
Improving Combined Detection and Classification of TEM Defects via Mask-Conditioned Latent Diffusion Augmentation
Source: arXiv:2606.02532 · Published 2026-06-01 · By Ni Li, Nuohao Liu, Ryan Jacobs, Ajay Annamareddy, Maciej P. Polak, Kevin Field et al.
TL;DR
This paper addresses the challenge of limited labeled data for detecting and classifying irradiation-induced defects in transmission electron microscopy (TEM) images of metal alloys. The authors propose a data augmentation technique using a mask-conditioned latent diffusion model (LDM) to synthesize realistic TEM images paired with automatically generated multi-class defect masks. These synthetic datasets mimic the statistical distributions of defect shapes, sizes, and orientations derived from expert-labeled experimental masks. By augmenting small experimental datasets (10, 50, 100 images) with these synthetic image-mask pairs, they train Mask R-CNN models to improve defect detection and classification.
Results demonstrate modest but consistent performance improvements when using generated data, with up to a 0.02 increase in the harmonic mean of detection and classification F1 scores (F1HM). Gains depend on the size of the experimental training set and the specific data split. Improvements primarily come from either detection or classification depending on the train/test partition, highlighting the sensitivity of augmentation effects. While improvements are small (3-8% of the possible F1HM gain), the study shows the potential utility of mask-conditioned LDMs for microscopy image augmentation in low-data regimes, especially when acquiring new experimental data is expensive.
Key findings
- Mask-conditioned latent diffusion model (LDM) can generate realistic TEM images conditioned on simulated segmentation masks without manual annotations.
- Augmenting Mask R-CNN training data with 10,000 generated image-mask pairs yields up to 0.02 gain in the harmonic mean of detection and classification F1 scores (F1HM).
- Performance gains are statistically significant for training sets of 50 images (p=0.0008) and 100 images (p=0.0013), but not conclusive for 10 images (p=0.069).
- Improvement magnitude depends on train/test split: one split shows gains mainly in classification F1, another in detection F1.
- Generated image quality improves with increasing number of real training images used to train the LDM, with sharper features and more realistic defect morphology seen at 50 and 100 images.
- Simply oversampling underrepresented defect classes using LDM-generated data did not yield measurable performance improvements, indicating limits in addressing class imbalance with current approach.
- Optimal inference confidence threshold for Mask R-CNN model shifts lower (0.6-0.7) when trained with augmented data compared to baseline (around 0.8).
- Approximately 10,000 data patches were generated per training condition through sliding window cropping and standard augmentations for both real and generated images.
Methodology — deep read
Threat Model & Assumptions: The adversary scenario is not explicitly security-related, but the work addresses the challenge of limited labeled TEM microscopy data for automated defect detection and classification. The assumption is that high-quality experimental data with expert annotations is scarce and costly, motivating synthetic data augmentation.
Data: The study uses a publicly available STEM dataset of irradiated FeCrAl alloys with expert-annotated segmentation masks for three defect types: ⟨100⟩ loops, ⟨111⟩ loops, and black dots. Images are 1024×1024 pixels, and the dataset was split into training subsets of 10, 50, and 100 images (excluding 22 images reserved for testing). Masks were analyzed to extract distributions of defect count, size (ellipse major/minor axes), orientation, and types.
Architecture / Algorithm: The core generative model is a mask-conditioned latent diffusion model (LDM) consisting of a pretrained VQGAN autoencoder and a U-Net denoiser trained from scratch on STEM images conditioned on segmentation masks. The masks encode pixel-wise defect class labels, allowing controllable image synthesis.
Mask simulation generates novel segmentation masks by sampling from empirical distributions of defect statistics extracted from the experimental masks. The LDM is then conditioned on these synthetic masks to generate matching STEM images, producing paired synthetic datasets.
Baseline detection/classification models are Mask R-CNN networks trained on either just experimental data (EXP) or a combination of experimental plus equal-sized synthetic data (EXP+GEN).
