computer use tasks vs. strong single-agent baselines.
Datasets
- OSWorld — 369 tasks — open research benchmark on Ubuntu desktop GUI tasks
- Online-Mind2Web — 300 tasks across 136 real websites — public benchmark
- WebTailBench-v2 — 609 tasks designed for web navigation complexity — public benchmark
- Odysseys — 200 long-horizon web navigation tasks based on real users — public benchmark
Baselines vs proposed
- Single-agent Qwen3.6-27B on OSWorld: Success rate 43.8%, median time 26.6 min vs MACU Opus 4.6 manager: 48.5%, 21.4 min
- Single-agent Qwen3.6-27B on Odysseys: Success rate 8.5%, median time 162.4 min vs MACU Opus 4.6 manager: 34.0%, 110.3 min
- Single-agent on WebTailBench-v2: 20.8% success vs MACU Opus 4.6: 29.5%
- Increasing replanning budget from 0 to 10 improves OSWorld success rate from 25.0% to 58.3%
- MACU success rate exceeds pass@8 repeated single-agent baseline across all actions executed up to 200 steps (Fig. 4)
- Using stronger manager models boosts MACU success: Opus 4.6 (58.3%) > Sonnet 4.6 (52.8%) > GPT-5.4 (44.4%) > single-agent baseline (25.0%)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.01533.
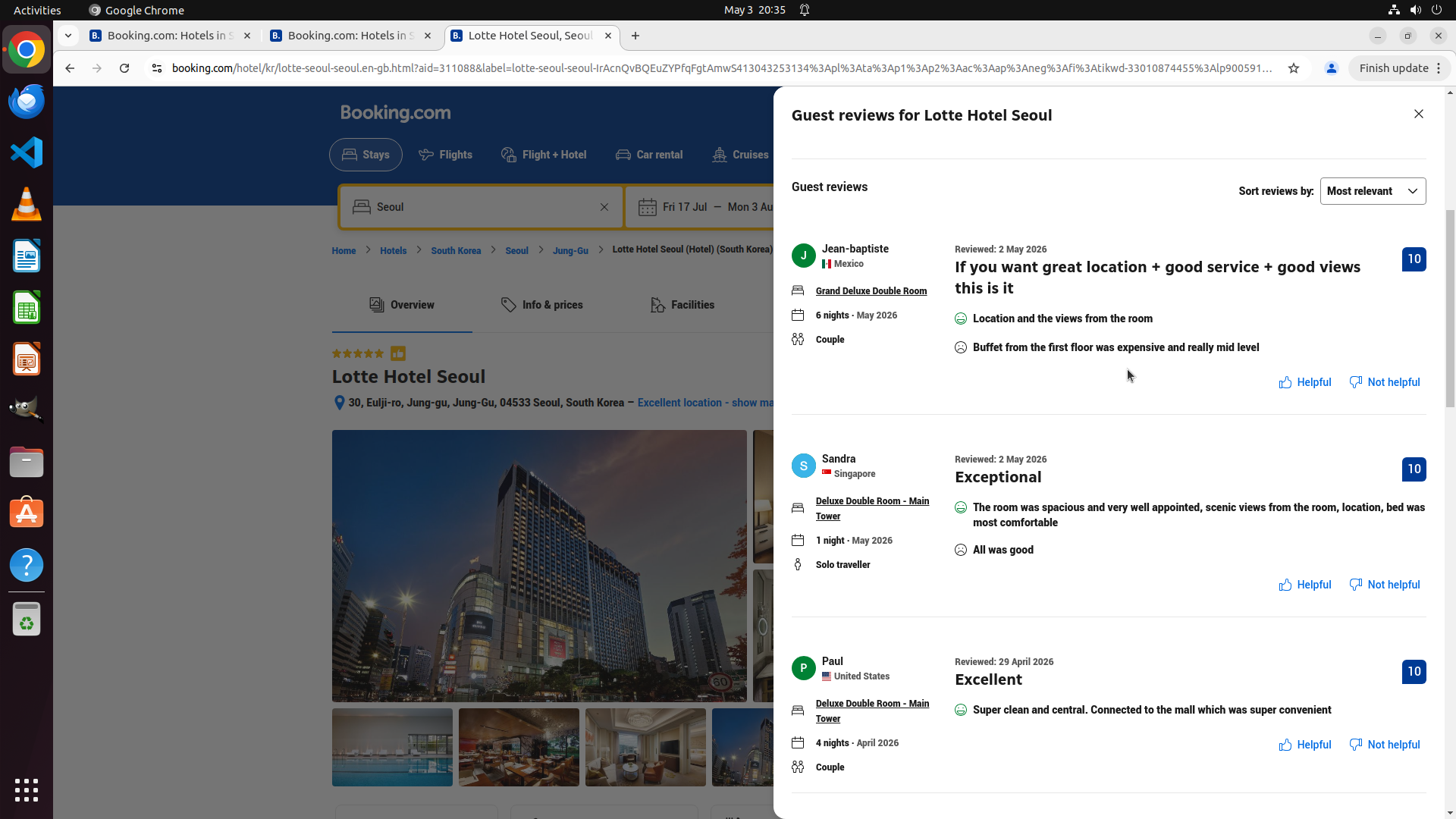
Fig 2: Example Odysseys travel planning task with MACU. The manager launches parallel hotel
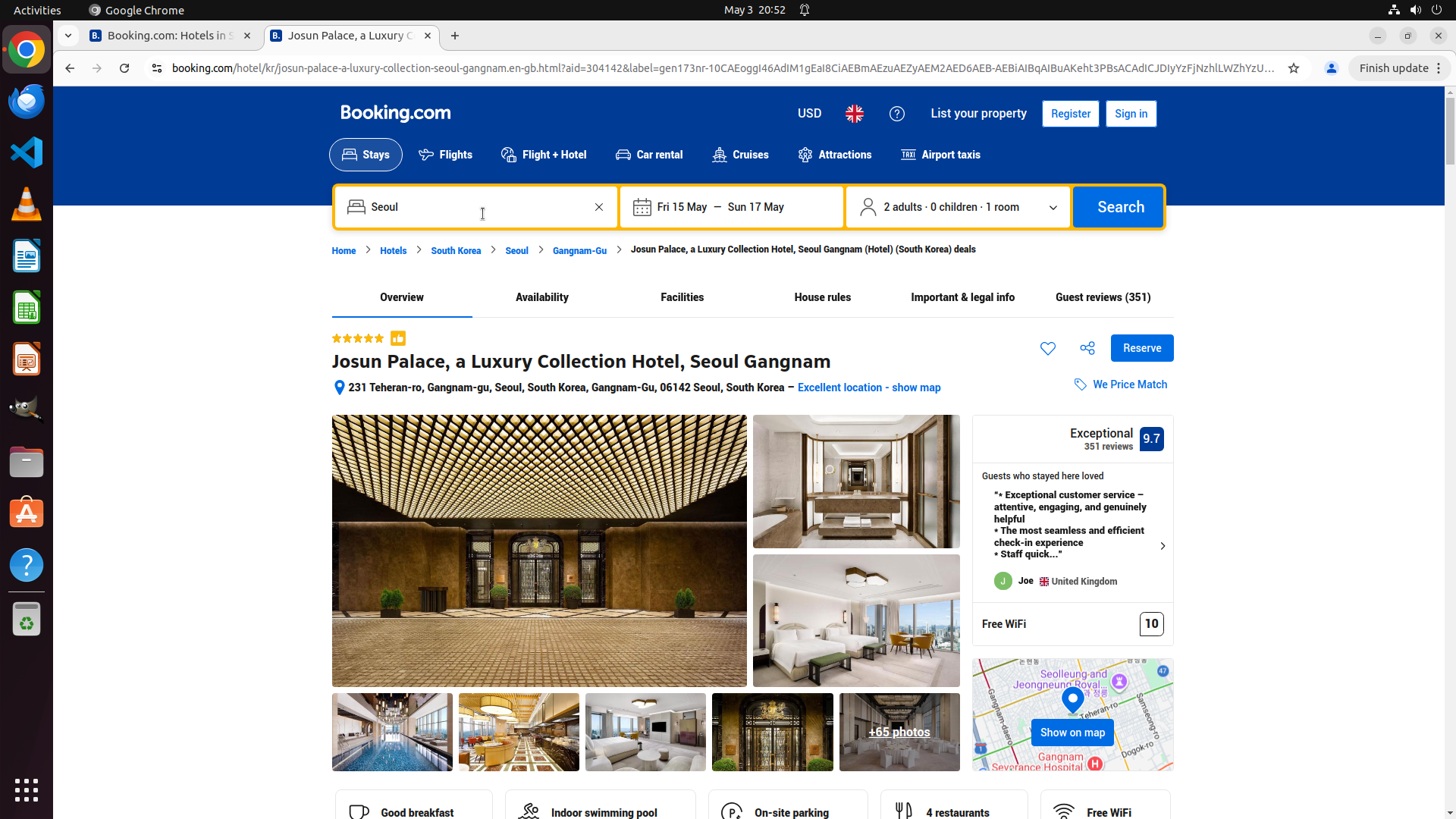
Fig 3: Success rate of MACU (Opus 4.6 manager) against number of CUA actions executed.
