
MMG2Skill: Can Agents Distill In-the-Wild Guides into Self-Evolving Skills?
Source: arXiv:2606.01993 · Published 2026-06-01 · By Xinyu Che, Junqi Xiong, Yunfei Ge, Xinping Lei, Shihao Li, Hang Yan et al.
TL;DR
This paper addresses the challenge of enabling vision-language model (VLM) agents to convert in-the-wild, human-authored multimodal procedural guides into executable and editable skills that improve agent performance on long-horizon tasks across diverse interactive environments. The authors formalize this as guide-to-skill learning, where agents distill noisy, heterogeneous web guides into structured skill representations which they then revise using trajectory-level root-cause analysis derived solely from agent-visible rollouts, without relying on external benchmark scores. To support research in this area, they introduce MMG2Skill-Bench, a new benchmark covering 130 success-inferable tasks split across three domains: desktop GUI control (OSWorld), open-ended gameplay (Minecraft OpenHA), and strategic card play (Doudizhu and Mahjong). Building upon this, they propose MMG2Skill, a closed-loop system that constructs editable skills from multimodal guides, injects skills as conditioning context for a fixed VLM agent during rollout, analyzes failures through an agent-visible trajectory analyzer, and iteratively refines the skills to improve performance.
Empirically, MMG2Skill yields consistent improvements over vanilla agents and naive raw-guide prompting baselines, with macro-average gains of +12.8 to +25.3 percentage points across six different VLM backbones and all domains. Ablations confirm that both structured skill construction and iterative trajectory-driven skill revision are essential for these gains, and that raw guide prompting often degrades performance. Analyzer-based early stopping further improves deployment by preventing late-stage regressions and saving 25%-53% of attempts when the success signal is well calibrated. Diagnostics highlight domain-specific bottlenecks: execution fragility in games, complex decision-rule conversion in strategy, and mixed failures in GUI. Overall, MMG2Skill demonstrates the feasibility and value of distilling uncurated public procedural knowledge into self-evolving agent skills without ground-truth reward feedback.
Key findings
- MMG2Skill outperforms vanilla baselines in every model-domain setting on MMG2Skill-Bench, with average gains of +12.8 to +25.3 percentage points across six VLM backbones.
- Raw guide prompting without skill extraction or revision can degrade performance, especially on Game and Strategy domains (-1.67 pp or worse).
- Structured skill construction alone matches or modestly exceeds vanilla on GUI (e.g., +8.34 pp) but contributes <10% of gains on Game and Strategy, where revision provides over 90% of the improvement.
- Trajectory-driven skill revision repairs guide-runtime mismatches such as missing runtime checks or recovery conditions, allowing MMG2Skill to recover from initial rollout failures.
- Analyzer-based early stopping achieves high precision (>74%) and recall (>95% on GUI and Game) on success-inferable tasks and saves 25%-53% of rollout attempts relative to full-run deployment.
- Revision gains are non-monotonic, with some late attempts degrading due to ambiguous analyzer signals, underscoring the need for calibrated stopping.
- Residual failures differ by domain: GUI errors split between grounding, diagnosis, and skill info; Game errors dominated by execution fragility; Strategy errors primarily from suboptimal decision-rule conversion and skill-not-followed cases.
- MMG2Skill’s closed-loop revisions outperform in-context root-cause feedback incorporated as history, showing persistent skill edits better capture corrections.
Threat model
The adversary is environmental complexity manifesting as uncertain or ambiguous alignment between in-the-wild human-authored procedural guides and the agent's runtime context. No access to oracle reward signals or ground-truth task scores is assumed; the agent only observes its own trajectory. The adversary cannot directly manipulate the agent’s internal policy, nor is external guidance or privileged knowledge available during skill revision.
Methodology — deep read
Threat model & assumptions: The adversary is the environmental complexity and mismatch between in-the-wild procedural guides and agent runtime states that can cause incorrect or incomplete execution. The agent does not update its VLM policy parameters; instead, all improvements come from compiling and revising an explicit skill set derived from public guides. Benchmark scores or ground-truth label feedback are not accessible during revision. The agent only observes its own trajectory during execution.