Training Regime: Experimental images and masks were cropped by sliding window into 256×256 pixel patches with four rotations and flips, yielding approximately 10,000 patches per training condition. The LDM was trained until convergence (~7 GPU hours on NVIDIA V100), with around 15 GPU hours total for training and generating 10,000 synthetic images. Mask R-CNN models were trained for 100,000 iterations with identical hyperparameters on both EXP and EXP+GEN sets.
Evaluation Protocol: Performance was measured on 22 experimental test images cropped into patches. Metrics include detection F1 score, classification F1 score, and their harmonic mean (F1HM). Optimal confidence thresholds were selected per model. Four independent runs were performed per condition to capture variance. Statistical significance was assessed with paired t-tests on Split 1 runs. Two distinct train/test data splits were used.
Reproducibility: The study reuses a public STEM dataset indexed by Jacobs et al., and code for LDM and Mask R-CNN training and mask sampling are made available on Figureshare with GitHub links. However, final trained weights are not explicitly mentioned as released. The dataset's expert mask annotations remain unchanged; no new manual labeling was needed.
End-to-End Example: For instance, at the 50-image training size, defect masks were analyzed for statistics used to randomly generate new synthetic masks. These synthetic masks conditioned the LDM to produce realistic STEM images. The 10,000 synthetic patches were combined with the 10,000 real patches from the 50 experimental images. Mask R-CNN was trained on this combined dataset and evaluated on held-out test data, showing a statistically significant 0.02 increase in F1HM score compared to training with only experimental data.
Technical innovations
- Use of mask-conditioned latent diffusion models to generate fully labeled synthetic TEM image–mask pairs without manual annotation in the generation loop.
- Sampling of synthetic multi-class defect masks from statistical distributions of real experimental annotations to drive controllable synthetic image synthesis.
- Integration of generative data augmentation with instance segmentation Mask R-CNN frameworks for combined defect detection and classification in low-data microscopy regimes.
- Demonstration that the relative benefit of augmentation stems either from improved detection or classification depending on the train/test data split, revealing sensitivity to dataset partitioning.
