
Harness-1: Reinforcement Learning for Search Agents with State-Externalizing Harnesses
Source: arXiv:2606.02373 · Published 2026-06-01 · By Pengcheng Jiang, Zhiyi Shi, Kelly Hong, Xueqiang Xu, Jiashuo Sun, Jimeng Sun et al.
TL;DR
This paper addresses a fundamental challenge in training reinforcement learning (RL) search agents: typical approaches require the policy model to manage both strategic semantic decisions and low-level, recoverable search state internally, complicating the learning process. The authors introduce Harness-1, a 20 billion parameter search agent that separates concerns by externalizing bookkeeping (search state like candidate pools, curated sets, evidence graphs, verification records, and budget markers) into a stateful environment "harness." The policy focuses solely on semantic search actions such as what to search, which documents to curate or verify, and when to stop. Harness-1 uses an importance-tagged curated set, compression, and verification mechanisms to maintain a compact and informative state representation. By training on multiple domains with supervised fine-tuning (SFT) followed by RL with a carefully designed reward incorporating diversity and curation, Harness-1 achieves a strong average curated recall of 0.730 across eight benchmarks in settings including web, finance, patents, and multi-hop QA.
This recall surpasses the next best open models by 11.4 points and remains competitive with much larger state-of-the-art frontier models. The gains are particularly pronounced on held-out, out-of-distribution transfer benchmarks, indicating that RL over explicit search state generalizes better than prior approaches relying on monolithic transcript-based policies. Ablations confirm the critical role of the harness components like importance tags, evidence graphs, and auto-seeding. The work demonstrates the benefit of stateful cognitive offloading for RL-based search agents and provides a modular, scalable framework with open code and data to facilitate future research.
Key findings
- Harness-1 achieves 0.730 average curated recall across 8 diverse search benchmarks, improving +11.4 points over the next best open subagent (Tongyi DeepResearch 30B).
- Performance gains on held-out transfer benchmarks (LongSealQA, Seal0QA, FRAMES, HotpotQA) average +17.0 recall points, which is 2.2x higher than gains on source-family benchmarks.
- Ablating any one of the harness mechanisms (importance tagging, BM25 compression, auto-seed, or evidence graph) causes relative final-answer recall drops of 3.9–7.9% (see Table 3).
- Removing all harness mechanisms at inference causes a −12.2% relative drop in final recall, larger than any single ablation alone.
- Content fingerprint deduplication, while intended to reduce token usage, showed a small nominal +4.6% recall/+1.6% final-answer recall gain, likely due to collapsing near-duplicates in noisy qrels.
- RL with a diversity bonus on the use of search tools increased final recall from ~0.53 to ~0.60 and maintained higher tool diversity in training (Figure 5).
- Trajectory recall (evidence discovered anywhere in the search before curation) is high (~0.88 on several benchmarks), showing the main challenge is selecting the final curated set properly.
- Harness-1 outperforms GPT-5.4, Sonnet-4.6, and GPT-OSS-120B on average curated recall despite being smaller (20B vs 30-120B).
Threat model
n/a — This paper is primarily about improving RL-based semantic search agent design and training rather than adversarial threat modeling.
Methodology — deep read
Threat Model & Assumptions: The adversary in this context is not explicitly modeled as a malicious attacker but considered as the learning policy itself facing a complex search environment. The policy must decide how to iteratively retrieve and curate documents relevant to open-domain queries. The major assumption is that the environment can maintain a stateful working memory reliably, externalizing bookkeeping tasks that were previously internalized by the model.
Data: The model is trained and evaluated on eight retrieval benchmarks spanning domains of web documents, finance, patents, and multi-hop question answering (QA). Benchmarks include BrowseComp+, Web Synthetic, USPTO patents, SEC filings, LongSealQA, Seal0QA, FRAMES, and HotpotQA. The supervised fine-tuning (SFT) dataset contains 899 filtered trajectories spanning BC+, Web, Patents, and SEC. Reinforcement learning (RL) is conducted on the SEC training split with 3,453 queries. Held-out benchmarks (LongSealQA, Seal0QA, FRAMES, HotpotQA) evaluate transfer generalization.
