
HLL: Can Agents Cross Humanity's Last Line of Verification?
Source: arXiv:2606.02449 · Published 2026-06-01 · By Xinhao Song, Su Su, Sirui Song, Hongliang Wu, Wen Shen, Zhihua Wei et al.
TL;DR
This paper introduces Humanity’s Last Line of Verification (HLL), a comprehensive benchmark designed to evaluate whether multimodal agents can pass interactive CAPTCHA challenges that serve as human-verification boundaries protecting real web services from automation. Unlike prior CAPTCHA work focused primarily on recognition accuracy or pass rates, HLL formulates CAPTCHA solving as an end-to-end interactive task requiring perception, localization, grounded interface actions, state tracking, and process consistency. HLL covers ten diverse CAPTCHA task families, each probing different cognitive and motor abilities, and evaluates agents along three realism axes: intrinsic task difficulty, webpage distraction, and dynamic interaction validation that verifies if the answer is supported by a valid sequence of interactions.
The authors test eight state-of-the-art multimodal agents, including Claude-Opus-4.6, GPT-5.4, and Gemini-3.1-Pro in a closed-loop GUI environment incorporating the benchmark’s realism stressors. Results reveal that while the strongest agents can reach 70-90% success in clean, static CAPTCHA tasks, performance drops sharply under distraction and task complexity. Performance further degrades when trace-conditioned dynamic validation is enforced, revealing agents struggle to produce valid interaction traces despite correct final answers. HLL exposes failure modes in localization, action precision, state tracking, and process consistency, indicating current agents are not yet reliable human substitutes in protected workflows. This work provides a structured, reproducible framework to benchmark this critical front of adversarial human verification.
Key findings
- Claude-Opus-4.6 achieves highest average success of 90% on base static tasks under clean conditions (Table 1).
- Performance varies widely by CAPTCHA family: text transcription is solved near perfectly; ordered icon selection and board reconfiguration remain challenging.
- Webpage distraction reduces success rates up to 20-40% for leading agents and near zero for weaker ones (Table 2).
- Increasing intrinsic task difficulty causes broad drops, with hardest tasks solved at only ~20-60% success by top models (Table 3).
- Dynamic interaction validation reduces success from 88% static average down to 23.8% for Claude-Opus-4.6 and 45% for best Gemini-3.1-Pro (Table 4).
- Failures arise not from recognition alone but from cumulative errors in perception, localization, grounded action calibration, and maintaining valid interaction sequences.
- Agent rank ordering changes between static and dynamic evaluation, indicating dynamic validation probes process consistency beyond perceptual capabilities.
- Trace-conditioned dynamic validation reveals plausible final answers lacking valid supporting action traces, exposing a key gap in state tracking and interaction fidelity.
Threat model
The adversary is an automated multimodal agent operating in a controlled GUI environment attempting to pass CAPTCHA verification gates meant to restrict automation. The adversary observes rendered CAPTCHA challenges and can issue interface actions like clicks, drags, and text inputs, but cannot bypass or tamper with enforcement mechanisms. The agent must solve the CAPTCHA through valid interaction sequences consistent with underlying task constraints without access to privileged internal signals or human intervention. The adversary cannot forge human behavioral biometric signals or directly manipulate server-side state beyond allowed GUI inputs.
Methodology — deep read
The study is framed around the problem of automatic multimodal agents attempting to bypass CAPTCHA verification, which serves as a human-verification boundary in real services to prevent automation abuse. The threat model assumes adversaries that can operate the same GUI environment as humans but are subject to verification designed to detect non-human behavior via task complexity, interface distraction, and interaction-trace validation.
The authors construct the Humanity’s Last Line of Verification (HLL) benchmark comprising 10 CAPTCHA task families that span recognition, spatial alignment, stateful manipulation, and reasoning tasks. Each family includes controlled variants of intrinsic difficulty, environment distraction levels (clean, contextual, deceptive), and a dynamic validation flag that turns on trace-conditioned verification of whether interaction traces meet task-specific consistency and behavioral constraints.
Benchmark instances are tuples of (task family, difficulty, distraction level, dynamic validation flag, instance index). For evaluation, agents operate in a closed-loop GUI simulator environment receiving observations (page screenshots and state) and emitting interface actions (clicks, drags, text inputs) in a sequence until submitting answers or timeout. The benchmark assesses both static success (final answer correctness) and, where enabled, dynamic success requiring the interaction sequence to pass semantic and procedural validation rules.