Datasets
- FeCrAl STEM irradiated alloy dataset — ~150 images total (splits of 10, 50, 100 for training + 22 test images) — public (https://doi.org/10.6084/m9.figshare.27281400.v1)
Baselines vs proposed
- Mask R-CNN trained on experimental data only (EXP) with 50 images: F1HM ~0.70-0.75
- Mask R-CNN trained on experimental + generated data (EXP+GEN) with 50 images: up to +0.02 improvement in F1HM over EXP alone
- Statistical significance (paired t-test) for 50 images: p=0.0008; for 100 images: p=0.0013; for 10 images: p=0.069 (not conclusive)
- EXP+GEN model shows optimal confidence threshold around 0.6-0.7, whereas EXP model at ~0.8
- Gains vary across train/test splits: Split 1 shows classification improvements; Split 2 shows detection improvements
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.02532.
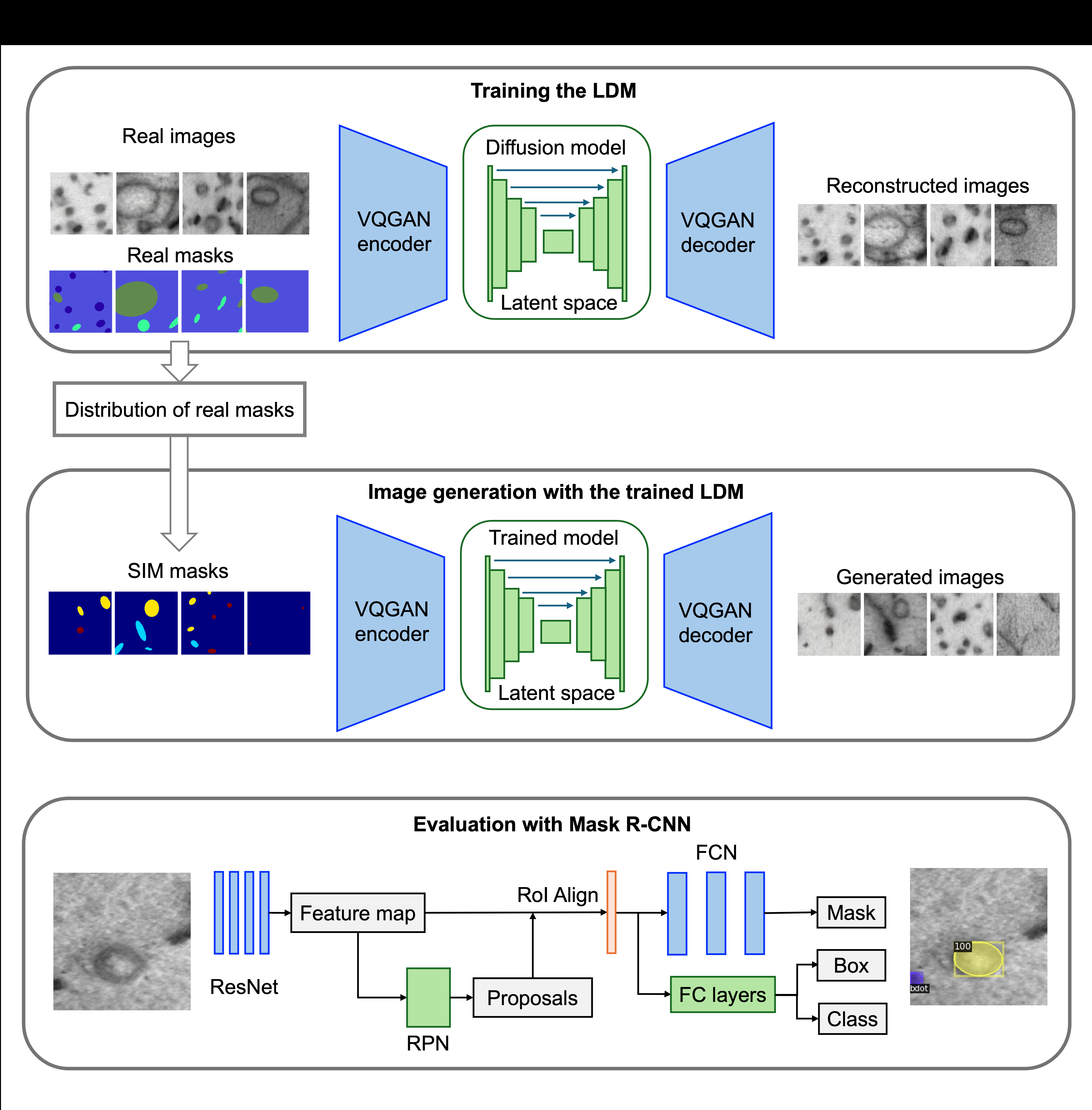
Fig 1: Mask-conditioned latent diffusion pipeline for STEM image generation. Simulated (SIM) masks are sampled
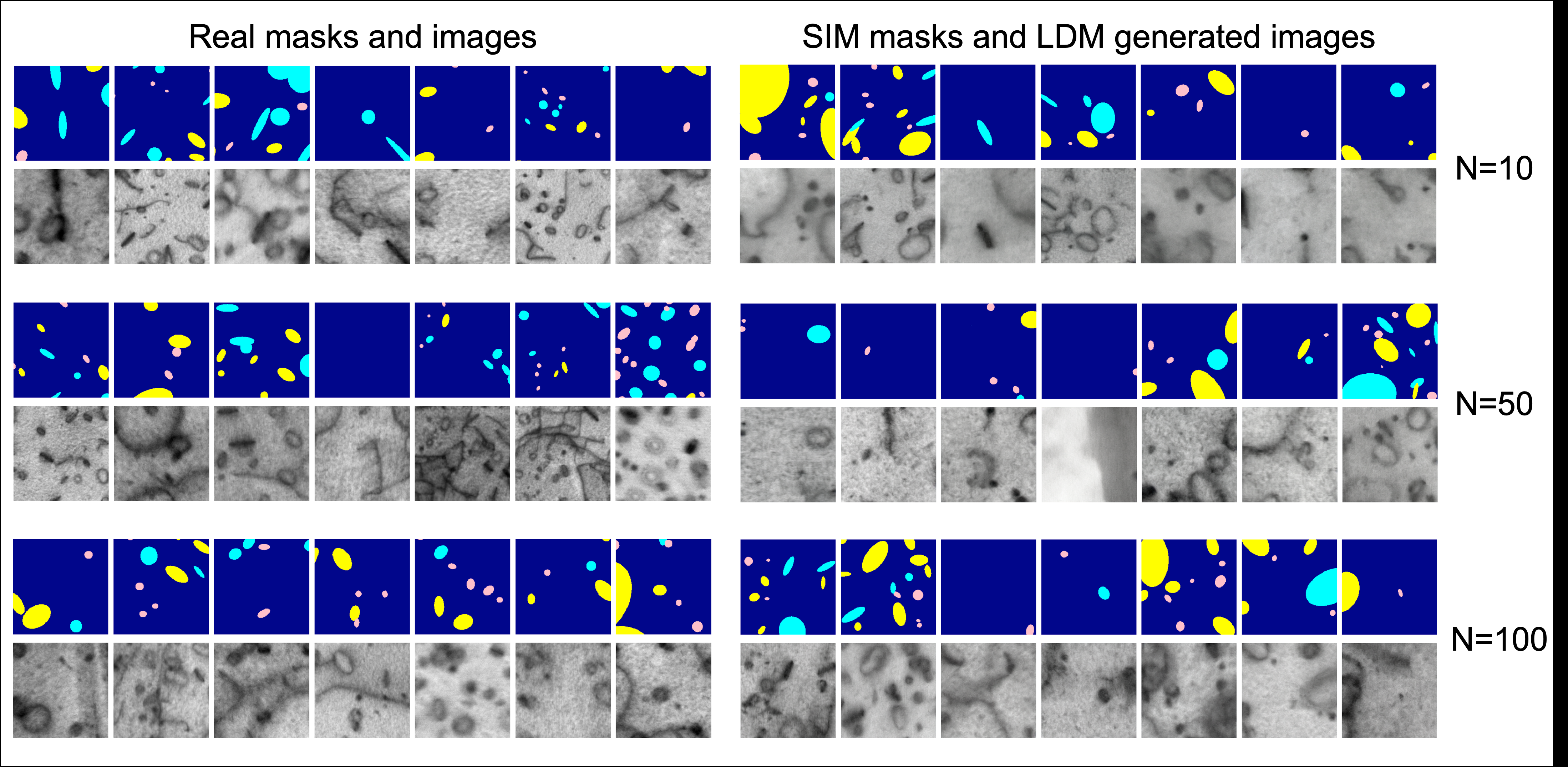
Fig 2: Visual comparison between real (left) and generated data (right). Left: Real segmentation masks and
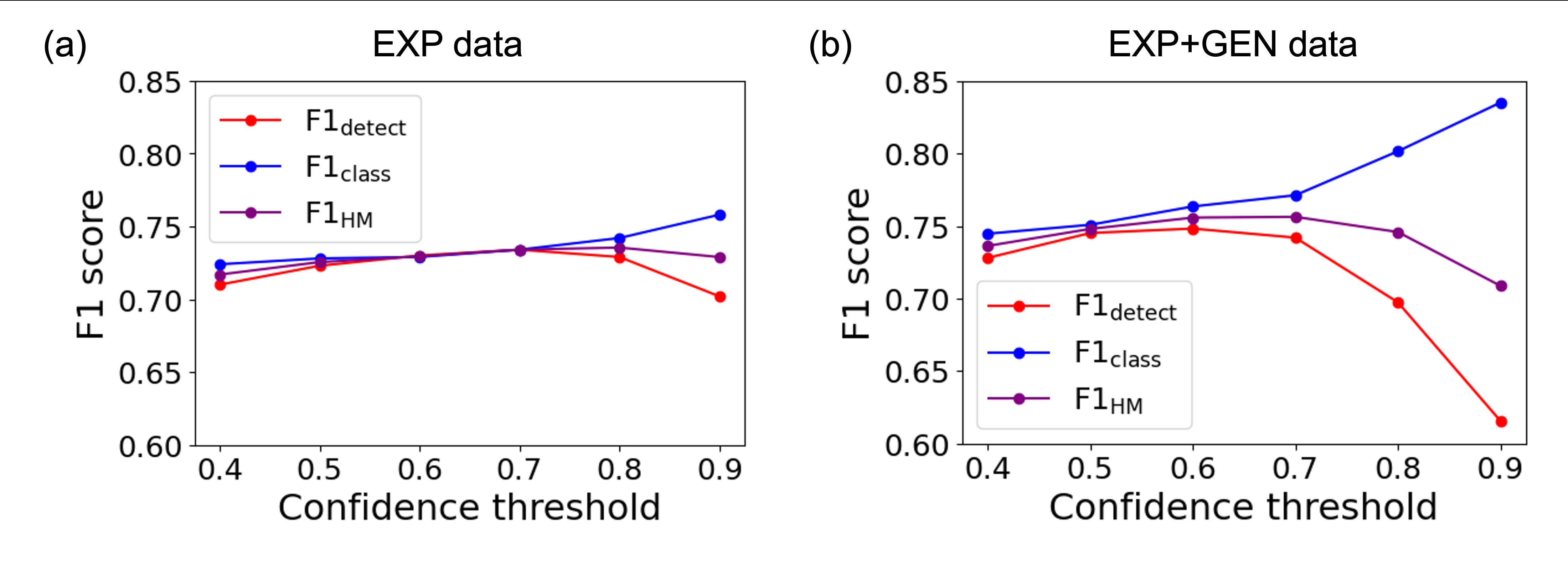