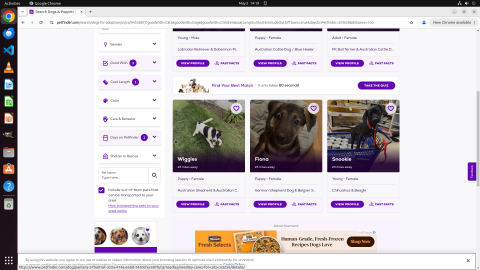
Fig 12: Example run for an Online-Mind2Web to find shorthaired dogs on Petfinder. The initial
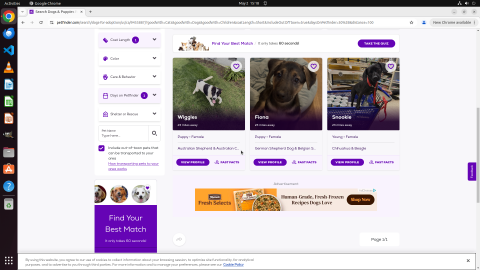
Fig 10: Example run for an OSWorld local-environment configuration task. The manager
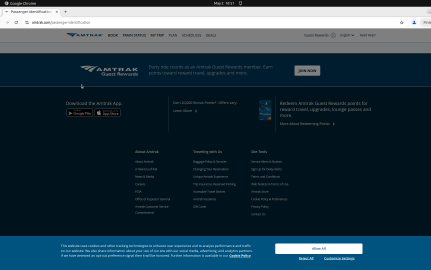
Fig 13: Example Online-Mind2Web run to find the identification required for boarding an Amtrak.
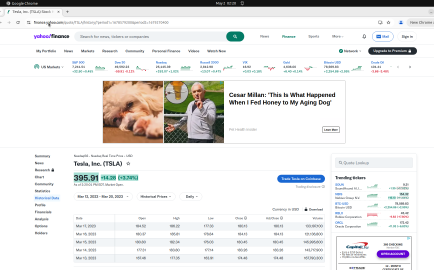
Fig 14: Example Online-Mind2Web task to find historical stock price. The initial Yahoo Finance
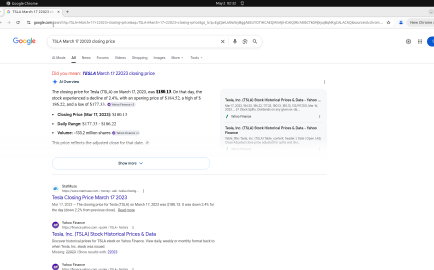
Fig 15: Example MACU run for an Odysseys law school outreach task. The manager initially
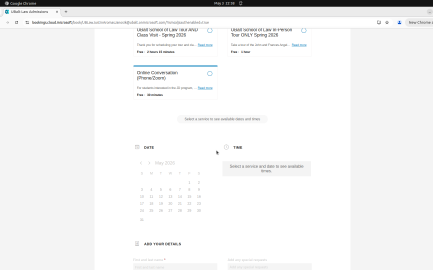
Fig 16: Example MACU run for an Odysseys brunch planning task. The manager decomposes
Limitations
- Evaluations rely on LLM-as-a-judge for some benchmarks, which can introduce biases in success measurement.
- Replanning budget and max parallelism hyperparameters are fixed and tuned but impact performance; not extensively optimized.
- System depends on availability and performance of large models (e.g., Opus 4.6, Qwen3.6-27B) which may be costly and have API limitations.
- No adversarial robustness or security evaluation demonstrating resilience to malicious inputs or environment perturbations.
- The framework currently uses off-the-shelf subagent and manager models with no finetuning or reinforcement learning to optimize multi-agent coordination.
- Some increase in wall-clock time observed on largely serial tasks (Online-Mind2Web) due to manager overhead.
- Limited analysis on error modes or failure cases where multi-agent decomposition is ineffective or causes overhead.
Open questions / follow-ons
- How can manager and subagent models be finetuned or jointly trained to improve coordination and task decomposition beyond prompt engineering?
- What are the trade-offs and optimal strategies for replanning budget and parallelism degree under resource constraints?
- How does the MACU approach perform under adversarial or noisy environments where observations are corrupted or incomplete?
- Can specialized subagents or hierarchical structures further improve efficiency compared to the homogeneous subagent setup?
Why it matters for bot defense
This work is highly relevant to bot-defense and CAPTCHA practitioners who seek scalable, robust automation systems interacting with complex GUI/web environments. MACU's multi-agent, dynamic decomposition and parallel execution approach offers a template to improve automation reliability and speed over traditional single-agent designs. Particularly for long-horizon, multi-step CAPTCHA challenges or layered bot interactions, multi-agent orchestration can reduce single points of failure and enable more flexible backtracking and retry strategies. The notion of encoding tasks as DAGs with dependencies and handling partial observability aligns with realistic web navigation and interaction scenarios bots often face. However, increased manager overhead and complexity in coordination may introduce latency or resource tradeoffs important for deployment at scale. Practitioners should consider MACU-inspired architectures to break down and parallelize complex interaction flows while managing state and observation persistence between subagents. Careful tuning of replanning budgets and parallelism could optimize throughput versus resource usage for CAPTCHA solver bots. Overall, this work opens promising avenues for architecting more sophisticated, scalable automation agents in adversarial or dynamic web environments common in bot defense.
Cite
@article{arxiv2606_01533,
title={ Multi-Agent Computer Use },
author={ Jing Yu Koh and Ruslan Salakhutdinov and Daniel Fried },
journal={arXiv preprint arXiv:2606.01533},
year={ 2026 },
url={https://arxiv.org/abs/2606.01533}
}