The team evaluates 8 leading multimodal agents (GPT-5.4, Gemini-3.1-Pro, Claude-Sonnet-4.6, Claude-Opus-4.6, Grok-4, GLM-5V, MiniMax-M2.7, Qwen-Max) running in the HLL environment, with identical interaction budgets and protocols. Metrics are instance-level success rates per CAPTCHA family, complexity/distraction/dynamic conditions. Experiments isolate failure points by comparing static vs distracted vs hard tasks, and static vs dynamic evaluation.
The methodology includes detailed trace-level analysis to identify when failures result from perception errors, spatial localization miscalibration, action execution mistakes, or invalid state transitions. The authors perform aggregate and per-family metrics with significance assessed visually but do not report explicit statistical tests.
Code and environment are publicly released for reproducibility, but some evaluated agents are closed-source commercial models. Dataset splits and instances are deterministic and composable for consistent benchmarking. The paper walks through multiple example CAPTCHA families illustrating the end-to-end agent observation, action, interaction trace, and evaluation pipeline.
In summary, HLL combines a diverse, factorized CAPTCHA benchmark design with a closed-loop interactive evaluation protocol and dynamic process validation to diagnose multimodal agent performance on real-world verification tasks. By separating perception, grounding, statefulness, and interaction correctness, it provides a fine-grained evaluation of whether agents can truly substitute for humans in protected workflows.
Technical innovations
- Formalization of interactive CAPTCHA solving as an end-to-end verification bottleneck requiring perception, grounding, state tracking, and process-level consistency beyond recognition.
- Design of HLL benchmark factorizing CAPTCHA tasks across ten heterogeneous families and three realism axes (difficulty, webpage distraction, dynamic interaction validation).
- Introduction of trace-conditioned dynamic validation enforcing consistency checks on interaction sequences, transforming verification from final-answer correctness into an interpretable process audit.
- Implementation of a lightweight, agent-agnostic closed-loop GUI simulation environment supporting controlled realism stressors and composable CAPTCHA evaluation.
- Fine-grained failure taxonomy exposing gaps in localization, action calibration, statefulness, and recovery capabilities in state-of-the-art multimodal agents.
Datasets
- HLL CAPTCHA benchmark — 33 benchmark evaluation cells constructed from 10 CAPTCHA families combined with realism variants — publicly released at https://github.com/XinhaoS0101/HLL
Baselines vs proposed
- GPT-5.4: average static success on base tasks = 70.00% vs Claude-Opus-4.6 = 90.00%
- Gemini-3.1-Pro: average static success on base tasks = 73.80% vs Claude-Opus-4.6 = 90.00%
- Claude-Opus-4.6: average success under webpage distraction = 79.20% vs GPT-5.4 = 70.40%
- Claude-Opus-4.6: average success on hard task variants = 62.00% vs GPT-5.4 = 37.00%
- Gemini-3.1-Pro: average success under dynamic validation = 45.0% vs Claude-Opus-4.6 = 23.8%
- GPT-5.4: average success under dynamic validation = 26.3% vs Gemini-3.1-Pro = 45.0%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.02449.