Fig 3: Detection F1, classification F1, and harmonic F1 scores as functions of confidence threshold for Mask R-CNN
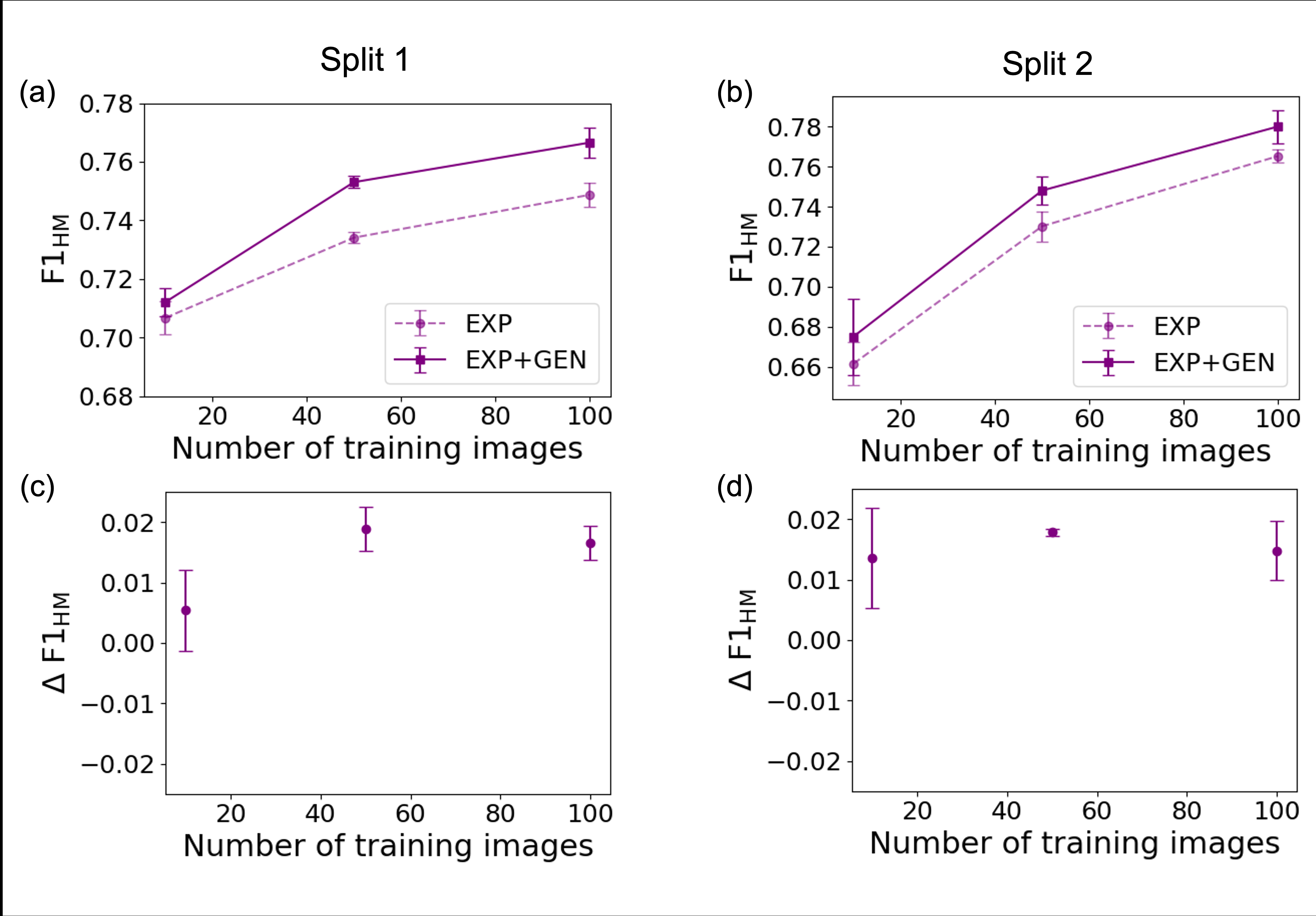
Fig 4: Comparison of Mask R-CNN performance across two train/test splits (Split 1 and Split 2). Panels (a) and
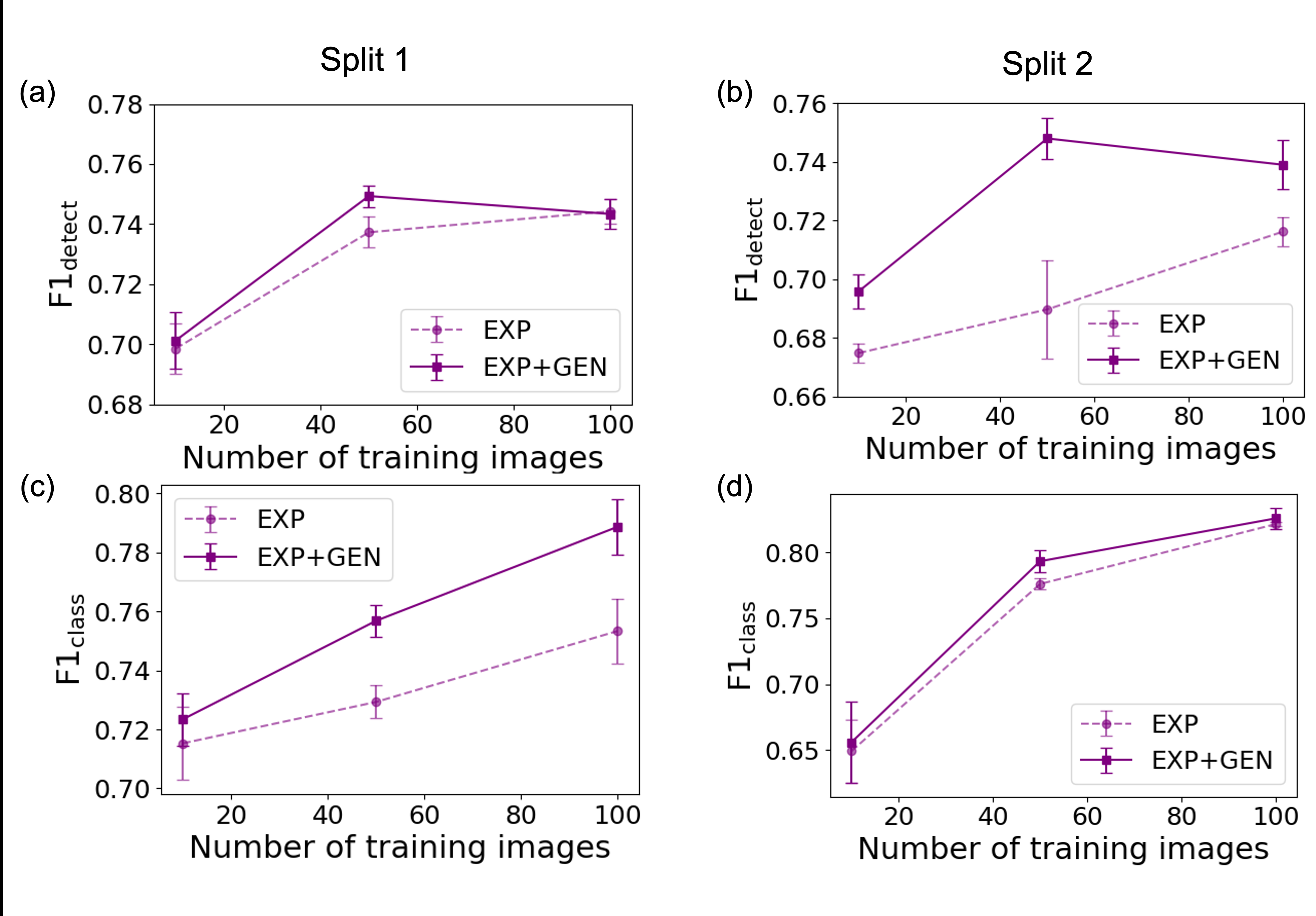
Fig 5: Detection and classification performance of Mask R-CNN models trained on experimental (EXP) data alone
Limitations
- Modest magnitude of performance improvement (3-8% of possible F1HM gain), small absolute gain (~0.02 F1HM).
- Generative model requires a moderate amount of real data (≥50 images) to produce useful synthetic data; augmentation less effective below this threshold.
- Synthetic data quality depends on mask simulation approximations (elliptical defect shapes) which may not capture complex defect morphologies.
- Limited exploration of class imbalance mitigation; oversampling minority defects with synthetic data did not improve performance.
- No explicit evaluation on data with substantial distribution shift or on adversarial robustness of generated data or models.
- Potential propagation of human bias from original expert-labeled masks into synthetic data and models.
- Physics-based contrast and diffraction effects in STEM images are not modeled in LDM generation, potentially reducing realism for certain defect types.