Architecture / Algorithm: Harness-1 is implemented as a 20B parameter search agent built on gpt-oss-20b. The environment provides a two-tier stateful search harness exposing a rendered "WORKINGMEMORY" state to the policy. This state encodes the candidate document pool (Pt), a curated output set with learned importance tags (Ct, It), full-text memory (Dt), an evidence graph (Gt) connecting entities across docs, verification records (Vt), search history (Ht), and a budget-aware context marker (Bt). The policy outputs structured semantic actions each turn to retrieve, curate (add/remove, importance tag), verify claims against documents, review documents, or terminate. The harness executes these actions and updates the search state, which is then compressed, deduplicated, and rendered back to the policy.
The key novelty is externalizing recoverable bookkeeping (e.g., document pools, links, verifications) into environment-managed constructs rather than embedding it all inside the policy's textual context. This allows the policy to focus on semantic control decisions rather than rote state management.
- Training Regime: Training proceeds in two stages:
- Supervised fine-tuning (SFT) teaches the model the protocol for operating the harness actions, importance tagging, verification conventions, and search → curate rhythms using human-like teacher data generated by a GPT-5.4 live agent operating inside the harness. SFT is run on gpt-oss-20b via LoRA rank 32 for 3 epochs.
- RL training starts from the SFT checkpoint and uses the on-policy CISPO algorithm with within-group advantage normalization to optimize full episodes capped to 40 turns. The reward combines multiple components: quality of the curated set, coverage of evidence retrieved (trajectory recall), answer evidence reward, a tool diversity bonus encouraging exploration of multiple tools, and a turn penalty to encourage efficiency. Groups of rollouts with identical reward are dropped from gradients to stabilize learning.
Evaluation Protocol: The agent is evaluated on curated recall (relevant documents in the final output set), final-answer recall (coverage of answer documents), and trajectory recall (coverage of relevant evidence encountered anywhere during the episode). Metrics are averaged over three runs. Baselines include strong open-source models (Context-1 20B, GPT-OSS, Qwen3 32B, Search-R1 32B) and frontier closed models (GPT-5.4, Sonnet-4.6, Opus-4.6). Ablations consist of disabling individual harness mechanisms at inference with the trained policy unchanged to analyze failure modes. Transfer evaluation on held-out benchmarks not seen during training tests generalization.
Reproducibility: The authors commit to releasing model weights, harness code, data generation pipelines, and RL training recipes openly on GitHub. The datasets are standard benchmarks, though some use proprietary web or document backends. Details on hyperparameters, reward weights, and training steps are provided in appendices.
Example End-to-End: For a given query, the policy first issues multiple fan_out_search calls, receiving a candidate pool in Pt. After auto-seeding the curated set Ct with top reranked candidates, the model iteratively performs curate actions to add or remove documents with importance tags, issues verify actions writing claims and checking support against documents in Dt, and re-reads documents via review_docs. At each turn, the harness compresses observations with BM25 sentence scoring and fingerprints deduplicate near-duplicates. The policy decides when to stop based on state signals including evidence graph connectivity and search budget Bt. Final evaluation measures how well the curated set covers ground truth relevant and answer documents.
Technical innovations
- State-externalizing harness architecture that offloads all routine bookkeeping (candidate pools, curated sets, evidence graphs, verification records) to environment-managed state, allowing the policy to focus purely on semantic search control.
- Use of an importance-tagged curated set to represent prioritized search results with explicit language for confidence and capacity eviction.
- Compact derived-state rendering including an evidence graph summarizing cross-document entity links and BM25 sentence compression of observations to reduce context size.