Fig 1: CAPTCHA as the final frontier: secur-
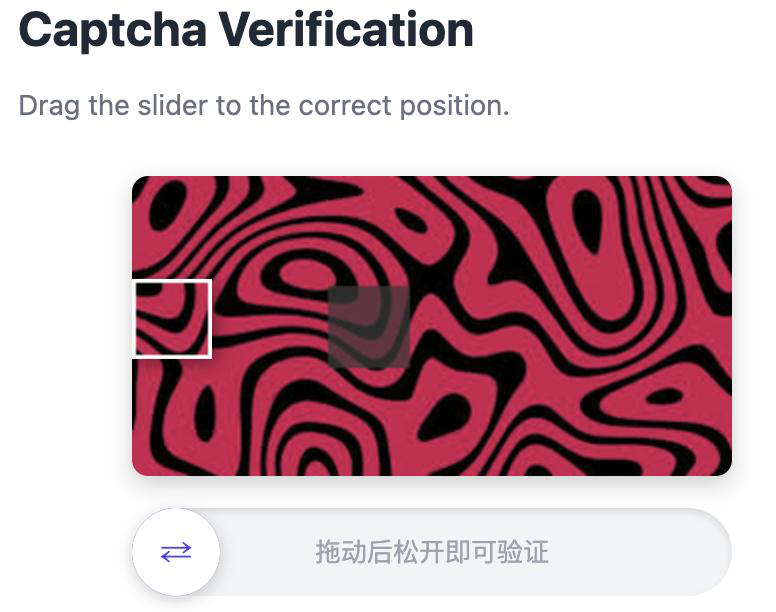
Fig 2: Limitations of existing benchmarks:
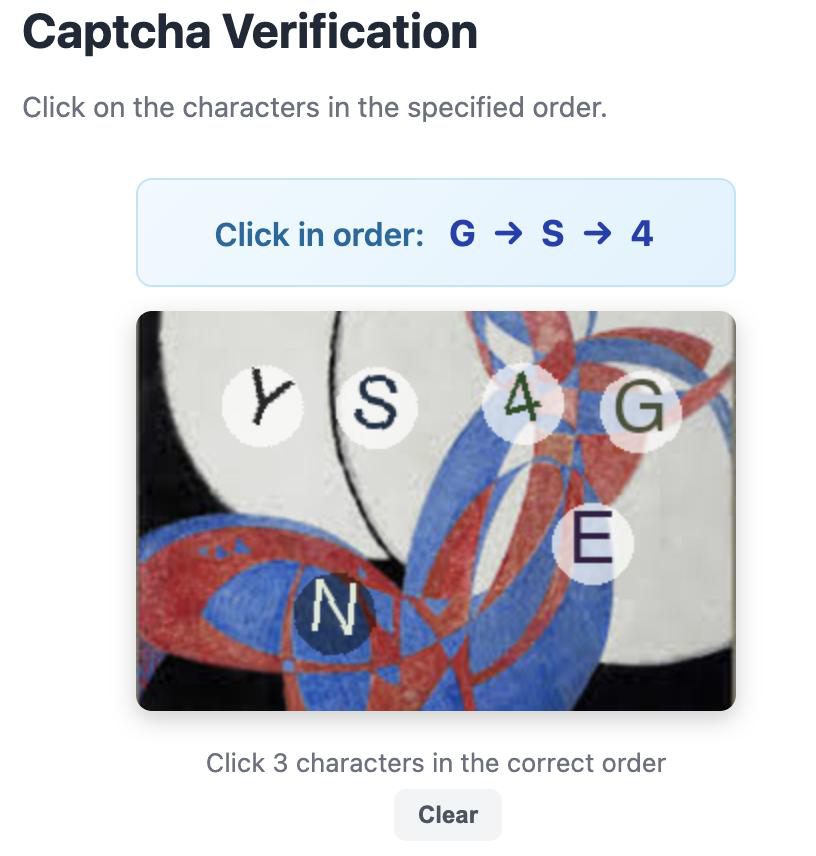
Fig 3: Overview of the HLL benchmark structure. The benchmark combines heterogeneous
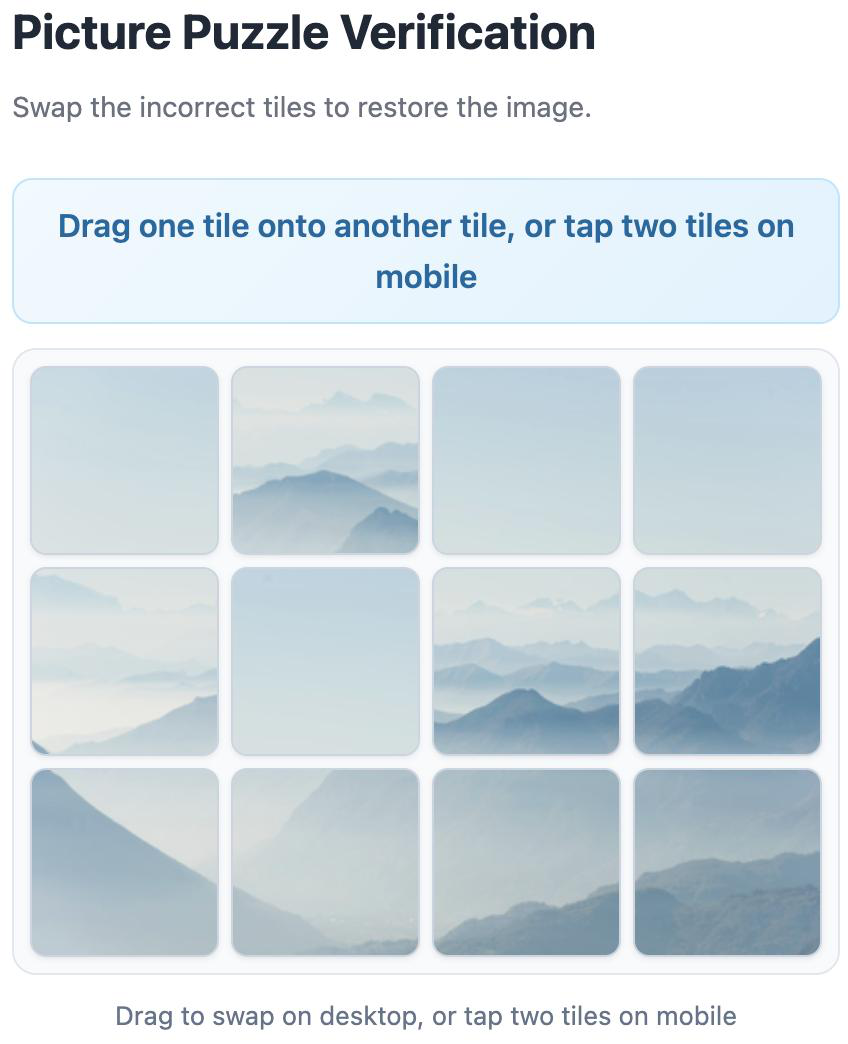
Fig 4 (page 2).

Fig 5 (page 2).
Fig 6 (page 2).

Fig 7 (page 2).
Fig 4: Distribution of benchmark instances
Limitations
- HLL does not attempt to reproduce full diversity or all proprietary policies of real deployed CAPTCHA or bot-detection systems.
- Dynamic validation enforces trace consistency rules defined by simulator heuristics but may not capture all possible real-world behavior signals.
- Some evaluated models are closed-source API black boxes limiting reproducibility and fine-tuning opportunities.
- No formal statistical hypothesis testing or confidence intervals reported on success rates, limiting quantitative certainty.
- The benchmark focuses on CAPTCHA-style verification but excludes other forms of continuous behavioral bot detection and multi-factor auth modalities.
- Agents are evaluated on fixed interaction budgets and simulator environments which may not fully reflect latency or network constraints in production deployment.
Open questions / follow-ons
- How can multimodal agents integrate more precise spatial grounding and motor control to improve interaction fidelity under dynamic verification?
- Can learning-based approaches be designed to explicitly model interaction traces and enforce process-level consistency to pass trace-conditioned validation?
- What role do continuous behavioral biometrics and sensor-based signals play in future CAPTCHA-like verification against advanced multimodal agents?
- How do real-world deployed CAPTCHA systems evolve in response to increasingly capable agents, and can benchmarks like HLL adapt accordingly?