Data: MMG2Skill-Bench includes 130 success-inferable tasks paired with publicly available multimodal (HTML+image) procedural guides from three domains: OSWorld desktop GUI control with product manuals and how-tos; OpenHA Minecraft tasks with wiki and walkthrough-style pages; and RLCard Doudizhu and Mahjong card game tasks with public rules and beginner strategy materials. Task outcomes can be inferred from agent-visible trajectories or public final states to enable analyzer-based revision without oracle access.
Architecture / algorithm: MMG2Skill builds an explicit editable skill set S from the guide G, where each skill is a tuple including procedure text, applicability conditions, expected state cues, and recovery advice organized into a SKILL.md format. The fixed VLM policy πθ is conditioned on the skill set alongside usual observation-action history during rollout. After executing an attempt producing a trajectory τk, an analyzer module inspects the visible trajectory plus task instruction to produce a root-cause diagnosis ρk indicating what succeeded or failed without using benchmark labels. A refiner then integrates accumulated diagnoses ρ1:k, the original guide, and current skill set Sk to produce a skill edit yielding Sk+1 for the next attempt. This closed loop iterates up to an attempt budget N or until success is detected.
Training regime: The VLM policy πθ remains frozen; improvements come entirely from skill construction and revision. Attempt budget N is generally set to 5, with some experiments pushing to 7. Analyzer and refiner are implemented as in-context learners over the agent-visible trajectory and accumulated diagnoses. No gradient-based policy training is involved.
Evaluation protocol: The main metric is task success rate scored natively by domain evaluators (scaled 0-100%). Comparisons are made across vanilla agent, raw guide prompting baseline, skill construction only (one-shot), and full MMG2Skill closed loop. Early stopping based on analyzer likely_success signals is evaluated against full-run attempts. Ablations examine mechanism contributions, revision dynamics, and residual failure modes across domains and backbones. Code and benchmark dataset are publicly released for reproducibility.
Reproducibility: The MMG2Skill code and benchmark datasets are released at https://github.com/NJU-LINK/MMG2Skill. Multiple VLM backbones, hyperparameters, and detailed appendices support replicability. However, some domain environments are partly research platforms, with occasional closed data components for opponent hands in Hold’em excluded from primary evaluation.
Concrete example: For a GUI task like cropping an image in GIMP, the raw guide instructs standard steps which the agent initially follows but misses a critical output-file verification check. After a failed rollout, the analyzer detects the discrepancy and the refiner inserts this check into the skill. Subsequent rollouts succeed due to the revised skill containing missing runtime conditions. This illustrates how guide-derived skills are progressively grounded and refined by trajectory diagnosis without ground-truth labels.
Technical innovations
- Formalizing guide-to-skill learning as distilling noisy, human-authored multimodal procedural guides into editable agent-executable skills revisable from agent-visible trajectories.
- Designing MMG2Skill-Bench, the first benchmark pairing in-the-wild multimodal guides with success-inferable interactive tasks across GUI, open-world game, and strategy card domains.
- Developing MMG2Skill, a closed-loop framework that constructs skill sets from guides, conditions fixed VLM agents on these skills, analyzes rollout failures without ground-truth scores, and iteratively refines skills via root-cause trajectory diagnosis.
- Demonstrating that raw guide prompting can hurt performance, while structured skill construction plus trajectory-driven revision yields consistent +12.8 to +25.3 pp gains over multiple VLM backbones.
- Introducing analyzer-based early stopping triggered by success-inferable outcome signals that saves 25%-53% of attempts and prevents late-stage performance regressions during deployment.
Datasets
- MMG2Skill-Bench — 130 success-inferable tasks — assembled from public multimodal guides and interactive environments: OSWorld GUI, Minecraft OpenHA Game, RLCard Strategy tasks
Baselines vs proposed
- Vanilla baseline: GUI average score = 42.74% vs MMG2Skill = 55.67%
- Raw Guide injection: Game average score = 42.22% vs MMG2Skill = 66.11%
- Skill extraction without revision: Strategy average score = 47.92% vs MMG2Skill = 61.67%
- Analyzer early-stop saves 25%-53% of attempts compared to full-run with precision >74% and recall >95% on success-inferable tasks
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.01993.