- Three trainability principles for creating RL-compatible search harnesses: warm-started curation via auto-seeding, compact derived-state rendering, and diversity-preserving incentives in the reward to ensure broad tool use.
- A structured action interface integrating search, curation, verification, memory review, and termination decisions with state updates executed outside the policy.
Datasets
- BrowseComp+ — thousands of queries — public/academic retrieval benchmark
- Web Synthetic — hundreds of queries — synthetic web-based retrieval tasks
- USPTO Patents — hundreds of patent office action queries — public patent corpus
- SEC Filings — 3,453 queries used for RL training — finance domain corpus
- LongSealQA — multi-hop QA, held-out transfer — public benchmark
- Seal0QA — multi-hop QA, held-out transfer — public benchmark
- FRAMES — multi-hop QA, held-out transfer — public benchmark
- HotpotQA — multi-hop QA, held-out transfer — standard open QA benchmark
Baselines vs proposed
- Tongyi DeepResearch (30B): average curated recall 0.616 vs Harness-1 (20B) 0.730
- Context-1 (20B): curated recall 0.557 vs Harness-1 0.730
- GPT-OSS-20B: curated recall 0.208 vs Harness-1 0.730
- GPT-5.4 (frontier model): curated recall 0.611 vs Harness-1 0.730
- Opus-4.6 (frontier model): curated recall 0.764 vs Harness-1 0.730
- Disabling importance tags at inference: final-answer recall drops −7.9% relative
- Disabling evidence graph rendering: final-answer recall drops −5.4% relative
- Disabling all harness mechanisms: recall drops −12.2% relative
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.02373.
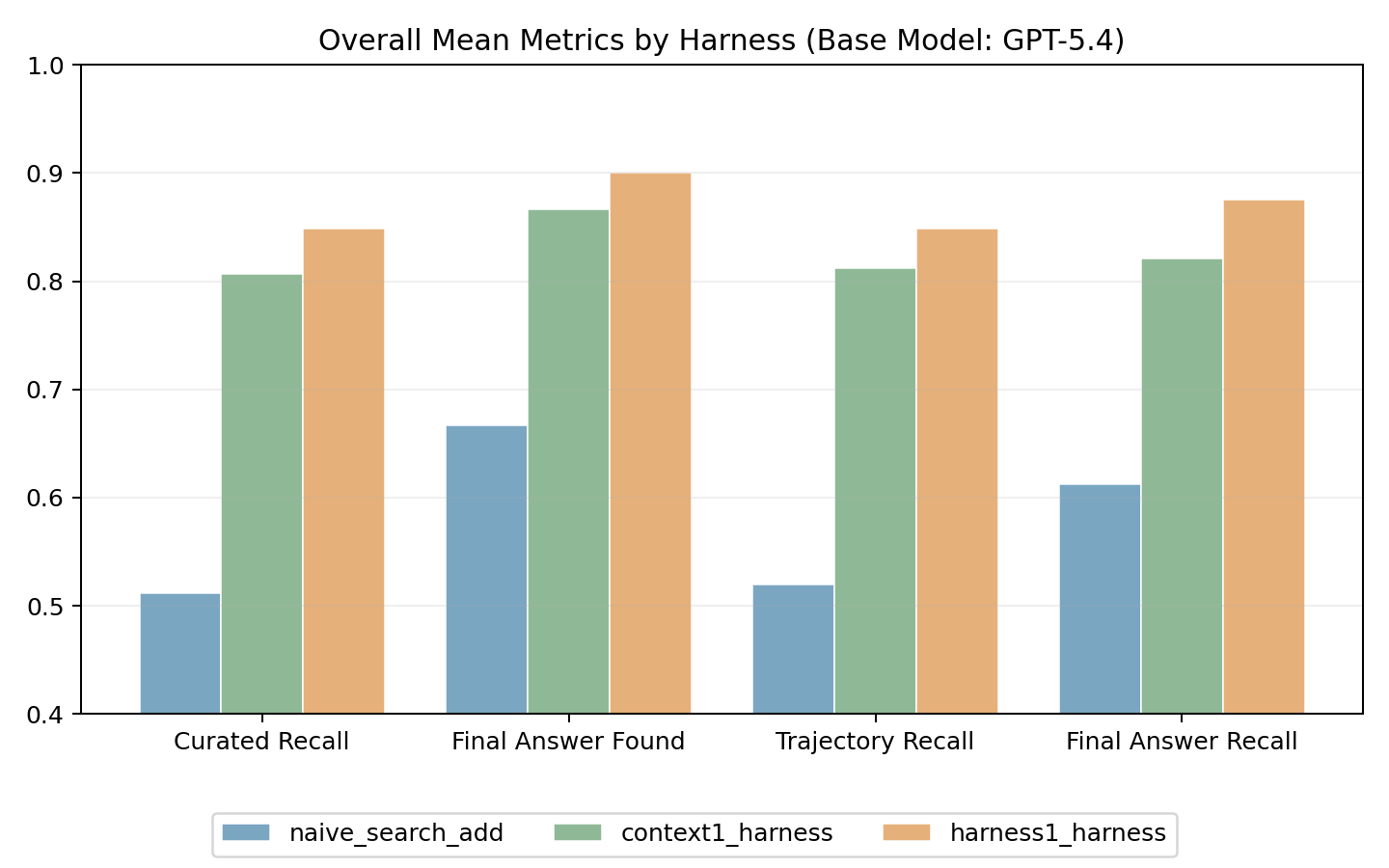
Fig 6: Answer accuracy (%) under the modular RAG protocol. Each subplot is a benchmark;
Limitations
- RL training is restricted to SEC dataset only; SFT covers four families but full RL cross-domain training was not explored.
- Held-out transfer benchmarks are limited to four QA-focused corpora; further generalization to truly unseen domains not tested.
- No explicit adversarial robustness or attack simulation is reported; model vulnerabilities to adversarial search queries remain unknown.