Open questions / follow-ons
- Can more advanced or learned mask generation models better capture complex defect shapes and improve augmentation effectiveness?
- How to integrate physics-based constraints or features into diffusion models to better replicate electron microscopy image characteristics?
- To what extent does bias in original expert annotations propagate or amplify through generative augmentation pipelines, and how can this be mitigated?
- Can iterative feedback loops between defect detection/classification models and generative models enhance synthetic data quality and ultimate performance?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this study illustrates the nuanced benefits of generative data augmentation in domains with scarce labeled data. While the domain here is materials microscopy, the insights on how mask-conditioned diffusion models can create labeled synthetic image-mask pairs have cross-domain relevance. The key takeaway is that generative augmentation may yield modest improvements when aligned closely with real data distributions and when baseline datasets have a minimal size threshold. However, the improvements depend sensitively on train/test splits and may primarily enhance either detection or classification components.
For CAPTCHA systems, which often confront low-data or adversarial environments, adopting generative augmentation must be weighed against computational costs and evaluation rigor. In particular, the finding that augmentation effects vary with dataset partitions warns that observed gains may not generalize across test conditions. Additionally, augmentation methods might fail to overcome imbalance without careful class-sampling strategies. This work underscores the importance of thorough evaluation pipelines and suggests cautious optimism that mask- or label-conditioned diffusion models could augment scarce security training datasets, but only as part of a holistic strategy considering data quality, domain shifts, and model biases.
Cite
@article{arxiv2606_02532,
title={ Improving Combined Detection and Classification of TEM Defects via Mask-Conditioned Latent Diffusion Augmentation },
author={ Ni Li and Nuohao Liu and Ryan Jacobs and Ajay Annamareddy and Maciej P. Polak and Kevin Field and Izabela Szlufarska and Dane Morgan },
journal={arXiv preprint arXiv:2606.02532},
year={ 2026 },
url={https://arxiv.org/abs/2606.02532}
}