Fig 1: Motivation and high-level finding of MMG2Skill-Bench and MMG2Skill. Public multimodal

Fig 2: MMG2Skill-Bench composition. Task-

Fig 3: MMG2Skill framework. The figure shows the closed-loop pipeline that constructs guide-

Fig 4 (page 2).
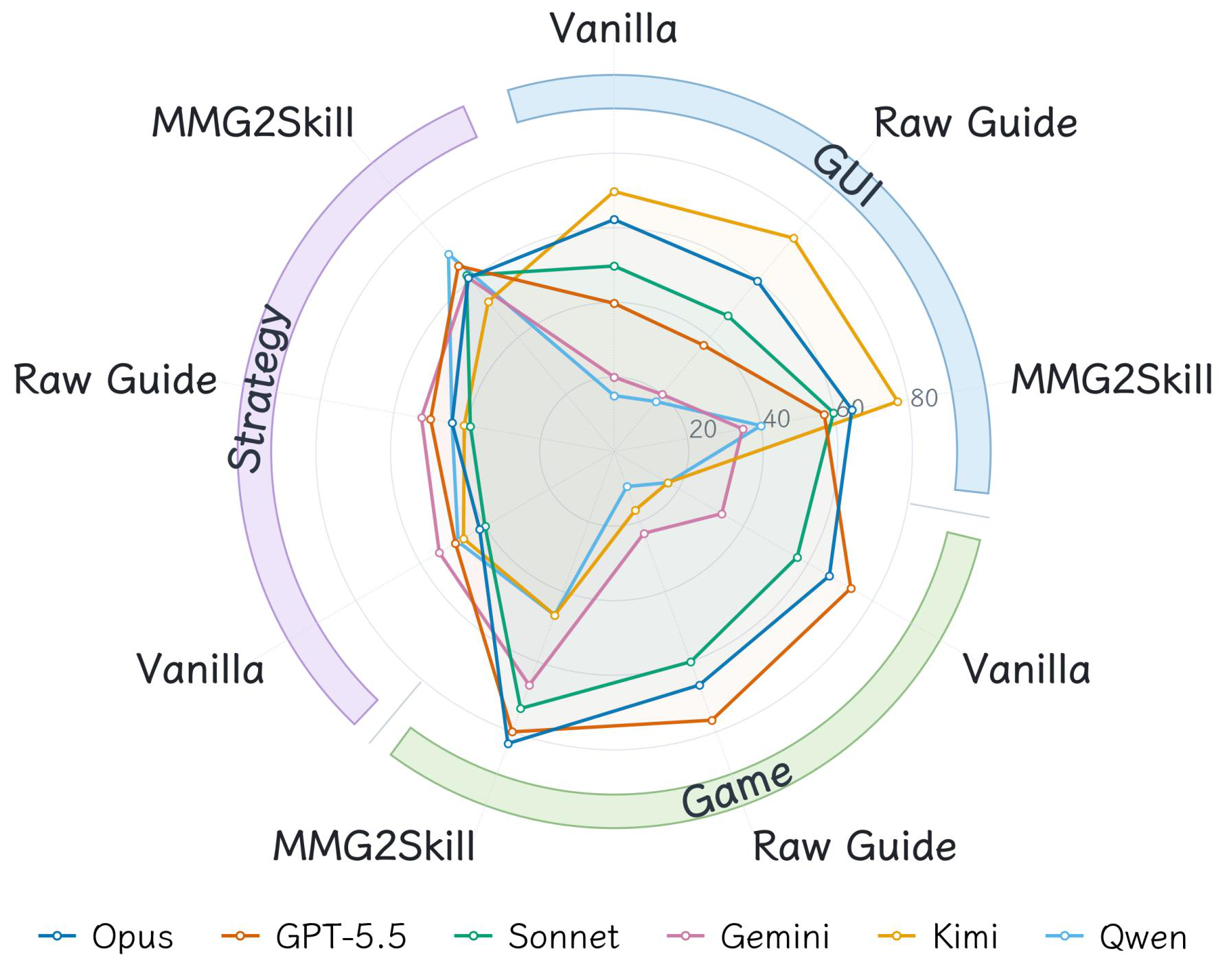
Fig 5 (page 2).

Fig 6 (page 4).

Fig 7 (page 4).

Fig 8 (page 4).
Limitations
- Does not address guide discovery, filtering, or selection upstream of skill construction; assumes task-relevant guides are provided.
- Trajectory diagnosis relies on task outcomes inferable from agent-visible observations; private information domains like Hold’em require separate handling.
- Revision gains exhibit non-monotonic dynamics; analyzer misclassification can cause late-stage regressions.
- Residual failures remain substantial and differ by domain, reflecting challenging grounding, execution, and decision-rule conversion bottlenecks.
- Fixed frozen VLM policy limits adaptability; all improvements come from skill edits, not policy fine-tuning.
- Some domain environments (e.g., opponents in Hold’em) contain private or unreleased data restricting full evaluation reproducibility.
Open questions / follow-ons
- How can agents efficiently search, filter, and select relevant in-the-wild guides when multiple candidate sources are available?
- Can skill construction and revision incorporate learning or fine-tuning of the agent policy parameters jointly with skill updates?
- How robust is MMG2Skill under distribution shifts, noisy or contradictory guides, or adversarial procedural instructions?
- Can the approach extend to private-information or imperfect-observation games where success signals are not visible from trajectories alone?
Why it matters for bot defense
This work reveals that simply providing agents with large-scale human procedural knowledge in raw form is insufficient and potentially detrimental, motivating design of intermediate, editable procedural abstractions for grounded interaction tasks. For bot-defense and CAPTCHA applications, the concept of distilling noisy human-readable guidance into structured, executable skills that agents can revise by observing their own executions offers a promising pathway for robust, adaptable agent behaviors under minimal supervision. The closed-loop refinement approach using trajectory diagnosis without external labels is particularly relevant where direct reward signals or success detection are unavailable or expensive, as in scalable CAPTCHA solving or stealthy bot activity detection. However, the limitations in skill discovery and variable revision reliability highlight that incorporating robust guide filtering and outcome inference mechanisms is vital for real-world deployments.
Cite
@article{arxiv2606_01993,
title={ MMG2Skill: Can Agents Distill In-the-Wild Guides into Self-Evolving Skills? },
author={ Xinyu Che and Junqi Xiong and Yunfei Ge and Xinping Lei and Shihao Li and Hang Yan and Han Li and Yuanxing Zhang and Zhiqi Bai and Jinhua Hao and Ming Sun and Han Li and Jiaheng Liu },
journal={arXiv preprint arXiv:2606.01993},
year={ 2026 },
url={https://arxiv.org/abs/2606.01993}
}