- The approach depends on fixed budget limits on curated set size (30 documents); scalability to much larger or unconstrained search scenarios is unclear.
- The evidence graph is built using regex heuristics for entity extraction; more sophisticated semantic linking could yield richer representations.
- While code and model weights are promised, working with large 20B models and accompanying infrastructure might limit accessibility.
Open questions / follow-ons
- Can the state-externalizing harness approach scale to web-scale search with billions of documents and richer knowledge graphs?
- How does the approach fare under adversarial or noisy retrieval environments designed to fool the agent's state mechanisms?
- Can the evidence graph construction be enhanced with learned or semantic entity linking methods rather than regex heuristics?
- What is the impact of further increasing policy scale or training data volume on transfer and generalization performance?
Why it matters for bot defense
For bot-defense engineers focused on CAPTCHA or bot-detection, this paper offers valuable lessons about how reinforcement learning agents managing search or retrieval tasks can benefit significantly from explicit state externalization to improve learning efficiency and generalization. Analogously, detection systems might better handle multi-step interactive behaviors by maintaining structured environment state rather than relying solely on transcripts. The modular harness approach separating semantic decisions from bookkeeping could inspire architectural designs in CAPTCHAs or bot challenges that require semantic understanding alongside complex state tracking. The demonstrated improvements in transfer learning also highlight the importance of disentangling semantic control from routine management for agents interacting with dynamic, distributed environments such as user sessions or interaction histories in bot defense.
Cite
@article{arxiv2606_02373,
title={ Harness-1: Reinforcement Learning for Search Agents with State-Externalizing Harnesses },
author={ Pengcheng Jiang and Zhiyi Shi and Kelly Hong and Xueqiang Xu and Jiashuo Sun and Jimeng Sun and Hammad Bashir and Jiawei Han },
journal={arXiv preprint arXiv:2606.02373},
year={ 2026 },
url={https://arxiv.org/abs/2606.02373}
}