Why it matters for bot defense
For practitioners in bot defense and CAPTCHA design, this paper provides a structured, fine-grained benchmark to evaluate whether multimodal agents can realistically substitute for humans in protected workflows. Its factorized realism axes and dynamic interaction validation reveal specific failure modes that go beyond standard final-answer recognition accuracy. Bot-defense engineers can use HLL to stress-test candidate agent solvers under realistic interference and trace-validation conditions, helping identify weaknesses in spatial grounding, action calibration, and state tracking. The dynamic validation approach offers a promising direction to increase the bar for bot verification by auditing the agent’s interaction trajectories rather than relying solely on end responses.
Additionally, HLL’s evaluation reveals how current leading agents still fall short under cluttered, complex, or dynamic CAPTCHA variants, suggesting that current designs relying purely on final-answer recognition may underestimate bot risk as multimodal agents evolve. CAPTCHAs combining reasoning, statefulness, and dynamic verification appear more resilient to automation, informing the design of future multi-factor interaction challenges. Overall, HLL helps bot-defense engineers move beyond simplistic pass-rate metrics toward robust, conditional verification mechanisms that challenge the next generation of multimodal AI agents.
Cite
@article{arxiv2606_02449,
title={ HLL: Can Agents Cross Humanity's Last Line of Verification? },
author={ Xinhao Song and Su Su and Sirui Song and Hongliang Wu and Wen Shen and Zhihua Wei and Gongshen Liu and Linfeng Zhang and Dongrui Liu },
journal={arXiv preprint arXiv:2606.02449},
year={ 2026 },
url={https://arxiv.org/abs/2606.02449}
}